Leaderboard




Popular Content
Showing content with the highest reputation on 06/08/18 in all areas
-
He was wondering if Limetech quit which would explain why the forums were so quiet, but that is not quite the case and they were just moving. ?6 points
-
Installation and Bug Reporting Instructions Getting back in the saddle after a move which took far longer than it should have... This is a small update to bring us up-to-date with the latest LTS kernel and fix a handful of bugs. Let's test this over the weekend and release 6.5.3 stable on Monday along with 6.6.0 next soon thereafter. Version 6.5.3-rc2 2018-06-08 Linux kernel: version 4.14.48 Management: Small update to create_network_ini to suppress progress information when using cURL. update smartmontools drivedb and hwdata/{pci.ids,usb.ids,oui.txt,manuf.txt} webgui: Remove unused tags from docker templates webgui: apcups: ensure numeric fields are 0 if the values are empty webgui: bug fix: prevent deleting user template when (letter case) renaming a docker container webgui: Strip HTML from back-end webgui: make entire menu items clickable for gray and azure themes Version 6.5.3-rc1 2018-05-18 Summary: In order to fix VM startup issue we need to change the linux kernel preemption model: CONFIG_PREEMPT=no (previous setting) This option reduces the latency of the kernel by making all kernel code (that is not executing in a critical section) preemptible. This allows reaction to interactive events by permitting a low priority process to be preempted involuntarily even if it is in kernel mode executing a system call and would otherwise not be about to reach a natural preemption point. This allows applications to run more 'smoothly' even when the system is under load, at the cost of slightly lower throughpu and a slight runtime overhead to kernel code. Select this if you are building a kernel for a desktop or embedded system with latency requirements in the milliseconds range. CONFIG_PREEMPT_VOLUNTARY=yes (new in this release) This option reduces the latency of the kernel by adding more "explicit preemption points" to the kernel code. These new preemption points have been selected to reduce the maximum latency of rescheduling, providing faster application reactions, at the cost of slightly lower throughput. This allows reaction to interactive events by allowing a low priority process to voluntarily preempt itself even if it is in kernel mode executing a system call. This allows applications to run more 'smoothly' even when the system is under load. Select this if you are building a kernel for a desktop system. Linux kernel: version 4.14.41 set CONFIG_PREEMPT=no and CONFIG_PREEMPT_VOLUNTARY=yes2 points
-
Just do whatever it takes to get an RMA for the drive. (I won't bother with reporting a specific SMART failure.) The few drives that I have had to RMA over the years, the replacement drive has always shipped the same day as the drive was received. (Knowing how Receiving Docks work, this is too short a time to do anything but log the shipment's receipt.) They will run an assessment of the drive at some point in the future. However, they know that they will get a percentage of drives back that will be good. They also realize that deciding to RMA a drive is not a causal decision on the part of the customer. (In fact, he is probably already pissed!) So, in the interest of good customer relations, they accept it as a cost of doing business and chalk the expense up to 'Good Customer Relations'.2 points
-
There are several things you need to check in your Unraid setup to help prevent the dreaded unclean shutdown. There are several timers that you need to adjust for your specific needs. There is a timer in the Settings->VM Manager->VM Shutdown time-out that needs to be set to a high enough value to allow your VMs time to completely shutdown. Switch to the Advanced View to see the timer. Windows 10 VMs will sometimes have an update that requires a shutdown to perform. These can take quite a while and the default setting of 60 seconds in the VM Manager is not long enough. If the VM Manager timer setting is exceeded on a shutdown, your VMs will be forced to shutdown. This is just like pulling the plug on a PC. I recommend setting this value to 300 seconds (5 minutes) in order to insure your Windows 10 VMs have time to completely shutdown. The other timer used for shutdowns is in the Settings->Disk Settings->Shutdown time-out. This is the overall shutdown timer and when this timer is exceeded, an unclean shutdown could occur. This timer has to be more than the VM shutdown timer. I recommend setting it to 420 seconds (7 minutes) to give the system time to completely shut down all VMs, Dockers, and plugins. These timer settings do not extend the normal overall shutdown time, they just allow Unraid the time needed to do a graceful shutdown and prevent the unclean shutdown. One of the most common reasons for an unclean shutdown is having a terminal session open. Unraid will not force them to shut down, but instead waits for them to be terminated while the shutdown timer is running. After the overall shutdown timer runs out, the server is forced to shutdown. If you have the Tips and Tweaks plugin installed, you can specify that any bash or ssh sessions be terminated so Unraid can be gracefully shutdown and won't hang waiting for them to terminate (which they won't without human intervention). If you server seems hung and nothing responds, try a quick press of the power button. This will initiate a shutdown that will attempt a graceful shutdown of the server. If you have to hold the power button to do a hard power off, you will get an unclean shutdown. If an unclean shutdown does occur because the overall "Shutdown time-out" was exceeded, Unraid will attempt to write diagnostics to the /log/ folder on the flash drive. When you ask for help with an unclean shutdown, post the /log/diagnostics.zip file. There is information in the log that shows why the unclean shutdown occurred.1 point
-
I'm at a loss, and could really use help troubleshooting this issue. I have two unRAID servers on my home network, both running version 6.3.5, both configured with static IP addresses. I'm using basic WORKGROUP setup for windows networking, not a Domain or Active Directory. (I'll refer to my older server as Server A and my newer one as Server B) Server A = AMD Athlon, 8GB RAM, 16TB, no Docker or VMs configured Server B = Core i5 4950, 24GB RAM, 20TB, no Docker, KVM is hosting one vm I have one Windows 10 Pro x64 client is running as a pass-through VM on Server B. That VM just auto-updated from Windows 10 v1703 to v1709 (Fall Creator's update). I've been able to access both servers via server name or IP address from any Windows machine or VM on my network for some time. From that VM only, I'm seeing weird behavior trying to browse files in Windows Explorer. I cannot ping either server by machine name. I cannot browse files on either server by machine name I can ping both Server A and Server B by IP address. I can browse files on Server B by IP address. I cannot browse files on Server A by IP address I get Error Code 0x80004005, Unspecified Error From other machines on my network, both Windows 10 v1703 and Windows 7, I can browse files by name or IP address just fine. If I change the static IP assignment on Server A (say from x.68 to x.168), I can browse files by IP address from the VM. If I change that static IP back to its original value, I can't browse files by IP address. I've tried resetting the network settings (netsh int ip reset c:\resetlog.txt) I've tried updating the VM's network driver, using the latest RedHat KVM drivers (virtio-win-0.1.141.iso) I've tried switching which unRAID server is set up as the WINS master browser. I've entirely disabled the Windows Firewall and my AVAST antivirus software. I've tried clearing the DNS and WINS caches using these Windows commands ipconfig /flushdns nbtstat –R ______________________________ After searching for hours, I just found the solution Control Panel\User Accounts\Credential Manager I deleted all saved credentials for that server, every entry, listed by server name and by IP address. After removing those saved credentials, I can browse the server again. I'm going ahead and posting this for documentation, in case anyone else runs into a similar issue. <edit - corrected references to Windows 10 v1703, and corrected typo in title>1 point
-
I would like to see a login page like nextcloud has or any of the docker pages have. The unraid webui is standard https login popup. The real reason is I use LastPass and I can't save a password or load it in with the https popup. But it would make unraid look a bit nicer a proper login screen. Maybe an opportunity to load some info on the login screen as well.1 point
-
Installation and Bug Reporting Instructions This is a somewhat unusual release, meaning vs. 6.5.2 stable we only updated the kernel to latest patch release, but also changed a single kernel CONFIG setting that changes the kernel preemption model. This change should not have any deleterious effect on the server, and in fact may improve performance in some areas, certainly in VM startup (see below). However, we want to make this change in isolation and release to the Community in order to get testing on a wider range of hardware, especially to find out if parity operations are negatively affected. The reason we are releasing this as 6.5.3 is because for upcoming unRAID OS 6.6 we are moving to the linux 4.16 kernel and will also be including a fairly large base package update, including updated Samba, Docker, LIbvirt and QEMU. If we released this kernel CONFIG change along with all these other changes, and something is not working right, it could be very difficult to isolate. Background: several users have reported, and we have verified, that as the number of cores assigned to a VM increases, the POST time required to start a VM increases seemingly exponentially with OVMF and at least one GPU / PCI device being passthrough. Complicating matters, the issue only appears for certain Intel CPU families. It took a lot of work by @eschultz in consultation with a couple linux kernel developers to figure out what was causing this issue. It turns out that QEMU makes heavy use of a function associated with kernel CONFIG_PREEMPT_VOLUNTARY=yes to handle locking/unlocking of critical sections during VM startup. Using our previous kernel setting CONFIG_PREEMPT=yes makes this function a NO-OP and thus introduces serious, unnecessary locking delays as CPU cores are initialized. For core counts around 4-8 this delay is not that noticeable, but as the core count increases, VM start can take several minutes(!). We are very interested in seeing reports regarding any performance issues not seen in 6.5.2 release. As soon as we get this verified, we'll get this released to stable and get 6.6.0-rc1 out there. Thank you!! Version 6.5.3-rc1 2018-05-18 Summary: In order to fix VM startup issue we need to change the linux kernel preemption model: CONFIG_PREEMPT=no (previous setting) This option reduces the latency of the kernel by making all kernel code (that is not executing in a critical section) preemptible. This allows reaction to interactive events by permitting a low priority process to be preempted involuntarily even if it is in kernel mode executing a system call and would otherwise not be about to reach a natural preemption point. This allows applications to run more 'smoothly' even when the system is under load, at the cost of slightly lower throughpu and a slight runtime overhead to kernel code. Select this if you are building a kernel for a desktop or embedded system with latency requirements in the milliseconds range. CONFIG_PREEMPT_VOLUNTARY=yes (new in this release) This option reduces the latency of the kernel by adding more "explicit preemption points" to the kernel code. These new preemption points have been selected to reduce the maximum latency of rescheduling, providing faster application reactions, at the cost of slightly lower throughput. This allows reaction to interactive events by allowing a low priority process to voluntarily preempt itself even if it is in kernel mode executing a system call. This allows applications to run more 'smoothly' even when the system is under load. Select this if you are building a kernel for a desktop system. Linux kernel: version 4.14.41 set CONFIG_PREEMPT=no and CONFIG_PREEMPT_VOLUNTARY=yes1 point
-
The IT world is full of black magic. Until you know what happens it can be almost impossible to figure out the almost random outcomes. And as software developer, it isn't always possible or practical to catch and hide all the strange magic from end users. In the end, we'll just have to help each other.1 point
-
So, yesterday I had the honor of speaking to Dmitry via hangouts to help me diagnose my feeble attempt at installing his docker... Now mind you that on the 10 scale of computer background I am currently at a 4.7 but Dmitry was able to push that to a 5. So here is the questions I had and how I decrypted them into something a novice like me could understand. I had issues with IP addresses ave how they relate with my home network. Q: "should I change the routing manager to reflect my internal IP" A: no, ZT creates a fake network internally for use of network. If your home IP range is 192.168.1.0/24 then the routing manager in ZT will create an IP range ( see top left of your network manager) and that will be what's signed to your off network device. So mine would be 172.xxx.xxx.0/24 and that range is I would use to access my drives and servers at home. Once I understood this, the dim lightbulb sparked back to life and everything else fell into place! Thanks Dmitry for your time1 point
-
Search unraid msi audio fix1 point
-
I saw that. I'll push an update to the docker container soon.1 point
-
Disk6 has a lot of UDMA CRC errors, unless these are old errors it points to a bad connection, most likely a bad SATA cable.1 point
-
It's sometimes possible to get into troubles because of differences in line endings between Linux and Windows. Windows uses a two-character sequence (carriage return + line feed) while Linux just uses the second character. This means it's possible to paste a carriage return from the windows machine that ends up as a hidden character at the end of the pasted command. And then follows the line feed that Linux sees as the real end of the line. So your command could end up as: btrfs fi df /mnt/cache^r where ^r is that hidden carriage return character. And btrfs can then treat this hidden character as an additional character belonging to the mount path. If the above is what happens, then it can make a difference how you make your copy/paste selection on the Windows side. When using the mouse to mark things for copying on Windows, it can often be a good idea to start from the right hand side of the line to copy and mark to the left. Then you avoid the selection logic in the program from also including the line ending in the selection. A number of programs will include the line ending when you select from left-to-right. You'll notice because directly when you paste on the Linux command line, Linux will execute the pasted line instead of waiting for you to press enter.1 point
-
type "cat /dev/sda > /dev/null" and look for which drive lights up. There is also a script here that will work.1 point
-
I'd like something like this. Both to easily reuse Docker Compose setups, but also to be able to group applications together in the Unraid UI. Atm it feels like Unraid promotes bad Docker practice by making it way easier bundling all the services of an app in a single container instead of doing one service per container. If the GUI supported making apps consisting of several containers it would be easier to work with the general best practices. Depending on the UI novice users might not even have to worry about how many containers the app consists of.
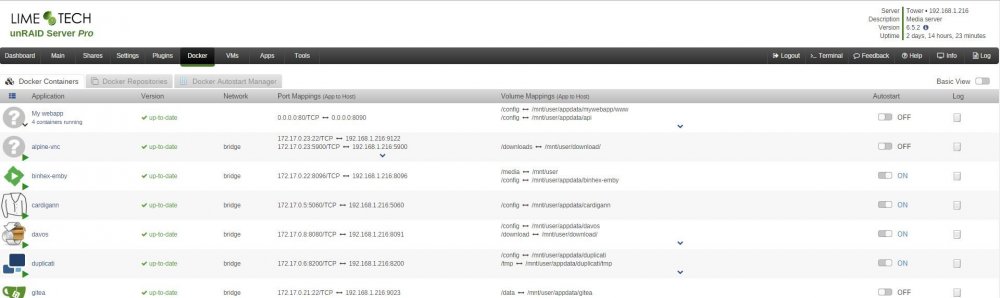
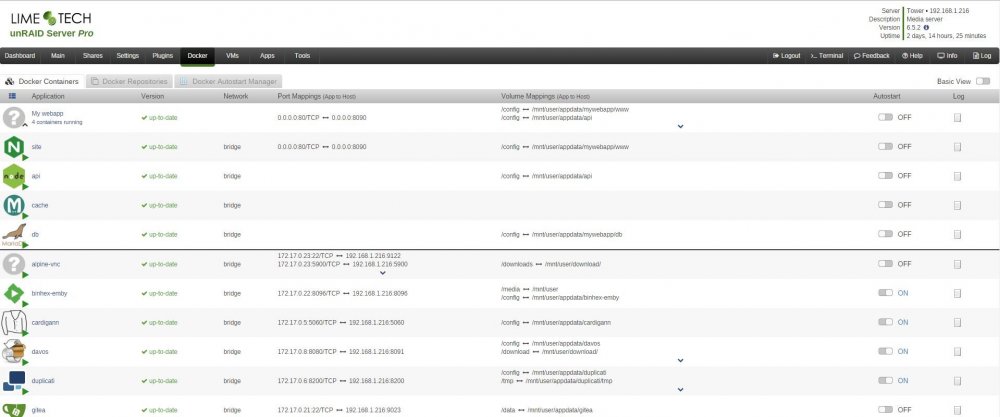 1 point
1 point -
There are a lot of issues with SMB that can rise up and bite you. Here are several that were discussed a few years back: https://forums.lime-technology.com/topic/25064-user-share-problem/?tab=comments#comment-228392 Be sure to read the next few posts as a couple of other ones follow. (SMB is Kludge based on a simple networking scheme conceived for Windows for Workgroups 3.1 OS for connecting a small number of computers that would work without a dedicated server where the security was not a concern. I suspect you could still connect one of those old computers to a modern SMB network and it would still work! I remember building a SMB network using 10base2 hardware to use in my original setup. For security, we used NetBIOS for the network and TPC/IP for the dialup modems.)1 point








