Leaderboard



Popular Content
Showing content with the highest reputation on 04/10/21 in all areas
-
Schön zu hören!! Ich konnte leider nicht früher schreiben, aber den Grund hatte ich ja schon genannt. Ich muss zu deinem Phänomen sagen, dass ich noch in meiner ersten Woche mit Unraid auf ovmf umgestiegen bin und daher den vendor-reset sowie den alten navi-patch nie mit seabios betrieben habe. Kann gut sein, dass dein Problem allein durch den Wechsel auf das UEFI bios gelöst wurde. Noch eine Frage zu deiner GPU.. Wenn du deine verschiedenen VM's über das OS neustartest, funktioniert der Sound? Hast du kurzzeitig merkwürdige Fragmente auf dem Display? Oder funktioniert alles reibungslos? Zu der Treiberinstallation.. Bei mir selbst verhält sich die Treiberinstallation exakt identisch zu einer Installation auf Bare Metal. Kann aber auch bei Windows gern mal an vorherigen fehlgeschlagenen Installationen o.ä. liegen. Windows bereinigt sich selbst ja nicht so "gut" Kann dir hier sonst noch für spätere Situationen "DDU" - einfach mal googlen - empfehlen. Damit konnte ich Windows eigentlich immer überzeugen Uff 💚2 points
-
I was waiting for a couple of minor revisions before upgrading from 6.8.3, just did it this morning, straight to 6.9.2, the update was seamless. I even added a disk after I shut down for the update and it rebooted just fine with the update and detected the new disk that I added to the array. One issue is with the VNC browser viewer for VMs. same as here: Disabling adblock didn't help but clearing browsing history does the trick. For anyone interested, under Chrome, you don't have to clear your whole history (I definitely didn't want that), you can clear only the "Cached images and files" from all time and you're good to go. It won't change much in practice, it just forces Chrome to redownload everything it put in cache which is exactly what we want here. Other than that, I wish we had an easy way to test features in a non-production environment in Unraid without buying another license and having other dedicated hardware. Making Unraid work as a VM in Unraid requires a lot of workarounds currently.2 points
-
Please provide the instructions for doing this in the Official Unraid Manual (the one you get to by clicking lower right-hand corner of the GUI) and not just in the release notes of the version number when the changes are introduced. Remember that many folks are two or three releases behind and then when they do upgrade they can never seem to locate the instructions which results in unneeded queries that the folks who provide most of the support for Unraid have to deal with. Having an updated manual section that deals with these changes makes pointing these folks to find what they will have to change a much similar task... EDIT: I would actually prefer that you link directly to the manual sections in the change notes. That way the information will be available in the manual when the changes are released!2 points
-
We're working on a design that lets driver plugins be automatically updated when we issue a release.2 points
-
Having any trouble setting up an Unraid 6.9 Capture, Encoding, and Streaming Server? Are you a streamer who uses Unraid? Let us know all about it here!1 point
-
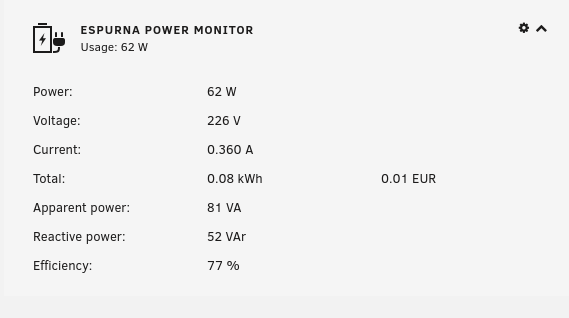
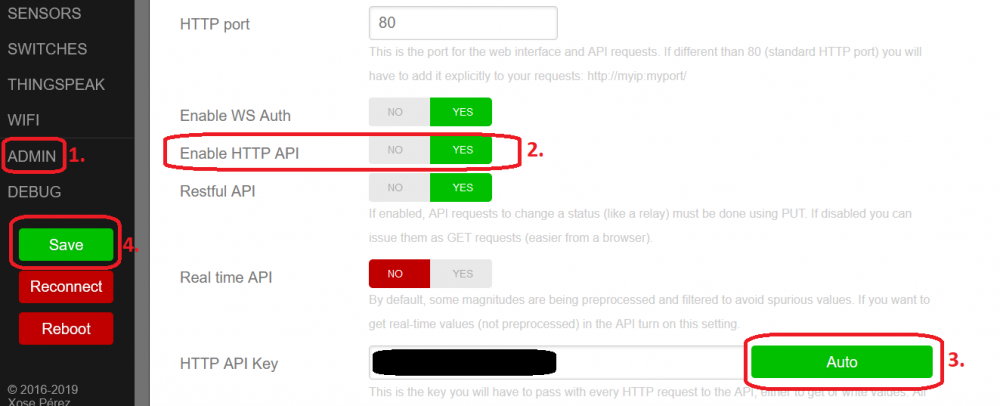
Hi guys, here is the power monitor for your ESPurna device. The plugin works like the Tasmota Power Monitor. You have to activate the API on your ESPurna device and enter the key in the plugin. To enable the API from your ESPurna device go to the WebUI and click on: 1. Admin 2. Enable HTTP API 3. Auto 4. Save If you find a nice logo for the plugin, please send it to me. Thanks to ich777 for testing. Created and tested with Unraid 6.9.1. Installation as usual... https://raw.githubusercontent.com/Flippo24/espurnapm-unraid/main/espurnapm.plg
 1 point
1 point -
Summary: Support Thread for cschanot docker templates: ntopnrg kibana - This currently relies on the existing Elasticsearch docker by FoxxMD1 point
-
Undervolten bringt nicht viel und du riskierst nur Instabilität. Beide schaffen um die 10W. Such im deutschen Forum nach der jeweiligen Bezeichnung, dann wirst du fündig. Kommt drauf an wie viele VMs schlussendlich darauf laufen sollen und was die so an Leistung benötigen. Ansonsten kannst auch erst mal mit einem i3 anfangen. Nur für den Server ist das egal. Ich würde 2666 Mhz nehmen, weil das vom Xeon unterstützt wird. Kommt auf die Menge an Platten an. Ab 14TB rechne mit 30W Stromaufnahme pro HDD beim Hochfahren. Darunter mit 20W. Die PicoPSU hat nicht viel 5V Leistung, also nicht sonderlich für viele SSDs geeignet, aber wenn sie reicht, ist sie das sparsamste Netzteil.1 point
-
@giganode aka Newbie 😅 Überhaupt kein Problem. Ich habe gerade nochmal eine neue Win10VM aufgesetzt und nochmals den Punkt "Auf Werkseinstellungen" bei der Radeon Treibersoftware für meine Grafikkarte angeschaut. Ich glaube, dass in diesem Zeitpunkt eher mein Monitor ein Problem hat. Hatte explizit dort nur den Unraid-Server dran und nach dem Neustart der VM hat er kein Bild mehr bekommen. Ich konnte ihn nicht mal mehr ausschalten. Habe dann den Stromstecker gezogen, wieder eingesteckt und siehe da, ich hatte wieder ein Bild. Bisher hatte ich mit meiner GPU und Sound keine Probleme. Bei meiner MAC-VM musste ich nur in der XML die Soundkarte auf den gleichen BUS, wie die Grafikkarte legen. Dort ist mir manchmal aufgefallen, dass sich der Mauszeiger für 1 Sekunde etwas vergrößert. Wieso hast du Probleme? DDU hab ich gegoogelt. Sehr interessant, aber nach bisherigen Erkenntnissen eher mein Monitor, als ein Treiberproblem. So meine Einschatzung1 point
-
Good night, i've made 3 others untranslated files : /CA Auto Update/autoupdateapps.txt /CA Config File Edit/configedit.txt /Disable Security Mitigations/disablesecurity.txt I go to sleep, it's 11:32PM here1 point
-
Thank you, i've done all the untranslated french in the presents files, made the correction needed in settings.txt (display settings was wrongly translated), commited all the changes in my fork and pushed it to the master, i'm not very familiar with git-hub, i hope it was the good way to proceed1 point
-
Es gibt dass Tool "stress". Ich weiß nicht ob das beim Nerd Pack dabei ist. Wenn nein hier habe ich erklärt wie man das installiert (runterscrollen):1 point
-
@lnxd & @trig229 Hey guys!! I'm a little confused right now as I went through this recent posts... Sry had a tough week working, so answering took a while now.. Everyones rx 6800xt is working now, right?! AX200 passthrough is fine in my windows and macos vm, but I never added it to my ubuntu vm.. Do you have an issue with linux? What is it?1 point
-
No If you always use GUI mode, then set it as the default via Main, Boot Device, (click on Flash), syslinux configuration1 point
-
/mnt/cache/appdata/PlexMediaServer would be /mnt/user/appdata/PlexMediaServer this should allow you to change the mover settings to do the procedure1 point
-
Not quite sure what you mean here? I agree that you need an additional USB stick containing a valid licence for that USB stick but once you have that running unRaid in a VM is comparatively trivial to set up.1 point
-
thanks, @binhex! It did the trick!1 point
-
thanks again for the offer but if you remember we tried this already few weeks ago and we found nothing but big wa when the copy occurs.1 point
-
Upgraded from 6.9.1 to 6.9.2 and no issues picked up so far. Thanks to the Unraid dev team!1 point
-
If you need me to give you logs or anything else, please let me know i'll gladly provide! Thanks for at quick response!1 point
-
I will look into this ASAP and report back, another user reported something similar and I thought I fixed it but as it seems not... Please give me a few days for this.1 point
-
I also had to click the little square symbol next to “monitored folder”. That will add your setting and open a new blank line. Click save when done.1 point
-
Danke für den Tip. Versuche ich heute abend einmal. Gruß Frank1 point
-
yep i got stuck on this myself and wrote up how to fix it, see Q2:- https://github.com/binhex/documentation/blob/master/docker/faq/qbittorrentvpn.md1 point
-
Does this mean I can now remove the vbios from my gaming VM? Is there a performance benefit? Does it perhaps pass the GPU "more directly" through or something like that?1 point
-
Hi All, Here is the forked repo with the details of my "fix", keep in mind this is only for X570D4U and X570D4U-2L2T users, I purposely didn't include this to be backwards compatible because I didn't have those boards to do the proper testing or the time to make this backwards compatible. This is the commit in question that has my "fix", I also fixed some minor bugs with the shell commands: https://github.com/lucasteligioridis/IPMI-unRAID/commit/49281fd8 I can't quite remember if the ipmi2json script works flawlessly or not, I may have hacked in some values on the first run, full disclosure I haven't used that one since I first put it together and used it. But the ipmifan script works wonders with these boards, haven't had a problem with it since implementation. You essentially want to copy the two files mentioned from here: https://github.com/lucasteligioridis/IPMI-unRAID/tree/master/source/ipmi/usr/local/emhttp/plugins/ipmi/scripts Into the correct location on the Unraid system, which is here: - /usr/local/emhttp/plugins/ipmi/scripts You will have to restart the ipmifan service in the Unraid UI and it all should hopefully work, at the very worse the ipmi2json script might not work perfectly as intended, but it will at least generate some of the json correctly. Let me know how it goes, happy to help further. I'm not at home at the moment and don't have SSH access to validate the above just yet. To have this fix "permanent" I just copy the ipmifan script into the above directory whenever the machine boots, because the plugins get reloaded each time Unraid restarts so the old code will be restored. Obviously any updates to the plugin will have the same effect. If I get more time I'd love to fix this into a proper patch and merge it upstream.1 point
-
@doron Test results, but my SATA drive works fine and spins down. Will try and get working on the HBA and try again. 1. Remove the plugin Plugin removed, all SAS drives spun up as soon as removed. 2. Manually spin down one of the SATA drives on which you've seen the problem. Test SATA spins down fine. 3. Issue this command against this SATA drive: sdparm -ip di_target /dev/sdX root@Tower:~# sdparm -ip di_target /dev/sdk /dev/sdk: ATA ST3320310CS SC14 Device identification VPD page: 4. Check whether this command caused (a) the drive to spin up (b) message "read SMART /dev/sdX" to be logged. Apr 10 09:45:15 Tower emhttpd: cmd: /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin remove sas-spindown.plg Apr 10 09:45:15 Tower root: plugin: running: anonymous Apr 10 09:45:15 Tower sas-spindown plugin: Removing the smartctl wrapper... Apr 10 09:45:15 Tower sas-spindown plugin: Restoring Unraid OS spindown script... Apr 10 09:45:43 Tower kernel: sd 7:0:4:0: attempting task abort!scmd(0x000000007e425516), outstanding for 15025 ms & timeout 15000 ms Apr 10 09:45:43 Tower kernel: sd 7:0:4:0: [sdh] tag#631 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00 Apr 10 09:45:43 Tower kernel: scsi target7:0:4: handle(0x000c), sas_address(0x5000cca027baa9a9), phy(6) Apr 10 09:45:43 Tower kernel: scsi target7:0:4: enclosure logical id(0x5003048011c7eb00), slot(5) Apr 10 09:45:43 Tower kernel: sd 7:0:4:0: task abort: SUCCESS scmd(0x000000007e425516) Apr 10 09:46:44 Tower emhttpd: read SMART /dev/sdj Apr 10 09:46:44 Tower emhttpd: read SMART /dev/sdh Apr 10 09:46:44 Tower emhttpd: read SMART /dev/sdg Apr 10 09:46:44 Tower emhttpd: read SMART /dev/sdf Apr 10 09:46:44 Tower emhttpd: read SMART /dev/sdc Apr 10 09:46:44 Tower emhttpd: read SMART /dev/sdi Apr 10 09:49:40 Tower emhttpd: spinning up /dev/sdk Apr 10 09:49:45 Tower emhttpd: read SMART /dev/sdk Apr 10 09:49:51 Tower emhttpd: spinning down /dev/sdk Let me know if any other tests you need. Hi @bonienl would you be able to run sdparm -ip di_target /dev/sdX against one of your SATA drives that doesn't spin down?1 point
-
Yes, it is my network problem. I solved it by using the proxy and the docker page is now displayed normally1 point
-
It does for most people. I understand it can be frustrating if you cannot do what you expect but simply saying that it does not work will not improve the situation. We have nothing to work from to try solve issues you might have with Unraid. Please make a post in General support explaining your issues in details. What you expect to do, what step you took, what is happening in return ? Pictures of errors can help. Attaching your Diagnostics will also give us information to help you (Tools / Diagnostics).1 point
-
Thank you! Should have been obvious to me, but I didn't know the new version was out yet 😅1 point
-
You can also flash a Tasmota device with ESPurna and vice versa from the WebUI from what I remember back when I tried Tasmota.1 point
-
Please upgrade to 6.9.2 and then try to do a custom build again. From what I see you are trying to build on 6.9.1 for 6.9.2 (the Kernel-Helper is always configured to only support the latest version).1 point
-
They didn't lock it, they just refused to fix a bug (hardware reset) that made pass-through unusable. As soon as the community started to build working fixes, AMD's next generation didn't have these issues, but the fixes weren't backported to previous gen. I should also note these hardware reset problems have never appeared in AMD's professional GPU lineup (Quadro competitors), funny that.1 point
-
Which means it's simply like running resistive heat strips, or a space heater. If you need the heat anyway, it's not really a waste, except that a heat pump is a little more efficient. When summer comes around however, you'd be paying twice, once to mine and once to move the heat outside with the A/C. So rest your environmental head, as long as it's cold outside and you would normally run a heater, mine away. At the very least it mines more coins than a baseboard heater.1 point
-
I have gotten Varken/UUD working with multiple Tautulli servers, which are selectable as a variable in the dashboard. If anybody is interested in trying to do that, let me know and I can write up the steps. There is one current limitation, as far as I can tell - Varken can be configured to access multiple Tautulli servers but can only notate them as 1,2,...n. To make that meaningful in the dashboard I had to use either rename transformations or name/value overrides to switch from '1' to the friendly name of the server. The server name does not seem to be stored anywhere in the Influx table for Varken.
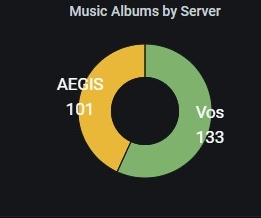 1 point
1 point -
Sorry I never posted my actual solution ages ago, I was actually going to fork the plug-in and submit a PR but I thought the author was going to do it. Ill post my changes that have a working solution for these boards later in the day, essentially it was a change to the ‘ipmi2json’ and the ‘ipmifan’ scripts.1 point
-
Haaa. Jetzt scheint es zu gehen. Folgendes hab ich jetzt durchgeführt: - Wiederherstellung des ursprünglichen Unraids - Update auf die neueste Version V. 6.9.1 auf V. 6.9.2 (Hatte ich vorher nicht gemacht) - Bereinigung der Kernel-Helper Dateien und Deinstallation des Dockers - Neustart und Neuinstallation des Kernel-Helpers - Nur die Option bei vendor-patch auf true setzen - Dateien auf dem USB-Stick getauscht - Win10VM nun von Seabios auf OVMF gestellt Neustart der VM geht und Herunterfahren und Wechsel zur MAC-VM und dessen Neustart geht auch. Einzig bei der Installation der Radeon-Software unter Win10 und setzen des Punktes "Werkseinstellung" habe ich mal kein Videosignal bekommen. Auch nicht nach einem Unraid-Neustart. Hab dann Unraid beendet, wieder gestartet, die Radeon Software zu Ende installiert und seitdem bisher keine Probleme mehr gehabt.1 point
-
....das Asrock 1151v2 aus dem Link ist kein Gaming Board und hat den Vorteil das beide M.2 mit PCIe-NVMe gehen ohne das Du, wie nicht selten üblich einen SATA oder PCIE Slot verlierst. Gesendet von meinem SM-G960F mit Tapatalk1 point
-
On one of my servers I do, but on the other it is gone....1 point
-
Yep, Unassigned Devices, i.e; networked storage from unRAID's perspective. I don't have cache pools, I don't even have parity. My server is a single small SSD and all storage is on NFS shares. I only used unRAID for the apps when I got it, then I switched to Fedora Server but I got it back online 'cause there's always something fresh and cool and unbelievably easy to manage by the unRAID's dev community it's hard to stay away. To sum it up, I can now create a share on my little SSD then add UDs as cache pools to it. Correct? It seems like nice concept if the main storage is mechanical. Though if it's flash-based I hope they implemented some sort of referencing mechanism so the clients can access the UD-based cache directly at the servers providing them, more or less like DFS Namespaces so it doesn't have to route trough unRAID. I think I'll obsess with that today, I feel it already. Thanks that's really helpful. I had already. Basically unRAID shares nothing. It provides nothing to the network but its more like a data processor--well, the apps running on it. Thanks again to both for answering. It's Friday here so, have a great weekend!1 point
-
Eventually, in my case I haven't specified a port and it worked just fine where my ISP doesn't support connections over port 25. That's really strange and interesting, because I also only use v4 and it is working without a problem. No pressure on that, really appreciate the responses and the updates about your findings.1 point
-
lol:- im off to test and ensure runc is the correct version.1 point
-
GUI SMART tests don't work with SAS devices, but you should see the attributes, tests for SAS devices need to be done manually.1 point
-
1 point
-
@falconexe I asked the grafana image plugin developer to implement the use of dashboard variables, like image url. He released a pre-release version of the plugin, which runs fine. Now it's much easier to set the Image Path (and width/height if needed) once and reuse it everywhere its needed. Download image plugin pre-release 2.3.0

 1 point
1 point -
Right now this link is dead. I'll check it later. here is the new issue i created. If you want you can do a comment there with your steps. and if you have the error still. https://github.com/linuxserver/docker-nextcloud/issues/189 Edit* Check the issue for the solution. TL?DR? Update docker, delete /config/nginx/site-confs/default, restart docker, Go to Settings > Overview, (for chrome) Press F12 and while having dev tools open right click refresh button and click emtpy cache and hard reload.1 point
-
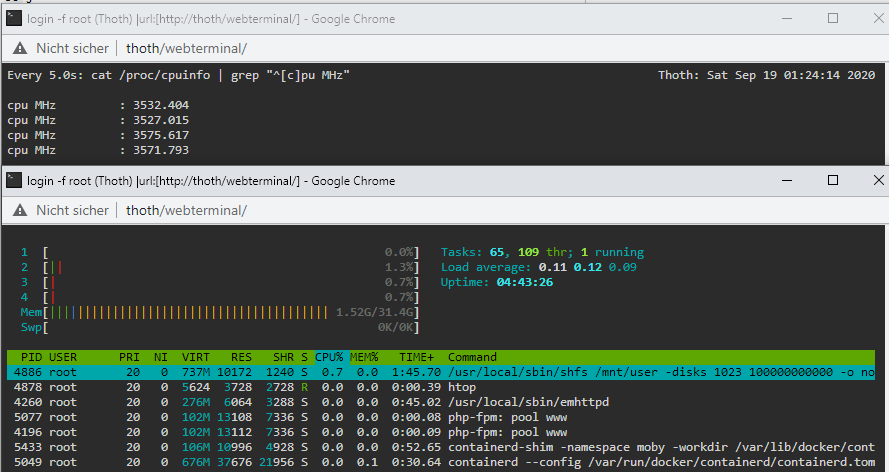
I asked this question by myself and found out that this message is created through the underlying Slackware: https://www.linuxquestions.org/questions/slackware-14/locking-all-cpu's-to-their-maximum-frequency-4175607506/ So I checked my file as follows: cat /etc/rc.d/rc.cpufreq #!/bin/sh # # rc.cpufreq: Settings for CPU frequency and voltage scaling in the kernel. # For more information, see the kernel documentation in # /usr/src/linux/Documentation/cpu-freq/ # Default CPU scaling governor to try. Some possible choices are: # performance: The CPUfreq governor "performance" sets the CPU statically # to the highest frequency within the borders of scaling_min_freq # and scaling_max_freq. # powersave: The CPUfreq governor "powersave" sets the CPU statically to the # lowest frequency within the borders of scaling_min_freq and # scaling_max_freq. # userspace: The CPUfreq governor "userspace" allows the user, or any # userspace program running with UID "root", to set the CPU to a # specific frequency by making a sysfs file "scaling_setspeed" # available in the CPU-device directory. # ondemand: The CPUfreq governor "ondemand" sets the CPU depending on the # current usage. # conservative: The CPUfreq governor "conservative", much like the "ondemand" # governor, sets the CPU depending on the current usage. It # differs in behaviour in that it gracefully increases and # decreases the CPU speed rather than jumping to max speed the # moment there is any load on the CPU. # schedutil: The CPUfreq governor "schedutil" aims at better integration with # the Linux kernel scheduler. Load estimation is achieved through # the scheduler's Per-Entity Load Tracking (PELT) mechanism, which # also provides information about the recent load. SCALING_GOVERNOR=ondemand # For CPUs using intel_pstate, always use the performance governor. This also # provides power savings on Intel processors while avoiding the ramp-up lag # present when using the powersave governor (which is the default if ondemand # is requested on these machines): if [ "$(cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_driver 2> /dev/null)" = "intel_pstate" ]; then SCALING_GOVERNOR="performance" fi # If rc.cpufreq is given an option, use it for the CPU scaling governor instead: if [ ! -z "$1" -a "$1" != "start" ]; then SCALING_GOVERNOR=$1 fi # To force a particular option without having to edit this file, uncomment the # line in /etc/default/cpufreq and edit it to select the desired option: if [ -r /etc/default/cpufreq ]; then . /etc/default/cpufreq fi # If you need to load a specific CPUFreq driver, load it here. Most likely you don't. #/sbin/modprobe acpi-cpufreq # Attempt to apply the CPU scaling governor setting. This may or may not # actually override the default value depending on if the choice is supported # by the architecture, processor, or underlying CPUFreq driver. For example, # processors that use the Intel P-state driver will only be able to set # performance or powersave here. echo $SCALING_GOVERNOR | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor 1> /dev/null 2> /dev/null # Report what CPU scaling governor is in use after applying the setting: if [ -r /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor ]; then echo "Enabled CPU frequency scaling governor: $(cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor)" fi As you can see the default is "ondemand", but then follows this condition which sets "performance" as default: # For CPUs using intel_pstate, always use the performance governor. This also # provides power savings on Intel processors while avoiding the ramp-up lag # present when using the powersave governor By that explanation its not recommened to set something else then "performance" for an Intel cpu. I had problems with "powersave" in the past, but this was with an Intel Atom CPU (now I'm having an i3): https://forums.plex.tv/t/cpu-scaling-governor-powersave-causes-massive-buffering/604018 I never experienced similar problems with "ondemand", so I wanted this gorvernor for the i3, too. Nevertheless I checked the active governor as follows: cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor performance Ok, performance has been set as expected. Lets try to overwrite it: /etc/rc.d/rc.cpufreq ondemand Enabled CPU frequency scaling governor: performance Hmm.. does not work. Seems to be this condition: # ... For example, # processors that use the Intel P-state driver will only be able to set # performance or powersave here. Lets try it out: cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor performance performance performance performance This means our cpu cores support only "performance"?! EDIT: Yes, recent Intel CPUs do only support performance or powersave (with massive lags): https://wiki.archlinux.org/index.php/CPU_frequency_scaling#Scaling_governors And the most important part: The performance governor should give better power saving functionality than the old ondemand governor. For me it does not really look like a proper p-state handling as my cpus maximum is 3.6Ghz and with really low load it never reduces the frequency: So lets try to find out what goes wrong here. At first the pstate values: ls /sys/devices/system/cpu/intel_pstate/* /sys/devices/system/cpu/intel_pstate/hwp_dynamic_boost /sys/devices/system/cpu/intel_pstate/num_pstates /sys/devices/system/cpu/intel_pstate/max_perf_pct /sys/devices/system/cpu/intel_pstate/status /sys/devices/system/cpu/intel_pstate/min_perf_pct /sys/devices/system/cpu/intel_pstate/turbo_pct /sys/devices/system/cpu/intel_pstate/no_turbo root@Thoth:~# cat /sys/devices/system/cpu/intel_pstate/hwp_dynamic_boost 0 root@Thoth:~# cat /sys/devices/system/cpu/intel_pstate/max_perf_pct 100 root@Thoth:~# cat /sys/devices/system/cpu/intel_pstate/min_perf_pct 22 root@Thoth:~# cat /sys/devices/system/cpu/intel_pstate/no_turbo 1 root@Thoth:~# cat /sys/devices/system/cpu/intel_pstate/num_pstates 29 root@Thoth:~# cat /sys/devices/system/cpu/intel_pstate/status active root@Thoth:~# cat /sys/devices/system/cpu/intel_pstate/turbo_pct 0 Explanations can be found here: https://www.kernel.org/doc/html/v4.12/admin-guide/pm/intel_pstate.html#user-space-interface-in-sysfs For example num_pstates returns the amount of p-states supported by the cpu. As we can see we have 29 for my cpu. And we know that the status is "active" and this means changing the p-states should work, but we do not know how: https://www.kernel.org/doc/html/v4.12/admin-guide/pm/intel_pstate.html#active-mode do we have Active with HWP or not? I found this sentence: https://01.org/linuxgraphics/gfx-docs/drm/admin-guide/pm/intel_pstate.html#user-space-interface-in-sysfs Our value is zero. What could that mean? Another hint that we are using Active with HWP is this explanation: https://www.kernel.org/doc/html/v4.12/admin-guide/pm/intel_pstate.html#energy-vs-performance-hints Lets check if they are present: Both are present so we can be sure. We use Active Mode with HWP: https://www.kernel.org/doc/html/v4.12/admin-guide/pm/intel_pstate.html#active-mode-with-hwp I disabled all my writings to the unraid server and stopped all disks. In this state the server consumes 24W. Performance still does not downclock: watch -n1 "cat /proc/cpuinfo | grep \"^[c]pu MHz\"" cpu MHz : 3600.114 cpu MHz : 3600.910 cpu MHz : 3601.040 cpu MHz : 3600.269 Does HWP + Performance mean it never changes the p-state? Which algorithm is used and where can I find it or influence it? I tried it with powersave /etc/rc.d/rc.cpufreq powersave Enabled CPU frequency scaling governor: powersave I don't know why, but all disks started with several seconds delay and very small writes (1,4 kB/s) were done. I waited one minute and spun them down again. The power consumption stayed at 24W. The frequency is only a little bit lower watch -n10 "cat /proc/cpuinfo | grep \"^[c]pu MHz\"" cpu MHz : 3263.100 cpu MHz : 3021.631 cpu MHz : 3252.913 cpu MHz : 2819.033 I checked the available HWP profiles and which one is used: cat /sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference balance_performance cat /sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences default performance balance_performance balance_power power I did not found any documentation about these variables. Only this answer to the same question: https://superuser.com/a/1449813/129262 So lets try them out: echo "power" > /sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference echo "power" > /sys/devices/system/cpu/cpu1/cpufreq/energy_performance_preference echo "power" > /sys/devices/system/cpu/cpu2/cpufreq/energy_performance_preference echo "power" > /sys/devices/system/cpu/cpu3/cpufreq/energy_performance_preference cat /sys/devices/system/cpu/cpu*/cpufreq/energy_performance_preference power power power power I tested "power" and "balance_power". No difference in power consumption. If I set "/etc/rc.d/rc.cpufreq" to "performance" the "/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference" becomes "performance". If I set it to "powersave" the preference becomes "balance_performance". Conclusion: Although "performance" is set, there is no room to save more energy in an idle state. "powersave" seems only influence the time in which the core stays in a slower state which could cause latency issues, but the lowest p-state is the same for all profiles. This is completely different to my Atom CPU, which directly showed a lower energy consumption after changing the profile to "ondemand". So it depends on the used CPU. But finally "ondemand" is set if its present so no further optimization seems to be needed. The next we could check are the c-states. For this I used "powertop" from the nerd pack. It seems we have the best results as c-state C10 is used most of the time:
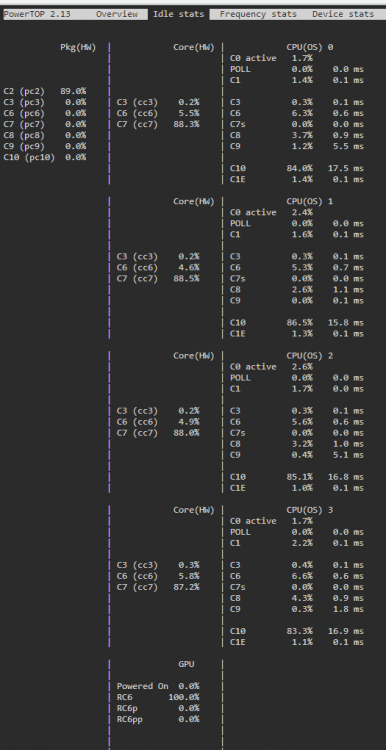 1 point
1 point -
when u want to change natively the listen port from filebrowser @brent3000 change it in the filebrowser.json file .. restart docker ... whyever u want todo so ...
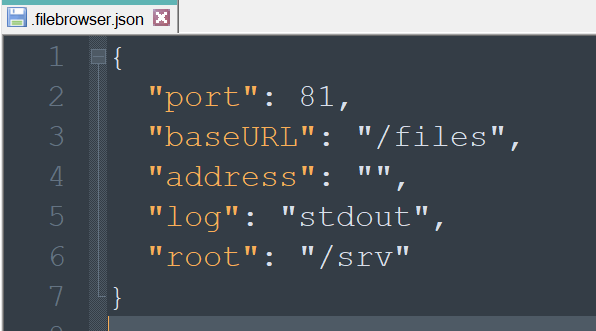
 1 point
1 point -
The easiest way to do this and to have everything in the webUI all in "sync" with the updates etc would be to install the Auto Update plugin. There you can configure it to automatically do this on a schedule etc. But, if you still want to trigger it via the command prompt, then /usr/local/emhttp/plugins/ca.update.applications/scripts/updateDocker.php > /dev/null 2>&1 Edit: You will have to configure the plugin though as to which apps to update, etc1 point
-
Hi Folks, I've been searching the forum and I still have a few questions. I'm trying to prepare for the worst case scenario which would result in me having to rebuild my unraid system from scratch (and of course, have no data loss). From forum posts I've read, I see "Community Applications" recommended to backup flash and files. I have this plugin but don't see any option where I can actually perform a backup of the flash/array files... Am I missing something? Thanks!1 point































ZohoMail.thumb.jpg.703f4dc537aa53b46dc7ce5559d6bccb.jpg)












