Leaderboard


Popular Content
Showing content with the highest reputation on 12/27/20 in Posts
-
Redis starts now with the recommended parameter, hope that fixes the error, please update the container (force-update on the Docker page with advanced view turned on) and report back. No, actually the developers doesn't released a Linux version of the dedicated server yet. I know that it is possible to run it through WINE but that's not my preferred way of doing it since it can add much overhead and also lead to other problems... I recommend to post on the official Empyrion forums if there is any progress... Have you installed a Cache drive in your server? If not can you send me a screenshot of you docker template page? Keep in mind that if you have no cache drive installed that you have to specify the exact path of the gamefiles for example '/mnt/disk2/appdata/garrysmod' and not with the 'user' prefix since this game needs to know the physical location where the files are (also please keep in mind that it has to be on one disk and should not be spreaded over multiple array disks).2 points
-
Introduction unbalanced is a plugin to transfer files/folders between disks in your array. Support Fund If you wish to do so, learn how to support the developer. Description unbalanced helps you manage space in your Unraid array, via two operating modes: Scatter Transfer data out of a disk, into one or more disks Gather Consolidate data from a user share into a single disk It's versatile and can serve multiple purposes, based on your needs. Some of the use cases are: Empty a disk, in order to change filesystems (read kizer's example) Move all seasons of a tv show into a single disk Move a specific folder from a disk to another disk Split your movies/tv shows/games folder from a disk to other disks You'll likely come up with other scenarios as you play around with it. Installation - Apps Tab (Community Application) Go to the Apps tab Click on the Plugins button (the last one) Look for unbalanced Click Install Running the plugin After installing the plugin, you can access the web UI, via the following methods: - Method 1 Go to Settings > Utilities Click on unbalanced Click on Open Web UI - Method 2<br/> Go to Plugins > Installed Plugins Click on unbalanced Click on Open Web UI - Method 3<br/> Navigate with your browser to http://Tower:7090/ (replace Tower with the address/name of your unRAID server)<br/> Check the github page for additional documentation Changelog The full changelog can be found here1 point
-
If you do a docker hub search within Apps (enable it in options), there's far more up to date versions of CUPS than what was available within apps.1 point
-
Yes, depending upon your allocation method, split level, include / exclude settings.1 point
-
Unraid never moves files from old disks to new ones. To do that, you'd want something like unbalance.1 point
-
That shouldn't be a problem.1 point
-
Same here. Broke all connections to my USB devices. You could try doing chmod 777 /dev/ttyACM0 in the server terminal and restart Domoticz. If it works, add the command to your go file.1 point
-
I actually just got it working again, I just changed the container path to /Movies and re added it to root folders in Radarr. For some reason it wasn't working with /Media which is what I use for Sonarr. I'm not completely sure if that was the root cause but at least its fixed.. Thanks for the help and step in the right direction!1 point
-
Even though I scratched mine out, looks like the 9500K limit and trickling all day might be the best way for you.1 point
-
I now also downloaded and installed the container and it starts just fine and I can query it from the Steam Server Browser, attached the log here: garry.log Can you try the following: Delete the container entirely Open up a command prompt from Unraid itself and type in: 'rm -rf /mnt/user/GModTest/' (without quotes) Also 'rm -rf /mnt/user/Steamcmd/' (without quotes) - I recommend leaving SteamCMD in the appdata directory... Download it again from the CA App What filesystem is your Array formated with? Can you eventually try to setup a Unassigned Devices disk (if you got a Disk somewhere lying around) - the path would then be something like '/mnt/disks/DISKNAME/garrysmod'1 point
-
If you are using openhab/openhab:latest-debian as openHAB Repository you are getting that update automatically.1 point
-
Hmm i see, in my case it was the formatting of my plex cache ssd in unraid, fomated it to NTFS first but that gave loads of errors while transcoding so had to switch to XFS and all started working flawless... but in this case i think i cant help sorry, this is all i know ^^1 point
-
It's an unassigned slot in the array. I've made an update that will ignore a non-existent disk.1 point
-
That would probably be it. `docker ps` will show you what’s running and `docker kill <id>` will take it down. You should be able to use the name (label) or the hex id, I think.1 point
-
@nikaiwolf You will need to add a volume mapping to all of the servers that you want clustered that they can all read/write data to. add this mapping to all of your containers: /serverdata/serverfiles/clusterfiles <> /mnt/cache/appdata/ark-se/clusterfiles When you look in /mnt/cache/appdata/ark-se/clusterfiles you should see a folder with the name of your cluster.1 point
-
when you Pm'd me i assumed that you read through my earlier posts about ARK... the automodmanager that wild card crammed in has all of its paths hardcoded into the game engine. Your choices are to install "YACOsteamCMD" (Yet Another Copy Of SteamCMD) or create some additional volume mappings for your container so that the game engine can find the SteamCMD folder and to the location of the workshop files, or to copy the workshop files from your client PC game folder to the server game folder. Adding these volume mapping should fix up the automodmanager: /serverdata/serverfiles/Engine/Binaries/ThirdParty/SteamCMD/Linux <> /mnt/user/appdata/steamcmd /serverdata/Steam/steamapps <> /mnt/cache/appdata/steamcmd/steamapps /serverdata/serverfiles/Engine/Binaries/ThirdParty/SteamCMD/Linux/steamapps <> /mnt/cache/appdata/steamcmd/steamapps1 point
-
the dynamic config is for a small number of options that can be changed without restarting the server. ?customdynamicconfigurl="<link>"a direct link to config file e.g.: http://arkdedicated.com/dynamicconfig.ini ; currently only the following options are supported to be adjusted dynamically: TamingSpeedMultiplier, HarvestAmountMultiplier, XPMultiplier, MatingIntervalMultiplier, BabyMatureSpeedMultiplier, EggHatchSpeedMultiplier, BabyFoodConsumptionSpeedMultiplier, CropGrowthSpeedMultiplier, MatingSpeedMultiplier, BabyCuddleIntervalMultiplier, BabyImprintAmountMultiplier, CustomRecipeEffectivenessMultiplier, TributeItemExpirationSeconds, TributeDinoExpirationSeconds, EnableFullDump, GUseServerNetSpeedCheck, bUseAlarmNotifications, HexagonRewardMultiplier and NPCReplacements. Introduced in patch 307.21 point
-
Hi, so I have an update. I found many posts with similar errors, but they were largely left without a solution so hopefully this helps someone else! I tried moving my script's cronjobs around and noticed the 'unlink_node: Assertion `node->nlookup > 1' failed' error appeared roughly around the same time, but when I moved it a few hours ahead of schedule and had nothing around the 3am mark, my shares stopped vanishing. I seeemed to have narrowed it down to the 'Recycle Bin' plugin. The Recycle Bin plugin was set to run it's cleanup and dump it's folder around 3am too.I believe since I'm moving and deleting a large amount of files right around the same area, things got wonky. Easiest solution for me was to just remove the Recycling Bin plugin altogether. I just never used it and I'd rather not schedule around it. It's been about 5 days now without shares vanishing so hopefully that was it!1 point
-
I think you can re-install the old plug-in from May by going to the history of the github and posting this URL (May 11th version of the plug-in script) into the URL for install plug-in. However, I have not tried this. https://raw.githubusercontent.com/hugenbd/ca.mover.tuning/6c146ad3ad63d162488d7e965c011d48d3e47462/plugins/ca.mover.tuning.plg1 point
-
Hi, Well, the backup process has been running continuously for 4 days and a half, so I can step back a bit more now. The data to be backed up is 952 GB locally, 891 GB have been completed, and the remaining 61 GB should be uploaded in 11 hours from now. So, the global "performance" should be 952 GB in 127 hours, an average of 180 GB per day. Roughly, that is 2.1 MB/s or 17 Mbps, which is consistent with the obvious throttling I can see in Grafana for the CrashPlan container upload speed. Data is compressed before being uploaded, so translating the size of the data to backup into network upload size is not totally accurate, but the level of compression will highly depend on the data you back up. For me, 893 GB backed up so far translated into 787 GB uploaded, i.e. a compression ratio of 88%. To sum up, if you get the same upload speed and compression ratio as me, your initial 12TB backup should generate 10.8 TB (10,830 GB) to upload at an average speed of 180 GB per day, i.e. circa 60 days ... Btw, as the upload speed of your internet connection seems to be 20/25 Mbps, the best you can expect to upload this amount of data is circa 40/50 days. So, you wouldn't be that throttled. For the 10GB per day you heard of, I suppose that's what you found in the CrashPlan FAQ. Let's say it's somehow their commitment, even if it's not legally binding, so they take very very little risk not to fulfill it, it's circa 1 Mbps ... As for the system resources, the container has an avg CPU load of 9% (Ryzen 7 3700X CPU), avg 1.2 GB memory load (out of 32 GB), and a constant Array I/O read of 2 MB/s. So, you can see it's running, but it has a low footprint on the global server load. I hope that can help you decide on your backup strategy.1 point
-
I only saw the connection issues on one disk in syslog so those CRC on the other disk could be old. The counts don't reset but you can acknowledge them as I mentioned. Since other disks don't seem affected I would be more inclined to suspect cables or just a loose connection. Make sure there isn't any tension on the cables that might disturb the connection and don't bundle SATA cables.1 point
-
SOLVED! This issue has been fixed by changing my NIC device to built-in. Here is link to guide so its easy to find. Have Big Sur up and running with passthrough gpu and nvme, everything is running fine apart from being able to sign into iCloud. I can sign into the App Store fine just not iCloud, I get the following error "could not communicate with server" I have tried with all different virtual NIC types and have even passed through an intel Nic that's working. Just no luck. Have also tried different smbios. Any help would be great as this is the last thing to get this 100% Thanks in advance
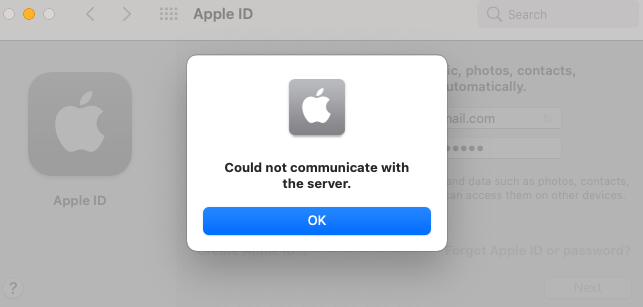 1 point
1 point -
Yes you can, you just to need to make sure that those dockers/vms are not filling up the target disks, otherwise the transfer may run out of space to put files.1 point
-
If Music was a top-level folder (share), per design, the app doesn't delete it.1 point
-
This should be fixed in 6.9.0-beta24.1 point
-
I would use these sshd configurations + setting the users disabled. I don't think having users with empty passwords is a good idea. Thanks for the fast reply!1 point
-
If a reallocation event happens once, and never again, it's not a concern. If it repeats again, it's time to pay attention. 3rd event, plan a replacement. If you get several reallocation events back to back, prepare to lose the drive, probably sooner rather than later. The number of sectors is a factor, but the rate of increase is what is most concerning. Some drives reallocate a dozen or so sectors, then stay quiet for years.1 point
-
You certainly can use XFS for a single member cache. It's only when you have multiple cache device slots defined that you are forced to use BTRFS, because at the moment XFS doesn't support RAID volumes. The major downside to BTRFS is that it seems to be more brittle or fragile than XFS. What I mean by that is a lack of tolerance for hardware or software errors, and the recovery options for broken BTRFS volumes aren't as robust as the tools available for XFS, so having a comprehensive backup strategy is, as always, a high priority. So, if you are running server grade hardware with robust power conditioning, BTRFS has more options and features than XFS.1 point
-
If as you try to access unsecure unRAID, you see this panel, insert \ backslash for user ID and click OK, your in.
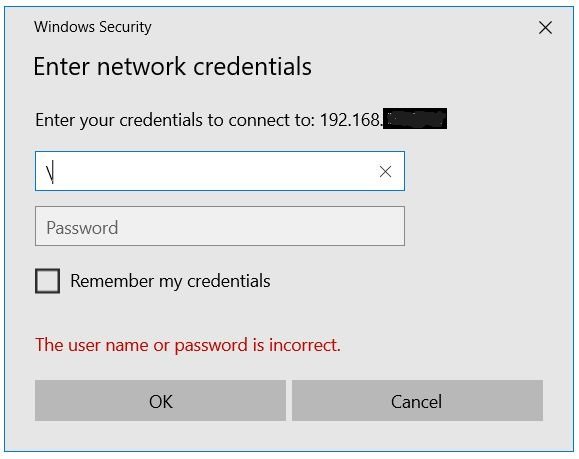 1 point
1 point -
Here's what I do when I replace a data drive: 1. Run a parity check first before doing anything else 2. Set the mover to not run by changing it to a date well into the future. This will need to be undone after the array has been recovered. 3. Take a screenshot of the state of the array so that you have a record of the disk assignments 4. Ensure that any dockers which write directly to the array are NOT set to auto start 5. Set the array to not autostart 6 Stop all dockers 7. Stop the array 8. Unassign the OLD drive (ie: the one being replaced) 9. Power down server 10. Install the new drive 11. Power on the server 12. Assign the NEW drive into the slot where the old drive was removed 13. Put a tick in the Yes I want to do this box and click start. The array will then rebuild onto the new disk. Dockers that don't write directly to the array can be restarted. When the rebuild is complete, the mover, docker and array auto start configuration can be returned to their normal settings. NOTE: You CAN write to the array during a rebuild operation, but I elect not to do so, to ensure my parity remains untouched for the duration of the recovery. Reading from the array is fine as the device contents are emulated whilst the drive is being rebuilt.1 point
-
Here's a sample that will only allow the 192.168.2.* machines write access to the NFS share. Everybody else gets readonly Additionaly, the options allow root user access from the 192.168.2.* machines. Everybody else gets mapped to uid=99 192.168.2.0/24(sec=sys,rw,no_root_squash,insecure) *(sec=sys,ro,insecure,anongid=100,anonuid=99,all_squash) So, if the client IP fails to match whatever you have listed, they don't get access.1 point
















