Leaderboard



Popular Content
Showing content with the highest reputation on 04/05/20 in all areas
-
This is a support thread for various Unraid docker container templates. If the template has a link to another support thread, then please post questions there. Templates will be uploaded to: https://github.com/Josh5/unraid-docker-templates Templates: TeamCity Server More Info : https://www.jetbrains.com/teamcity/ Dockerhub Page : https://hub.docker.com/r/jetbrains/teamcity-server GitHub Page : https://github.com/JetBrains/teamcity-docker-server TeamCity Build Agent More Info : https://www.jetbrains.com/teamcity/ Dockerhub Page : https://hub.docker.com/r/jetbrains/teamcity-agent GitHub Page : https://github.com/JetBrains/teamcity-docker-agent Lancache Bundle More Info : https://lancache.net/ | https://github.com/lancachenet Dockerhub Page : https://hub.docker.com/repository/docker/josh5/lancache-bundle GitHub Page : https://github.com/Josh5/lancache-bundle1 point
-
EDIT (March 9th 2021): Solved in 6.9 and up. Reformatting the cache to new partition alignment and hosting docker directly on a cache-only directory brought writes down to a bare minimum. ### Hey Guys, First of all, I know that you're all very busy on getting version 6.8 out there, something I'm very much waiting on as well. I'm seeing great progress, so thanks so much for that! Furthermore I won't be expecting this to be on top of the priority list, but I'm hoping someone of the developers team is willing to invest (perhaps after the release). Hardware and software involved: 2 x 1TB Samsung EVO 860, setup with LUKS encryption in BTRFS RAID1 pool. ### TLDR (but I'd suggest to read on anyway 😀) The image file mounted as a loop device is causing massive writes on the cache, potentially wearing out SSD's quite rapidly. This appears to be only happening on encrypted caches formatted with BTRFS (maybe only in RAID1 setup, but not sure). Hosting the Docker files directory on /mnt/cache instead of using the loopdevice seems to fix this problem. Possible idea for implementation proposed on the bottom. Grateful for any help provided! ### I have written a topic in the general support section (see link below), but I have done a lot of research lately and think I have gathered enough evidence pointing to a bug, I also was able to build (kind of) a workaround for my situation. More details below. So to see what was actually hammering on the cache I started doing all the obvious, like using a lot of find commands to trace files that were written to every few minutes and also used the fileactivity plugin. Neither was able trace down any writes that would explain 400 GBs worth of writes a day for just a few containers that aren't even that active. Digging further I moved the docker.img to /mnt/cach/system/docker/docker.img, so directly on the BTRFS RAID1 mountpoint. I wanted to check whether the unRAID FS layer was causing the loop2 device to write this heavy. No luck either. This gave me a situation I was able to reproduce on a virtual machine though, so I started with a recent Debian install (I know, it's not Slackware, but I had to start somewhere ☺️). I create some vDisks, encrypted them with LUKS, bundled them in a BTRFS RAID1 setup, created the loopdevice on the BTRFS mountpoint (same of /dev/cache) en mounted it on /var/lib/docker. I made sure I had to NoCow flags set on the IMG file like unRAID does. Strangely this did not show any excessive writes, iotop shows really healthy values for the same workload (I migrated the docker content over to the VM). After my Debian troubleshooting I went back over to the unRAID server, wondering whether the loopdevice is created weirdly, so I took the exact same steps to create a new image and pointed the settings from the GUI there. Still same write issues. Finally I decided to put the whole image out of the equation and took the following steps: - Stopped docker from the WebGUI so unRAID would properly unmount the loop device. - Modified /etc/rc.d/rc.docker to not check whether /var/lib/docker was a mountpoint - Created a share on the cache for the docker files - Created a softlink from /mnt/cache/docker to /var/lib/docker - Started docker using "/etc/rd.d/rc.docker start" - Started my BItwarden containers. Looking into the stats with "iotstat -ao" I did not see any excessive writing taking place anymore. I had the containers running for like 3 hours and maybe got 1GB of writes total (note that on the loopdevice this gave me 2.5GB every 10 minutes!) Now don't get me wrong, I understand why the loopdevice was implemented. Dockerd is started with options to make it run with the BTRFS driver, and since the image file is formatted with the BTRFS filesystem this works at every setup, it doesn't even matter whether it runs on XFS, EXT4 or BTRFS and it will just work. I my case I had to point the softlink to /mnt/cache because pointing it /mnt/user would not allow me to start using the BTRFS driver (obviously the unRAID filesystem isn't BTRFS). Also the WebGUI has commands to scrub to filesystem inside the container, all is based on the assumption everyone is using docker on BTRFS (which of course they are because of the container 😁) I must say that my approach also broke when I changed something in the shares, certain services get a restart causing docker to be turned off for some reason. No big issue since it wasn't meant to be a long term solution, just to see whether the loopdevice was causing the issue, which I think my tests did point out. Now I'm at the point where I would definitely need some developer help, I'm currently keeping nearly all docker container off all day because 300/400GB worth of writes a day is just a BIG waste of expensive flash storage. Especially since I've pointed out that it's not needed at all. It does defeat the purpose of my NAS and SSD cache though since it's main purpose was hosting docker containers while allowing the HD's to spin down. Again, I'm hoping someone in the dev team acknowledges this problem and is willing to invest. I did got quite a few hits on the forums and reddit without someone actually pointed out the root cause of issue. I missing the technical know-how to troubleshoot the loopdevice issues on a lower level, but have been thinking on possible ways to implement a workaround. Like adjusting the Docker Settings page to switch off the use of a vDisk and if all requirements are met (pointing to /mnt/cache and BTRFS formatted) start docker on a share on the /mnt/cache partition instead of using the vDisk. In this way you would still keep all advantages of the docker.img file (cross filesystem type) and users who don't care about writes could still use it, but you'd be massively helping out others that are concerned over these writes. I'm not attaching diagnostic files since they would probably not point out the needed. Also if this should have been in feature requests, I'm sorry. But I feel that, since the solution is misbehaving in terms of writes, this could also be placed in the bugreport section. Thanks though for this great product, have been using it so far with a lot of joy! I'm just hoping we can solve this one so I can keep all my dockers running without the cache wearing out quick, Cheers!1 point
-
DEPRECATED
 1 point
1 point -
Ironwolf and Ironwolf Pro drives have an advanced health management feature where the NAS can start a health check. This health check seams to be different from the SMART checks, but I do not know it. Is it? This feature supported e.g. by Synology DSM, you can schedule runs of this health tests as you like. I am wondering if unraid does in any way make use of this feature. Can someone please comment? The background of the question is: The Seagate Exos drives (Enterprise segment, longer lifetime and warranty, faster) are currently cheaper than the Ironwolf drives. However, the Exos drives do not ship with the health check feature. So everything seems in favor for the Exos drives at this point in time, I am just holding back because of the health check feature.1 point
-
Does IHM exist within UnRaid? It would, for me, sit squarely inside the "Nice to Have" department.1 point
-
Yeh, I think it was worth the price. I bought mine for 99 Euros at amazon.de. It seems like it's more expensive now tho.1 point
-
Sweet, that's all my questions answered. I'll be hitting that purchase button shortly Thanks!!1 point
-
Yes Yes Mostly yes. Keep a backup of the stick somewhere else. (You can create a backup from within the GUI) You'll definitely need the contents of the config folder on it to place onto the replacement stick. After that, the GUI will walk you through replacing the registration key tied to the original to the new one. Worst case scenario if you lose the backup is that you'll have lost the assignments of the disks, so you reassign them appropriately, and then contact limetech to get a replacement key for the new one.1 point
-
There is a good chance that a file system repair can be done on the original drive so that it can be mounted again.1 point
-
Have you still got the original drive? If so it might be possible to retrieve files from there?1 point
-
You probably want to do this1 point
-
The dockers themselves aren't that big an issue, but one that is misconfigured could end up consuming a lot of memory.1 point
-
OK so I have swapped out the PSU's from my unRAID machine and my Gaming machine. I do not have a Corsair 650Watt as per the original post it is a cooler master 650Watt same as my 1000Watt Cooler Master in my gaming Rig(Photo below of the 2 PSU's). Put the 1000W in the unRAID machine and also removed my Sata extenders as I have 16 x Sata connectors on my 1000W PSU. I was also able to remove my Molex splitter as the 1000W PSU molex can reach as I have put the PSU in the top chamber of the case where I had the other one in the bottom (Antec 1900) I turned the unRAID box back on and let it do the Pre clear on the 2 "Dead" drives. I have also plugged all drives into my Dell H310's now so none of them are on the motherboard at present. Photos below. But as it is a lovely 20c in Isolation today we decided to have a BBQ (Last photo) so the Gaming PC is still in bits and will put it together tonight or tomorrow. For now the unRAID machine is showing 0 errors so will wait and see how it goes over the next week as I need to do the Pre clear then add the drives back into the array and do a parity SYNC. Fingers crossed.




 1 point
1 point -
This has been a very rare recurring problem. (probably only noticed via CA because of it's release frequency vs other plugins). I can replicate one way that this can happen and the OS was patched to prevent that, but I've changed the install plugin ever so slightly for what I *think* might have happened here. Time will tell.1 point
-
If you check the Docker logs you'll see that it's missing an variable. We updated the template but you need to add it manually for now. https://github.com/selfhosters/unRAID-CA-templates/issues/1101 point
-
SMART tests confirm disk2 is failing and needs to be replaced, since there's no data you can just rebuild to a new disk, or do a new config with a new disk2 and re-sync parity. Syslog is cleared after a reboot, this might help if it happens again.1 point
-
Hello Binhex! Thank you for your amazing work! I especially love this qBittorrent/VPN combo, gives me such piece of mind. I am having trouble where this container seems to have just stopped. I had it behind a reverse proxy LetsEncript and it had its own DNS (not subfolder) and it worked great. Then I had to switch things up and I made it a subfolder and it stopped working. However, I do not think this is the problem because it would still work when trying to access it from my local network (localhost:8080) but that has since ceased to work without any obvious reason. I only get the 'Site cannot be reached' and reloading doesn't work. I have tried to clear cookies and use different browser with no luck. On top of this, I also use your amazing Radarr container as well as the Krusader one and neither of those will load either, not from the reverse proxy subfolder or localhost. I didn't touch any of the container settings from the time it worked to the time it stopped. Only thing that has changed was the subfolder (nothing changed for Radarr or Krusader and Krusader is not behind reverse proxy) Things I have tried: Stopping and restarting the container Stopping/restarting Letsencrypt Deleting config file Updating to latest Downgrading to 4.1.9 (last working for me) Checked for port conflicts and didn't find any Log is full of this: 2020-04-04 22:03:49,560 DEBG 'start-script' stdout output: [warn] Response code 000 from curl != 2xx [warn] Exit code 7 from curl != 0 [info] 5 retries left [info] Retrying in 10 secs... Any help you can offer I would greatly appreciate it!1 point
-
Update you can now sort folders import/export of folders is also a thing now (there might be a few bugs lurking so watch out ) url can now open in new tab yeahhh (its a new type not just a switch button )1 point
-
Hi there, Good luck on your journey, it looks like I am looking for similar answers and advice too.1 point
-
Very sure. This is my image config: And I recorded a video. But hey, it works at the 3rd time of install lol! Steps I did: 1. Open a terminal in unraid, and rm -rf /mnt/user/appdata/Nextcloud folder 2. Created this image and run it 3. Start the install. Note that it says some apps failed to install, not sure which app. During my first and second try, it didn't mention any error. 4. This time it... works! Not sure why. I made a video, fast forwarded most of the really long parts this time. Slightly longer than a minute. I don't mind talking via discord. I'm at the unofficial unraid discord server https://discordapp.com/invite/qWPbc8R nextcloud.mp4
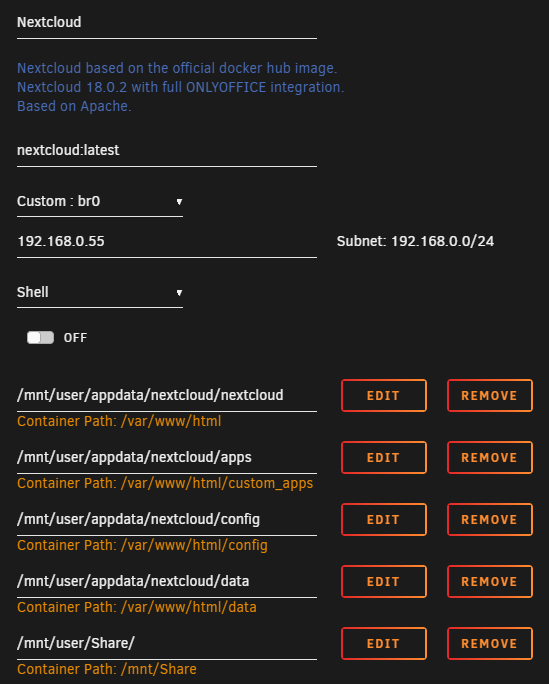 1 point
1 point -
I am using a g4 datatraveler but it is already soucted I already have the whole installation again in a sandisk and support I have already authorized the new key and I was able to recover 100% of everything with a little work this time I already have a backup of the usb in case it happens again thanks to all1 point
-
Did you Google error 522? It tells you exactly what the problem is. Cloudflare can't reach your server. Check your port forwarding https://blog.linuxserver.io/2019/07/10/troubleshooting-letsencrypt-image-port-mapping-and-forwarding/1 point
-
No, only the trial license requires internet connection, and only at array start.1 point
-
Do you have a link for this? Will do.1 point
-
This too coming in 6.9 release.1 point
-
https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.6-Released1 point
-
Thanks to @bonienl this is coming in 6.9 release!1 point
-
Awesome work buddy much appreciated.1 point
-
Hey! Sorry for the long wait, but here are all the cases you've requested!














 1 point
1 point -
Multiple cache pools being internally tested now. Multi array pools not in the cards for this release.1 point
-
Yes. This may be a problem for certain windows apps because you might create a file named "MyFile" but windows is permitted to open as "MYFILE" and this will result in "file not found". In 6.8.3 we added a share SMB config setting called "Case-sensitive names" which can take on the values Auto, Yes, or Forced lower. Here's the Help text: > The default setting of **auto** allows clients that support case sensitive filenames (Linux CIFSVFS) > to tell the Samba server on a per-packet basis that they wish to access the file system in a case-sensitive manner (to support UNIX > case sensitive semantics). No Windows system supports case-sensitive filenames so setting this option to **auto** is the same as > setting it to No for them; however, the case of filenames passed by a Windows client will be preserved. This setting can result > in reduced peformance with very large directories because Samba must do a filename search and match on passed names. > > A setting of **Yes** means that files are created with the case that the client passes, and only accessible using this same case. > This will speed very large directory access, but some Windows applications may not function properly with this setting. For > example, if "MyFile" is created but a Windows app attempts to open "MYFILE" (which is permitted in Windows), it will not be found. > > A value of **Forced lower** is special: the case of all incoming client filenames, not just new filenames, will be set to lower-case. > In other words, no matter what mixed case name is created on the Windows side, it will be stored and accessed in all lower-case. This > ensures all Windows apps will properly find any file regardless of case, but case will not be preserved in folder listings. > Note this setting should only be configured for new shares. "Auto" selects the current behavior (and is actually the current default). If you need both faster directory operations because you have huge number of files in a directory, AND you have to preserve window case-insensitive filename semantics, then you can use "Forced lower". But if you set this for an existing share, you will need to run a shell command to change all the file and directory names to all-lower case. Then if you create "MyFile" it will be stored and show up in directory listings as "myfile". If windows tries to open "MYFILE" samba will change requested filename on-the-fly to "myfile" and thus be able to find it.1 point
-
It means you have filesystem corruption on that disk, which in this case is your cache disk. https://wiki.unraid.net/index.php/Check_Disk_Filesystems1 point
-
So, I'm new to this docker. I've been using the controller through a Windows 10 VM... but I love the idea of having it as a docker instead. As someone else suggested, the only way I could get the controller to adopt my AP's (they were in the adopting/disconnecting loop) was to switch it from bridge to host... which then adopted them immediately, then put it back in bridge mode (the docker that is). What's the biggest differences between bridge and host? What harm would it cause if I left it in host mode? Also, and perhaps it has nothing to do with the docker, but figured I'd ask anyways. I'm having issues with just this docker's web gui being accessible when using a subdomain with port forwarding on my router. If I type in my static ip:randomport (I've assigned this port on my router to forward to the unraid server's ip:unifi web gui port... it loads the web gui no issue, but when I set up a sub domain on godaddy (with https) to forward to my static ip:randomport... it says it can not connect. What would cause it to be accessible when typing in my static IP, but when I use a sub domain to forward to it, it's no longer accessible? I have a lot of subdomains being forwarded to different dockers on my unraid server, and they have no issue. I only have an issue when I try to access unifi via my sub domain forwarding.1 point
-
DEPRECATED1 point










































