Leaderboard




Popular Content
Showing content with the highest reputation on 12/18/20 in all areas
-
The latest Unraid blog highlights all of the new major changes in Community Applications 2020.12.14 including: New Categories and Filters Autocomplete Improvements Repositories Category/Filter Community Applications now viewable on Unraid.net As always, a big thanks to @Squid for this amazing Unraid Community Resource! https://unraid.net/blog/community-applications-update1 point
-
The app should see all files in the Complete folder when it browses /media/.1 point
-
This is proper behavior. The app inside the container sees /media/<name of movie>. The actual location on your server will be /mnt/user/Complete/<name of movie>1 point
-
Yeah my case is correct everywhere. So it ended up being the fact that I had categories set in nzbget which nothing like.1 point
-
@xthursdayx It's been a crazy month for me personally and work-wise! Ready for this year to be over with. I was going to start with these steps, but then read the Roon docker has been updated so it works updated from an end point device now. Nice! I moved from my Ubuntu VM to the docker and updated successfully (just read I needed to delete the Roon app data folder which I did not). Now I'm restoring a backup. Runs better on the docker than it did in the Ubuntu VM via SMB. Should I remove the docker, delete the app data folder and start again? I chose to remove the image when I removed the docker.1 point
-
oh true will fix asap1 point
-
It's on two 'r's my guess is it didn't update the template for you yet as it show Overseerr for me
 1 point
1 point -
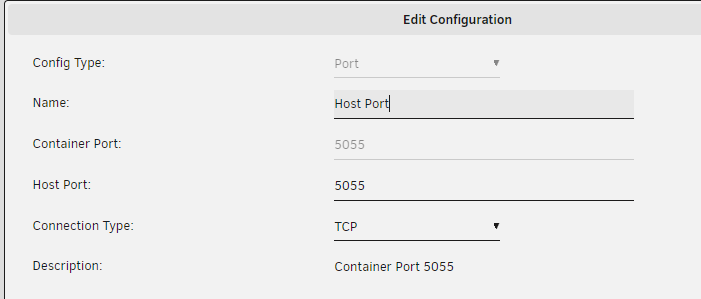
Mine worked immediately following this change. I also had to remove the Host Port 1 and then recreate it: I also had to modify the port from 3000 to 5055 in my reverse proxy config. More info about that here.

 1 point
1 point -
Righto, advice taken. A set of Crucial MX500s are on their way and the ADATAs are going back. I'll let you know how I get on when I receive and install them. Many thanks to you!1 point
-
Well, pressure is going down, thanks for the mental coaching 😉 VMs and containers restarted properly after the restoration of appdata and the move of both domains and system. Moving from array to SSD was ofc way faster than the contrary, so I didn't have to wait too long. The only expected difference I can see is the appdata, domains and system shares are now tagged with "Some o all files unprotected" in he shares tab, which makes sense, as they are on a non-redundant XFS SSD. I checked the containers for the appdata assignment, and only found Plex to have /mnt/cache/appdata. But I remember now I have changed that over time, first reading /mnt/cache was the way to go, and then reading it was no longer useful and could raise issues. I think I now understand what the author had in mind ... Anyway, I also conclude that the containers which were created with the /mnt/cache and switched afterwards to /mnt/user have this hardlink problem (krusader and speedtest-tracker for me), and that can only be resolved by a fresh install of the container. As I switched Plex right now and it restarted properly, I now have three containers whose appdata can't be moved, only backed up and restored. But enough for today, again I learnt a lot thanks to the community, even if it was a bit the hard way 😆1 point
-
1 point
-
Marking as solved. I've now confirmed that the unraid server itself isn't the bottleneck by getting 1Gb speeds between unraid and my firewall.1 point
-
Checks it on the schedule you set in Notification settings1 point
-
If there are sync errors but no disk errors you can run a correcting check, if there are sync errors and disk errors, or just disk errors, replace the disk.1 point
-
@JorgeB Thank you for your help again. The parity drive rebuild has been running for 16 hours now (with 4 remaining) and not a single error. I did two things: Updated the firmware as you highlighted in the above linked guide. For my card, I needed the P20 installer. I read elsewhere that tied or bunched SATA cables can cause interference. I gave the cables a little more space. I suspect it's mostly (1) that did it but noting both in case someone comes across a similar issue in future.1 point
-
Knock on wood but I think I'm good now. Rebuild completed with no errors and disk is enabled again. Thanks for the help!1 point
-
iMacPro1,11 point
-
Danke für den Link, da lag das Problem! Nun wird alles übertragen mit den richtigen Schriftzeichen. Es läuft aktuell noch über den Odroid, da der wenig Energiebedarf hat und der unraid Server erst neu dazu kam. Werde das vermutlich zukünftig umstellen aber aktuell bleibt es mal noch so.1 point
-
Okay. Fair decision, your call after all. Yet it still causes a significant downtime for me when the backup runs if compression only runs on one thread. I found a way to use pigz without needing to modify the plugin tho. I installed pigz via nerd tools and replaced the gzip binary with a symlink to pigz, so it's used by tar --auto-compress with the .tar.gz ending like CA Backupv2 invokes it. It yields substantial performance improvements with my 8C/16T CPU. Currently that's a reduction down to 6min from 37min (with verification of the backup file). If anyone stumbles upon this and thinks they can profit from parallel compression, it's fairly simple to do, just don't expect @Squid to fix any problems that should come up with this configuration and keep it in mind if you should ever run into a problem with CA Backupv2 to revert this before filing any bug report. Just move the original gzip binary (I renamed it to ogzip so if you should ever need it, it's still there) and then create the link: mv /bin/gzip /bin/ogzip ln -s /usr/bin/pigz /bin/gzip 'Official' support via a checkbox if pigz is detected would probably be better but this works for me and can be applied via the /boot/config/go script just fine.1 point
-
This is awesome! I've tried Ombi before but I like this better even in the ALPHA state. Looking forward to the updates!1 point
-
Hi @linuxserver.io, It seems there is an issue regarding the support of 3 last gens of intel CPUs while using this Plex App with HW HDR to SDR tone mapping. It seems one of your devs created a working solution, creating the OpenCL branch in this container GitHub here: https://github.com/linuxserver/docker-plex/tree/opencl Shall I ask you if there is any plan to provide this solution in the main tree, so we can all benefit of it without hack/trick ?1 point
-
It is important that users who choose a non subscription model, even if that is just implicit by the fact they use only the traditional unRAID product, that there be no phone home or other services that reach out of the system by lieu of the subscription services running in "off" mode of or any other mechanism. I cannot stress this enough. Feel free to add value in whatever way suits your business but dont break that trust model whilst doing so.1 point
-
Whilst it is not ideal that the poster did not follow normal security reporting etiquette it is clear there is an issue and it is off our own making. See versus http://www.slackware.com/security/list.php?l=slackware-security&y=2020 tl;dr we are long overdue an update but we have slipped into the old habit of waiting for the development branch to be ready and ignoring the stable branch. It is not the end of the world but its a habit we need to break again ASAP1 point
-
Can you be more specific? What vulnerabilities are you referring to? Vulnerabilities are ranked differently based on the complexity, feasibility of the execution and impact on Confidentiality, Integrity and Availability (aka CIA) . And you measure your own risks, @limetech addresses appropriates risks in a timely fashion as we've seen in the past. I'd like to get more context around this, what are you eluding to and what risks do you need mitigated.1 point
-
Since you are upgrading, any database conversion, if necessary, will take place in the upgrade. This is not a big leap from 5.12 to 5.14. I don't think there were major database upgrades between those two. Going up to 6.xx or downgrading from 6.xx to 5.xx is a bigger step and will involve some db changes. If you were going from LTS (5.6), to 5.14, there would be some necessary interim steps as outlined earlier in this thread.1 point
-
As I had read contradictory information on this matter, I hot-plugged a spare cold storage SanDisk SSD Plus 2TB in a spare tray. This SSD seems to have the required features, even if DRZAT is called "Deterministic read data after TRIM" : root@NAS:~# hdparm -I /dev/sdj /dev/sdj: ATA device, with non-removable media Model Number: SanDisk SSD PLUS 2000GB Serial Number: 2025BG457713 Firmware Revision: UP4504RL Media Serial Num: Media Manufacturer: Transport: Serial, ATA8-AST, SATA 1.0a, SATA II Extensions, SATA Rev 2.5, SATA Rev 2.6, SATA Rev 3.0 Standards: Used: unknown (minor revision code 0x0110) Supported: 10 9 8 7 6 5 Likely used: 10 Configuration: Logical max current cylinders 16383 0 heads 16 0 sectors/track 63 0 -- LBA user addressable sectors: 268435455 LBA48 user addressable sectors: 3907029168 Logical Sector size: 512 bytes Physical Sector size: 512 bytes Logical Sector-0 offset: 0 bytes device size with M = 1024*1024: 1907729 MBytes device size with M = 1000*1000: 2000398 MBytes (2000 GB) cache/buffer size = unknown Form Factor: 2.5 inch Nominal Media Rotation Rate: Solid State Device Capabilities: LBA, IORDY(can be disabled) Queue depth: 32 Standby timer values: spec'd by Standard, no device specific minimum R/W multiple sector transfer: Max = 1 Current = 1 Advanced power management level: disabled DMA: mdma0 mdma1 mdma2 udma0 udma1 udma2 udma3 udma4 udma5 *udma6 Cycle time: min=120ns recommended=120ns PIO: pio0 pio1 pio2 pio3 pio4 Cycle time: no flow control=120ns IORDY flow control=120ns Commands/features: Enabled Supported: * SMART feature set Security Mode feature set * Power Management feature set * Write cache * Look-ahead * Host Protected Area feature set * WRITE_BUFFER command * READ_BUFFER command * DOWNLOAD_MICROCODE Advanced Power Management feature set SET_MAX security extension * 48-bit Address feature set * Device Configuration Overlay feature set * Mandatory FLUSH_CACHE * FLUSH_CACHE_EXT * SMART error logging * SMART self-test * General Purpose Logging feature set * 64-bit World wide name * WRITE_UNCORRECTABLE_EXT command * {READ,WRITE}_DMA_EXT_GPL commands * Segmented DOWNLOAD_MICROCODE unknown 119[8] * Gen1 signaling speed (1.5Gb/s) * Gen2 signaling speed (3.0Gb/s) * Gen3 signaling speed (6.0Gb/s) * Native Command Queueing (NCQ) * Phy event counters * READ_LOG_DMA_EXT equivalent to READ_LOG_EXT Device-initiated interface power management * Software settings preservation Device Sleep (DEVSLP) * SANITIZE feature set * BLOCK_ERASE_EXT command * SET MAX SETPASSWORD/UNLOCK DMA commands * WRITE BUFFER DMA command * READ BUFFER DMA command * DEVICE CONFIGURATION SET/IDENTIFY DMA commands * Data Set Management TRIM supported (limit 8 blocks) <------ * Deterministic read data after TRIM <------ Security: Master password revision code = 65534 supported not enabled not locked not frozen not expired: security count not supported: enhanced erase 2min for SECURITY ERASE UNIT. Logical Unit WWN Device Identifier: 5001b444a7732960 NAA : 5 IEEE OUI : 001b44 Unique ID : 4a7732960 Device Sleep: DEVSLP Exit Timeout (DETO): 50 ms (drive) Minimum DEVSLP Assertion Time (MDAT): 31 ms (drive) Checksum: correct I mounted the drive with UD, and fstrim seems to work fine with my SAS2308 HBA (IT mode firmware 20.00.07.00) : root@NAS:~# fstrim -v /mnt/disks/WKSTN/ /mnt/disks/WKSTN/: 1.8 TiB (2000201273344 bytes) trimmed So maybe something has changed with the latest versions of the drivers ? That's beyond my technical skills, but I just wanted to report for others who would wonder about TRIM support behind this HBA/firmware couple. Thanks again for your help @JorgeB !1 point
-
There is already an image tag called "v4-preview" for testing and dev purposes. When tidusjar (ombi dev) pushes v4 to master/stable, our image will update the latest tag accordingly.1 point
-
I need some help here. Ive switched from the linuxserver version of nzbget to binhex. Now Sonarr can't find the downloaded files. It seems as if the mapping for /data in the container does not work. The download is within the container at /usr/local/bin/nzbget/downloads/completed. And after completion it is clear that Sonarr cant find the file thats within the container. Can somebody tell me what I am doing wrong?1 point
-
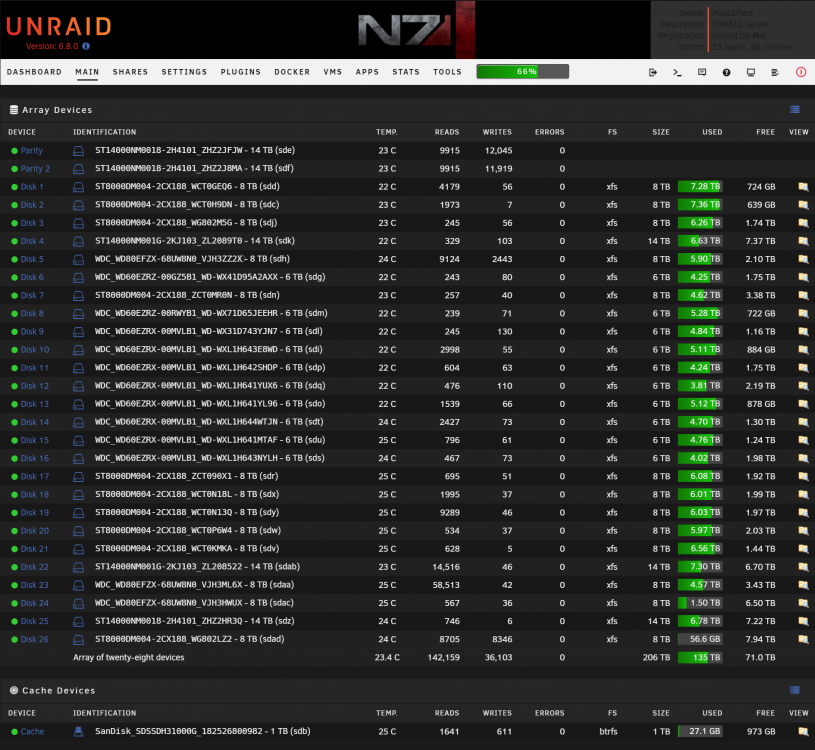
I just Friggin hit 206TB usable. Approaching .25PB 😍
 1 point
1 point -
Yup...it's saving to "/usr/local/bin/nzbget/downloads/completed/Series/" INSIDE the Docker. Can anyone shed some light on how to set up the paths in NZBGet?1 point
-
Got it downloading! Yay! Still not seeing anything in my Media/TV Shows folder, though. Boo... If I go into NZBGet and click on the completed file, it has a path of "/usr/local/bin/nzbget/downloads/completed/Series/showname". Is it saving IN the Docker container?1 point
-
I've been down some crazy rabbit holes with windows before, but this one really takes the cake. A little googling, and you quickly see that tons and tons of people have experienced this particular error. There are dozens upon dozens of potential solutions, ranging from simple to extremely complicated and everything in between. Reading posts of people's results couldn't be more random. For every person that is helped by a particular solution, there are twenty people for whom it didn't work. I myself had tried about a dozen of the best sure-fire fixes without any success. I really didn't have much hope, but I took a look at the post linked above. The thread started in August of 2015. One common thread in error 0x80070035 posts is the 1803 windows 10 update so I decided to jump ahead to the end of the thread. Low and behold, on page 5, the first post I read struck a chord for some reason. Even though I was quite tired of trying random things without success, I decided to give this registry edit a try. As soon as I added the key below I was able to access the unraid server. I didn't even have to reboot. HALLELUJAH!!!! Try: (Solution) https://www.schkerke.com/wps/2015/06/windows-10-unable-to-connect-to-samba-shares/ Basically the solution follows, but you'll need to use regedit: add the new key HKLM\SYSTEM\CurrentControlSet\Services\LanmanWorkstation\Parameters\AllowInsecureGuestAuth key, value set to 1 It's interesting to know one of my other computers that works doesn't have this key, but it has "AuditSmb1Access" which set to 0, which this computer doesn't have. I checked one of windows 10 home machines, and like the post above it does not have the AllowInsecureGuestAuth key, but does have the AuditSmb1Access key set to 0. My windows 10 pro machine, the one the could not access my unraid server, had the AllowInsecureGuestAuth set to 0. Setting this to 1 appears to have fixed my problem. I'm not certain, but I suspect the different keys could be linked to one being Home and the other Pro. Again I'm just guessing, but the name suggests that access was blocked because the share lacked a password. I guess it's a security thing, but it's kind of an unexpected default setting. I wonder what GUI setting this is associated with. I don't recall ever seeing a windows setting to block access to open servers. I don't even want to test and see how much frustration I could have saved myself if I had simply secured the share and set a password from the start.1 point
























