Leaderboard

Popular Content
Showing content with the highest reputation on 04/03/21 in all areas
-
It might be worth emphasising to anyone using a trial licence that once you purchase a licence then Unraid no longer needs to check back with the key server and can function quite happily without an active internet connection.2 points
-
Pretty sure that there's some issues at the moment with logging in (I'm having some). Either email [email protected] or wait for @ljm42 / @SpencerJ2 points
-
The SATA link is failing and being reset, so it's a problem somewhere between the controller and the drive electronics, which includes the cable and the connectors. Connections go bad more often than silicon and are generally easier to replace. It might be a damaged contact, or it might be dirty. Try plugging it and unplugging it a few times and make sure it's properly seated at both (or, rather, all 5!) ends. I've had the same problem with breakout cables. Three work just fine but the fourth one is problematic. 1 metre isn't too long. Here's what that error looks like in the syslog. Notice how it couldn't sustain a 6 Gb/s link and shifted down to 3 Gb/s. Mar 28 19:19:28 Tower kernel: ata1.00: exception Emask 0x11 SAct 0x4000000 SErr 0x600100 action 0x6 frozen Mar 28 19:19:28 Tower kernel: ata1.00: irq_stat 0x48000008, interface fatal error Mar 28 19:19:28 Tower kernel: ata1: SError: { UnrecovData BadCRC Handshk } Mar 28 19:19:28 Tower kernel: ata1.00: failed command: READ FPDMA QUEUED Mar 28 19:19:28 Tower kernel: ata1.00: cmd 60/00:d0:20:29:0c/04:00:00:00:00/40 tag 26 ncq dma 524288 in Mar 28 19:19:28 Tower kernel: res 40/00:00:20:29:0c/00:00:00:00:00/40 Emask 0x10 (ATA bus error) Mar 28 19:19:28 Tower kernel: ata1.00: status: { DRDY } Mar 28 19:19:28 Tower kernel: ata1: hard resetting link Mar 28 19:19:29 Tower kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Mar 28 19:19:29 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible ### [PREVIOUS LINE REPEATED 1 TIMES] ### Mar 28 19:19:29 Tower kernel: ata1.00: configured for UDMA/133 Mar 28 19:19:29 Tower kernel: ata1: EH complete Mar 28 19:19:29 Tower kernel: ata1: limiting SATA link speed to 3.0 Gbps How do I know that ata1.00 refers to Disk4? Well, that takes a little detective work, but there are clues: Mar 28 19:17:14 Tower kernel: ata1.00: ATA-9: WDC WD80EDAZ-11TA3A0, VGHJVGXG, 81.00A81, max UDMA/133 and, from the very useful system/vars.txt file in your diagnostics: [name] => disk4 [device] => sdb [id] => WDC_WD80EDAZ-11TA3A0_VGHJVGXG which tie the disk model and serial number, the /dev/sdX identifier, the Disk slot number and the ATA bus all together. Entries in other files will confirm that this is the case. The log actually covers several parity checks in total. A non-correcting one starts like this: Mar 28 19:19:23 Tower kernel: mdcmd (37): check nocorrect Mar 28 19:19:23 Tower kernel: md: recovery thread: check P ... and if it finds an error, reports it like this: Mar 29 07:40:45 Tower kernel: md: recovery thread: P incorrect, sector=10671239984 but obviously doesn't correct it. A correcting parity check starts like this: Mar 31 02:38:06 Tower kernel: mdcmd (48): check Mar 31 02:38:06 Tower kernel: md: recovery thread: check P ... and if it finds an error, reports it like this: Mar 31 14:31:48 Tower kernel: md: recovery thread: P corrected, sector=10671239984 and, as expected, corrects it. There is indeed a final non-correcting check, finding one error, which I missed because of all the noise: Mar 31 20:41:02 Tower kernel: mdcmd (54): check nocorrect Mar 31 20:41:02 Tower kernel: md: recovery thread: check P ... ... Apr 1 02:25:05 Tower kernel: md: recovery thread: P incorrect, sector=5682714232 Hopefully, the examples I've included will help. One difficulty is that messages from various subsystems often overlap, which is why getting rid of the Nvidia driver noise is useful. Incidentally, that looks like this: Mar 29 13:08:41 Tower kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000c0000-0x000dffff window] Mar 29 13:08:41 Tower kernel: caller _nv000708rm+0x1af/0x200 [nvidia] mapping multiple BARs repeated over and over. One way to get familiar with syslogs is to examine the one from your own server when it's running smoothly. Boot it up and look at the syslog before starting the array. Then start the array and see what messages have been added. Then start up a docker container, and so on. I hope this helps.2 points
-
I know i915 is supported so is there any way we could get the new UHD 750 i915 drivers supported in Unraid? Specifically the new Rocket Lake line of processors and the new UHD 750 IGP. Maybe I'm just doing it wrong, but trying to load the i915 drivers i get this error message: [ 636.077251] i915 0000:00:02.0: Your graphics device 4c8a is not properly supported by the driver in this kernel version. To force driver probe anyway, use i915.force_probe=4c8a module parameter or CONFIG_DRM_I915_FORCE_PROBE=4c8a configuration option, or (recommended) check for kernel updates.1 point
-
And most data loss is due to user error.1 point
-
It's because the mount is flagged NOEXEC. You can chmod it yourself to fix it, but the problem will keep coming back everytime it tries to update the codec. I have no idea what causes this and I am in the same boat as you.1 point
-
You ware right, only an error in the description. Thanks you so much for "holding my hand" with this problem. It is people like you who make unRAID and the unRAID community so very special. Thanks again. I buy you a beer or three. Edit: Eth: Effective speed: 44.44 MH/s; at pool: 44.44 MH/s1 point
-
Can you please double check that all varaibles have the right value and key? It can be only a minor problem but I think it has something to do with the parameters itself. If you run it without this parameter you don't hand over the GPU to the container and it can't work. Also you don't hand over Cuda.1 point
-
Sorry for the trouble, you should be able to login now1 point
-
Nein, ich habe keine Erfahrungen damit. Ich habe nur die Beiträge aus dem Forum gelesen. Für mich klingt das nach "meine Kaffeemaschine ist von Bosch, dann muss der Kühlschrank auch von Bosch sein". Ich mein extra Geld ausgeben, nur damit man alles von einer Marke hat. Finde ich eine komische Argumentation. Es gibt übrigens noch weitere Einschränkungen. Die USG kann zB keine Domains lokal auflösen: https://community.ui.com/questions/Resolve-DNS-to-Local-IP/a15900d2-62cb-4396-a106-525476dc45ca#answer/7aa28a27-3f9d-4187-9656-47ce495fd4dd Den Rebind-Schutz kann man nur per json Datei beeinflussen: https://forums.unraid.net/topic/65785-640-error-trying-to-provision-certificate-“your-router-or-dns-provider-has-dns-rebinding-protection-enabled”/?tab=comments#comment-630082 Und lustig wird es, wenn die Datenbank vom Controller wegen einem Stromausfall etc korrupt ist. Dann kannst du nämlich alles neu einrichten und hast so lange keinen Zugriff auf die USG und damit dem "Tor zum Internet". Ubiquiti konnte das nie lösen und hat deswegen ja diese überteuerten Cloud Key2 mit "eingebauter USV" rausgebracht. So toll ich die APs ja finde, aber beim Rest... naja muss jeder selber wissen. Wie telefonierst du eigentlich? Oder hast du kein Festnetz? Das ist einer der Gründe, warum ich eine Fritz!Box habe. Wobei ich noch den DECT 200 nutze und die Internetfilter. Das würde ich alles beim USG vermissen.1 point
-
In case anyone else encounters this issue I’ve updated the relevant part of the “Getting Started” section of the online documentation (accessible via the manual link at the bottom of the unRaid GUI) with these steps so hopefully in the future other Linux users will also be successful1 point
-
Thx, for quick response. I can confirm it's working fine now. Previously I was not able even create USB because of error when trying to write to flash drive. After creating flash drive manually, It works but was not able to obtain trial key. Initially I was thinking it's a problem of my flash drives, but it was failing on all of them (Samsung, Adata, SanDisk). Now USB Creator works fine and I was also able to obtain trial license.1 point
-
And since you can also directly access them as disks instead of going through user shares, I don't see any advantage with UD for this.1 point
-
Naja, du hast schon alles gefunden, was man dazu finden kann: https://community.ui.com/questions/GERMAN-Portfreigabe-IPv6/eb970a73-7e43-4609-9de8-199267ca5e73 Kurz gesagt: Von Haus aus geht das nicht, kann man nur manuell lösen und die Regeln verfallen immer wieder, wenn man in der GUI was ändert. Warum hast du die USG überhaupt gekauft?1 point
-
thanks a million!! you guys are good!!!1 point
-
It should be back up now. Please let us know if otherwise. cc: @Squid1 point
-
It does appear to be. Gotta wait for @jonp @SpencerJ @limetech @ljm42 to get things working again. It is a holiday weekend though...1 point
-
That's pretty slick having the corsair PSU show usage. My EVGA has feature envy1 point
-
Upps. Natürlich ^^1 point
-
Ich hab mich für einen Intel entschieden einfach wegen der iGPU im zusammenspiel mit Emby und bei Intel funktioniert einfach alles (muss man aber schon schön langsam über AMD auch sagen). Der Vorteil an Intel wäre hald auch noch GVT-g aber ich teste das grad noch und bin mir noch nicht sicher was ich davon halten soll. Meinst du AMD oder?1 point
-
You would have to actually unplug the 7th drive as unRaid will not let you start the array with it present if you have a Basic licence. if that drive happens to be a USB drive then you could unplug it to allow the array to be started and once the array is started it can be plugged back in and used as an Unattached Device as the check on the number of attached drives is only carried out at the point you start the array meaning you can plug in removable drives (e.g for copying or backup) once the array is already started.1 point
-
The main difference that Pools provide over UD is the ability to participate in User Shares which UD devices cannot. If this does not matter then it is up to you which you choose. I believe that the expectation going forward is that pools will be chosen over UD except when there is a good reason to use UD so that they can take advantage of any enhancements in the future in pool support.1 point
-
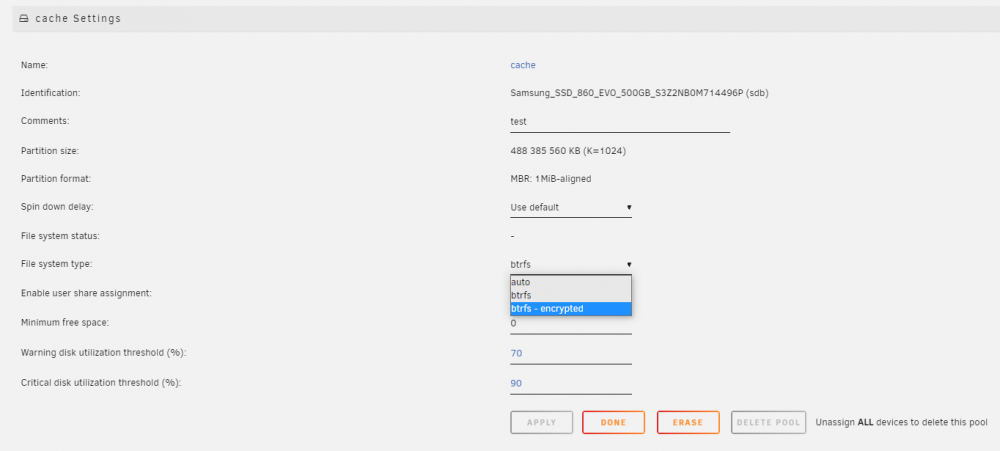
Each individual pool can have encryption or not, just like the array. Stop the array and go to the pool (cache) settings and change the file system type. Note: when a pool consists of 2 or more devices, it will always use btrfs.
 1 point
1 point -
On your phone (client) you need to have AllowedIPs to include all your additional networks too, e.g. AlloweIPs=192.168.3.0/24, 192.168.4.0/24, 192.168.5.0/24 ...1 point
-
Nvidia is also a really cool thing since you can game in a Container, for example look at my Nvidia-DebianBuster container, you can basically stream your games from Steam (in a Docker) to any device you want with basically 0 things to do and it's all pre configured except for your Steam account. I know, these APU's are also really cool things, I also switched to a CPU with integrated graphics (i5-10600) and I'm really happy with ti.1 point
-
OK, thanks. It is what it is, then. At least I can point people here when they have problems. Ah, the joys of closed source drivers! Still loving my $50 AMD APU, BTW1 point
-
It works with the "Cache" pool and multiple pools are just an extension of that idea so I believe it should work, though I don't use it myself. If you haven't started using your new pool try changing it or see here:1 point
-
This also happens on my dev machine with a GTX1050Ti and a Xeon processor C602 Chipset motherboard this is mainly because CONFIG_WATCHDOG is enabled in the Kernel to support more NCT hardware monitor chips. This is a known "bug" in the Nvidia driver and this happens every time nvidia-smi is called. If a user have installed the GPU Statistics plugin and the user is on the Dasboard this happens then every one second or so because it calls nvidia-smi every second and produces this message in the syslog.1 point
-
I had a look at your latest syslog and it's really nasty. You have a very complicated start-up and there are so many issues that it's difficult to untangle them. May I make the suggestion that you simplify things temporarily? I'm a simple soul and need to work methodically by breaking a difficult problem into smaller pieces. Try turning off all auto-starting docker containers and boot in safe mode and let the inevitable parity check complete, then use the server as a plain NAS without any bells and whistles for a few days, to prove its stability. If the diagnostics look good, then start building on that solid foundation. Because, at the moment you have a lot of things trying to happen and, really, none of it is working. Incidentally, how fast are you clocking the RAM? It's one of the things I can't tell from the diagnostics. You have four dual-rank DIMMs on a Zen2 CPU, so the specification is 2666 MT/s, or 1333 MHz. Any higher and you're overclocking the memory controllers on the IO die. Also, please confirm that the CPU cores are not being overclocked - your diagnostics suggest they are not but then again the figures don't look entirely believable: CPU MHz: 2200.182 CPU max MHz: 6767.5781 CPU min MHz: 2200.0000 What I'd like to see is a nice clean start-up and then we can tackle things like the network bonding problems, then move on to the other issues.1 point
-
Read this thread for the reason I said NOT to work directly on the cache until you know how things work at a lower level.1 point
-
Yep, just delete the corrupted files. The only damage is the zero length files.1 point
-
Did you unmount it before trying to mount it with the user script? Either one will work.1 point
-
Figured it out. Instead of using the host IP I used the hashed one... Thanks1 point
-
Turn off ssl for web GUI to stop that redirect.1 point
-
Das ist ein Fall fürs ioBroker Forum. In deinem Auszug ist wieder ein File exists: /opt/iobroker/node_modules/.bin/tsservernpm ERR! Remove the existing file and try again, or run npmnpm ERR! with --force to overwrite files recklessly drin. Gleiches Thema wie beim js-controller. Du kannst die Konflikte entweder händisch lösen oder per "iobroker backup" deine Daten sichern und in einem neuen Container restoren (habe ich auch was zu auf der seite). Das braucht zwar etwas Zeit, ist aber die beste Lösung um wieder ein sauberes und updatefähiges System zu erhalten. Bei diesem Schritt werden nämlich automatisch alle Adapter neu uns in der aktuellsten Version installiert... MfG, André1 point
-
I don't use Nvidia GPUs myself but in the General Support section I'm seeing a lot of other users' diagnostics with this spamming the syslog over and over again, every second or so, eventually filling up the log space, but otherwise seemingly harmless: Apr 1 17:31:32 Tower kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000c0000-0x000dffff window] Apr 1 17:31:32 Tower kernel: caller _nv000708rm+0x1af/0x200 [nvidia] mapping multiple BARs Apr 1 17:31:33 Tower kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000c0000-0x000dffff window] Apr 1 17:31:33 Tower kernel: caller _nv000708rm+0x1af/0x200 [nvidia] mapping multiple BARs At first I thought it only affects users with Quadro cards but this particular one has a GT 710. The thing they do have in common though is that the users have AMD motherboards, at least all the ones I've seen so far do. EDIT: It's more universal than that. See the reply, two messages below this. A quick search revealed this report from 2017, which suggests a buggy BIOS (though it isn't clear what hardware the problem affected then) but promised the messages would be suppressed in an update. It looks as though the problem has resurfaced. Perhaps a future driver update will fix it. Maybe someone with the appropriate combination of hardware can help monitor the situation.1 point
-
It took some tinkering, but I've figured out how to do it with python. The docker image includes python3, so this is what I did: Mount a folder, "/mnt/user/path" to "/script" In qBittorrent, put this under "run external program": "python3 /script/notify.py "%N" "%G" "%Z"" This is a simplified version of my script, which sends a notification via Pushover import sys import time import json import urllib name = sys.argv[1] tags = sys.argv[2] size = sys.argv[3] pushover_user = "USER" pushover_token = "TOKEN" import http.client #Python 3 def pushover(): conn = http.client.HTTPSConnection("api.pushover.net:443") conn.request("POST", "/1/messages.json", urllib.parse.urlencode({ "token": pushover_token, "user": pushover_user, "message": name + " has finished downloading", }), { "Content-type": "application/x-www-form-urlencoded" }) conn.getresponse() pushover()1 point
-
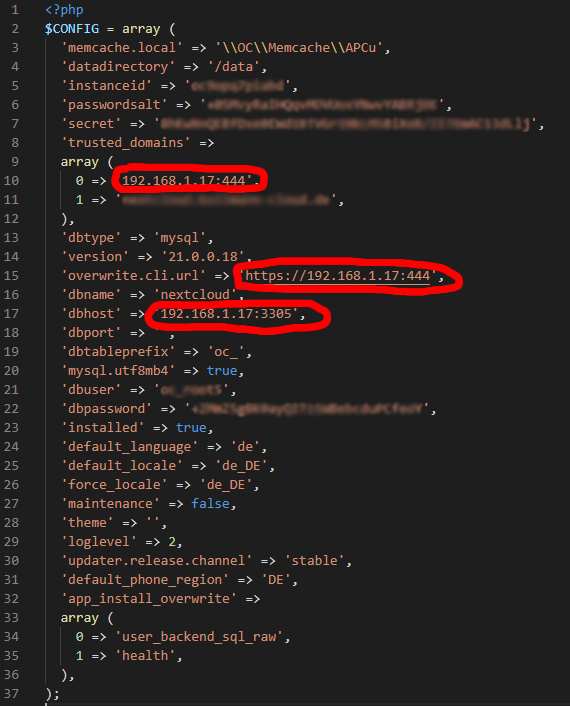
Moin, Danke für deine schnelle Antwort. Ich habe eine Lösung gefunden. Die rot eingekreisten Daten müssen bei einer Ip Änderung angepasst werden.
 1 point
1 point -
Servas Hirates, ich habe mein Heimnetzwerk letzte Woche auch auf Unifi mit der UDM-Pro umgestellt. Dementsprechend auch eine IP-Adress-Änderung vorgenommen, jediglich aber vom ganzen unRAID-Server und nicht von dem Nextcloud Docker spezifisch. Bei mir hat es jedoch problemlos funktioniert, ich musste nur in meinem Reverse Proxy die IP-Adresse anpassen, und das wars. In der config.php oder der Datenbank hab ich absolut nichts verändert - ich schau aber gleich mal wenn ich zuhause bin ob ich dort "localhost" oder eine IP-Adresse eingetragen hab und meld mich dann gleich nochmal bei dir. Aber wie gesagt, bei der Adressänderung von dem ganzen Server haben sich die Docker selbstständig den neuen IP-Bereich zugewiesen und ich musste diese nur noch im Nginx anpassen. Meld mich gleich wieder bei dir. Danke im Voraus für deine Geduld! Beste Grüße/Habedere, Dominic1 point
-
You should go with the Ultra, at least based on the block diagram. That way both GPUs get an x8 link to the CPU. Ultimately that will depend on the IOMMU groupings. I’m about to do some testing with an 11700K and a Z590 Master soon. I’ll let you know how it goes. The Master and the Ultra are very similar.1 point
-
Pushed a update of the container, please force a update of the container on the Docker page or pull a fresh copy from the CA App and it will work after the update.1 point
-
I think so. Don't have any hardware on hand to test...1 point
-
does the intel gpu top support 11th gen Rocket Lake?1 point
-
Found the issue! i didnt had device_tags = ["ID_SERIAL"] set in [[inputs.diskio]] All working now!
 1 point
1 point -
I am having issues with the latest Docker image and i cannot access the application, if i look in the log file located at '/config/supervisord.log' then i see the following message:- '/usr/lib/jvm/java-8-openjdk/jre' is not a valid Java environment path Q. What does it mean and how can i fix it? A. See Q10 from the following link for the solution:- https://github.com/binhex/documentation/blob/master/docker/faq/general.md EDIT - unRAID 6.9.2 has just been released, this includes the latest version of Docker, which in turn includes the latest version of runc, so if you are seeing the message above then the simplest solution is to upgrade to v6.9.21 point
-
Any plans to add 2FA to the Secure Remote Access feature? I really like this feature.1 point
-
AHA !!! Someone found a way !!!! Thanks to @bordershot1 from a K8s thread on Plex forum, I found the right info, about a mysteriously updated Beignet Driver and how to compile it directly from this nice linuxserver.io plex container. https://forums.plex.tv/t/hdr-to-sdr-tonemapping-opencl-driver-resource-for-kubernetes/656635/19? Kudos to him ! Edited on Dec 10th 2020: Adding cleanup of the dev environment at the end of the script to use less storage, and installation of clinfo for proper installation check. Now I could write a User Script from this, and here it is: #!/bin/bash #description=This script updates Beignet Driver to support last Intel GPUs for Plex Container docker exec plex bash -c "apt update && apt -y install cmake pkg-config python ocl-icd-dev libegl1-mesa-dev ocl-icd-opencl-dev libdrm-dev libxfixes-dev libxext-dev llvm-7-dev clang-7 libclang-7-dev libtinfo-dev libedit-dev zlib1g-dev build-essential git clinfo" docker exec plex git clone --branch comet-lake https://github.com/rcombs/beignet.git docker exec plex bash -c "mkdir /beignet/build/ && cd /beignet/build && cmake -DLLVM_INSTALL_DIR=/usr/lib/llvm-7/bin .. && make -j8 && make install" docker exec plex rm -rf beignet docker exec plex bash -c "apt -y remove cmake pkg-config python ocl-icd-dev libegl1-mesa-dev ocl-icd-opencl-dev libdrm-dev libxfixes-dev libxext-dev llvm-7-dev clang-7 libclang-7-dev libtinfo-dev libedit-dev zlib1g-dev build-essential git && apt -y autoremove" docker restart plex docker exec plex clinfo -l Execute it, will take some time to download all the required dev librairies, and do the actual compilation, but it works !!! Using FTTH, i5-9600k, 32 GB ram, and NVME it takes lake 4 mins to do the job, but depending on you internet and system performance it may go up to hours... If you execute it via RUN SCRPT button, you will see, that a part of the logs are not displayed, and that the compilation itself throws many errors, but these are just warnings, and shouldn't be considered. It finishes with these lines: plex beignet-opencl-icd: no supported GPU found, this is probably the wrong opencl-icd package for this hardware (If you have multiple ICDs installed and OpenCL works, you can ignore this message) beignet-opencl-icd: no supported GPU found, this is probably the wrong opencl-icd package for this hardware (If you have multiple ICDs installed and OpenCL works, you can ignore this message) beignet-opencl-icd: no supported GPU found, this is probably the wrong opencl-icd package for this hardware (If you have multiple ICDs installed and OpenCL works, you can ignore this message) Platform #0: Intel Gen OCL Driver `-- Device #0: Intel(R) UHD Graphics Coffee Lake Desktop GT2 Platform #1: Intel Gen OCL Driver Script Finished Dec 10, 2020 09:53.34 Enjoy !!! 😄1 point
-
Hi all I was having a heck of a time getting this to work, lidarr would keep spitting out error 255 when i went to test the conection. I did some digging and discovered that the link https://raw.githubusercontent.com/TheCaptain989/lidarr-flac2mp3/master/flac2mp3.sh simply downloads a file containing the words "error 404 not found" if you replace the above link with https://raw.githubusercontent.com/TheCaptain989/lidarr-flac2mp3/7fda34528327e907cf583385c68260512ffb4ba3/flac2mp3.sh you can get the script to work within Lidarr, it looks like TheCaptain989 has stopped supporting this script over at github, and the link i have provided is the one that was likey used when thejasonparker wrote this original post. I am very very very new to all of this linux buisness so im sure anyone who reads this could come up with a beter way of fixing this tutorial, but it worked for me :) Hope i helped Frod1 point
-
Dec 2 17:17:39 unRAID root: Found invalid GPT and valid MBR; converting MBR to GPT format Dec 2 17:17:39 unRAID root: in memory. Dec 2 17:17:39 unRAID root: *************************************************************** Dec 2 17:17:39 unRAID root: Dec 2 17:17:39 unRAID root: Warning: The kernel is still using the old partition table. Dec 2 17:17:39 unRAID root: The new table will be used at the next reboot or after you Dec 2 17:17:39 unRAID root: run partprobe(8) or kpartx(8) Just reboot and it will format.1 point
-
and this https://hub.docker.com/r/danielguerra/soulseek/1 point





























