Leaderboard




Popular Content
Showing content with the highest reputation on 03/08/17 in all areas
-
So they responded with a new bios to test (L1.87). I'll give it a whirl and post back my results. It's different from the last beta bios they sent me (P1.89E), so hopefully it will solve this!2 points
-
For some time now I wanted to upgrade my homeserver, the one I have now is based on a 1st gen core i5 processor with 8GB of Ram sitting on an m-itx motherboard with only four sata connections. The four sata connections quickly became an obstacle to expand my array of harddisks. I solved that by buying a cheap Sata Controller I/O board, and to my surprise it actually worked very well. The Sata Controller allowed for an additional 4 Sata connections, which of course is great, but now I don’t have the opportunity to add other I/O cards because of the m-itx formats limitation of only having one pci-e port. I really like the m-itx form factor because of it’s physical size, but it is also the physical size that is it’s limitation, what I needed was a new motherboard. I contacted Asrockrack to see if they were interested in sponsoring this endeavor of updating my server, and it turned out that they would, and a few days ago this came: A both classy and anonymous looking box with only a little information on the front, and just a little more on the back: Information is maybe stretching it a little, it is more advertisements but that makes sense to me, as the folks that buy this are for most part aware of what they are getting into, and they don’t necessary need more information from the box. A box is all good and well, but what really is interesting is of course the content: What we see here is A drivers DVD Five SATA cables An I/O shield A manual My initial thought was that isn't much; I'm used to mainstream boards where there are screws, ceramic washers, door hangers, a soundcard or maybe even an antenna for Wi-Fi. but this is not a mainstream motherboard, it is servergrade and made for professional use, so door hangers aren't really a buying factor - Come to think of it, is a door hanger really a factor when buying factor when buying mainstream motherboards? And here it is, the crown jewel; the ASRockRack ep2c602: Initially I proposed ASRockRack to sponsor the EPC602A, which is a single socket motherboard - more that adequate for a home server, but as these boards feature chipsets that were launched in Q1 2012, they aren't the newest out there, and the epc602d8a was no longer in stock, so ASRockRack suggested the ep2c602; I humbly accepted. The center piece(s) of the ep2c602 are of course the two LGA 2011 cpu sockets, capable of supporting a large variety of intel Xeons int both Ivy- and Sandy bridge flavors, that means that should I ever want to upgrade the CPUs in this build I would have ample choice. To the left and to the right of the sockets (respectively) we see the mosfets, they are kept nice and cool by the heatsinks. Above and below the Dimm slots are clearly visible, combined they support 256GB of RAM. Though that would require that both CPU sockets are populated. Should only one CPU be used, it should be mounted in the left most socket, and as indicated earlier only the corresponding Dimms are usable in that case. The 20+4 pin ATX connecter can be seen on the lower edge, and the two EPS 8 pin connectors are seen in the bottom left corner, and on the right edge, there are two because there are two sockets, these EPS connectors feed the mosfets with power, they in turn feed the CPU with ripple minimized current. There are no less than eight fan headers on the ep2c602, the seven are of the 4pin PWM persuasion, that means that noise from fans forced to run at full speed is nothing to be worried about, with this board. The two remaining headers are placed near the second CPU socket; convenient. Ah the disk connectors... The four blue ones farthest away are actually SAS connectors, I don't own any SAS drives, but my guess it isn't a problem connecting SATA drives to those, they should be compatible, there is only one way to be sure... Testing. The four blue ones that are right angled on the PCB are SATAII ports and are, together with first two white ports (They are SATAIII though), controlled by the chipset. The last four white ports are SATAIII and controlled by a marvel controller. Notice how the ten angled SATA connectors are pulled back from the edge of the motherboard? Yeah I was wondering about that myself, but it turns out it isn't a bad idea, but more on that later. The keen eye has probably already seen the onboard USB connector, this will come in handy; my operating system of choice is Lime-Technologys unRaid, which runs directly from a USB drive. Behind the USB connector we se a pair 7 segment led displays which server the purpose of helping with diagnose the system should there be any errors. On the Rear I/O panel we see some legacy connectors PS/2 for mouse and keyboard and a Serial connector, even though the latter isn't use that often it can be very useful when working with network devices, as the preliminary configurations needs a serial connection. We have the standard VGA connection, this system is going to run headless, but with early testing and configuration this will come in very handy. Three RJ45 ports, two gigabit ports for LAN connection and one 100 megabit port for IPMI connection. I will do a more in depth post of the IPMI function. For now I will say that IPMI from an administrators point of view is bloody awesome! The EP2C602 is an older motherboard, it still is build on a solid technology and should prove to be a very good and sturdy base for my build.1 point
-
Sorry to double post, but I'm not getting any assistance in the docker container support thread. My Crashplan docker continues to crash randomly, about a week or so, and I have no idea what it's complaining about or why it's crashing. This is what pops in the log when it happens: *** Shutting down runit daemon (PID 22)... XIO: fatal IO error 11 (Resource temporarily unavailable) on X server ":1" after 2120 requests (2120 known processed) with 0 events remaining. ./run: line 20: 39 Killed $JAVACOMMON $SRV_JAVA_OPTS -classpath "$TARGETDIR/lib/com.backup42.desktop.jar:$TARGETDIR/lang" com.backup42.service.CPService > /config/log/engine_output.log 2> /config/log/engine_error.log Unfortunately if I go and look for that engine_error log it mentions it's completely blank so this is all I have unless someone can point me in another direction. I also have a problem with this docker and autostart - as in it can't for whatever reason. Also asked in the support thread and got nothing. This is that error, in case somehow it's all related. ERROR: openbox-xdg-autostart requires PyXDG to be installed Not really sure why it's complaining about that. It's not like I have an option to install it.1 point
-
Welcome to v6+. The best way to add "Apps" in unRAID 6 is to use the Community Applications Plugin: https://forums.lime-technology.com/topic/38582-plug-in-community-applications/ When you add this plugin you will get a tab within the unRAID GUI called Apps. Within this tab you can search for "Plex" and choose the linuxserver container and install. Once installed the container will appear in the Docker tab where you can configure. Useful links for you: v6 getting started: https://lime-technology.com/wiki/index.php/UnRAID_6/Getting_Started#Getting_Started Docker FAQ's: https://forums.lime-technology.com/topic/55246-docker-faq/1 point
-
Install Community Applications The notion of repositories isn't really used anymore within unRaid (and that's not the repository URL that you posted)1 point
-
I thought it would be helpful to do a separate post on Ryzen PCIe lanes, since it is a bit confusing right now. Here's a crash course. DISCLAIMER: I may be wrong on a detail or two, but if so I blame the tech sites, many of which have posted bad info. Also keep in mind that with ~80 different motherboards on the market, in different configurations, there may be some exceptions to the info I post below. Ryzen has 24 PCIe 3.0 lanes. Total. That's it. On X370, B350 and A320 chipset motherboards, 4 of those lanes are dedicated to the chipset. That leaves 20 PCIe 3.0 lanes for add-in cards. The X300/B300 small form-factor chipsets are unique in that they hardly do anything, and supposedly don't use PCIe lanes to communicate with the Ryzen CPU, instead they use a dedicated SPI link. This should leave all 24 PCIe 3.0 lanes available directly from the CPU. Sounds interesting, though IOMMU groups may be bad, and all USB ports will be going directly to the CPU, so again IOMMU groups may be bad. Plus, since the X300/B300 series chipsets are intended for small form factor only (ITX), dual or triple x8 slots are not likely to be available with X300, even though it certainly seems possible. No X300/B300 boards have been released at this time - the expectation is for the second half of 2017. Back to those 20 remaining PCIe 3.0 lanes: 16 of those 20 lanes will go to the primary x16 slot, which will be wired for x16 The secondary x16 slot will be wired for x8, and will "steal" those 8 lanes from the primary slot. That means, with dual GPU's in the primary and secondary slots, both operate at PCIe 3.0 x8. This also means that, since those 16 lanes are being split, typically both of those slots will be in the same IOMMU group - unless the BIOS can somehow fix this The last 4 of the 20 lanes: On most motherboards, the remaing PCIe 3.0 x4 lanes will be dedicated to the M.2 slot. Done and done. But that isn't a hard and fast rule. Sorry, I don't have any examples of other uses of the remaining PCIe 3.0 x4 lanes, but here's some ideas: It could go to a third x16 slot, running at PCIe 3.0 x4 - but this is not likely. If there is a third x16 slot, most likely it will be running at PCIe 2.0 x4, not x16 or x8, a strong indication that this is wired to the X370 chipset, and is NOT using the 4 remaining PCIe 3.0 lanes. If there are additional x1 slots, these will often be shared with the third x16 @ PCIe 2.0 x4 slot and go through the X370 chipset as well. In that case, if you plug anything into an x1 slot, the third x16 slot will downgrade from x4 to x1 as well. The X370 chipset offers an additional 8 lanes of PCIe 2.0. These get routed through the X370 back to the Ryzen CPU over 4 lanes of PCIe 3.0 (along with all the other communications that are probably going through the X370, like audio and USB). This likely means that these 8 lanes of PCIe 2.0 perform below what would be expected from dedicated PCIe 2.0 x8. In some cases, these 8 lanes are being used to create the third x16 slot, which would most likely be wired as PCIe 2.0 x4. The B350 chipset offers an additional 6 lanes of PCIe 2.0, instead of the 8 that X370 offers. The A320 (which for the most part none of use should even consider) only offers 4 PCIe 2.0 lanes. X300/B300 chipsets offer 0 additional lanes, since they connect via SPI link and not PCIe. On some motherboards, like the ASRock Fatal1ty X370 Professional Gaming, using the 2nd M.2 slot will completely disable the third PCIe x16 @x4 slot. You may see similar compromises on other motherboards, where using lanes in one place prevents you from using them in another. Ryzen could have really used another 8 lanes, and this shortcoming is forcing motherboard manufacturers to make compromises. The only potential solution, in the near-term, is for manufacturers to add a PLX chip to their high-end motherboards. If you don't know what a PLX chip is, think of it like a 4-port USB hub that allows a single USB connection to become 4. A PLX chip could easily allow 3 or 4 fully wired x16 slots, possibly each in their own IOMMU group, though their traffic will be shared with each other like a carpool using the 16 lanes going back to the CPU. A PLX chip will probably add about $100 to the cost of a motherboard. The most expensive motherboard (that I've seen) is the MSI X370 XPower Gaming Titanium, at about $300, and it does not appear to have a PLX chip. So at this time, it appears no AM4 motherboards are implementing PLX, though that may change in the future. I'm really, really, really surprised no manufacturer has done this yet. Hopefully this information provides useful, and doesn't scare anyone away from Ryzen. Ryzen is great, but it is smart to know about the nitty gritty details like this before you commit. -Paul1 point
-
If you want to improve parity check speed with current setup try this: 6 disks onboard (use your fastest disks only, 4 and 8tb) 6 disks on SASLP #1 using PCIE1 5 disks on SASLP #2 using PCIE4 Divide slower 2TB disks by the 2 SASLP evenly. With the right tunables this should give a starting speed of around 100MB/s, eventually decreasing a little during the first 2TB but speeding up considerably once past that mark, total parity check time should be well under 24 hours.1 point
-
I'll have a look.1 point
-
The parity is absolutely not valid if you removed a disk from the array.1 point
-
I have a mixed array of 2, 4, and now 8tb drives and thought I would do a little testing. First off this is my initial build. http://forum.kodi.tv/showthread.php?tid=143172&pid=1229800#pid1229800 Since then I have replaced the CPU with a Intel® Core™ i5-3470 and just recently replaced the cache drive with Samsung SSD 850 EVO 250GB along with a new Seagate Archive HDD v2 8TB 5900 parity drive. Here is what my array looks like ...just FYI... So here is a pic of my parity history with the 4 TB against the 8 TB. So after reading about how fast everyone's parity checks were going I decided to run a speed test on drive. here is the pic You can see that the 8TB holds up well and the 4TB are cruising along but the bottle neck are the 2TB drives I have. I have ordered 3 more 8TB drives and am hoping to replace the 2TB drives. Then add a second parity drive. Just thought I would post this for info.
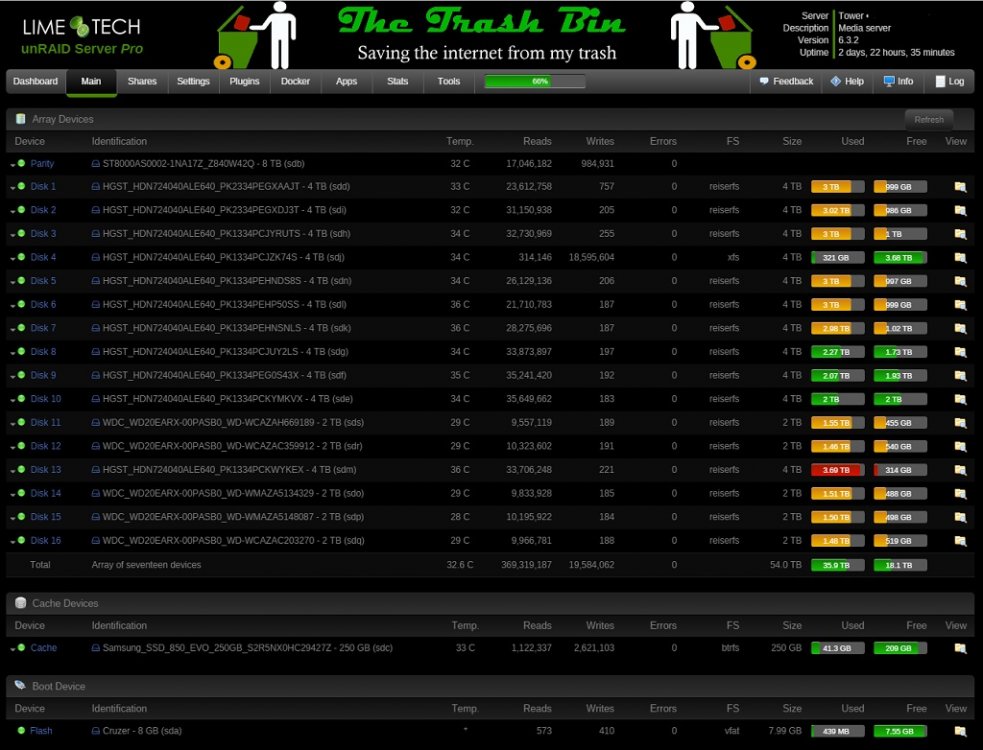
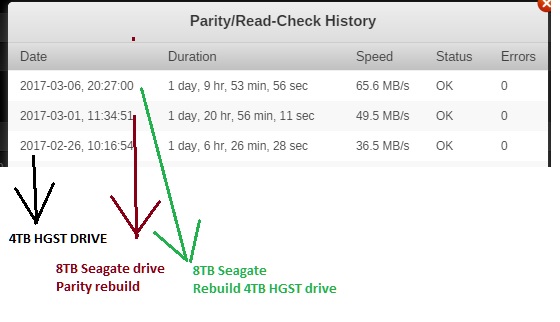
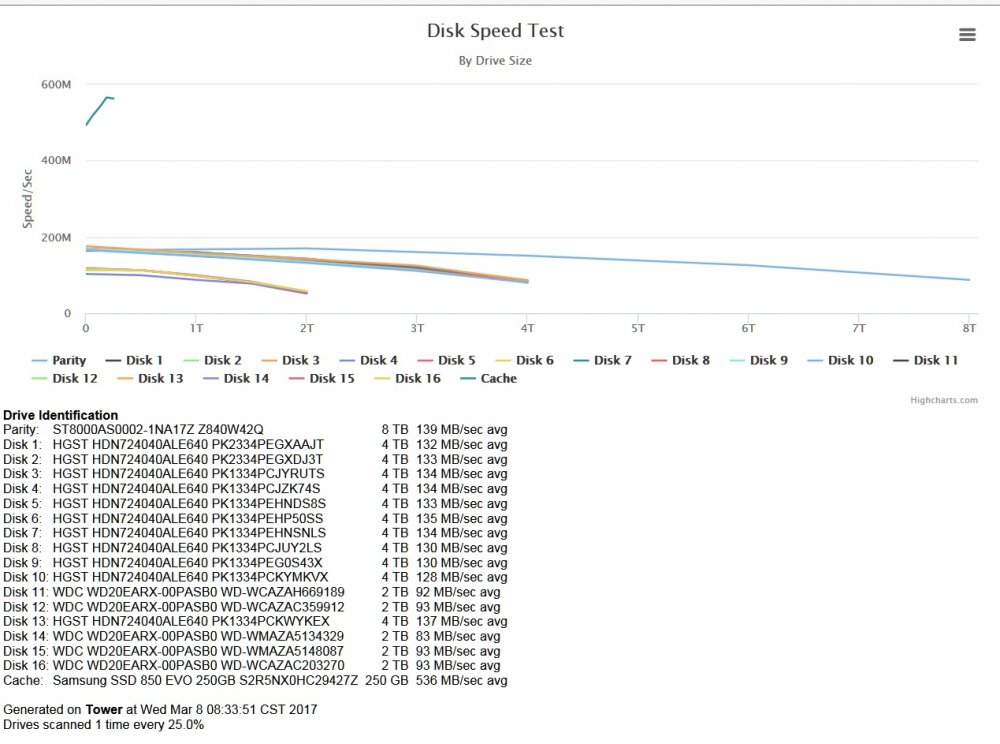 1 point
1 point -
I think I have an approach. The following command gives this output. It shows I have 5 x 8GB sticks installed. But I know I have 6x 8gb sticks installed. The Locator field tells me the name of the DIMM Slot. So it looks like P1 DIMM 3A is either a bad slot or had a bad stick. Did I interpret this properly? I have attached a diagram of the motherboard. # dmidecode -t 17 # dmidecode 3.0 Getting SMBIOS data from sysfs. SMBIOS 2.6 present. Handle 0x0017, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 8192 MB Form Factor: DIMM Set: None Locator: P1-DIMM1A Bank Locator: BANK0 Type: DDR3 Type Detail: Other Speed: 1066 MHz Manufacturer: Hyundai Serial Number: C9B4A928 Asset Tag: Part Number: HMT31GR7BFR4C-H9 Rank: Unknown Handle 0x0019, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P1-DIMM1B Bank Locator: BANK1 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x001B, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P1-DIMM1C Bank Locator: BANK2 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x001D, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 8192 MB Form Factor: DIMM Set: None Locator: P1-DIMM2A Bank Locator: BANK3 Type: DDR3 Type Detail: Other Speed: 1066 MHz Manufacturer: Hyundai Serial Number: 59833027 Asset Tag: Part Number: HMT31GR7BFR4C-H9 Rank: Unknown Handle 0x001F, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P1-DIMM2B Bank Locator: BANK4 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0021, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P1-DIMM2C Bank Locator: BANK5 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0023, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P1-DIMM3A Bank Locator: BANK6 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0025, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P1-DIMM3B Bank Locator: BANK7 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0027, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P1-DIMM3C Bank Locator: BANK8 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0029, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 8192 MB Form Factor: DIMM Set: None Locator: P2-DIMM1A Bank Locator: BANK9 Type: DDR3 Type Detail: Other Speed: 1066 MHz Manufacturer: Hyundai Serial Number: A37F4026 Asset Tag: Part Number: HMT31GR7BFR4C-H9 Rank: Unknown Handle 0x002B, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P2-DIMM1B Bank Locator: BANK10 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x002D, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P2-DIMM1C Bank Locator: BANK11 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x002F, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 8192 MB Form Factor: DIMM Set: None Locator: P2-DIMM2A Bank Locator: BANK12 Type: DDR3 Type Detail: Other Speed: 1066 MHz Manufacturer: Hyundai Serial Number: 16373101 Asset Tag: Part Number: HMT31GR7BFR4C-H9 Rank: Unknown Handle 0x0031, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P2-DIMM2B Bank Locator: BANK13 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0033, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P2-DIMM2C Bank Locator: BANK14 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0035, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 8192 MB Form Factor: DIMM Set: None Locator: P2-DIMM3A Bank Locator: BANK15 Type: DDR3 Type Detail: Other Speed: 1066 MHz Manufacturer: Hyundai Serial Number: 3F7F6001 Asset Tag: Part Number: HMT31GR7BFR4C-H9 Rank: Unknown Handle 0x0037, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P2-DIMM3B Bank Locator: BANK16 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown Handle 0x0039, DMI type 17, 28 bytes Memory Device Array Handle: 0x0015 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: No Module Installed Form Factor: DIMM Set: None Locator: P2-DIMM3C Bank Locator: BANK17 Type: DDR3 Type Detail: Other Speed: Unknown Manufacturer: Serial Number: Asset Tag: Part Number: Rank: Unknown
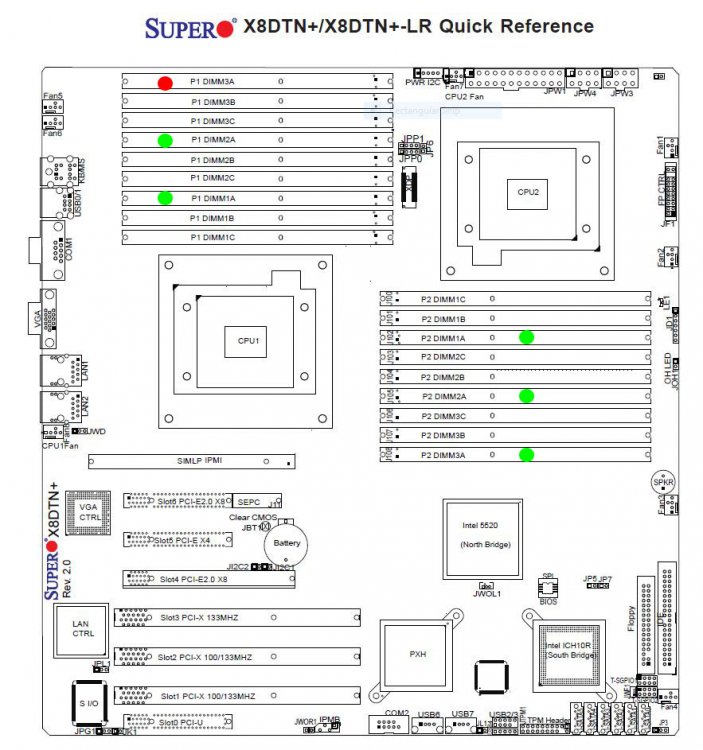 1 point
1 point -
I am just seeing this thread. When dealing with an older, "fragile" array, I would recommend leaving it alone and building a new modern server. You didn't mention the total data capacity of your existing server, or the actual disk sizes involved, but with 8T drives you'd be able to drop the drive count significantly. Once the new server is ready, you could copy the data over the lan without any changes to the old server, which could live on as a backup server. But given where you are, this is what I would do. I would buy some 8T drives, preclear them, and create a new array. Maybe 3 drives to start? You probably have to physically remove some of the existing disks (or remove then all, see below) to make room. I would not assign a parity drive to start, feeling that speed is going to be valuable to get data moved over quickly from the fragile older drives. But having parity installed has advantages to ensure the new array is working and reliable. There is also a write mode called turbo write you could use. It would be up to you. You can install the unassigned devices plugin to mount your existing data disks a few at a time to copy data over to the new disks. You'd be rebooting and physically swapping out the ones you copied from, and swapping in the drives you removed. Once all the data is copied over, you'd build parity if you didn't already have. You might consider removing all the existing disks from the server, with plan to install them one (or a few) at a time to migrate their data. That wound give time to preclear the new disks and test out the new array without the older disks going along for the ride. I'd be worried about the cabling. It is so delicate, and even a small nudge can cause drives to go offline and errors to occur. Problem is exponentially worse with lots of drives. I strongly recommend locking cables and drive cages. If you don't have these, be especially diligent that the corrections on both sides are firm and secure. If you have cables that slide off and on with near zero effort, replace those with different cables that provide better friction. Another reason to remove all the old drives is to simplify your cabling. If you have 3 8T and two of the older drives, that's only 5 disks. Not sure your current count, but imagining 12+. Newer unRaid versions have some issues with some controllers, notably the SuperMicro SASLP and SASLP2. There are settings you can change to likely be able to made these work, but initially I'd focus on using motherboard ports. You may not need addon controllers with the bigger disks. Post back with questions. Good luck!1 point
-
I've seen it before when the bzroot files are either missing or corrupt. Manually download Unraid from the LT website. Extract bzroot, bzroot-gui and bzimage and copy them to your flash drive.1 point
-
Although I would like to see such information I suspect it is not available. I think the Spindown messages relate to specific events within unRAID, while the Spinups are likely to happen automatically when an access is made to the drive (without an explicit Spinup command being issued). The closest I could see is adding a message to the log on the periodic drive checks when the Spin state is found to be different to the last one logged. Although this may mean the log message is delayed from the actual event happening it would still be useful information.1 point
-
The ones I've seen reported were a bit over 15 hours. on arrays with all 8TB Seagate archive drives.1 point
-
You can, don't forget you need to create the destination folder before doing the restore.1 point
-
Possibly, but keep in mind there have been several reports that linux support is much better in a later kernel than what is currently in unraid. With that in mind, I wouldn't expect much of a positive result until unraid's next update that includes the new kernel. I'm sure limetech has internal builds that they are testing, but don't expect to hear about them. Realistically, I'd say wait for the next round of public unraid beta's before even contemplating a ryzen build unless you are a willing guinea pig.1 point
-
For the future follow the FAQ instructions to remove a cache device, much safer. For now your best bet is probably to try an mount it read only, copy all data and format: mkdir /x mount -o recovery,ro /dev/sdX1 /x Replace X with actual device1 point
-
Funny enough, though I have other issues with my board (and others have the same as well) with false temp sensor events and fans spinning to max on their own, I have no problems using the Marvell SE9230 controller. I have all 4 Marvell ports connected, and am running 2 VMs, and haven't had an issue yet... I should mention that one of my drives *did* just drop out of the array this morning, but I was messing around in there yesterday and may have jostled a cable (haven't had time to confirm which controller the drive was attached to)...1 point
-
Yes, Avoid the Marvel ports. Its a known issue that they go a little crazy if you have visualization enabled. Its discussed here:1 point
-
@Positivo58's issue is solved, as it turns out it was an issue with the VLAN/network setup preventing PMS from pulling the Plex token initially.1 point
-
Solved it today. Did some more searching around, trying to use virtfs etc to get some more data about what is happening. Didn't progress so much with that, buy while reading about different solutions to this type of problem, I found out that having your free disk space reduced below a certain point could create issues with VMs running that would instantly pause them without any appropriate messages whatsoever. It seemed a bit strange as my VMs have all their disk size (40GB each) pre-allocated, but the problem is with the amount of free space the system uses for this operation. People had issues with those files being on Cache Disks which, when dropped below a certain point, could cause this. My problem was a bit more obvious, if you knew where to look ofc. The drive hosting the VMs, and I suspect hosting other files for this reason, dropped to the amazing 20,5KB of free space. Which was strange as I had stopped all writes on this disk at 50+GB. That nice docker I have, which is a Minecraft server for the kids, ended up eating up all available free space due to daily backups. Clearing that space and returning the disk to 50+ free GB allowed my VM to start correctly. I can't tell you how nice it is to hit F5 and have the Web GUIs running on that VM to actual no say something rude to me... I hope this situation is also helpful to someone else to, especially you ashman70 I will change the topic to solved, and I hope it stays like that1 point
-
No, they are both exactly the same size. All you would need to do is ... (a) Do a parity check to confirm all is well before you start. (b) Swap the parity drive and wait for the rebuild of the new drive (the WD Red) (c) Do a parity check to confirm that went well. (d) Now add the old 8TB shingled drive to your array. If you haven't seen any issues with the shingled drive, it's probably not really necessary to make this switch; but it IS true that if you are ever going to hit the "wall" of performance with the shingled drive (i.e. a full persistent cache), that it's most likely this will be on the parity drive. The conditions that would make this likely are a lot of simultaneous write activity by different users. If that never happens with your use case, you're probably okay to just leave well enough alone. I agree, however, that the WD Reds are clearly better drives -- both because they're not shingled, but also due to the helium sealed enclosure, which results in lower power draw and lower temps.1 point
-
I copied 6TB from a 8TB Archive (ST8000AS0002) to a 8TB NAS (ST8000VN002) and saw a consistent 180-200MB/s for the whole transfer (using Intel H170 SATA, running Win10Pro). I've never seen inconsistent read performance like that. I have to say, have no regrets in buying the Archive drives, they're quiet, fast and run cool. So far, the pair I have given flawless performance for well over a year. They're also the original Archive v1 drive, so aren't even as good as the ST8000AS0022 Archive v2 units.1 point
-
I regularly do a single write of 100 -120 GB of data at a time, no speed issues at all, with "reconstruct write" on I nearly always max out the Gigabit connection, it occasionally drops from 113MB/s to 90MB/s. I have 11 of these shingled drives in the server, 2 of them are parity.1 point
-
You apparently haven't read about the mitigations Seagate has incorporated into these drives to offset the potential issues with shingled technology. These are outlined in some detail in the 2nd post in this thread -- the most relevant fact vis-à-vis typical UnRAID usage is "... If you're writing a large amount of sequential data, you'll end up with very little use of the persistent cache, since the drives will recognize that you're writing all of the sectors in each of the shingled zones. There may be a few cases where this isn't true - but those will be written to the persistent cache, and it's unlikely you'll ever fill it." So the performance "wall" you'll hit with shingled drives simply isn't likely with typical UnRAID usage. Note that both danioj and ashman70 have VERY large arrays and have been using these drives for well over a year and had NO issues with them. There are many other users who have had similar experiences -- and virtually NO reports of any significant write performance issues. Correct => this is the performance "wall" I referred to. But the simple fact is that actual users of UnRAID who are using these drives have NOT found this to be an issue. Remember that most UnRAID users write a lot of LARGE media files ... and these files simply won't be using the persistent cache, but will be written directly to the shingled area, so there's no performance "hit" with these files. Agree -- and if these were priced the same as PMR drives, I'd definitely recommend using the non-shingled units. But many folks are price sensitive -- and at $233.88 for an 8TB Seagate Archive drive vs. $310.97 for an 8TB WD Red drive (current Amazon prices for both) it can make a significant difference in the cost of populating an array => e.g. $770 difference if you're buying 10 drives. ... and of course there's NO difference in read performance.1 point
-
Are you both confirming that following testing of the drive for infant mortality things were fine and then a Parity Check killed the drive? Can you post the evidence to support these claims we can view? I only ask as I assume you would have collected this to support your RMA claim and it is of benefit to the community. As for reliability I have empirical evidence that these drives in good health are indeed an excellent choice for use with unRAID. I have these running in my Backup Server - an all Seagate Shingled 8TB drive array (single Parity). Running alongside my Main Server - an all WD Red 3TB drive array + 1 x 8TB data and 1 8TB Data (Single Parity). This setup has been running PERFECT 24x7 now for ~: 1y, 3m, 24d, 8h In addition to the evidence I collected at the beginning of this journey (please read initial posts) here is some in life data: Parity History for Backup Server: 2016-10-01, 19:04:53 19 hr, 4 min, 52 sec 116.5 MB/s OK 2016-09-21, 01:07:39 23 hr, 14 min, 18 sec 95.6 MB/s OK Aug, 01, 16:25:46 16 hr, 25 min, 42 sec 135.3 MB/s OK Jul, 01, 15:51:40 15 hr, 51 min, 37 sec 140.1 MB/s OK Jun, 01, 17:47:45 17 hr, 47 min, 41 sec 124.9 MB/s OK May, 01, 18:53:44 18 hr, 53 min, 40 sec 117.6 MB/s OK Apr, 05, 12:47:54 16 hr, 15 min, 19 sec 136.7 MB/s OK Apr, 03, 08:02:32 16 hr, 39 min, 57 sec 133.4 MB/s OK Mar, 01, 15:55:59 15 hr, 55 min, 55 sec 139.5 MB/s OK Feb, 10, 01:36:07 1 day, 3 hr, 57 min, 1 sec Parity History for Main Server: 2016-10-01, 20:18:02 19 hr, 48 min, 1 sec 112.3 MB/s Aug, 01, 18:47:49 18 hr, 17 min, 47 sec 121.5 MB/s Jun, 01, 19:29:00 18 hr, 58 min, 56 sec 117.1 MB/s May, 01, 23:10:57 22 hr, 40 min, 52 sec 98.0 MB/s Apr, 05, 15:26:53 18 hr, 54 min, 20 sec 117.6 MB/s Apr, 01, 19:39:23 19 hr, 9 min, 19 sec 116.0 MB/s Mar, 01, 19:57:13 19 hr, 27 min, 9 sec 114.3 MB/s Feb, 01, 18:44:41 18 hr, 14 min, 36 sec There are a few spikes due to load. I run my daily backups at 3am (3 hours after a Parity Check has begun) and I don't stop the backups when this Check is running. My backup is going from Main -> Backup Server via a SyncBack managed compare, copy then verify. I have had 2 instances of a need for rebuilding a drive over the year in this setup: 3TB drive on Main Server: 9 hr, 24 min, 40 sec 8TB drive on Backup Server: 15 hr, 59 min, 10 sec Nothing wrong here.1 point
















