Leaderboard




Popular Content
Showing content with the highest reputation on 04/24/21 in all areas
-
I wasn't sure where to post this kind of thing - it's not exactly 'forum feedback', nor is it really a 'feature request for UnRAID' (if the capitalization is wrong here, please do let me know - I may've been writing it wrong all this time 😕 ), but more a 'business feature request' I guess... An ask of the team as far as planning goes I guess? The request: For Limetech to publish a Feature Roadmap which gives a generalized direction for wherever Limetech is planning to take the core OS over the next (however long you feel is realistic). What would be super helpful (and hopefully more realistically possible now that the team's grown a bit!) is to publish a Feature Roadmap, updated perhaps once per every major release (6.8, 6.9, 7.0, etc), or every 3-6ish months (whatever makes sense based on your internal structure and cadence), which outlines the 'big new things' planned for the next (however many releases can be semi-accurately forecast). _____ Some background: A Little Justification: Ideas for what it looks like: <To be filled out once I get back from the day out with the fam>1 point
-
This release contains bug fixes and minor improvements. To upgrade: First create a backup of your USB flash boot device: Main/Flash/Flash Backup If you are running any 6.4 or later release, click 'Check for Updates' on the Tools/Update OS page. If you are running a pre-6.4 release, click 'Check for Updates' on the Plugins page. If the above doesn't work, navigate to Plugins/Install Plugin, select/copy/paste this plugin URL and click Install: https://s3.amazonaws.com/dnld.lime-technology.com/stable/unRAIDServer.plg Bugs: If you discover a bug or other issue in this release, please open a Stable Releases Bug Report. Thank you to all Moderators, Community Developers and Community Members for reporting bugs, providing information and posting workarounds. Please remember to make a flash backup! Edit: FYI - we included some code to further limit brute-force login attempts; however, fundamental changes to certain default settings will be made starting with 6.10 release. Unraid OS has come a long way since originally conceived as a simple home NAS on a trusted LAN. It used to be that all protocols/shares/etc were by default "open" or "enabled" or "public" and if someone was interested in locking things down they would go do so on case-by-case basis. In addition, it wasn't so hard to tell users what to do because there wasn't that many things that had to be done. Let's call this approach convenience over security. Now, we are a more sophisticated NAS, application and VM platform. I think it's obvious we need to take the opposite approach: security over convenience. What we have to do is lock everything down by default, and then instruct users how to unlock things. For example: Force user to define a root password upon first webGUI access. Make all shares not exported by default. Disable SMBv1, ssh, telnet, ftp, nfs by default (some are already disabled by default). Provide UI for ssh that lets them upload a public key and checkbox to enable keyboard password authentication. etc. We have already begun the 6.10 cycle and should have a -beta1 available soon early next week (hopefully).1 point
-
1 point
-
You can do something like this : The support thread for the new Nvidia plugin is there :1 point
-
I'm not able to help you with the long lines you have provided. If you have logs with errors in them, feel free to open an issue ticket on GitHub with ALL the logs attached. As I mentioned earlier, if you are wanting help personally with regard to configuring Unmanic or issues with your files, please contact me on discord as a patron. I am unable to provide assistance to everyone who has issues with the configuration of unmanic or issues specific to their files. I would much rather spend my time further developing the application.1 point
-
1) To use the M.2 coral you need to install the "Coral Accelerator Module Drivers" plugin and then edit this: to this: 2) I already changed this on the template this week, look at the hidden settings and you should see this: If you don't see it, delete your container and add it again from the app store.


 1 point
1 point -
Das klingt doch schon viel besser. Es wird natürlich etwas langsamer über die Zeit, aber das liegt in der Natur einer HDD.1 point
-
Right, http://ipaddress redirects to https://hash.unraid.net . That is what it is designed to do. But if DNS is down and you can't resolve hash.unraid.net, you can use httpS://ipaddress (note the 's') as a work around, as long as you ignore the browser warnings.1 point
-
Yeah I figured out that I had to click on the icon next to the port to actually “assign” it to the VM and device. Once I did that it’s working great. My monitor has built in KVM so switching between my physical machine and an unraid vm now works like a treat.1 point
-
This worked, cheers! One thing to add is that I needed to log in with [email protected] and MyPassword for the first login regardless of what I had in the container variables.1 point
-
That works, thank you!1 point
-
It’s just a meme I saw once. Glad you are answering all the questions because uh, idk anything.1 point
-
Big THANK YOU to @JorgeB. It worked like a charm.Was able to retrieve all the data. Linux 4.19.98-Unraid. Last login: Tue Apr 20 19:19:53 -0400 2021 on /dev/pts/0. root@Tower:~# ddrescue -f /dev/nvme0n1 /dev/sdo /boot/ddrescue.log GNU ddrescue 1.23 Press Ctrl-C to interrupt ipos: 500107 MB, non-trimmed: 0 B, current rate: 1099 MB/s opos: 500107 MB, non-scraped: 0 B, average rate: 113 MB/s non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s rescued: 500107 MB, bad areas: 0, run time: 1h 13m 19s pct rescued: 100.00%, read errors: 0, remaining time: n/a time since last successful read: n/a Finished root@Tower:~# Still don't know if that drive is completely dead or not. Again Thank You.1 point
-
@Matthew_W @GregP @BullDog656 Please try the My Servers Dashboard again. It should be working again.1 point
-
Thanks again for reporting this, the issue has been resolved.1 point
-
It sounds like you enabled SSL for Local Access. This is a requirement if you want to use the optional Remote Access feature, otherwise it is not required. To disable Local Access SSL so go to Settings -> Management Access and set "Use SSL/TLS" to No.1 point
-
it was a licensing issue. when I remove the drive and acept the drive been marked as failed i was permited to start the array. thanks guys for the support!1 point
-
Thanks for your help. I have now measured it. The array takes 1m 45s to stop. I will revise the script and add the new timeouts.1 point
-
Click "Add Container" and enter the following. You will need to add new Vairables for everything except the AppData location which is a path. You can use the following as an icon URL (visible by clicking the advanced view toggle) - https://hay-kot.github.io/mealie/assets/img/favicon.png The WebUI can also be changed to your Unraid address followed by port 9926, unless you change this port in the initial step.
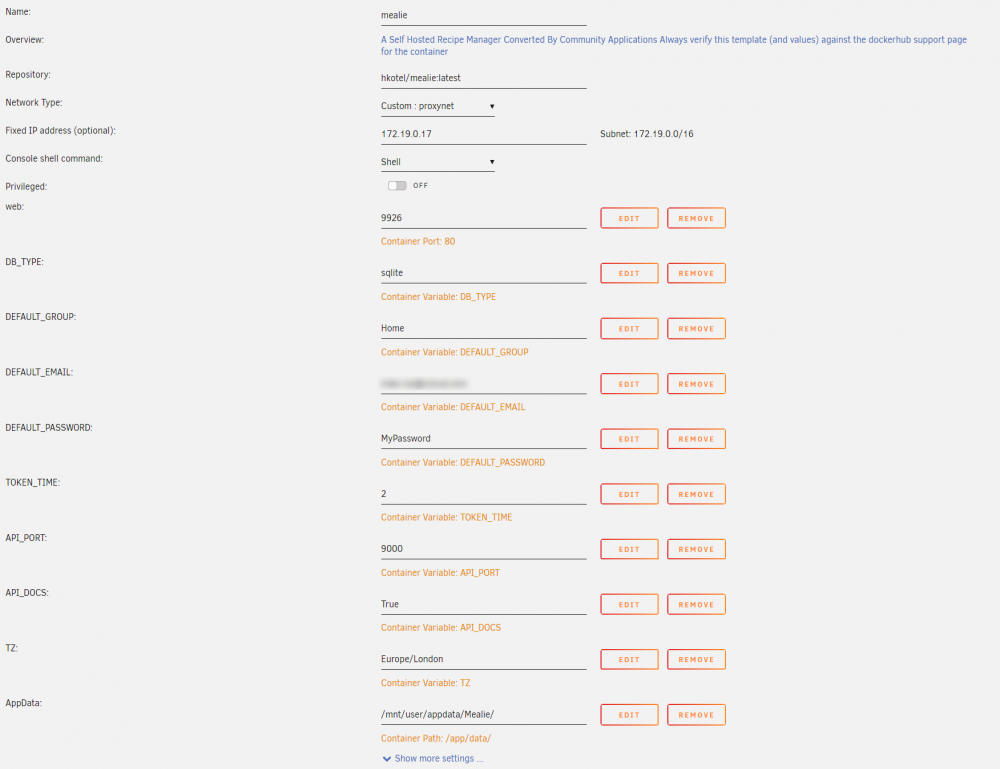 1 point
1 point -
Hab die Lösung gefunden, da Unraid die Array neu startet ist der DNS und Domain Server natürlich nicht erreichbar. hab ein Post gefunden in dem einer Unraid auf einem anderen DC in die Domain einbindet und dann den "selben" DC in der VM startet. Mal testen wenn ich Langeweile habe.1 point
-
Als kleines Update, da ich nun gezwungenermassen den Server abwürgen musste aufgrund eines 500 Internal Server Errors (jetzt gehts wieder hurra) macht es einen Parity Check und der ist nun mit ca. 216MB/s jedenfalls mal gestartet. Scheint eine wahnsinnig gute Idee gewesen zu sein😄 Falls das Tempo gehalten wird von 5 Tagen auf 23h die Parity Dauer reduziert. Hab 2 der AliExpress Karten jeweils an einem x1 Slot und je 4 Platten angeschlossen..1 point
-
I just wanted to stop in and say thanks for making this plugin. My transcoding GPU has been acting up for while, but I wasn't sure what the problem was. This plugin helped me see that the temp was high and the fan wasn't working. Turns out I had a stray wire blocking the fan's operation. So thanks again, I appreciate it.1 point
-
When you edit the container settings, there is a toggle at the upper-right corner that allows you to switch to the Advanced View. Once in that view, you will be able to click the Edit button of the "Storage" setting. In this new window, you can change the "Access Mode" to "Read/Write".1 point
-
You should be able to go into the prefs.xml file located in your Crushftp9 folder located in your Appdata (if you use the standard locations) share. Open the XML file and the banned ip's should be listed. Below is an example of a banned IP. Look for your ip or the ip of your reverse proxy server and delete that block. <ip_restrictions_subitem type="properties"> <start_ip>61.75.30.52</start_ip> <type>D</type> <stop_ip>61.75.30.52</stop_ip> <reason>05/29/2019 02:43:48.047:password attempts</reason> After you have deleted the banned ip you can search for the "never_ban" and add your lan range. <never_ban>127.0.0.1,10.0.*,172.*</never_ban> Then save and restart the docker container.1 point
-
By default, the mapping of /storage is read-only. If you want to restore to /storage, you need to edit the container settings and change /storage to be read/write (you need to enable advanced view to do this).1 point
-
I saw online some people were having this due to macvlan problems, which popped up in 6.8 or so, and were fixed, but are now back, and the log does seem to indicate that may be the problem. Unfortunately the containers I have using this broke when I took away their static ip (pihole, unifi, and a few others), so that is not an option. Do we know if the devs are working on a fix for this?1 point
-
This guide by lotetreemedia has been very helpful for me, but starting with unRAID 6.9.x the steps that are unraid specific should be done differently because unRAID has implemented GPU drivers. Everything lotetreemedia says to do in PLEX is still valid, but activating the driver is different. If you have lines in your "go" file you should remove them and change unRAID as follows: https://wiki.unraid.net/Unraid_OS_6.9.0#GPU_Driver_Integration After completing lotetreemedia 's steps in the PLEX docker, all I had to do to get QuickSync working with 6.9.1 was remove the lines from my "go" file and create a file in \flash\config\modprobe.d\i915.conf. The i915.conf file is just empty. craigr1 point
-
I replaced these lines in the '/mnt/cache/appdata/nextcloud/nginx/site-confs/default' file. (Adjust path to your appdata path, if it's different) location = /.well-known/carddav { return 301 $scheme://$host:$server_port/remote.php/dav; } location = /.well-known/caldav { return 301 $scheme://$host:$server_port/remote.php/dav; } location = /.well-known/webfinger { return 301 $scheme://$host:$server_port/public.php?service=webfinger; } location = /.well-known/host-meta { return 301 $scheme://$host:$server_port/public.php?service=host-meta; } location = /.well-known/host-meta.json { return 301 $scheme://$host:$server_port/public.php?service=host-meta-json; } with these lines # Make a regex exception for `/.well-known` so that clients can still # access it despite the existence of the regex rule # `location ~ /(\.|autotest|...)` which would otherwise handle requests # for `/.well-known`. location ^~ /.well-known { # The following 6 rules are borrowed from `.htaccess` location = /.well-known/carddav { return 301 /remote.php/dav/; } location = /.well-known/caldav { return 301 /remote.php/dav/; } # Anything else is dynamically handled by Nextcloud location ^~ /.well-known { return 301 /index.php$uri; } try_files $uri $uri/ =404; } Then I restarted the Nextcloud docker and the error was gone.1 point
-
to get german the interface in german language add the following to papermerge.conf.py in appdata folder LANGUAGE_CODE = "de-DE" to get german language for OCR go to docker shell and type apt-get install tesseract-ocr-deu and change the following in papermerge.conf.py like this OCR_DEFAULT_LANGUAGE = "deu" OCR_LANGUAGES = { "deu": "Deutsch", } And voila! German interface and OCR.1 point
-
I got this figured out and am able to use the MariaDB inside the container to make this work. No need to run a dedicated MariaDB docker instance. First, make sure the shinobipro docker container is running. Log into the console of the container, either by using the unraid feature or by this command: docker exec -ti shinobipro sh Next, create the database and tables... mysql source sql/framework.sql; source sql/user.sql; exit Now restart the container and it will work.1 point
-
Woah, this solved all my problems. Thanks!1 point
-
(I have updated this first post to reflect the solution I have found) My syslog shows read errors like those: Sep 3 08:17:01 SS kernel: print_req_error: critical medium error, dev sdr, sector 3989616 Sep 3 08:17:01 SS kernel: md: disk17 read error, sector=3989552 A parity check also confirms read errors on the same drive. I wanted to find out which files are affected and have used the following approach: Start maintenance mode Mount the drive partition: e.g. mount /dev/sdr1 /mnt/test. Get the drive number from the unRAID Main GUI. Add 1 to the drive number which indicates the first partition. Check the block size: xfs_info /mnt/test - look for data = bsize=[Block size]. In my case, on a 4TB drive it was 4096 Check the start sector of the partition with fdisk -lu /dev/sdr. In my case 64. Calculate the block number of the sector as: (int)([sector]-[start sector)*512/[block size]. My bad sector 3989616 is in block 498694. Unmount the partition so it xfs_db will run: e.g. umount /mnt/test Run xfs_db -r /dev/sdr1 (-r is for read-only) On the xfs_db command line: Get the information of the block with blockget -n -b [block number]. E.g. blockget -n -b 498694 This will run for a while as it reads the entire disk. At the beginning it will output the inode number for the block. In my case it was 35676. The larger the size of the drive, the more memory it needs. With 4GB on a 4TB disk I got an out of memory error: xfs_db: ___initbuf can't memalign 32768 bytes: Cannot allocate memory. Upgrading to 16GB allowed the command to run. Get the file name for the inode with: ncheck -i [inode] Enter quit or press Ctrl-D to exit xfs_db I have not figured out: How to get blockget to run faster or with less memory usage. Maybe there is an alternative way to determine the inode of a block. How to check additional blocks without exiting xfs_db and running blockget again. I tried convert but couldn't get it to work. Maybe someone from the community has an idea about those. Unfortunately, xfs_db is not very well documented yet on the web beyond man pages e.g. on https://linux.die.net/man/8/xfs_db Kind regards, Tazman1 point
-
i had a similar problem at one point and it turned out to be due to the fact the disk controller card was not perfectly seated in the motherboard. It would work most of the time, but occasionally a disk would get a write error and then all disks on the controller were missing. I assume that a momentary disconnect due to vibration meant the controller was lost and this caused the issue. This sounds similar to what you are seeing? the seating issue was due to the backplate tending to lift one edge of the connector slightly. Resolving this stopped my problem. As a general rule any error that takes out all disks on a controller means that you need to look at the controller rather than individual drives.1 point
-
You can also use /mnt/user0 share (bypasses cache)1 point






























