Leaderboard




Popular Content
Showing content with the highest reputation on 02/01/19 in all areas
-
sorry guys my screw up, forgot to change path for jellyfin data env var, its fixed now and is building a new image, sadly this will of course mean that when you pull the new image down it will re-create the container and thus you will looose any config (as its currently incorrectly located in the container).5 points
-
New image seems to be working as intended and can see appdata folder being populated as expected, thanks!2 points
-
Overview: Support for Docker image arch-jellyfin in the binhex repo. Application: Jellyfin - https://github.com/jellyfin/jellyfin Docker Hub: https://hub.docker.com/r/binhex/arch-jellyfin/ GitHub: https://github.com/binhex/arch-jellyfin Documentation: https://github.com/binhex/documentation If you appreciate my work, then please consider buying me a beer 😁 For other Docker support threads and requests, news and Docker template support for the binhex repository please use the "General" thread here1 point
-
Good day. New to Unraid and enjoying the learning. I built an Asrock x470itx with a Ryzen 2700x. My first build ! Picked the parts based on...... ordered them and then started reading about the lock ups Anyway, took me 2 days to work out how to plug everything and get it up and running. Whilst updating the MOBO bios, I decided that it made sense to set up the RAM frequency, since it was stated in the package and I was there........ Plugged Unraid and started running; whilst executing pre-clearing the server would drop about every 4 hours. To summarise, I tried every CPU setting in the bios with no success; until in the end I remembered fiddling with the RAM frequency... Put it back in Auto, which I should have never touched and surprise, surprise..... server running without problem for 2 straight days. Perhaps my outcome may have been obvious, but since no doubt there are many more newcomers like me, I thought worthwhile sharing this experience.1 point
-
Time Machine will prune itself automatically. There shouldn’t be any need for manual pruning.1 point
-
No worries. This is what Day 1 software is all about. Will the new image be available shortly?1 point
-
yes, some. depends on your drives. writing to ssd cache is at ssd speed for me via 10gbe (mellanox to solarflare.) reading from array is whatever that drive can sustain, which for some spinning discs is greater than gigabit. also if you're serving multiple clients that exceed gigabit then it is handy.1 point
-
Correct. This is currently not possible. Correct. No need for a wildcard certificate. You just need to have a DNS name for each application, like app1.example.com, app2.example.com, etc. LE will generate a certificate for each of them. It may be better to just add a cname for each DNS name you need. Else, every subdomain will resolve successfully to your machine...1 point
-
Yes. UD device shares either locally mounted or remote mounted will not show. No. Excluding a share only excludes it on the local server. Remote mounted shares are cannot be excluded because they are mounted on another server. When shares are enabled on the recycle bin, the share is defined with the vfs_recycle that moves files to the .Recycle.Bin folder when they are deleted from the share. This puts files in the recycle bin. When a share is excluded from the recycle bin, no files are moved to the recycle bin when deleted. The contents of the .Recycle.Bin folder on the share will still show in the recycle bin if there are files in that folder, even though no further files will be moved there. To summarize: - When the recycle bin is enabled on a share, it has to be a local device share and files will be moved to the .Recycle.Bin folder when deleted from the share. - The recycle bin size and browsing shows devices with files in the share .Recycle.Bin folder, whether or not the recycle bin is enabled for that share. - Remote mounted devices will show in the recycle bin size and browsing when their .Recycle.Bin folder has content. The only way to turn this off is to not enable UD devices in the recycle bin. - Only local device shares can be excluded from the recycle bin.1 point
-
Don't know how to do that. I'd hit up the support link on the telegraf docker hub page or maybe their github page.1 point
-

From the album: Community Created Banners
1 point -
It could also be the controller, Marvell controllers are known to drop disks without a reason.1 point
-
Update 2019.02.01 - Commit #31 - Improvement: Created a new SHA256 string of static device model name and serial number instead of using LUN. Should now remember devices regardless of controllers. Require a database upgrade (v2). - Commit #29 - BUG: Javascript: Added delay between kill and start/stop to the Locate button, should be more stable now. Thanks to TeeNoodle for debugging and testing.1 point
-
Disk1 isn't responding. Check connections, SATA and power, both ends. Probably nothing wrong with any of the disks. Bad connections are much more common than bad disks. If you had asked to begin with you might have saved yourself from buying 2 disks.1 point
-
It not necessary to hard code anything. Everything works fine for me as is. I have the Default vm bridge set to br0.80. I doesn't really matter what bridge the VMs are on. The default bridge is what matters as it is the interface the script will be listening on. It will be looking for any magic packet. It will then compare the magic packet mac to all the vm macs and start a matching vm. Wol packets have to be broadcast on the same network. Are you setting your Default vm bridge to br0.40 in the Unraid webgui? Are you sending the wol from the br0.40 network? I can send etherwake -i br0.40 vmmacaddress from the server and the vm starts up. The VBMC is command line only for now. You'll have to google how to use it. But basically you assign vms to different ports and then you use ipmi commands/software to send ipmi commands to server.ip:vmport#. You'll need something like my cmdline plugin to save and restore your /root directory on server restart also. All the VBMC settings are saved in /root/.vbmc1 point
-
The VMs are what makes this interesting...you want to reserve cores for those, but running a 10 stream plex server can quickly much them even in a 1080p world. So the first decision: Plex in a docker with an iGPU for transcoding OR Plex in a VM with a P2000 for transcoding That will really dictate where you go from here IMHO, if you need an iGPU for a plex docker, then team Blue is your only option. If you want to do transcoding in a VM then you can use either, but team Red would get more bang for the buck (IMHO). You could go with a really beefy i7 or i9 with an iGPU, but Intel is really managing what processors have gpus tightly...so it is a very limited set. If you aren't going to go for hardware transcoding, then likely team Red is the default as they have much higher core counts for the investment and you will ALWAYS have PCI-E lanes free to drop in a video card later. Anyway, that's just my thought on a clear distinction between the two.1 point
-
I use Time machine but haven't had to do this for ages. Google is your friend but I believe last time i did this it was as follows: - Open up Time Machine on the Mac that's being backed up. - The timeline scale thing is on the right - move that 'slider' to a date in the past - from this date all older backups will be removed. - Then if I remember correctly - right click on 'Macintosh HD' or the name of your hard drive - and you should be able to 'delete the backups' from there. I'm fairly sure you can just delete backups on specific directories as well. You might want to test how it works on a smaller directory first to ensure it doesn't delete ALL the backups but I remember this just worked for me last time. Del1 point
-
I'd consider replacing disk 2 197 Current_Pending_Sector -O--C- 100 100 000 - 48 198 Offline_Uncorrectable ----C- 100 100 000 - 48 As for the flash, as mentioned try a different port, preferably USB21 point
-
Looks like your flash drive is dropping offline. Try a different port. Ideally USB2 Looks like your disk 2 is dropping offline, causing the read errors (and presumably it being disabled). Could simply be a crappy connection to the drive / port / power As @Frank1940 said, we'd like to see your diagnostics.1 point
-
oh yes there is 😁i built it yesterday, check CA1 point
-
Next time please post the complete diagnostics. WD looks fine, Seagate mostly fine, safest option would be rebuilding to new disks while keeping the old ones intact in case something goes wrong during the rebuild, but should be OK to rebuild on top of the old ones, but in that case first check they are mounting and contents look correct.1 point
-
You forget: RC doses not mean "Release Candidate", it means "Rickrolling Complainers" 😎1 point
-
@jayarmstrong If this happens, reduce the cores to only one for the installation. The issue is reported a couple of times in the forums. This should fix the hang during the installation.1 point
-
If as you try to access unsecure unRAID, you see this panel, insert \ backslash for user ID and click OK, your in.
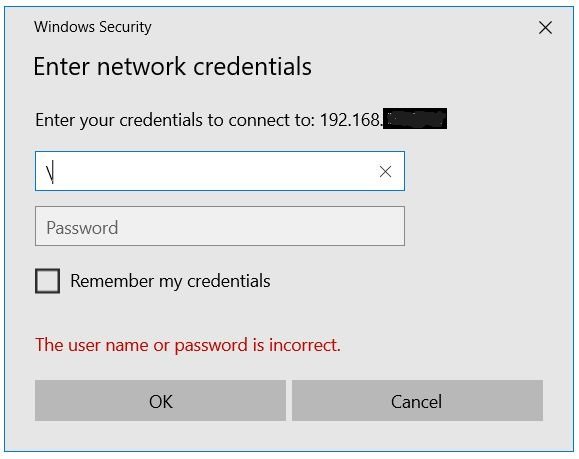 1 point
1 point -
You cant. To use a nvidia GPU for any sort of trans-coding on unRAID you must use a VM and passthough the card to the VM. So for your case, if emby supports GPU transcoding, you would have to run emby in a VM with the GPU passed through to the VM.1 point
-
I agree with some of this but respectfully disagree with the conclusion. The priority of the enhancement should certainly be a consideration, but so should the level of effort. This is not like implementing dual parity, or figuring out how to make Ryzen c-states work. It is well defined, the techniques are clear, and by and large the code already exist. This would not be a lengthy enhancement. There are three parts: 1 - Copy the data off - a lot like the mover script, but moving from the "drive to remove" to the array. It could get snagged up if there is not enough space. It would take some testing to confirm everything got moved off. Not trying to say trivial, there are some exception cases that would have to be thought through. But very doable. And if things got too complex, it could punt the job back to the user. 2 - Zero the disk - dead simple 3 - Remove the disk from the config - maybe a little tricky if the array is not brought offline. But I think the stop array button could be used to stop the array and remove the disk from the array. And I DO think it would be used. I already gave one use case ("I added a drive to the array and now want to use it to rebuild a failed disk"). But here is another maybe more satisfying use case. Say a user buys a new 8T drive, and wants to use it to replace 2 3T drives (freeing a slot and adding 2T of free space). He can replace one of the disks with the 8T drive. But now he wants to distribute the contents of the other disk to the array and remove it. Today he would be using unbalance or Krusader, performing a parity check, doing a new config, performing a parity build. and if they are a good citizen, doing one more parity check at the end. If this feature were in place, push the remove drive button, and the whole operation would happen with parity maintained. Stop the array and the disk is free. People would use this feature!1 point
-
...OK, I tested (under Windoze with my IBM ServeRAID M1015 (LSI SAS2008, re-branded/custom version of 9240-8i) the sas2flash utility from your zip is version 7, although it should be version 9, yes?...at least you did supply the original docs of P9 with your zip sas2flash v7 did not recognise my IBM card (step 1 "LIST")...downloaded v9 from LSI...same result ...looks like my M1015 is still a no go :'( Not for your situation, but you cannot use v9 of sas2flash it will not allow rebadged cards to be flashed, its in my notes with the zip. v7 with "-o" command added WORKIE WORKIE1 point



















