Leaderboard



Popular Content
Showing content with the highest reputation on 08/19/18 in all areas
-
Probably in a week. QEMU 3.0 was just released so we'll get that in to the public unRAID 6.6-rc release too.3 points
-
I wrote a very basic test program to verify this: #include <stdint.h> #include <unistd.h> #include <fcntl.h> int main() { uint32_t val = 0; int fd0 = open("test1", O_RDWR | O_CREAT); write(fd0, &val, sizeof(val)); close(fd0); while (val < 100000) { uint32_t val2 = 0; int fd1 = open("test1", O_RDWR | O_CREAT); int fd2 = open("test2", O_RDWR | O_CREAT); read(fd1, &val2, sizeof(val2)); close(fd1); val++; val2++; fd1 = open("test1", O_RDWR | O_CREAT); write(fd1, &val2, sizeof(val2)); write(fd2, &val, sizeof(val)); close(fd1); close(fd2); } return 0; } On a normal disk, the resulting "test1" and "test2" files will always contain identical 4-byte integers (100000). We can see this with a hex dump: $ cat test1 test2 | hexdump -C 00000000 a0 86 01 00 a0 86 01 00 |........| However, if the move program is run on test1 while the program runs, we can desynchronize: $ echo /mnt/cache/[path]/test1 | move -d 2 $ cat test1 test2 | hexdump -C 00000000 9f 86 01 00 a0 86 01 00 |........| Note that the two files now differ by 1. Losing writes can result in a lot of unexpected behaviors; I think it might be responsible for corruption I've seen in files downloaded by Transmission, as well as in sqlite databases (I saw corruption in my Plex Media Server database last night that appears consistent with lost writes, and happened about the same time as I ran the mover script). I'm not sure what the best solution for this problem is, as I'm not familiar with the internals of the mover program or the shfs ioctl it uses. One route could be to do the copy to a tmp file on the destination drive, then while holding an internal lock on the file as exposed by fuse, verify that it hasn't changed since the copy started, and only then take the place of the source. Alternately, while a file is being moved, shfs could expose it to userspace such that reads come from the source file, but writes go to both the source and the destination.1 point
-
There was a typo "install" needs to be after "plugin"1 point
-
I heared it c an come to sound problems like stuttering when you dont use the correct pairs.1 point
-
I bet it will be, that is until you get your Ryzen upgrade then it will seem like, "night and day." It's a good question, won't really know until you try. There's a bit of extra latency (benchmark scores) when HT isn't paired with its core but other than that, none I'm aware of.1 point
-
And I would assume that everyone in the Complex uses the same SSID and PassPhase. That means that everyone in the Complex can access your unRAID server shares using whatever security settings you have on those shares. If they are public. they can browse, read and write and write (and delete) the files. How well do you know and trust your neighbors? You can test this by looking for other SSID's in the Complex using a portable device. If you only find one, you can be sure that this is the case. For you to be truly secure there should be one for each Apartment... And I not even considered, the person sitting in a car outside of the Complex who has (somehow) learned/discovered the PassPhase. It is far more profitable to have this Passphase than to a normal Home router/WiFi setup because the increased number of users. There is much more likelihood that someone has something really worth gaining access to. I have no doubt that you are protected by a NAT at the WAN level. And granted many of your devices (including Laptops) are protected because the manufacturer assumed in many cases that you would using Internet access on 'Public' networks but this is not the case for your unRAID server. It is low hanging fruit ready for plucking. You really need protection on the Complex's LAN level.1 point
-
Since the rebuild is going to take a while and I'm going on vacation for a couple of weeks later today, this is what I would like you to try if when running xfs_repair -v on disk6 you get an error like this: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Start the array in maintenance mode, then on the console type: mkdir /x mount -vt xfs -o noatime,nodiratime /dev/md6 /x If it mounts see below, if it doesn't try: mount -vt xfs /dev/md6 /x If it mounts with 1st or 2nd option now unmount: umount /x And run xfs_repair again: xfs_repair -v /dev/md6 If it doesn't mount with either option use -L xfs_repair -vL /dev/md61 point
-
The command "plugin xxx" says - use the first command named "plugin" found in the search path. So if there are multiple programs named "plugin", then you aren't in control of exactly which of them that is run. And if the command "plugin" is installed in a directory that isn't in the search path, then the command fails. The command "/usr/local/sbin/plugin xxx" names a very specific program "plugin" by giving a fully qualified name.1 point
-
Can someone explain briefly what the difference is please as using 'plugin install' has 'worked' perfectly fine for me. Should I be using this command?1 point
-
Many better PSU allows a significant short-term overload - the switch transistors etc can handle quite a lot of current to handle load spikes but it's mostly the cooling that specifies the maximum allowed load. And since the PSU power components and fitted heatsinks have thermal mass, it takes a while for the temperature to rise high enough that the overload circuits will step in. It's also quite common for both single-rail and multi-rail units that the current overload cut-off is 30-50% over the specified current. One reason for allowing short-term overloads is to handle the large current spike on power-on, when all the empty capacitors has to be charged. Some of this inrush current is handled by slow-start features where the PSU ramps up the voltages. But even with slow-start, the initial current can be quite significant. The following review tested the RM850 at 110% load with proper function - so the PSU obviously does not instantly shuts down. It does have over-power protection, but it seems +10% isn't enough to trig that protection. If overloading a single rail, they could most probably have run at way more than 10% overcurrent without shutdown - at least for a limited time until the thermal protection steps in. https://www.techpowerup.com/reviews/Corsair/RM850/5.html In the end, it's normally the thermal protection that will make a PSU shutdown on overload - the short-circuit protection normally steps in at a very large overcurrent.1 point
-
Recommended is: /usr/local/sbin/plugin https://raw.githubusercontent.com/Waseh/rclone-unraid/master/plugin/rclone.plg1 point
-
LT is onto it1 point
-
Change it to /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin install https://raw.githubusercontent.com/Waseh/rclone-unraid/master/plugin/rclone.plg1 point
-
Yes, I think it will. Many in the unRAID community have done something like this, including myself. Feel free to click on my signature link, I go over the configuration of my own system there. The idea is the same as with the RAM, allocate some to the VM's and leave a cpu core, maybe two, to unRAID. Since you have eight threads what I would do is allocate two, or three, threads to each VM and leave cpu-core 0 and 1 to unRAID. You could also have the VM's drives be image files, in which case you wouldn't have to assign an ssd and/or HD to each VM. You could even setup your Steam library as a network share in Windows - not sure how VAC would like that though (I had some issues with ARK's anti-cheating software when I had it installed on a network drive share). Here's a link where Jonp goes over how this is done in unRAID; and yes, you could run two instances of a game at the same time, one on each VM. unRAID doesn't have to have it's own GPU, it could be run "headless" if you're prepared to do the maintenance from either a setup VM or from a remote system (such as a laptop or second desktop). unRAID uses the primary GPU as its own, but a VM can take that away, from unRAID, and use it for a VM. Now, if your GTX1050ti is your primary GPU you might get a black screen passing through video - which is an indication you might need to pass through the video card bios. How to dump your vbios (I prefer this way) How to get GPU working without dumping vbios (other community members have liked this way) I hope I've answered and clarified everything; if not ask away. Have a good day.1 point
-
This is a user mis-configuration issue highlighted by the latest commit, so you have STRICT_PORT_FORWARD set to 'yes', what this does is it enables code to try and get an incoming port from PIA, it will attempt to do this, if it cant get a port forward then it will retry (pia can be a bit unreliable at times and thus the need for retries). The problem you have is that PIA endpoint Netherlands no longer supports port forwarding, and as the ovpn file you are using is pointing at the Netherlands it will fail to get a port forward and thus you are stuck in the retry loop. So how do you fix this?, two options:- 1. switch endpoint to one that does enable port forwarding (recommended solution) - if you want to do this then go here to see the current list of port forward enabled endpoints, then download the ovpn zip pack from here unzip it and place the corresponding port forward enabled endpoint ovpn file in /config/openvpn/ and restart the container. or (do not do both options) 2. set STRICT_PORT_FORWARD to 'no' (NOT recommended) - whilst this is an easier option to the above as you dont need to switch endpoint, it will result in you not getting an incoming port and thus your torrent downloads will be very slow, but the option is there if you want it. @repentharlequin @glennv i would assume you have the same issue and thus the above is the solution for you too.1 point
-
The Template has been updated and pushed .... Check for updates in the next few hours. Welcome to v4! (if it didn't update for you, change the repository to: pihole/pihole:latest )1 point
-
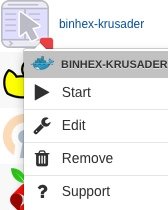
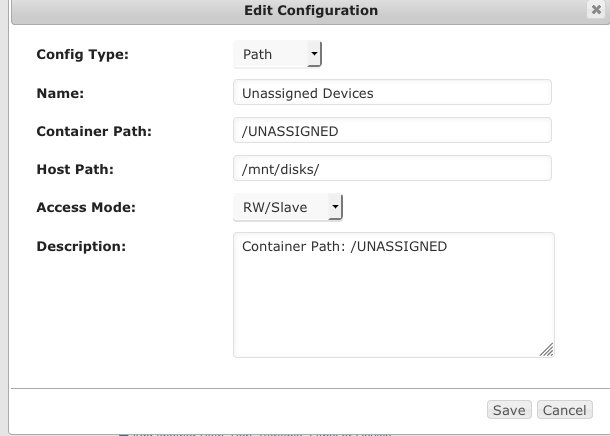
Go to the Docker tab. Find the Binhex-Krusader in the Dockers list. Click on it (see picture below) and select "Edit". The Binhex-Krusader Docker edit screen pops up. Go down the list until you see the /mnt/disks/ for the container path for unassigned. Click the "Edit" button to the right of it. The details pop-up for the unassigned devices paths. Go down the list to "Access Mode" and change that to "RW/Slave" and then save.

 1 point
1 point -
A NFS share of a user share /mnt/user/Test 192.168.2.0/24(rw,async,wdelay,hide,no_subtree_check,fsid=110,sec=sys,secure,root_squash,no_all_squash) can be mounted by a client for rw access, but completely ignores the permissions. [root@centos user]# mount mediastore:/mnt/user/Test /mnt/user/Test [root@centos user]# ls -ld Test drwxrwx---. 1 nobody users 20 Jun 20 08:27 Test [root@centos user]# cd Test [root@centos Test]# touch a [root@centos user]# ls -l a -rw-r--r--. 1 nfsnobody nfsnobody 0 Jun 20 08:27 a [root@centos Test]#1 point
-
To upgrade: If you are running any 6.4 stable release or any 6.4-rc/6.5-rc release, click 'Check for Updates' on the Tools/Update OS page. If you are running a pre-6.4 release, click 'Check for Updates' on the Plugins page. If the above doesn't work, navigate to Plugins/Install Plugin, select/copy/paste this plugin URL and click Install: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer.plg Refer also to @ljm42 excellent 6.4 Update Notes which still are helpful if you are upgrading from a pre-6.4 release. This is another security and bug fix release, with yet more cool improvements by @bonienl among which are: The context menu for a running docker container now includes a function to open a terminal window for the container console, very handy! You can rearrange the start order of containers by dragging the rows up and down. Add 'Advanced/Basic View' for 'Main/Boot Device/Flash/Syslinux configuration'. Very nice. Make the 'SMB extra' text box auto-resize. Several styling improvements. In addition, github user 'shayne' added support for "Docker Labels". In his words: Finally, this release includes new microcode from Intel. Here are their changes vs. the 20180312 microcode release: == 20180425 Release == -- Updates upon 20180312 release -- Processor Identifier Version Products Model Stepping F-MO-S/PI Old->New ---- updated platforms ------------------------------------ GLK B0 6-7a-1/01 0000001e->00000022 Pentium Silver N/J5xxx, Celeron N/J4xxx ---- removed platforms ------------------------------------ BDX-ML B/M/R0 6-4f-1/ef 0b000021 Xeon E5/E7 v4; Core i7-69xx/68xx -- Special release with caveats -- BDX-ML B/M/R0 6-4f-1/ef 0b00002c Xeon E5/E7 v4; Core i7-69xx/68xx The "Special release with caveats" means that the firmware should only be loaded when using kernels with certain sets of patches installed. We have checked and verified that all specified patches are included with the kernel in this release (4.14.40). Due to security updates all users are encouraged to update. Version 6.5.2 2018-05-15 Base distro: Replace lxterminal with sakura version 3.5.0 intel-microcode: version 20180425 mozilla-firefox: version 60.0 (CVE-2018-5150, CVE-2018-5151, CVE-2018-5152, CVE-2018-5153, CVE-2018-5154, CVE-2018-5155, CVE-2018-5157, CVE-2018-5158, CVE-2018-5159, CVE-2018-5160, CVE-2018-5163, CVE-2018-5164, CVE-2018-5165, CVE-2018-5166, CVE-2018-5167, CVE-2018-5168, CVE-2018-5169, CVE-2018-5172, CVE-2018-5173, CVE-2018-5174, CVE-2018-5175, CVE-2018-5176, CVE-2018-5177, CVE-2018-5180, CVE-2018-5181, CVE-2018-5182) php: version 7.2.5 (CVE-2018-10545, CVE-2018-10546, CVE-2018-10547, CVE-2018-10548, CVE-2018-10549) smartmontools: update drivedb and hwdata/{pci.ids,usb.ids,oui.txt,manuf.txt} Linux kernel: version 4.14.40 added driver: CONFIG_PATA_SIL680: CMD / Silicon Image 680 PATA support Management: webgui: Fixed calculation of next custom parity schedule webgui: Suppress Docker PHP error if container has no ports exposed or utilized webgui: Docker skip hidden files when listing directories webgui: Adjusted TAB color styling for all themes webgui: Added branch type to previous version webgui: Suppress auto generated hyperlinks by MS Edge webgui: Docker: added pause/resume commands & container console window webgui: Added: Docker Pause/Resume all Containers buttons webgui: Make sorting of Docker and VM list draggable webgui: Fixed column count in Docker container list webgui: CSS correction VM list for themes white and black webgui: Add class A (/8) network mask webgui: Smart syslinux configuration webgui: Syslinux config: basic and advanced mode webgui: Make SMB extra auto sizeable webgui: Add support for Docker Labels to Docker plugin webgui: Add release notes to version string in header webgui: Fixed incorrect display of memory size on dashboard Memory size is incorrectly displayed when a parity check is running webgui: Fixed regression error in docker_cfg file webgui: Minor style adjustment for Docker containers and VMs1 point
-
Alternately you could have used the chown command on the folder to reassign i believe the docker setting in binhex-plexpass has PUID settings and GUID setting for setting permissions too1 point
-
Me again, this was a permission issue on the main folder create under cache. I deleted the binhex-plexpass folder and recreated the docker instance. Boom, got it.1 point
-
To my best knowledge and from everything I have read these messages are purely debug only, they are not errors. What settings are not saving? this could all be due to the fact rutorrent does NOT modify tTorrent settings. I well be cranking down the logging which will stop these messages filling the log Sent from my LG-V500 using Tapatalk It reverts many settings from the GUI back to default everytime I restart the docker, and also loses track of where the torrents were moved to. They are all on pause until I "save as" to the right place without checking the move files box, then I need to recheck the files and then I can start them again. Currently I have to uncheck DHT and Peer everytime, change the port, and also adjust the default download directory after every restart. It seems like a few settings that were set on first start stay, but some don't. If there is any way I can log the stopping of the docker to see if there are any write error of some sort, that would be great ok so some of your issues are due to a misunderstanding as to what rutorrent can and cannot do (by design). So rutorrent is purely a web frontend to rtorrent, and as such does NOT modify any settings, the only settings you can save using rutorrent are settings for rutorrent itself, i.e. things like enabling/disabling plugins, settings for plugins etc. If you want to modify things like incoming port, enabling/disabling dht, and folders for incomplete/complete downloads then you will have to modify the rtorrent config file, this is located in /config/rtorrent/config/rtorrent.rc please make sure you use something like notepad++ (not notepad) to prevent windows line endings getting added.1 point
-
A slightly better way to maintain the keys across reboots is to * copy the authorized_keys file to /boot/config/ssh/root.pubkeys * copy /etc/ssh/sshd_config to /boot/config/ssh * modify /boot/config/sshd_config to set the following line AuthorizedKeysFile /etc/ssh/%u.pubkeys This will allow you to keep the keys on the flash always and let the ssh startup scripts do all the copying.1 point
-
reserved1 point
-
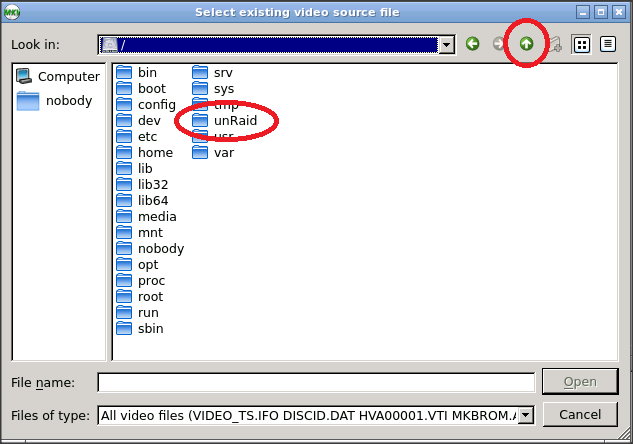
You are almost there….! The folder you are looking for is unRaid. That folder is mapped to your folder Q located in the share called Other. So just browse for the unRaid folder in the MakeMKV file dialogue.
 1 point
1 point


















