Leaderboard



Popular Content
Showing content with the highest reputation on 09/28/19 in all areas
-
The problem is resolved in 6.8. I guess the RC release isn't too far away.2 points
-
I've been using the spindown/sleep for almost 10 years now. Not a single HDD died of it. The oldest in use is over 5 years old (a 3TB WD-Red). Four HDDs died due to Platter problems (weak sectors), but not a single one has affected the motor or the mechanics. The REDs have a Load Cycle Count of 600.000. It takes a long time to reach this limit...1 point
-
Unfortunately soon tends to be a very long time!1 point
-
Are you using Plex and have the transcode folder set to /tmp? The solution I use is as follows 1. Add this to the 'go' file (before starting emhttp) # make plex working directory mkdir -p /tmp/plex 2. Change the mapping in the docker container settings
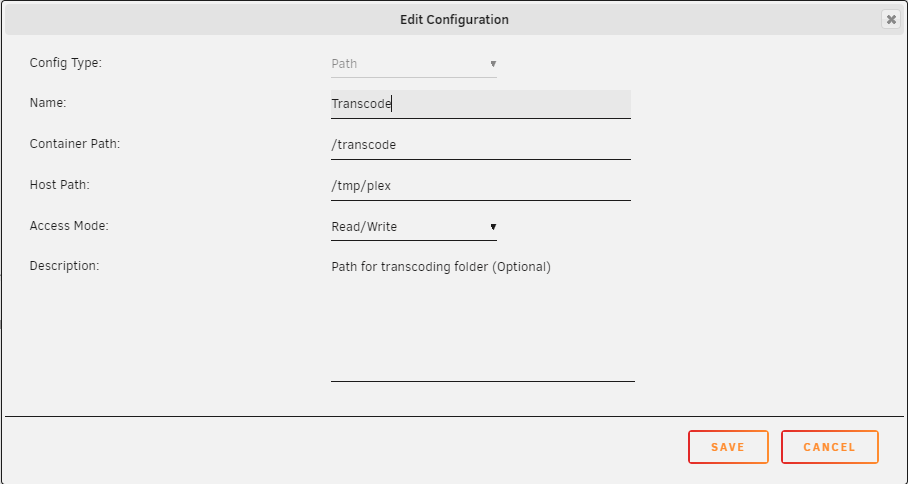 1 point
1 point -
This container is maintained and supported by a third party. It is not a Limetech/unRAID product. I and many others have Plex hardware transcoding with an Intel iGPU working flawlessly across all my devices (PC, laptop, iOS phones and tablets, TVs) with this Plex container. Unfortunately, Plex hardware transcoding with an iGPU is an optional functionality that requires some config outside the container and, really, LSIO (the maintainers of this docker container) is not responsible to make sure it works for everyone. There could be hardware or software issues outside the control of Limetech or LSIO. By all appearances you seem to have things set up properly with the 'go' file entries and from the container side. Is your primary graphics adapter in the BIOS set to the iGPU? Again, it looks like things are properly configured and it SHOULD work, but, something is clearly not working in your case based on your posts. Unfortunately, neither Limetech nor LSIO is responsible to make sure it works for you. You'll have to rely on the community and/or Plex to help you with this. I once had a similar issue where trying to play anything on certain platforms resulted in a black screen. The solution for me was to delete the {appdata}/Plex/Library/Application Support/Plex Media Server/Codecs files and force Plex to download the codecs again. It will do so on demand for each needed codec. For some reason, I had some messed up codecs that did not allow content to play/transcode properly.1 point
-
Started it yesterday evening with -A and -f. Pre-read completed successfully. Currently at 2% on zeroing. This is on an 8TB drive.1 point
-
There are only two options, both are described there.1 point
-
XFS uses around 1GB per TB for filesystem housekeeping, so that's normal on an empty 8TB disk.1 point
-
They haven't hit the next milestone 6.8.0-rcn0sy1 point
-
This is a Tautulli problem and they know about.1 point
-
Sometimes it´s nice to see which container is hogging available cpu cycles and memory. Currently i see no way of enabling resource monitoring for individual containers in the settings page Settings/DisplaySettings as i would have expected. This ties nicely in with the other resource monitoring widgets already present.1 point
-
Not strange at all. Iirc Plex doesn't use hw acceleration for thumbnail generation. They never did.1 point
-
Did you remove a USB device, which was previously attached (before your holidays)?1 point
-
How has the setup process changed (if at all) with the newest Public PMS release (version 1.17.0.1709)?1 point
-
While this is fine for most use cases; and probably even "acceptable" for mine; it reaches limitations rapidly when hitting the disk with high network bandwidth. I have 10gbe uplink to my network. A single sata hard disk can hardly saturate gigabit; let alone 10gbe. If I'm transferring a large image on my network (500gb+ disk images) and a user wants to stream an episode of a tv show form the same disk as I am hitting - it might work. But if that TV show is 4k.... we've got a problem. The disk I/O demand is just too high. Yes, even spreading the data out, we can run into this problem - but it will be substantially more rare. I can then also further mitigate these issues by ensuring my large disk images are on a single share, and that those shares don't touch the disks with tv shows and movies. But we still hit disk I/O bottlenecks when multiple users are slamming the same drive. Enter cache, maybe? Sure - if you can reliably predict which data users are going to grab and cram all of that into a (relatively) small cache device; unlikely. In the above I highlight several (band-aid) fixes for the "problem" in the form of a lot of constant, manual server administration work. I paid for an unraid license because I don't want to fiddle with the server constantly. I have my Arch server, and I went down that road. I haven't had to do any manual administration on said arch server in over a year. This unraid box, I cannot say the same for - but that's growing pains. Once everything is set up the way I like and works properly, I won't need to fiddle. This is probably the single biggest downside to unraid. The throughput sucks. There are a lot of positives to a system like this, but the big detriment is that I/O performance is abysmal by comparison to a striped disk system. I keep teetering between whether I should continue to fill this server, or jump ship to a different platform while I can still afford to empty the drives and make the swap or not. I'm less inclined to just because I've paid for a license here.1 point
-
Would it be possible to add support for a true scatter function? All of my disks are currently the same size. I'd like to keep files distributed among the disks to spread out the bandwidth use. Originally my files were distributed by unraid's High-Water option. I used unbalance to migrate data to 3 individual disks so I could switch to encrypted disks. Migrating data off those existing disks is where I realized the name "scatter" doesn't quite tell the story. Now I have 4 disks more or less permanently stuck at 100% usage making a much larger portion of my data reside on them. I can manually go through and select individual directories to spread the data out, but that's probably going to take several months.1 point
-
Ok, did some more digging, deleted the "dhparams.pem" file in the /letsencrypt/nginx folder and letsencrypt has now restarted successfully and regenerated a new dhparams.pem file I would like to try and understand what had happened though? any insight or pointers would be most appreciated. Thanks1 point
-
I'm not sure what import folder you are referring to, but you can upload books through the web interface. That is the correct method. However, the location the books reside in has to be accessible by the container, meaning you don't upload through the web, but you use the web to point to the books calibre should import. Calibre-web is a separate app by a separate developer. It is simply an alternative web interface for calibre and it requires an existing calibre db to connect to. This image only replaces the RDP Calibre image that is in my personal repo. This one is more up to date and will continue getting updates whereas the RDP Calibre will be deprecated once I write migration instructions for existing users.1 point
-
Thank you. For reference, this has been resolved by adding the below line: store dos attributes = yes To: Settings -> SMB -> SMB Extras -> Samba extra configuration Keep it at the first line Then reboot unRaid or restart samba using the below commands: samba restart smbd restart1 point











