Leaderboard



Popular Content
Showing content with the highest reputation on 01/15/21 in Posts
-
Hello Unraid community, The Unraid forum is now on Invision Community v4.5.4.2. You also might have noticed a UI update as part of this upgrade sequence. During the update process, we received reports of low forum latency which had to do with an internal server slowdown issue. This issue should be resolved now. Thank you to everyone who reached out to report this. If you are experiencing any other forum related issues, please post them in Forum Feedback or you can also reach out to me directly. I hope you all have a great day! -Spencer2 points
-
That is awesome! You are the 3rd to report a working navi card in this thread! Yesterday, @derpuma reported that he could even force stop a vm and boot afterwards As we should not hesitate.... can you try that, too?! Just kidding.... Have fun with it!!!2 points
-
Both the Nvidia drivers and the vender-reset are working; there were no issues booting up. Thank you so much for your help and hard work, I really appreciate it! If you need someone to test future changes or updates don't hesitate to reach out.2 points
-
I am running a custom build with nvidia support and the vendor-reset. Please do a new build with the kernel-helper but integrate nvidia support into it. Remove the nvidia plugin if you readded it.2 points
-
Hello Unraid Community, I made a beginners guide/tutorial to install/setup Unraid (It was using v6.6.6). I cover the following topics: USB Key - 18:00 BIOS - 3:42 Disk Array - 4:56 Parity Check - 10:30 Format Drives - 11:03 Single Share - 11:38 PSA - 21:11 Security - 22:11 Share per Media Type - 28:43 APC UPS - 40:36 10 Gigabits/Second Transfer Test - 43:11 Share Troubleshooting - 44:41 I hope it helps those looking for some initial direction to get started and be inspired to continue their Unraid journey. How to Install & Configure an Unraid NAS - Beginners Guide1 point
-
Hi I just build a kernel to support X570 motherboard (mine is msi x570 ace) and latest AMD Ryzen 2 3000 family CPU. 6.8.3 is out, here is the new kernel and some tweaks: Add Vega Reset Patch Add Navi Reset Patch Enable NFSv4 in kernel(God damned, we finnaly get nfsv4 to work) Add R8125 out tree driver. AMD onboard audio/usb controller flr patch. Provide two version (linux-5.5.8 and linux-4.19.108) in case of bug. Notice that linux-4.19.108 still don't have AMD Zen 2 suppport. Download url can be found in the latest comments. For those who want to use NFSv4: NFSv4 have some change compared to v2/v3, it must have root share and the nfs-utils version can't handle it well.You must add this script to UserScript Plugin triggered when array start: #!/bin/bash # Add NFSv4 root echo '"/mnt/user/" -async,no_subtree_check,fsid=0 *(sec=sys,rw,insecure,anongid=100,anonuid=99,all_squash,crossmnt)' >> /etc/exports # Load configuration exportfs -ra # Tunning mkdir -p /var/lib/nfs/v4recovery sed -i 's@/usr/sbin/rpc.nfsd 8@/usr/sbin/rpc.nfsd 32@g' /etc/rc.d/rc.nfsd # Restart Services /etc/rc.d/rc.nfsd restart And if you have trouble mount nfsv4, you can specify mount vers=3 on client. Edit at 2020.01.31 The procedure of compiling kernel(you can compile it in other linux distribute or linux VMs): download kernel sources from kernel.org, notice that should be same or related version of unraid(like 4.19.94 which 6.8.2 used) unarchive the kernel source zip, like kernel-4.19.94/ copy the patches and .config (important!) from unraid server which located at /usr/src (like /usr/src/linux-4.19.94-Unraid/) to step 2 source directory (Optional) copy custom patches like navi patches or others to source directory too apply patches: find . -type f -iname '*.patch' -print0|xargs -n1 -0 patch -p 1 -i use old config : make oldconfig compile the kernel and modules: make -j5 bzImage; make -j5; make -j5 modules installing the modules, then you can find the module directory in /lib/modules: sudo make modules_install Copy the kernel image: cp sources/linux-4.19.94/arch/x86_64/boot/bzImage releases/6.8.2-4.19.94/bzimage (Optional) ThirdParty modules compiling (like nic r8125 outtree driver): enter the thirdparty driver directory compile the module: make -C /lib/modules/4.19.94-Unraid//build M=(pwd)/src modules install the module to direcotry: sudo make -C /lib/modules/4.19.94-Unraid/build M=(pwd)/src INSTALL_MOD_DIR=kernel/drivers/net/ethernet/realtek/ modules_install you can check whether the module exists in /lib/modules/4.19.94-Unraid/kernel/drivers/net/ethernet/realtek/ archive the modules to bzimage: mksquashfs /lib/modules/4.19.94-Unraid/ releases/4.19.94/bzmodules -keep-as-directory -noappend Then you get the bzimage and bzmodules, copy it to unraid server: /boot/
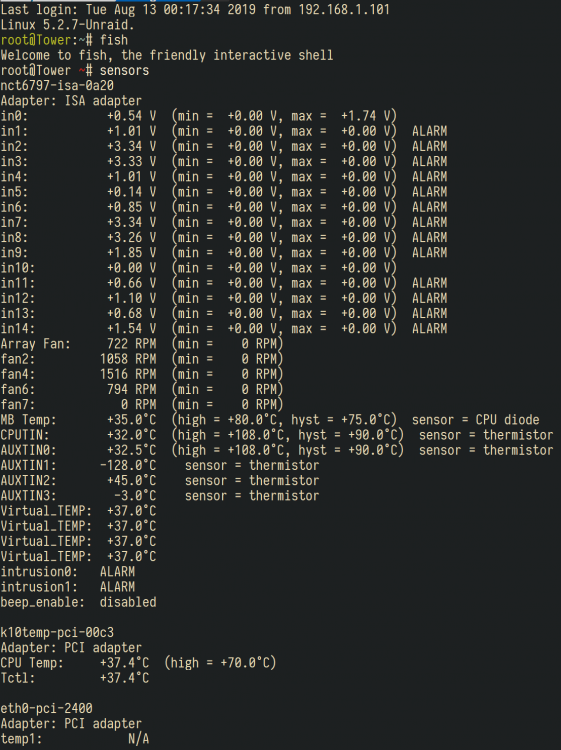
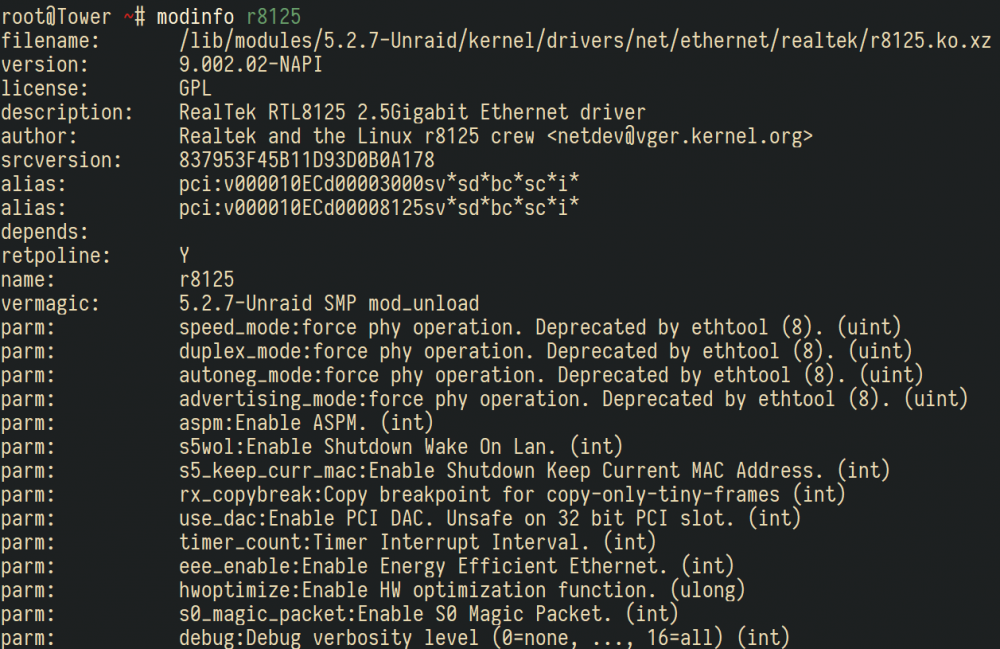 1 point
1 point -
Problems with the flash drive. Put it in your PC and let it checkdisk. Be sure to boot from a USB2 port.1 point
-
Was having issues that later turned out to be a failing SSD cache drive in a cache pool. The SSDs had 4yr 8months on them(Crucial MX200 x 2 500G). Replaced with 2 x 1TB WD RED SSDs. This failing SSD even when put back in as an Unassigned Device SSD, Unraid would report errors and sometimes Unassigned Device would lose the device, making all Unassigned Devices SSDs disappear(on same MB controller, spinning drives on 9211-8i). Which temporarily caused the new Cache pool SSDs to get lost too. So fully removed the almost 5yr old 2 x SSDs fully. And haven't had an issue since. On the new cache pool SSDs had to delete the files that btrfs scrub said uncorrectable errors(only a TV show and on Docker). So while I got everything working fully will stay at 6.8.3 for now. When I lost the 5yr old SSDs I lost all my Dockers. Yes I started using thr CA Backup plugin. And had to rewrite my DelugeVPN-flexget Docker to get it caught up with Binhex-DelugeVPN.1 point
-
You can now switch to the new 'feature/audio-reset' of the vendor-reset. Just use @ich777's docker to compile your custom build as you need it. I can boot between Windows 10 20H2, Ubuntu 20.10 and macOS Big Sur 11.1 Afaik @derpuma runs catalina atm and he also reported that everything is working properly. In addition, even the old navi patch could not help him with his powercoler 5700xt. Oh, and he even just fully send it yesterday by force stopping a vm. After starting the vm again he could just go on as if nothing had happend. So this is not just an alternative, but even a possible solution for people having problems with the navi patch.1 point
-
yes I know the fault is not on the unraid side.. will take the time tomorrow and test.1 point
-
The prebuilt images at the bottom just work fine, I've updated them recently. The build for 6.8.3 is not possible or at least will fail, I had to remove this version because of some strange requests here in this thread on page 22 and blaming me for some things... Yes becaus it's now only for 6.9.0rc2 and up The build will fail because it's not compatible... Glad to hear that everything is working now.1 point
-
I still haven't found the time to shuck and, more to the point, disassemble the server to drop in the drives. I'm waiting on another part to arrive (caught up in Christmas/Brexit shipping fiasco) so once that's here, I'll do so and report back. The pre-celaring was not so much to preclear as to run the drives at some degree of intensity while still in their cases to see if there would be any issues that would merit a warranty return. (none showed up). Also, these will be parity, and I can't recall if parity disks actually need a pre-clear Anyway, will report back once I get a chance to do the installation.1 point
-
Yes und Only sind tatsächlich das Gegenteil voneinander. Bei Yes wird der Cache nur solange genutzt, bis der Mover die Daten auf die HDD verschiebt. Bei Only wird ausschließlich die SSD genutzt. Ich empfehle allerdings Prefer. Prefer ist wie Only, nur dass beim Volllaufen der SSD der Container nicht abstürzt (weil er nichts mehr speichern kann), sondern weiter auf der HDD abspeichern darf. Du kannst außerdem keinen Share direkt auf der SSD erstellen, sondern der wird in Abhängigkeit der Cache-Einstellung dort erstellt. Also bei "Prefer" landet ein neuer Ordner auf der SSD (und bleibt da). Wenn beim Öffnen von ioBroker die HDD anspringt, dann vermutlich, weil der Share "appdata" oder "system" nicht vollständig auf der SSD liegt. Prüfen kannst du das, in dem du auf Shares wechselst und dann rechts "View" anklickst. In der Spalte location steht dann wo die Unterordner von "appdata" bzw "system" liegen. In meinem Fall liegen zB alle Ordner außer "appdata" brav auf der SSD: Wenn das bei dir nicht der Fall ist, dann prüfe noch mal ob die Shares auf "Prefer" stehen. Tun sie das, musst du in den Einstellungen Docker und VM deaktivieren und über die Übersicht den Mover starten. Wenn der dann fertig ist, schaust du noch mal über "View" ob nun alle Daten auf dem Cache liegen. Wenn ja kannst du Docker und VM wieder starten. Der Mover kann nur Dateien bewegen, die nicht in Benutzung sind. Daher kann es gerade zu Anfang passieren, dass die Dateien auf Cache und Array verstreut liegen. Aber durch die Deaktivierung von Docker/VM kann der Mover alles korrekt verschieben und danach wird das nicht mehr passieren.
 1 point
1 point -
lol, ok that just got weird real quick, but YES it works!!!!! highlight of my week, i know i should get out more :-), thanks Spencer, and yes i do indeed love you long time.1 point
-
How about meow?1 point
-
this is certainly one way of doing it, but for me this wouldnt work too well as i have split tv/movie collections, so i use the more granular control you get with sonarr to ensure the right file goes in the right location and is also post processed for filename changes and crud removal.1 point
-
typically its the metadata downloader (such as sonarr, radarr etc) NOT the download client (such as deluge) that does the copying (note i didnt use the word move, as sonarr etc generally do a copy not a move for torrents), HOWEVER it is possible for the download client to do the move/copy if you use a script to do this, but its not normally required.1 point
-
Try this:
 1 point
1 point -
Thanks, yes that did it! I went into settings and selected Intel, then applied, then I went back in and changed to nvidia and applied and the dash now works many thanks!1 point
-
Why in a container, I would implement that directly into the Plugin itself so you can run the command directly from the command line. Yes I know, I also have DVB Drivers and a few other things that needs compiling when a new Kernel is released in my repo and this would be no problem to compile it in one run with the other things.1 point
-
Thank you for the information. Still new to Unraid and I will be honest, I did not see that information when I was doing my research before posting. Again thank you very much.1 point
-
Thanks. It's not an improvement in my view. It may depend how one uses the Unread Items list, but I use it just to quickly scan for any topics that I am interested in or where I may be able to help out. The new arrangement just makes it very much harder to spot things, and if one only looks every two or three days then the list also becomes unnecessarily long. I can see that for someone actively supporting a number of threads, the new method may be useful in tracking the levels of activity and determining where to focus.1 point
-
Assuming you didn't already start the array with the single device do this: If Docker/VM services are using the cache pool disable them, unassign all cache devices, start array to make Unraid "forget" current cache config, stop array, reassign all cache devices (there can't be an "All existing data on this device will be OVERWRITTEN when array is Started" warning for any cache device), re-enable Docker/VMs if needed, start array.1 point
-
You are right, I do.1 point
-
Now I just want to get rid of multiples of the same topic in my "Content I follow" Activity Feed.1 point
-
You can try it but please keep in mind that this could lead to the same problem. Please report back.1 point
-
Thanks it's back working now. Not sure why it didn't downloaded the latest one the first time but forcing another check for update allowed me to get the newest one.1 point
-
Solved by disable the "Enable bridging", many thanks!1 point
-
EDIT: Solved my issue.... when I edited the path for completed downloads in your container I inadvertently typed the mountpoint for completed downloads as /CompletedDL. In the SAB .ini file I had this set to /Completed, not /CompletedDL. Simple fix, but I'm still going to blame it on my medical cannabis usage. 🥴 @ich777 Sorry if this has been answered already, but I'm having permission issues with your SABnzbd container. I searched this topic looking for 'permissions sabnzbd' but the results that came back didn't help. I have been using the binhex container which was working with no issues, but it doesn't support use of prerelease or beta builds. As your container does, I decided to give it a try. I backed up my binhex-sabnzbd appdata folder after stopping it from both the webgui and then from unRAID's Docker tab. I set it to not auto-start but left it installed. I then installed your container from CA, adding the paths/mountpoints that I used with the binhex version. I changed the http port to 7070 as 8080 and others were already in use. I also changed from the latest tag to prerelease. The version of SABnzbd pulled was 3.2.0 beta 1. Side note: not specific to your container but I wish installing a container didn't actually start it at the end of a successful install. As it did start right away, I then stopped your version both in the webgui and via the unRAID Docker tab. I then copied the .ini file from the binhex install to your container. SABnzbd started up with no errors after replacing the .ini file so I added a .nzb to test. The incomplete and monitored folder for incoming .nzb files worked properly, but the final folder for completed downloads is throwing permission errors. The folder for completed downloads actually resides on my media unRAID server, whereas the SAB container (and others like it) runs from my 2nd unRAID system. The PID and UID values are the same in both containers, but I did notice that your container has a DATA_PERM variable that by default was set to 770. I've tried changing that to 777 but it made no difference. I also ran the Docker-safe New Permissions tool on the media unRAID to ensure things are OK. I even stopped your container and re-started the binhex version which still works with no permission errors. I used the same paths as in the binhex version, with the final 'Downloads' folder being accessed at /mnt/remotes/mediaunraid/General/Complete. I had some issues with this in the binhex version when Unassigned Devices made the change to mounting remote shares in /mnt/remotes instead of the previously used /mnt/disks. Even though UD puts a symlink to the remote shares in /mnt/disks, I still had to change the path to use /mnt/remotes/ instead of /mnt/disks. And as mentioned above, the binhex container does still work using the /mnt/remotes pathing. This is probably something super-simple but I'm getting nowhere on my own, probably because I'm a little over-medicated from my medicinal cannabis usage. Any idea what might be causing the permission errors when SABnzbd tries to unpack and create folders on my media unRAID? Let me know if you need any screenshots or logs.... thanks!1 point
-
This one worked for me. https://mathiashueber.com/fighting-error-43-nvidia-gpu-virtual-machine/#comments1 point
-
You cannot use a discrete Nvidia GPU simultaneously in multiple VMs, but you can use an iGPU simultaneously in multiple docker containers.1 point
-
In theory, yes. I have not tried transcoding in multiple Media management systems simultaneously; however, I have successfully used Plex and HandBrake (added /dev/dri to both docker containers) at the same time doing media transcoding.1 point
-
@SpencerJ How do I fix whats broken in the Unread Activity? It used to display a thread only once, but now its utterly messed up and displays the thread multiple times. Notice how the thread "Neuer Server... würde mich über Beratung/Tipps freuen..." shows up so many time.
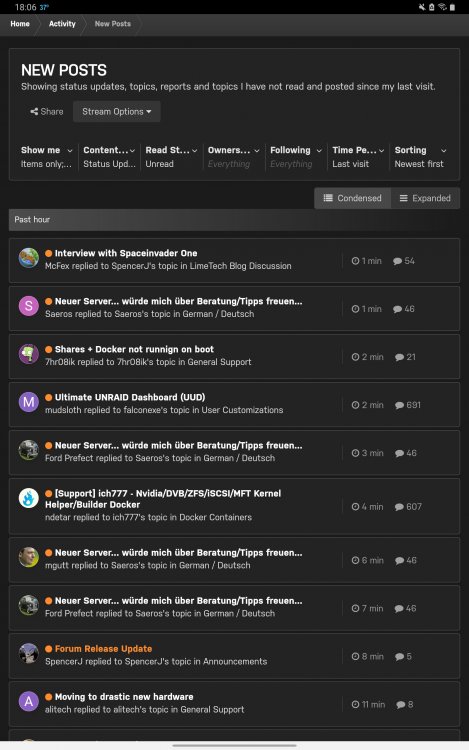 1 point
1 point -
I love the man! He really is legendary already and I am grateful he is part of this community!1 point
-
I also just tested shutting down and starting up a VM and the gnif/vender-reset seems to be working correctly! The only thing left would be to figure out the Nvidia drivers issue. I have a second Nvidia GPU I use for transcoding. Should I try building the kernel with the Nvidia drivers built in rather than the plugin?1 point
-
There seems to be a minimum message in the thread limit before the sidebar shows up. For example, if you go here, do you not see the sidebar @ChatNoir?1 point
-
Yes. Repo is quite good documented as well. I don't think it would be necessary to install the hpsahba tool (maybe in a separated docker?). Patchs are for kernels 4.x and 5.x1 point
-
So I just booted up without the Nvidia Driver Plugin and it started up with no issues.1 point
-
you are running an out of date docker image, click on the 'force update' link or click on 'check for updates' button and then apply updates to update to the latest image.1 point
-
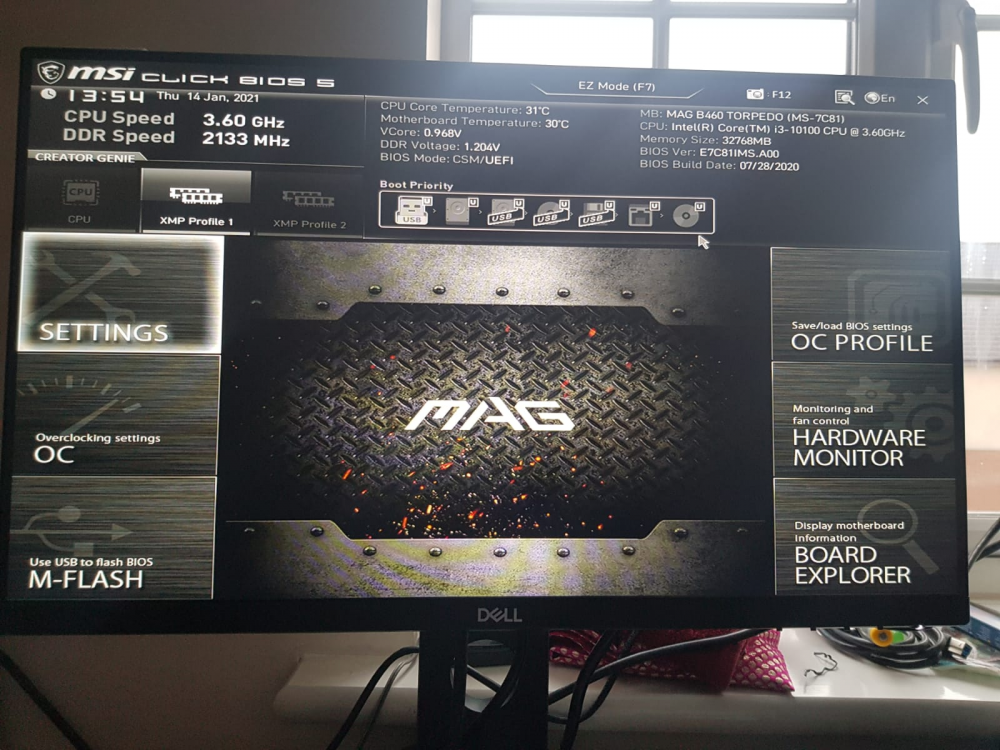
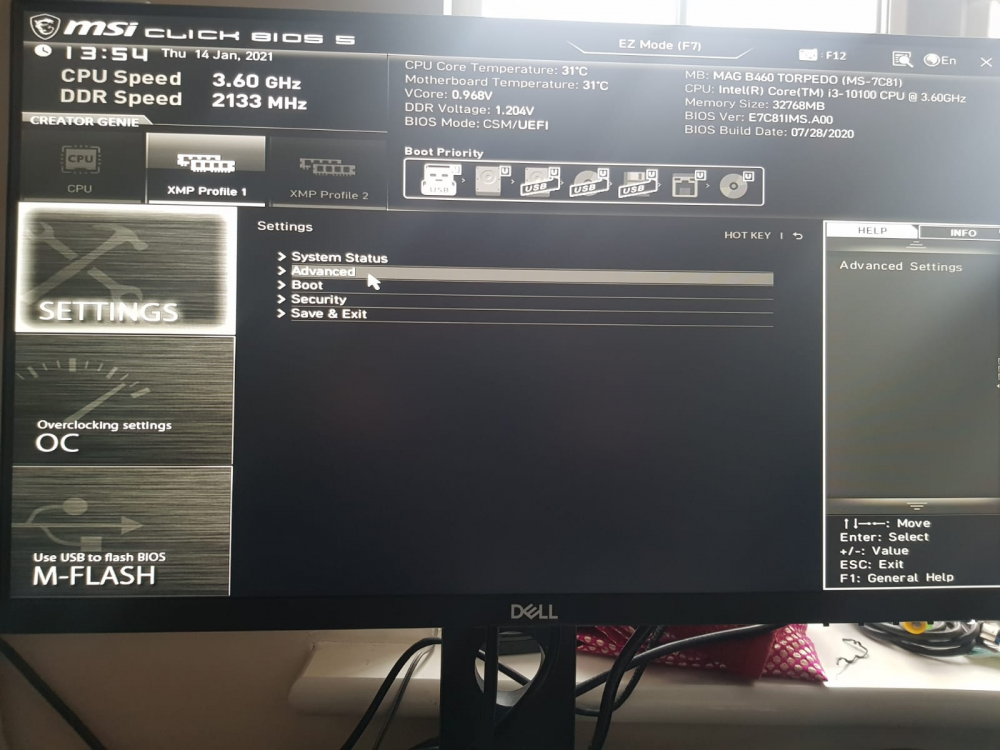
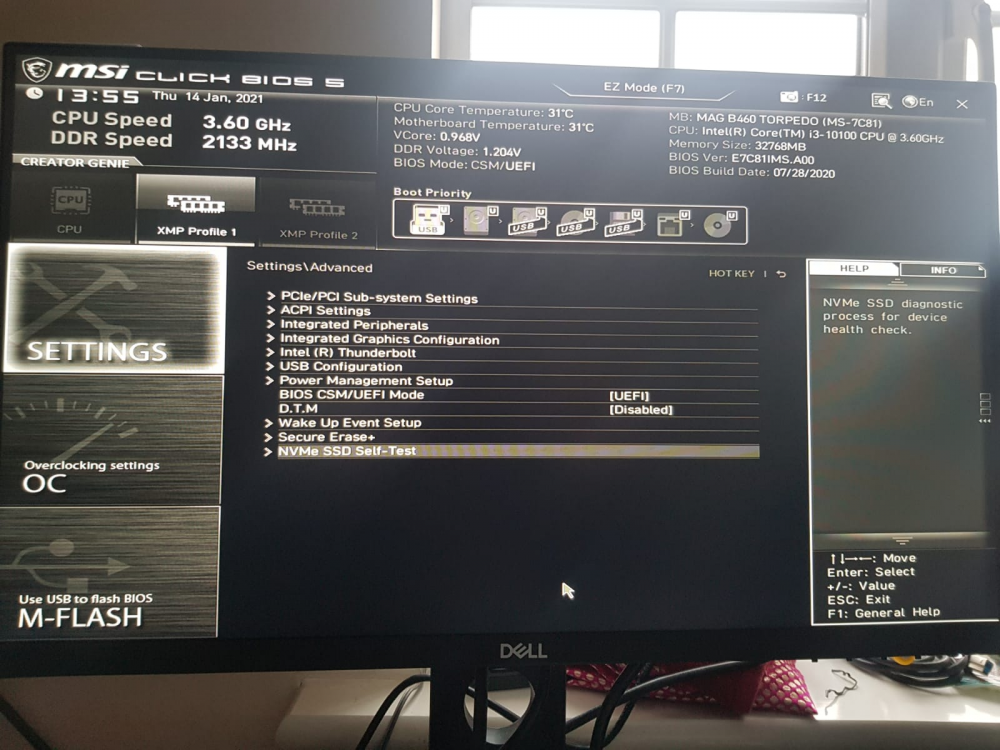
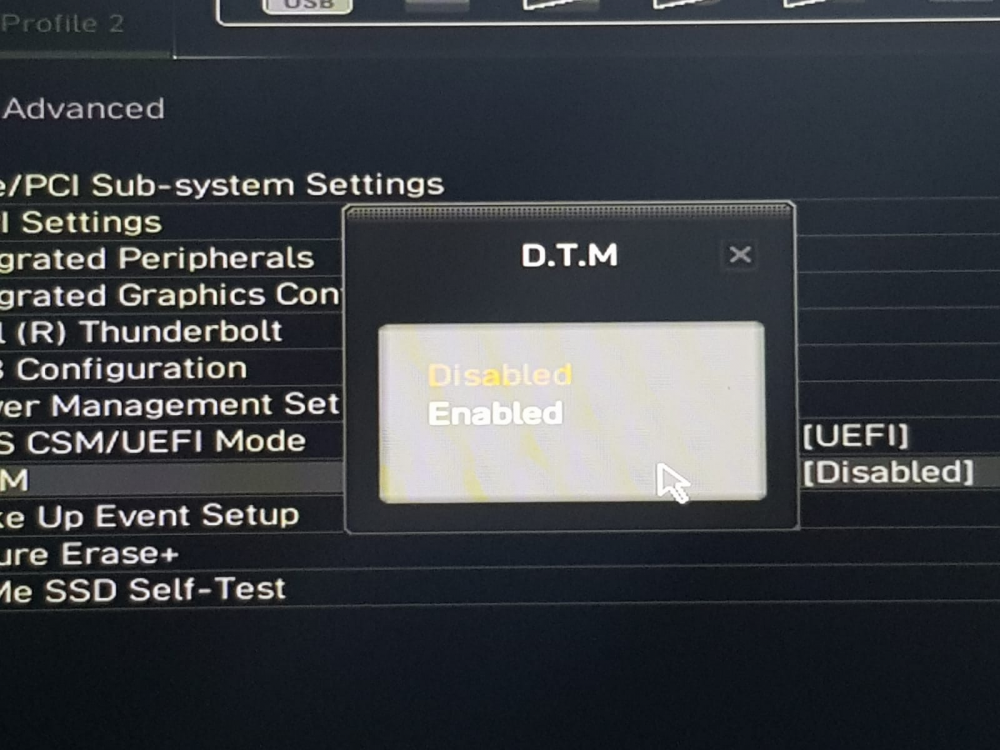
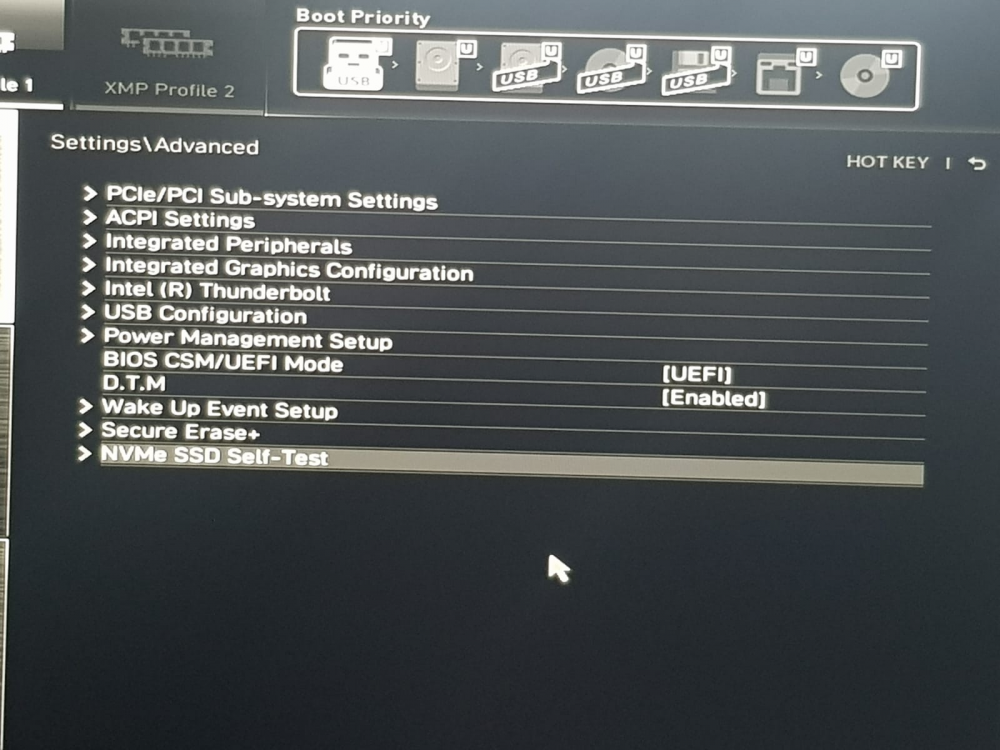
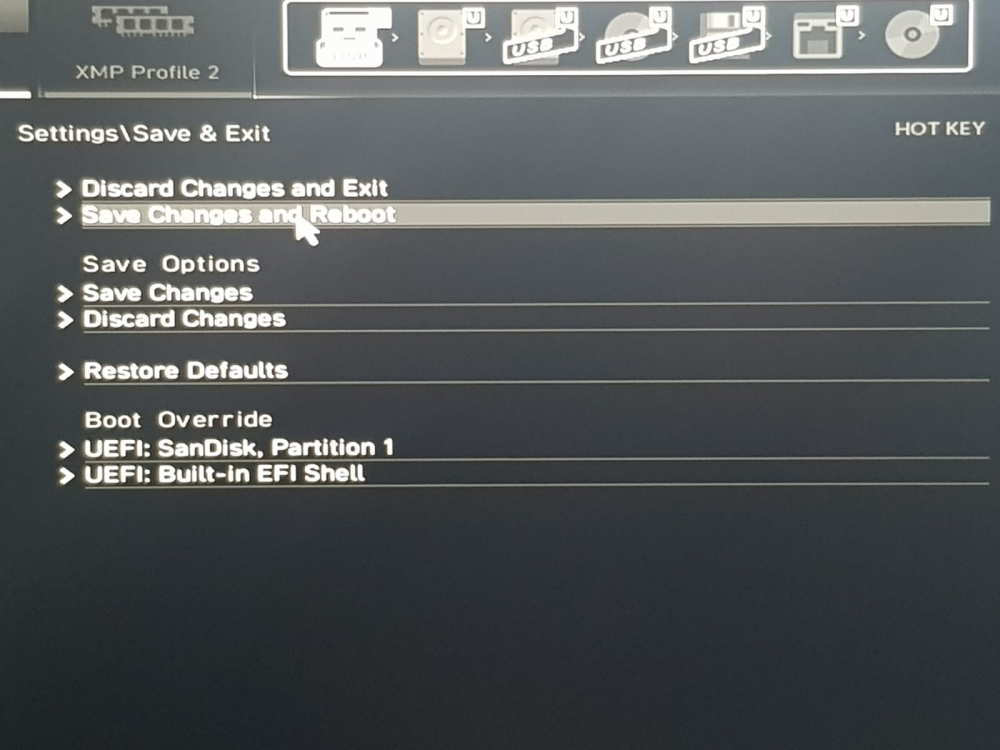
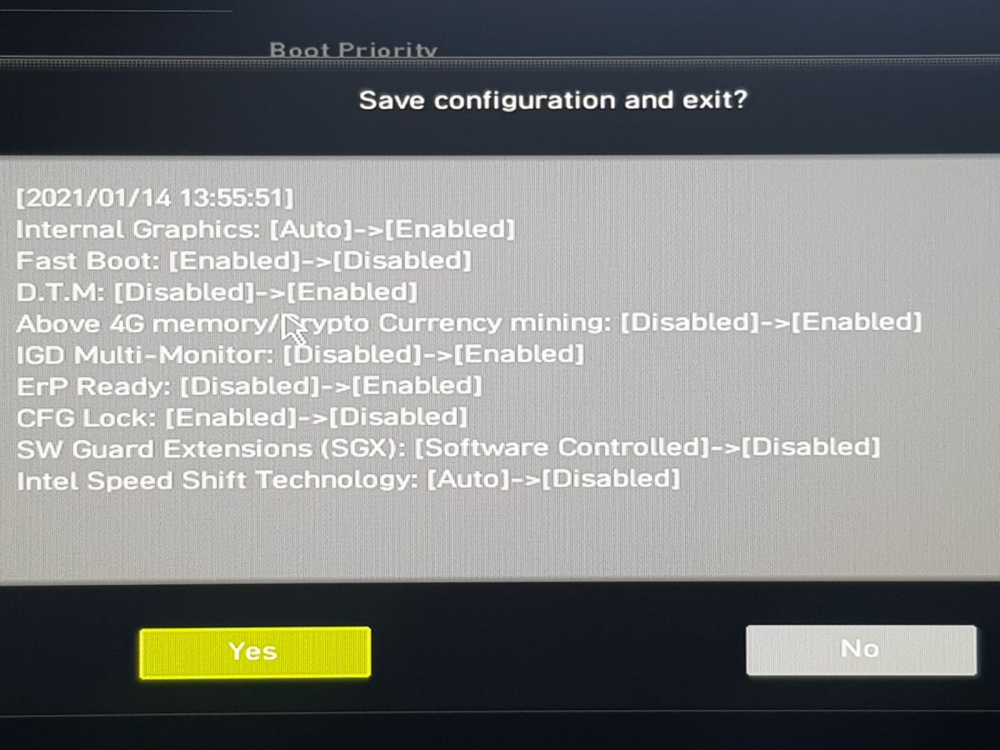
so I tried some settings on my MSI B460 Torpedo motherboard which looks like fixed the issue i have tried multiple reboots from webUI and unraid is starting up correctly without going to BIOS. 1. click settings 2 Access Advanced 3 Power Mgmt Setup 4. DTM - I changed it to Enabled 5 Save changes and reboot this did the trick for me. Why this approach work I don't know may be someone can throw some light on it
 1 point
1 point -
Hi everyone. Yes, the forums went through an upgrade last night to both the software and theme. It appears either A) some batch jobs are still running or B) something went wrong. The performance is NOT what we expect, but I just ask for everyone's patience while we look into and resolve the issue. Thanks.1 point
-
@jwiener3, @zer0zer0 & @StevenD If you need it here is the custom version of Unraid v6.9.0rc2 with the microcode from beta35. Just be sure to first upgrade to RC2 (or at least put the files for RC2 on your USB boot device) and then replace the bzroot on USB boot device with the one from my archive. Click1 point
-
Thank you, I'll try the VNC solution and also mapping another directory for import/export.1 point
-
Ich tippe darauf, dass es viele falsch machen. Bei Virtualbox gibt es nämlich eine wichtige Funktion, die man bei einem Dateisystem wie ZFS oder BTRS nicht hat, nämlich, dass das generierte Snapshot auch den RAM Inhalt enthält. Man muss also bei BTRFS zwangsläufig erstmal die VM herunterfahren, bevor man das Image sichern kann. Jede andere Methode führt zwangsläufig dazu, dass man ein korruptes Image hat bzw irgendwann bekommt, da es nichts anderes ist, als wenn man bei einem laufenden Rechner den Strom zieht. Alles was dann noch im RAM war, ist dann eben weg. Ich habe das folgende Script mal überflogen und es ist gut aufgebaut, da es den Status der VM (suspend, shutdown) prüft, bevor es per rsync eine Sicherung davon macht: https://forums.unraid.net/topic/46281-unraid-autovmbackup-automate-backup-of-virtual-machines-in-unraid-v04/ Allerdings möchtest du ein platzsparendes Backup, also eine inkrementelle Sicherung der Daten. Da wären wir dann beim nächsten Problem. Ja, man kann in BTRFS platzsparende Snapshots erstellen, aber diese Snapshots sind dann ja auf dem selben Datenträger wo sie vorher waren. Du kannst zB kein Snapshot auf einem externen Datenträger erstellen. Du kannst nur lokal ein Snapshot erstellen und es dann mit btrbk auf einen externen Datenträger kopieren. Oder man synchronsiert die Snapshots mit snap-sync. Alternativen dazu: A) Man startet des Backup über die VM selbst und sichert inkrementell die Dateien. Das resultiert aber kein laufendes Image. B) Man weist der VM eine (kleine) SSD als Datenträger zu und sichert die Dateien dieses Datenträgers inkrementell, wenn die VM heruntergefahren wurde. Auch das resultiert kein laufendes Image. C) Nachdem die VM heruntergefahren wurde, erstellt man von der kompletten SSD ein Image. Als Snapshot wäre es inkrementell möglich (aber mit oben genannten Einschränkungen), mit rsync nicht. D) Man nutzt ChunkSync zur Sicherung von Images. Leider gibt es aber noch kein Paket für Slackware (Unraid OS). Müsste man sich erst kompilieren. Setzt man diese Chunks mit cat wieder in eine Datei zusammen, hat man ein laufendes Image. Letzteres plane ich in Zukunft in meinem inkrementellem rsync Script zu implementieren. Dazu würde ich mit dem --max-size Parameter alle Dateien, die größer sind als x GB von rsync ignorieren lassen und genau die dann von ChunkSyze sichern lassen.1 point
-
SOLVED: The issue is not related to the Docker Template or UnRaid but is unique to OpenHAB. I have a high core count server(32 cores) and Jetty chokes. The solution is to either pin the docker to no more than 4 cores or update the OpenHAB conf/services/runtime.cfg as follows. For future reference: in Openhab 3.0 org.eclipse.smarthome.webclient has changed to org.openhab.webclient. So it becomes: org.eclipse.smarthome.webclient:minThreadsShared=20 org.eclipse.smarthome.webclient:maxThreadsShared=40 org.eclipse.smarthome.webclient:minThreadsCustom=15 org.eclipse.smarthome.webclient:maxThreadsCustom=40 After making these changes OH3 runs without apparent issue. _______________ I've been running OpenHAB 2.5.x for almost 2 years now using the Docker template without much problem. I have also spun up another Docker to evaluate OpenHAB 3.0 and it runs pretty well overall, but I have 1 major problem with OH 3.0 that I do not have OH2.5x, I am unable to connected to OH3.0 from the myopenhab.org website. I can push Notifications from the site but I cannot access my local OH3.0 WebUI from home.myopenhab.org. For 2.5.x I have no issue. Every time I try to access OH3 this way I get an error openHAB connection error: HttpClient@4016d1a5{FAILED} is stopped Any ideas how to fix this? is this a permissions issue or some incompatibility with UnRaid Docker (my suspicion). I am running UnRaid 6.8.2 and have tried 6.8.3 and 6.9.rc2 but it makes no difference. I have also removed and recreated the docker image and docker containers, without a better result. If I switch over to OH2 I immediately am able to access the local OH2 WebUI. I also tried installing OH3 on a MacOS VM hosted on UnRaid using br0 just like my dockers and that worked like a charm without issue, so I know OH3 can run on UnRaid network setup. If it was only UI access I wouldn't be too concerned, but any traffic such as OWNTracks that uses the home.myopenhab.org interface is not able to communicate with my OH3 installation and therefore I have no way to update Presence detection that involves the GPS Tracker/OWNTracks. Any ideas as what might be the problem or what to try next? Any arguments I should be using during the install?1 point
-
Hi you just need to install netcat-openbsd-1.105 from NerdPack plugin, and it will be fine1 point
-
Marvell controller based cards are no longer recommended as they can drop drives randomly from the array or fail to display them in the first place. This is more common with virtualization enabled. Some have found some kernel parameters that mitigate but do not totally solve the problem in all cases. It is a Marvell driver issue with recent Linux kernels. To be safe, LSI, ASMedia (1061/1062) and some JMicron (JMB582/JMB585) chipsets are recommended; especially LSI. Lots of posts in these forums with recommended LSI chipset HBA cards. I am using a Dell H310 (LSI 9211-8i clone) in my server which supports 8 HDDs.1 point
-
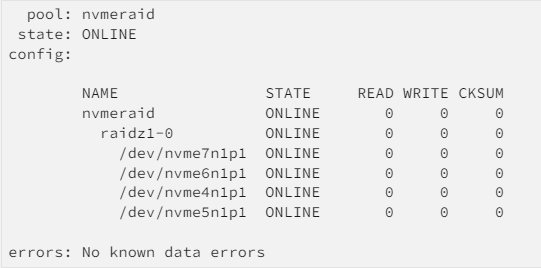
How can I monitor a btrfs or zfs pool for errors? As some may have noticed the GUI errors column for the cache pool is just for show, at least for now, as the error counter remains at zero even when there are some, I've already asked and hope LT will use the info from btrfs dev stats/zpool status in the near future, but for now, anyone using a btrfs or zfs cache or unassigned redundant pool should regularly monitor it for errors since it's fairly common for a device to drop offline, usually from a cable/connection issue, since there's redundancy the user keeps working without noticing and when the device comes back online on the next reboot it will be out of sync. For btrfs a scrub can usually fix it (though note that any NOCOW shares can't be checked or fixed, and worse than that, if you bring online an out of sync device it can easy corrupt the data on the remaining good devices, since btrfs can read from the out of sync device without knowing it contains out of sync/invalid data), but it's good for the user to know there's a problem as soon as possible so it can be corrected, for zfs the missing device will automatically be synced when it's back online. BTRFS Any btrfs device or pool can be checked for errors read/write with btrfs dev stats command, e.g.: btrfs dev stats /mnt/cache It will output something like this: [/dev/sdd1].write_io_errs 0 [/dev/sdd1].read_io_errs 0 [/dev/sdd1].flush_io_errs 0 [/dev/sdd1].corruption_errs 0 [/dev/sdd1].generation_errs 0 [/dev/sde1].write_io_errs 0 [/dev/sde1].read_io_errs 0 [/dev/sde1].flush_io_errs 0 [/dev/sde1].corruption_errs 0 [/dev/sde1].generation_errs 0 All values should always be zero, and to avoid surprises they can be monitored with a script using Squid's great User Scripts plugin, just create a script with the contents below, adjust path and pool name as needed, and I recommend scheduling it to run hourly, if there are any errors you'll get a system notification on the GUI and/or push/email if so configured. #!/bin/bash if mountpoint -q /mnt/cache; then btrfs dev stats -c /mnt/cache if [[ $? -ne 0 ]]; then /usr/local/emhttp/webGui/scripts/notify -i warning -s "ERRORS on cache pool"; fi fi If you get notified you can then check with the dev stats command which device is having issues and take the appropriate steps to fix them, most times when there are read/write errors, especially with SSDs, it's a cable issue, so start by replacing the cables, then and since the stats are for the lifetime of the filesystem, i.e., they don't reset with a reboot, force a reset of the stats with: btrfs dev stats -z /mnt/cache Finally run a scrub, make sure there are no uncorrectable errors and keep working normally, any more issues you'll get a new notification. P.S. you can also monitor a single btrfs device or a non redundant pool, but for those any dropped device is usually quickly apparent. ZFS: For zfs click on the pool and scroll down to the "Scrub Status" section: All values should always be zero, and to avoid surprises they can be monitored with a script using Squid's great User Scripts plugin, @Renegade605created a nice script for that, I recommend scheduling it to run hourly, if there are any errors you'll get a system notification on the GUI and/or push/email if so configured. If you get notified you can then check in the GUI which device is having issues and take the appropriate steps to fix them, most times when there are read/write errors, especially with SSDs, it's a cable issue, so start by replacing the cables, zfs stats clear after an array start/stop or reboot, but if that option is available you can also clear them using the GUI by clicking on "ZPOOL CLEAR" below the pool stats. Then run a scrub, make sure there are no more errors and keep working normally, any more issues you'll get a new notification. P.S. you can also monitor a single zfs device or a non redundant pool, but for those any dropped device is usually quickly apparent. Thanks to @golli53for a script improvement so errors are not reported if the pool is not mounted.
 1 point
1 point

.thumb.jpg.0c644260dacbdbc011d7ad8ba9a1c10a.jpg)


































