Leaderboard



Popular Content
Showing content with the highest reputation on 03/25/20 in all areas
-
Please don't take offense at this, but you probably will anyway. If the only or overriding reason you are running this is to be directly compensated in some way, don't run it.3 points
-
Hahaha - we're beating the LTT team.2 points
-
Umm, is this how skynet gets started?!? We were so preoccupied with whether or not we could, we didn’t stop to think if we should. 😜2 points
-
This is a plugin that shows the file and directory activity on the array by disk. This includes read and write activity on the array. Read activity can cause disk spin ups. It is recommended that you have the Dynamix Cache Directories plugin installed and running. The plugin uses inotify to log read and write disk activity. You will need to start File Activity to start the logging. I don't recommend leaving it on all the time. A server with a lot of file activity can fill the log space. You can see which files and directories are being read and written and keeping the disks from spinning down. The file activity is shown by disk, UD disks, and the cache and Pool drives. The 'appdata', 'syslogs', and 'system' shares are excluded. This is not the ultimate answer for disk spin ups, but I used it to find an issue with Windows 10 backing up files every hour. It would write new files on the cache, but constantly modify the older file directory entries causing spin ups on disks. The plugin is installed in the Tools menu under System Information. The preferred way to install the plugin is with CA. Or you can install the plugin by copying the following URL in the install plugin line of unRAID: https://github.com/dlandon/file.activity/raw/master/file.activity.plg1 point
-
Hey 👋 This started off as a bit of a hobby project that slowly become something that I thought could be useful to others. It was an exercise for me in writing a new app from scratch and the different choices I would make, compared to having to constantly iterate on an existing (large) code base. After sharing this with some of the community in the unofficial discord channel, I was encouraged to get it into a state where it makes sense for others to use. https://play.google.com/store/apps/details?id=uk.liquidsoftware.companion I've already received some great feedback as well as a number of issues and requests for new features, that I hope to add soon. I hope others will find this as useful as I do in managing your UNRAID servers. Enjoy
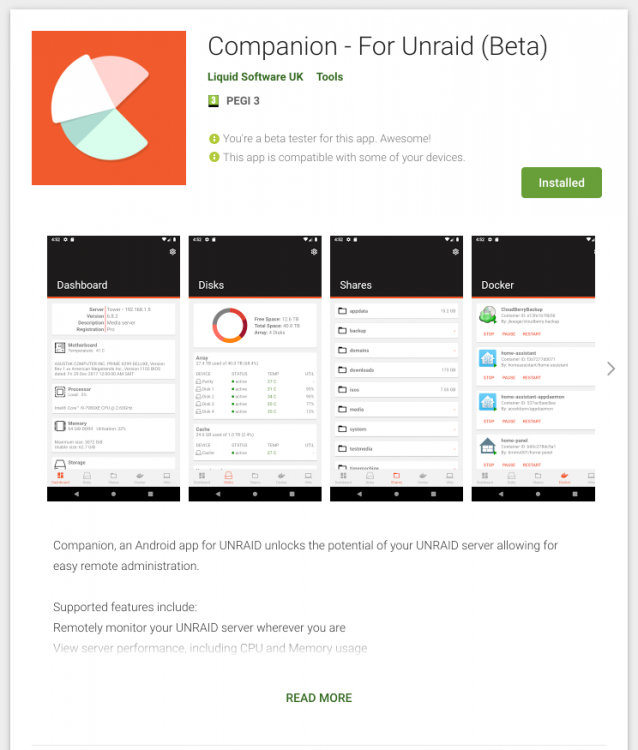 1 point
1 point -
Recently (starting with 6.2beta?) if array auto start is set to yes array starts even when there's a missing disk, IMO this can be dangerous when upgrading a disk, I'm used to upgrade a disk while leaving auto star ON, unRAID would detect a missing disk and wouldn't start the array, I just assign the new disk to begin the rebuild. Now, if say while upgrading a disk I bump a cable to another disk in a server with dual parity it will start the array with 2 missing disks, so besides the upgrade I'll have to rebuild another disk. If you want to keep this behavior then please consider setting another option for enable auto start: Always Yes, if there aren't missing disks No1 point
-
Hi everyone: I am Squids wife. I just wanted everyone to know he will be 50 on Sunday March 22nd, If you all can wish him a happy birthday that would be great.Due to Covid 19 - no party. Thanks Tracey1 point
-
Thank you! You're an awesome human being!1 point
-
It's also faster. Krusader and Dolphin both seem to be slower copying. A properly configured network is probably faster than a locally connected USB as well. USB data transfer can be very temperamental, I'd recommend connecting to a SATA or eSATA port for mass data transfer.1 point
-
update my solutions fyi. 1. add "modprobe e1000 eeprom_bad_csum_allow=1" into go file, failed Problem with e1000: EEPROM Checksum Is Not Valid 2. modify i219v to i219-LM via eeupdate, now it works. hopefully can help someone. i hide the mac address. root@Tower:~# dmesg | grep e1000e [ 18.642910] e1000e: Intel(R) PRO/1000 Network Driver - 3.2.6-k [ 18.643344] e1000e: Copyright(c) 1999 - 2015 Intel Corporation. [ 18.643923] e1000e 0000:00:1f.6: Interrupt Throttling Rate (ints/sec) set to dynamic conservative mode [ 18.899380] e1000e 0000:00:1f.6 0000:00:1f.6 (uninitialized): registered PHC clock [ 18.975021] e1000e 0000:00:1f.6 eth1: (PCI Express:2.5GT/s:Width x1) 88:88:88:88:88:88 [ 18.975024] e1000e 0000:00:1f.6 eth1: Intel(R) PRO/1000 Network Connection [ 18.975080] e1000e 0000:00:1f.6 eth1: MAC: 12, PHY: 12, PBA No: FFFFFF-0FF [ 20.777124] e1000e 0000:00:1f.6 eth1: removed PHC [ 21.295254] e1000e: Intel(R) PRO/1000 Network Driver - 3.2.6-k [ 21.295256] e1000e: Copyright(c) 1999 - 2015 Intel Corporation. [ 21.295520] e1000e 0000:00:1f.6: Interrupt Throttling Rate (ints/sec) set to dynamic conservative mode [ 21.509554] e1000e 0000:00:1f.6 0000:00:1f.6 (uninitialized): registered PHC clock [ 21.591988] e1000e 0000:00:1f.6 eth0: (PCI Express:2.5GT/s:Width x1) 88:88:88:88:88:88 [ 21.591993] e1000e 0000:00:1f.6 eth0: Intel(R) PRO/1000 Network Connection [ 21.592048] e1000e 0000:00:1f.6 eth0: MAC: 12, PHY: 12, PBA No: FFFFFF-0FF [ 24.989268] e1000e: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: Rx/Tx1 point
-
I discovered the same thing and addressed it in the same way. No magic one-size-fits-all solution is coming from me. 😀1 point
-
I started using this container this week. I have not run a CPU taxing container like this before and found an interesting thing that might be applicable to others. I have half my CPU cores available to Unraid and half isolated for VMs. Making the isolcpu system initialization change does not modify how the CPU is reported to the docker process and the containers that are run. For example, my 8C/16T AMD 3800X still reports as such even though only 4C/8T are available for allocation by the host (and by extension, docker). So, when running the BOINC container and letting it use 100% on my CPU, it spins up 16 WU processes because it thinks it can do that many on the processor concurrently without multitasking on the same core. The result, each core has 2 BOINC threads competing for resources. Probably not the biggest deal, but not ideal as there is still likely overhead switching between them. So, in instances where you isolate CPUs away from the host, my workaround is to tell BOINC the percentage of the CPU still available to it (i.e. how many are still available for docker allocation ... e.g. [16/2]/16 = 8/16 = 0.5, 0.5*100=50%). This setting is in: Options->Computing Preferences->Computing->Usage limits->Use at most '50%' of the CPUs. I tried CPU pinning cores to the BOINC docker and keeping the BOINC config at 100%, but BOINC still interprets the number of cores from the CPU definition. Anyone have a better solution that is more portable and less hardcoded to the current system configuration? I don't always run CPU isolation and would like to keep as much as possible immune to my whim to change it. -JesterEE1 point
-
No worries! Not everyone is expected to be an expert in all things unRAID; especially not after just a couple of weeks of use. There are no stupid questions (well, actually that does happen from time to time 😀) just lack of understanding. Most people here are very happy to help improve understanding of unRAID.1 point
-
Just as a note to others with this issue, I have only seen it once since adding "-i br0" and after a reboot it was resolved and has not occurred again. It has been 2-3 months since I last saw a CPU spike to 100%. My network is exclusively WSD/SMB 2.0+ as I have disabled SMB 1.0 on all client computers as well as in unRAID. I know that for others this parameter has not resulted in a fix, but for me it seems to have worked (knock on wood). Single CPU spike to 100% was a semi-regular occurrence before I added that parameter.1 point
-
1 point
-
Happy Birthday @Squid! Hope you had a great one 🍻1 point
-
I assumed something to this degree but I wasn't sure on the specifics of it, either way thanks for your quick response. Donation coming soon1 point
-
I use vlans at home and this caused all the traffic to leave via the management address even after binding it to an interface within the rclone upload script. The fix was to add a route second routing table and route for the IP I assigned it to. The subnet is 192.168.100/24 The gateway is 168.168.100.1 The IP assigned to rclone upload is 192.168.100.90 echo "1 rt2" >> /etc/iproute2/rt_tables ip route add 192.168.100.0/24 dev br0.100 src 192.168.100.90 table rt2 ip route add default via 192.168.100.1 dev br0.100 table rt2 ip rule add from 192.168.100.90/32 table rt2 ip rule add to 192.168.100.90/32 table rt21 point
-
The license is associated with the flash drive you register it on. That flash drive can be used on any computer and the license is still in effect. If for some reason the flash drive needs to be replaced, the license can be transferred to the new flash. See the last sentence on this wiki page here: https://wiki.unraid.net/UnRAID_6/Changing_The_Flash_Device1 point
-
No, licenses are tied to the USB flash drive.1 point
-
Dear Lime tech. I would like to see some direct feedback in the web gui related to performance data for individual drives and the average parity check speed to better judge if i should consider replacing individual drives or if my array is performing normally. With your current userbase and lots of different hardware-configuration, each array already has the data ready to harvest, and to further the lifespan of each system since we with such a feature better know what can be considered a normal average speed for a array parity check, or average drive speeds. A question i have seen frequently appear in the forums, or what can be considered normal wear and tear, based on Smart-data or individual performance of each drive after a parity check has been completed. If such recommendations were to be presented in a user friendly and intuitive way, it can prevent data loss and help end users better understand when drives should be replaced and to make informed decisions when considering proactive maintenance. A new consent option in the user interface could allow for periodic uploads of this kind of user data, and it can be presented with notification boxes or as more detailed info in the smart-data section/elsewhere. Hopefully i have presented my suggestion well enough that this can be implemented. I would be very happy if it comes to fruition.1 point
-
Some combinations of hardware (cpu / motherboard) will issue a MCE when initializing the CPUs at boot up time (Anecdotally, I've also determined that this can also be caused by ignoring your wife telling you to pick up your socks). This is normal, and is what you're seeing, and safe to ignore (on the MCE being issued). But, the ryzen tweaks / fixes linked above still need to be handled.1 point
-
Yes, that should be fine, though if you can get one from a more wll known brand, like SYBA/IO CREST https://www.sybausa.com/index.php?route=product/product&product_id=10271 point
-
There haven been similar errors on both cache devices: Mar 14 19:45:59 Gravity kernel: BTRFS info (device sdd1): bdev /dev/sdd1 errs: wr 428, rd 482, flush 0, corrupt 0, gen 0 Mar 14 19:45:59 Gravity kernel: BTRFS info (device sdd1): bdev /dev/sdc1 errs: wr 295, rd 293, flush 0, corrupt 0, gen 0 Possibly there's a cable/connection problem on both, like for example if they share a SATA splitter, that or some compatibility issue with that model, but that would be strange. Also see here for better cache pool monitoring.1 point
-
Hi there William, I sent you a PM to discuss this further but as an FYI, the instructions on how to buy are right underneath the pricing on the pricing page:
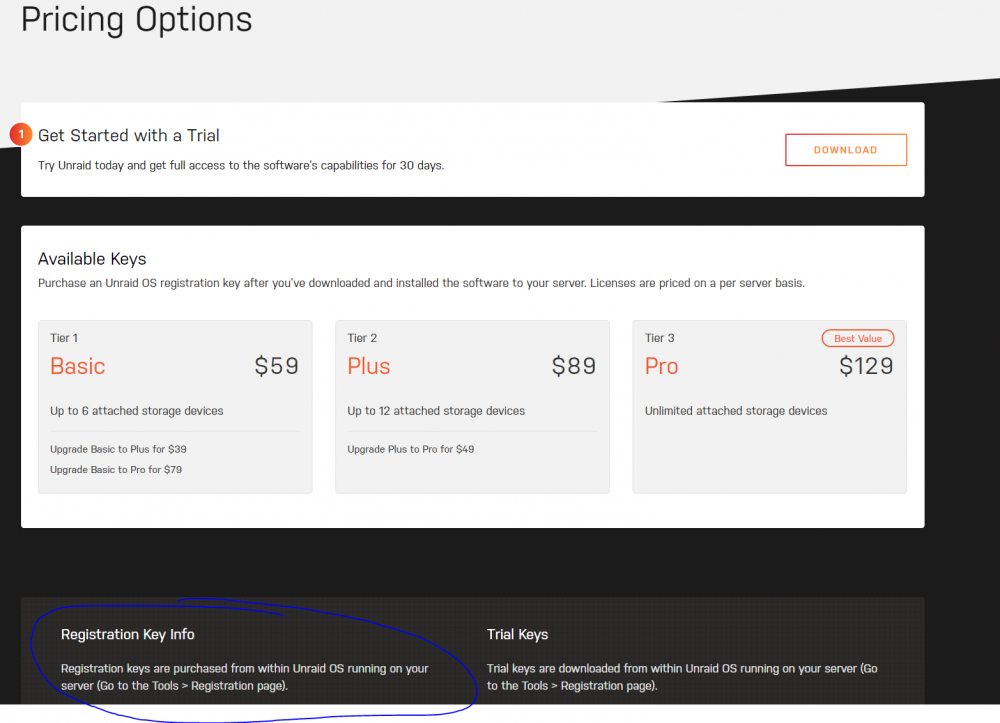 1 point
1 point -
Only the parity disk would be written to, but just check "parity is already valid" before starting the array and everything will be good, including parity, assuming it was valid before.1 point
-
I don't know of a way to use a proxy with Plex either, but you can do what I have done with some of my containers and run *all* of the Plex traffic through a VPN container. Since you won't be doing remote access I don't see any issues with this myself, but keep in mind I haven't actually tried Plex specifically. The method for doing this is a bit different between UnRAID 6.7.x and 6.8.x, it works best on the latest version of UnRAID (6.8.3 as of this post) because they have added some quality-of-life fixes to the Docker code. I figured out how to do this through these two posts (https://jordanelver.co.uk/blog/2019/06/03/routing-docker-traffic-through-a-vpn-connection/ and https://hub.docker.com/r/eafxx/rebuild-dndc) but I will summarize here since neither completely cover what you need to do. 1) Have a VPN container like Binhex's up and running. 2) Create a dedicated "VPN network" for Plex and anything else you want to run through the VPN on. - Open the UnRAID terminal or connect via SSH, then run the command docker network create container:master_container_name where "master_container_name" is the name of your VPN container, so "binhex-privoxyvpn" in my case. This name should be all lowercase, if it isn't than change it before creating the new network. 3) Edit your Plex container and change the network type to "Custom: container:binhex-privoxyvpn" if you are on UnRAID 6.8.x. If you are on 6.7.x then change the network type to "Custom" and add "--net=container:binhex-privoxyvpn" to the Extra Parameters box. 4) Remove all the Host Port settings from the Plex container, so by default on my setup there are ports TCP 3005, 32400 and 32469 and UDP ports 1900, 32410, 32412, 32413 and 32414. 5) Edit your VPN container and add the Plex required ports to the VPN container. You can probably get away with just TCP ports 3005 and 3005 and UDP port 1900 and have it work, but probably safer to add them all again. Leave the VPN containers' network type to what it is now, probably Bridge. 6) Do a forced upgrade (seen with Advanced View turned on) on the VPN container first and then the Plex container. You should still be able to reach your Plex containers web UI now, with the VPN container acting as a "gateway". Now all external traffic will go through the VPN. There are some things to remember with this kind of setup, like if the VPN container goes down you will be unable to reach Plex at all even if it is running. Also, if the VPN container is updated the Plex container will lose connectivity until it is also updated. There is code in UnRAID 6.8.3 to do this update automatically when you load the Docker tab in the UnRAID UI. Hopefully all that is clear, let me know if you have any questions!1 point
-
If you can't flash it to IT mode, then it may be more trouble than it's worth to try to use it, and you would be better of with another card. RAID controllers may not pass the disk serial number as the disk identifier. That is how Unraid identifies which disk belongs where, and if that isn't consistent, it will not remember your disk assignments. RAID controllers also may not pass SMART information to Unraid, which it uses to monitor disk health and alert you if a drive is having problems.1 point
-
Hey guys, sorry for the lack of updates. The coronavirus as thrown a wrench in my schedule. I will try to get to your requests by the weekend! Stay safe and wash your server buttons!1 point
-
Just pushed a new build to Google Play after some great feedback from testers. It should hopefully already be available. ### 1.1 ### - [NEW] Support for self-signed certificates - [NEW] Improved Add Server screen - [NEW] Allow offline servers to be added - Add message to server list when no servers added - Fix crash if trying to add server before providing any host information - Fix share information populating wrongly - Update persisted server information when connecting - Fix crash restoring app - Fix timeout when calculating sizes of large shares1 point
-
Just to be clear, the array auto-starting with a missing array device was fixed some time ago, but it will still auto-start with a missing cache pool device.1 point
-
Made a simple colorful banner from an old background to share. It seems to scale well if you have a large screen.

 1 point
1 point -
We are a bunch of grumpy old bastards that don't like changes1 point
-
Are you changing it in the Qbt WEBUI settings or the container? Edit: I found I had the same issue as you, but was able to figure it out. With the base settings, any time you change the port in the QBT interface, it will reset to 8080 when rebooting the docker. To fix this, you need 2 changes from the default config. Remove the original 8080:8080 port map create a new one 6666:6666 (whatever your new port is) add a new variable Key: WEBUI_PORT Value: 6666 (again, whatever your new port is) apply this and your UI should now work on the new port. However, clicking WEBUI on your docker in the UnRaid UI will yield a webpage opening with :8080 which won't load. I'm still trying to figure out how to change the default webpage since it seems hardcoded to 8080. Hopefully this helps you or anyone else trying to change their port! edit: I figured out that I had the view on basic. Switched it to advanced, and I can change the default launch URL as well. That should fix all the issues for everyone. Woot!1 point




















