Leaderboard



Popular Content
Showing content with the highest reputation on 06/11/19 in all areas
-
Yes you can - just make sure you have a backup of the key file that contains the licence and is linked to the GUID of the USB stick However I suspect you are less likely to want to redo the USB stick than with more traditional OS as Unraid is not installed in the traditional sense. Instead on every hoot it unpacks itself from archives on the USB stick into RAM.2 points
-
P.S. I warned you some time ago that this disk was failing, it should heave been replaced at the time.2 points
-
Any LSI with a SAS2008/2308/3008 chipset in IT mode, e.g., 9201-8i, 9211-8i, 9207-8i, 9300-8i, etc and clones, like the Dell H200/H310 and IBM M1015, these latter ones need to be crossflashed.2 points
-
Here's how to uncompress/compress bzroot ##Extract microcode dd if=$D/unraid/bzroot bs=512 count=$(cpio -ivt -H newc < $D/unraid/bzroot 2>&1 > /dev/null | awk '{print $1}') of=$D/unraid/bzmicrocode ##Unpack dd if=$D/unraid/bzroot bs=512 skip=$(cpio -ivt -H newc < $D/unraid/bzroot 2>&1 > /dev/null | awk '{print $1}') | xzcat | cpio -i -d -H newc --no-absolute-filenames ##Prepend microcode and Compress cp $D/unraid/bzmicrocode $D/$VERSION/nvidia/bzroot find . | cpio -o -H newc | xz --format=lzma >> $D/$VERSION/nvidia/bzroot2 points
-
Well LT just contacted me to let me know that the user did finally get their message and has taken steps to remedy the issue. Needless to say, they were glad that it was a community member that found it and shut it down to prevent harm. Glad they handled it before some black hat decided to re-purpose it.2 points
-
A good PSU for unRaid has the following: 1. Single 12 volt rail. A subsequent figures refer to the 12 volt rail. 2. The minimum capacity that can power your build. Any more will just waste power. All drives will be in use during startup, shutdown, parity check, parity build, failed drive emulation, and drive rebuild, but startup requires the most power. 3. 2 amps (24 watts) per green drive and 3 amps (36 watts) per non-green drive on the 12 volt rail. 4. 5 amps (60 watts) for the motherboard on the 12 volt rail. Please make comments below and I will incorporate changes in to this post.1 point
-
Hi, Long time reader, first time poster. I recently decided to stop booting from, and writing to, the usb flash drive after two drives has gone bad. There seems to be some information on how to do this, but I could not find any method that was simple, clean, persistent and "set-and-forget". I solved it by overlaying bzroot with a tiny initramfs and wrote up all instructions on how to do this here: https://github.com/thohell/unRAID-bzoverlay This will also work well when running unRAID in a vm where boot from usb may not even be possible. No need to chain load using plop or other hacks. Just build a small boot image using these instructions. Hopefully this information is useful to others.1 point
-
As off January 19, 2022 this image has been deprecated, read the notice here https://info.linuxserver.io/issues/2022-01-19-clarkson/ Application Name: Clarkson Application Site: https://github.com/linuxserver/Clarkson Docker Hub: https://hub.docker.com/r/linuxserver/clarkson/ Github: https://github.com/linuxserver/docker-clarkson Please post any questions/issues relating to this docker you have in this thread. If you are not using Unraid (and you should be!) then please do not post here, instead head to linuxserver.io to see how to get support. Note: This requires MySQL v5.7.* and is not compatible with MariaDB, this is due to a limitation in flyway.
 1 point
1 point -
Ok, this may be dumb, but I have a use case that this would be really effective on. Currently I pass trough 2 unassigned 10k drives to a vm as scratch disks for audio/video editing. In the vm, they are then setup as Raid 0. Super fast. The problem becomes that the drives are then bound to that VM. I can't use the disks for any other vm nor span a disk image (work areas) for separate vm's on that pool. I think it would be better to have the host (unRaid) manage the raid, and then mount the "network" disks and use them that way. Since the vm uses paravirtualized 10GBE adapters, performance should be no issue. And multiple vm's could access them as well. Why don't I just add more drives to my current cache pool? Separation. I don't want the dockers that are running, or the mover, or anything else to interfere with performance. Plus, i'm not sure how mixing SSD's and spinners would work out. Maybe ok? I'm sure someone has done that. TLDR: Essentially I'm suggesting that we be able to have more than one pool of drives in a specifiable raid setup (0 and 10! please!)1 point
-
All my hard disks are encrypted. One reason for doing that is so that the content of the disks are protected - which also means that the file names etc. are also not known until the disks are unlocked. The only part that is not encrypted is the USB drive. Looking at the /boot/config/shares folder I can see all the shares which I created. While not disclosing the files, the "content" on the disks can be guessed based on the filename. That is considered an "Confidentiality" vulnerability (even if not a very critical one in this case). None the less, it is one. Renaming the shares to something like A, B, C ... beats the purpose of defining names at all and is therefore not helpful imho. And it doesn't prevent other issues, Additionally, these configuration files store information on the shares regarding the "security" levels. An attacker just needs to pull out the USB stick and change the shareSecurity from private to public, reinsert the USB stick and then has access to the share. That is considered an Integrity vulnerability which allows the attacker to delete/change/add (maybe illegal stuff) data on the encrypted share (even the flash disk allowing covering up any changes made) which could even get the user into a lot of trouble when user unlocks his disks and finds a surprise there... However, as the shares are not used (and therefore useless) until the disks are unlocked (scenario: the user has encrypted all disks), it would make perfect sense to store the configuration files of the shares in encrypted format instead of plain text as is done right now. Suggestion: Using the keyfile (which is created after the user has unlocked the disks) as the password for AES encryption/decryption of the filename and it's content is easily possible, preventing both attack vectors. The same applies to other data I suspect is being stored on the USB stick, e.g. "users" (config/shadow), log files (could be stored as encrypted ZIP files), and maybe more (maybe a wlan password?) I can't think of right now. Maybe everything in the config file??? The argument "but the attacker would need access to your system so this is not really a problem" is imho not valid. The issues should be fixed (and I cannot imagine this being very difficult to achieve from a code perspective). And also true is that this will not prevent someone from changing the unraid code itself to achieve the same goal - but that is a different technical league. The ultimate security would be available using USB disk encryption for Unraid so that the authentication (and unlocking) happens when the system starts, but that is a different technical league to accomplish as well in Unraid. And all this may sound paranoid, but since Snowden paranoia is now reality I guess So whatever can be done to increase security should be done imho.1 point
-
Planning on purchasing a PRO key. I hope my question is clear enough... I do understand that the purchased key is tied to the USB boot flash drive. I have a tendency to rebuild my boot OS image every few months (after a few OS updates or a few application updates, or in case I screw up - which happens a lot). Can I download and recreate the bootimage on the SAME USB flash drive? Basically, in other words - can I start from scratch using the same USB key that is registered. Thanks!1 point
-
Thank you for the report and blog post. It's going to take a while for me to fully digest what you're doing. There's nothing really 'magic' about the Unraid SMB implementation - we use pretty much the latest releases of Samba. You can tweak yourself via Network/SMB/SMB extra configuration.1 point
-
You might find that it improves with the latest (6.7) stable release.1 point
-
Hello @binhex I found the solution and I post it here for the people in my case. Under our proxmox host: nano /etc/pve/lxc/XXX.conf (XXX is the ID of the proxmox CT) Add at the end: lxc.autodev: 1 lxc.hook.autodev: sh -c "mknod -m 0666 ${LXC_ROOTFS_MOUNT}/dev/fuse c 10 229" lxc.cgroup.devices.allow: c 10:200 rwm lxc.apparmor.profile: unconfined And : nano /etc/modules add iptables if missing # /etc/modules: kernel modules to load at boot time. # # This file contains the names of kernel modules that should be loaded # at boot time, one per line. Lines beginning with "#" are ignored. loop # Iptables modules to be loaded for the OpenVZ container ipt_REJECT ipt_recent ipt_owner ipt_REDIRECT ipt_tos ipt_TOS ipt_LOG ip_conntrack ipt_limit ipt_multiport iptable_filter iptable_mangle ipt_TCPMSS ipt_tcpmss ipt_ttl ipt_length ipt_state iptable_nat ip_nat_ftp ipt_MASQUERADE Restart the proxmox host and restart container too. Access to rutorrent is OK from the outside. With this change, we allow the use of the iptable_mangle modprobe on the container. Thank you for this great image @binhex. A + and good luck!1 point
-
Yeah, with 16TB I prefer double parity. All these drives are older, makes me feel better even though I do have backups.1 point
-
You could simply move some complete series to another drive to free up space on the problem drive and keep your current settings. You really want a strategy in mind so you know how you want to handle things going forward.1 point
-
Looks like your hard drive controller is limiting the size of the disks. Post diagnostics.1 point
-
We've made it easier to get Nvidia & iGPU hardware trancoding working with this container. This post will detail what you need to do to use either of these in your container. (Emby Premiere Required) Nvidia 1. Install the Unraid Nvidia Plugin, download the version of Unraid required containing the Nvidia drivers and reboot 2. Add the Emby container and add --runtime=nvidia to extra parameters (switch on advanced template view) and copy your GPU UUID to the pre-existing NVIDIA_VISIBLE_DEVICES parameter. There is no need to utilise the NVIDIA_DRIVER_CAPABILITIES parameter any more. This is handled by our container. Intel GPU 1. Edit your go file and add modprobe i915 to it, save and reboot. 2. Add the Emby container and add --device=/dev/dri to extra parameters (switch on advanced template view) There is no need to chmod/chown the /dev/dri, this is handled by the container.1 point
-
You are just the 264th person to ask that in this thread.1 point
-
Those call traces during parity check (and related bad performance) can usually be solved by lowering the md_sync_thresh value, though the current value is pretty low already.1 point
-
The reason I asked about the MB was mainly to know if the drives are connected to SATA2 or 3 ports. And you didn't answer @testdasi question about TRIM on the cache drive. Do you have it regularly scheduled or has it not been trimmed in a while? I don't have time to log at the diags right now, but let's do some simple performance tests without any network, docker containers and what not involved to rule out some things. Your cache drive should absolutely perform better then what your tests are showing. SSH in or open terminal in the webui, navigate to a cache only share on the cache drive and run this command: dd if=/dev/zero of=file.txt count=5k bs=1024k This will write a 5GB file to the drive and give you some stats, please post the output here. Run it 3-4 times to get the average and post the result. Do the same for the array drives, first directly to a single disk, then a user share which does not has the use cache set to: yes and post the results. I don't know if it makes a difference to write to a specific drive or a user share (it shouldn't), but it's fun to test anyway. Also do the same test to the array with turbo write enabled. It was not clear from your posts but it seemed like you did most of the test on the cache drive, and turbo write only works on the array. Been a while since I've done any test on my system but I remember vaguely something about the speed you say you've had earlier around 50MB/s to the array, without turbo write. The cache drive I think had around 3-400MB/s.1 point
-
Open up the shares in Windows using File Explorer and see if the 'missing' files are there. It is my understanding that excluding a share from a disk only prevents writing new files to that disk. Existing files can still be read. What could be happening is that Plex is attempting to access those files in a read-write mode and that might not be allowed. EDIT: you might want to read through this thread:1 point
-
If you mean global exclude list, yes. Those disks are globally excluded from participating in user shares.1 point
-
You are providing too little information for anyone to able to figure out the issue. Please attach full diagnostic .zip in your next post. How are the drives connected? To an HBA card or to the MB ports? If connected to the MB, have you made sure it's connected to a SATA3 port and not a SATA2 port? Many MB have both, old ones in particular. When you say new/different MB with dual CPU I automatically assume older server grade MB/CPU, because that's what most dual CPU users around here use (what I've seen anyway). Unless you spent a lot of $$$.. And I have to guess since there's not any info. You should also fix the spamming in your syslog, if it's the "SAS drive spin down bug" causing that like you said you should disable spin down for the parity drives if they are unable to spin down anyway. And disk 29 is the parity2 drive FYI.1 point
-
Right, for NFS the security modes map to entries in /etc/exports as follows (example share name is Test): For Public: "/mnt/user/Test" -async,no_subtree_check,fsid=100 *(sec=sys,rw,insecure,anongid=100,anonuid=99,all_squash) For Secure: "/mnt/user/Test" -async,no_subtree_check,fsid=100 *(sec=sys,ro,insecure,anongid=100,anonuid=99,all_squash) If Private has been selected (and click Apply) a new input field labeled Rule will appear. Whatever you type will replace the third field in the exports line: "/mnt/user/Test" -async,no_subtree_check,fsid=100 <what you type goes here> Hence, for NFS, Public means read/write for anyone; Secure means read-only for everyone; Private gives you control to set whatever you want. The 'fsid' value is established when the share is first created and will retain that value for as long as the share exists.1 point
-
I think what step 17 is referring to double check/verify that you have requested the format changes to the proper disks on the setup screen BEFORE you click 'Apply'. Because if you didn't, you will lose all of the data on an 'innocent' drive as soon as it starts the format procedure. As I recall, this is a point at which it is actually quite easy to make a mistake. That was why I had a table prepared with what the settings were to be on each step and I checked-off each step as I did it!1 point
-
Create an archive file on the source end so you only need to transfer 1 large file.1 point
-
From what i've seen there is a dedicated for linux so i will look into that and if it's possible. Give me a few days.1 point
-
@fluisterben As you can see in the default proftpd.conf I'm not additionally limiting the max users in any way. So if they are, this is a ProFTPd default setting baked into the server itself and not changeable by me. It is probably a security precaution to only allow one login per user. If you want to change it, you can use the MaxClientsPerUser number|none directive.1 point
-
It will work with SSDs that support read zeros after trim.1 point
-
Any LSI with a SAS2008/2308/3008 chipset in IT mode, e.g., 9201-8i, 9211-8i, 9207-8i, 9300-8i, etc and clones, like the Dell H200/H310 and IBM M1015, these latter ones need to be crossflashed.1 point
-
As far as I know this feature has always been there (well at least since Unraid v5 which is when I started with it). The only thing I can remember that changed was making it default to non-correcting rather than correcting. Any time Unraid cannot successfully unmount the drives there is quite likely to be some invalid sectors on the parity drive so I cannot see why a normal user would EVER want this feature disabled. The correct solution is for you to resolve what is stopping the unmounting from succeeding so the shutdown completes cleanly. What are you using to trigger your unmount scripts - maybe that is where the issue lies and they are not getting run successfully?1 point
-
Something is preventing Unraid from unmounting the disks: Apr 30 01:27:07 Unraid-Server emhttpd: shcmd (416): umount /mnt/user Apr 30 01:27:07 Unraid-Server root: umount: /mnt/user: target is busy. Hence the unclean shutdowns.1 point
-
So you expect the disks to fail after 4 scheduled parity checks?1 point
-
Please implement the ability for unRAID to spin down SAS drives automatically when idle. I understand that there is an argument that spinning down lowers drive life but there is already a feature to disable this for those who don't want drives to spin down. I like the drives spinning down to save power. Also, Parity drives are spun down most of their life on my unRAID system as my cache drive is huge and only syncs @ 0300 or when the Cache drive hits 70% usage. I've searched the forms and see others who want this feature but couldn't find it as a formal Feature Request. It's already a feature of FreeNAS. I'm not going to switch from unRAID, you guys rock. Just would like on the road map that it will become a feature one day, preferably sooner than later. I do understand your busy and I'm not a programmer so have no idea what I'm asking you to do. Thank you for such a wonderful server product!1 point
-
I kept trying each RC until I found a stable one. RC4 had been the most stable with an uptime of about 2 weeks which usually means I am in the clear. I just upgraded to RC5 a couple days ago and that has been solid as well so far.1 point
-
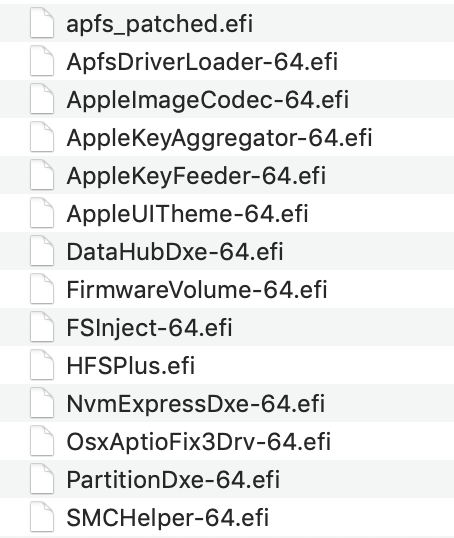
Was someone able to install the latest version of clover (4895)? I'm using 4674 right now an it works absolutely fine. If I update to 4895 or 4901 (which was released nearly an hour ago), I can't boot anymore. I get stuck at the TianoCore logo. I've discovered a new driver AudioDxe-64.efi, which I guessed I won't need anyway and sounds like it could cause problems. After deleting it it shows "clover 4895, scan entries". But nothing more happens. Tried it with HFSPlus.efi and VBoxhfs.efi, neither worked and also not both at the same time... Beside that, I don't use any unusual drivers. Also tried replacing the new drivers64UEFI folder with my backed up one, but won't boot either. The image attached shows all the driver I'm currently using with clover 4674. EDIT: I've also tried removing my old drivers64UEFI folder before the installation, so all drivers will get installed. After that I've copied the Apple* ones over, but also doesn't work. EDIT2: So I found a version which could maybe work (4862 from tonymacx86). My external USB backup drive (HFS+) is recognized. But usually I'm using an NVMe drive with APFS. I'm pretty sure the APFS filesystem isn't working properly... and I've already tried different drivers. EDIT3: Finally got it working (at least 4862 from tonymacx86). The problem was ApfsDriverLoader-64.efi. Had to delete it completely and instead use only apfs-patched.efi. Now its working so far
 1 point
1 point -
@binhex Can you do a FireFox/Chrome VNC docker, the current one by @Djoss is running old FireFox and they use a diff linux distro that isnt staying as current as Arch is.1 point
-
Time to start from scratch. Pro tip: once you have a base img up and running with vnc, make a backup copy on the array. That way of you mess it up later it only takes a few minutes to copy over a known working good img vs starting over again (learned this the hard way a few times.)1 point
-
so far having a issuse , with new vm setup of a sierra mac load , from my mac to unraid , running fine , but went to increase vdisk amount , in unraid no problem , vdisk was in creased in the os , i try over and over and still stays at 40gb , for the vdisk main partition , but the top main disk shows the correct amount but it is free .... and os wont let me install anything else , i have plenty of room on the system ..ie... ssd caches, and storages ,... only trying to incress the mac boot disk to 250gb , from 40 ....1 point
-
Split levels can be confusing, let me give you 2 examples that should help, this is how 2 of my shares are set: (Share / Folder / Files) ps: share is also a folder, the top level one Movies / Movie Title / Movie and related files: split only the top level directory, all files from any movie will be on the same disk TV / Show Name / Season # / Episodes: split only the top two directory levels, all episodes from the same season will be on the same disk, different seasons of the same show can be on different disks, if you wanted all seasons to be on the same disk you'd need to set split level as the Movies share.1 point

.thumb.jpg.50fe04ea2fd24fe57ffc99b91ad9a81c.jpg)


















