Leaderboard


Popular Content
Showing content with the highest reputation on 05/16/21 in all areas
-
Bon ben j'ai résolu mon problème en désactivant l'affichage du logo msi au démarrage au cas où cela peut aider quelqu'un et pour la température j'ai modifié à partir des paramètres disques généraux dans settings disk Ca applique la valeur à tous les disques mais au moins ça reste2 points
-
Oh Mann, vielen Dank für den Hinweis. Ich habe mich dumm und dämlich gesucht.. alle Plugins deinstalliert usw... Es lag nur an dem Fragezeichen^^2 points
-
thanks again everyone, especially @HyperV, @ich777, @Morthan and @ephdisk for your help. I am glad that any easy, non-intrusive fix has been found, as I am still reluctant to move away from 6.8.3.2 points
-
Well, it's the docker hub registry that changed something. However, the HTTP RFC spec states headers are case-insensitive, so the script is at fault and this script is under the control of LT. Unfortunately this temporary fix is indeed volatile, it will not survive a reboot. The script is unpacked from the image files to ram on each boot. A permanent fix would have to be made by LT. However, as @Squid pointed out, the current source of the webgui of Unraid, which contains this script, already has updated code for this. It appears someone else at some point revisited the code and came to the conclusion as well that the code was faulty and that headers should be checked case-insentively before this ever became a real problem. Now it has actually become a problem for people still running older versions because the casing of the header changed, so this fix should probably be back-ported or we are stuck with this temporary solution.2 points
-
I had exactly the same issue and could not find any solutions on the forum or the internet. So I did some digging myself and found the cause of the issue. The docker update check script gets the remote digest of the latest tag from the docker repository via a header called 'Docker-Content-Digest'. The script checks for this header with a case-sensitive regex pattern. Manually querying the docker hub registry gives me a header called 'docker-content-digest' (mind the casing). The docker hub registry must have recently changed the casing of this header, because it broke for me in the last 24 hours. I'm running on Unraid 6.8.3 still, so I'm not 100% sure if this issue also exists in 6.9.x. If you feel up to it, you could quite easily fix this yourself until there is a real fix. I'll describe the steps below: Open file: /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php Go to line 457. There you should look for the text: @Docker-Content-Digest:\s*(.*)@ and replace it with: @Docker-Content-Digest:\s*(.*)@i Save the file. This will make the header check case-insensitive and should make it work again.2 points
-
There are several things you need to check in your Unraid setup to help prevent the dreaded unclean shutdown. There are several timers that you need to adjust for your specific needs. There is a timer in the Settings->VM Manager->VM Shutdown time-out that needs to be set to a high enough value to allow your VMs time to completely shutdown. Switch to the Advanced View to see the timer. Windows 10 VMs will sometimes have an update that requires a shutdown to perform. These can take quite a while and the default setting of 60 seconds in the VM Manager is not long enough. If the VM Manager timer setting is exceeded on a shutdown, your VMs will be forced to shutdown. This is just like pulling the plug on a PC. I recommend setting this value to 300 seconds (5 minutes) in order to insure your Windows 10 VMs have time to completely shutdown. The other timer used for shutdowns is in the Settings->Disk Settings->Shutdown time-out. This is the overall shutdown timer and when this timer is exceeded, an unclean shutdown could occur. This timer has to be more than the VM shutdown timer. I recommend setting it to 420 seconds (7 minutes) to give the system time to completely shut down all VMs, Dockers, and plugins. These timer settings do not extend the normal overall shutdown time, they just allow Unraid the time needed to do a graceful shutdown and prevent the unclean shutdown. One of the most common reasons for an unclean shutdown is having a terminal session open. Unraid will not force them to shut down, but instead waits for them to be terminated while the shutdown timer is running. After the overall shutdown timer runs out, the server is forced to shutdown. If you have the Tips and Tweaks plugin installed, you can specify that any bash or ssh sessions be terminated so Unraid can be gracefully shutdown and won't hang waiting for them to terminate (which they won't without human intervention). If you server seems hung and nothing responds, try a quick press of the power button. This will initiate a shutdown that will attempt a graceful shutdown of the server. If you have to hold the power button to do a hard power off, you will get an unclean shutdown. If an unclean shutdown does occur because the overall "Shutdown time-out" was exceeded, Unraid will attempt to write diagnostics to the /log/ folder on the flash drive. When you ask for help with an unclean shutdown, post the /log/diagnostics.zip file. There is information in the log that shows why the unclean shutdown occurred.1 point
-
No problem, PM me if you find issues in setting the architecture up. For the Pi installation, I chose Ubuntu Server 20.04.2 LTS. You may chose Raspbian also, that's your choice. If you go for Ubuntu, this tutorial is just fine : https://jamesachambers.com/raspberry-pi-4-ubuntu-20-04-usb-mass-storage-boot-guide/ . Note that apart from the enclosure, it's highly recommended to buy the matching power supply by Argon with 3.5A output. The default RPi4 PSU is 3.1A, which is fine with the OS on a SD card, but adding a SATA M.2 SSD draws more current, and 3.5A avoids any risk of instability. The Canakit 3.5A power adapter is fine also, but not available in Europe for me. The general steps are : - flash a SD card with Raspbian - boot the RPi from the SD Card and update the bootloader (I'm on the "stable" channel with firmware 1607685317 of 2020/12/11, no issue) - for the moment, just let the RPi run Raspbian from the SD card - install your SATA SSD in the base of the enclosure (which is a USB to M.2 SATA adapter), and connect it to your PC - flash Ubuntu on the SSD from the PC with Raspberry Pi Imager (or Etcher, Rufus, ...) - connect the SSD base to the rest of the enclosure (USB-A to USB-A), and follow the tutorial from "Modifying Ubuntu for USB booting" - shutdown the RPi, remove he SD Card, and now you should boot from the SSD. By default, the fan is always on, which is useless, as the Argon One M.2 will passively cool the RPi just fine. You have to install either the solution proposed by the manufacturer (see the doc inside the box), not sure it works with Ubuntu. There's also a raspberry community package which is great and installs on all OSes, including Ubuntu, see https://www.raspberrypi.org/forums/viewtopic.php?f=29&t=275713&sid=cae3689f214c6bcd7ba2786504c6d017&start=250 . The install is a piece of cake, and the default params work well. Once the RPi is setup and the fan management of the case installed, just install chia, and then try to copy the whole ~/.chia directory from the container (mainnet directory in appdata/chia share) onto the RPi. Remove the plots directory from the config.yaml as the local harvester on the RPi will be useless anyway. That should preserve your whole configuration and keys, and above all your sync will be much faster, as you won't start from the very beginning of the chain. Run 'chia start farmer' and check the logs. Connect the Unraid harvester from the container as already explained, and check the connection in the container logs. At that stage, you should farm from the RPi the plots stored in the Unraid array through the harvester in the container. To see your keys, just type 'chia keys show' in the RPi, it shows your farmer public key (fk) and pool public key (pk). With these two keys, you can create a plot on any machine, even outside your LAN. Just run 'chia plots create <usual parameters> -f fk -p pk'. It signs the plot with your keys, and only a farmer with these keys can farm them. Once the final plot is copied into your array, it will be seen by the harvester, and that's all.1 point
-
Thank you so much!!! This is perfect! Exactly what I was looking for. I followed your steps and I have Swar humming along nicely inside this docker!! Now I can actually see what the docker is doing!! As an aside, this is also a great roadmap for me on how to get other scripts running inside other dockers!!!! Super helpful!!!1 point
-
...ist halt die Frage ob Du ECC RAM willst. Mit einem alten i5 oder auch aktuellem i3-10xxxx nicht möglich....ein i3-9xxx kann das noch und hat auch 4 Kernchen, ist etwas schlapper als Dein i51 point
-
Docker page is also unusable for me on both Pixel 3A XL and LG Velvet up to 6.9.1. I have about 30-40 containers, can't do anything on the page without it locking up.1 point
-
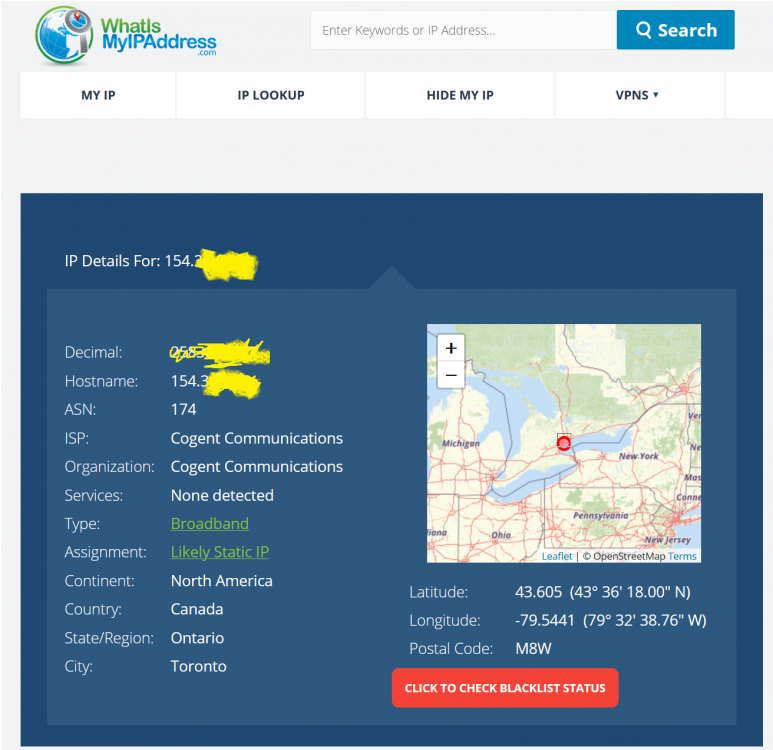
@Jorgen @ICDeadPpl @ljm42 Sometimes I swear I am getting senile!!!! The PIA script DOES WORK!!!! IF YOU USE THE CORRECT D@*#ED PASSWORD!!! ARRRGGGGGG! Thank you everyone for your time and patience. We have a great team here and hopefully this fiasco will help someone else! Be safe everyone!
 1 point
1 point -
Thanks for the quick reply. I will ask in the macinabox thread then. Cheers Daniel1 point
-
A single tunnel can support multiple connections (peers). Each peer wiil have the same access rights, e.g. "Remote connection to LAN". If you want different peers to have different access rights, you could set up multiple tunnels, each with a different connection type and let peers connect to one or the other.1 point
-
Ich kann dir nur sagen, dass diese Meldung kommt, weil etwas anderes auf die GPU zugreift. Und solange die VM nicht exklusiv auf die GPU zugreifen kann, wird sie auch nicht funktionieren. Das ist vom Prinzip alles irrelevant, da die Hardware für Unraid nicht mehr existiert, wenn sie an vfio gebunden ist. Mit dem allerneuesten Treiber eigentlich nicht mehr: https://unraid.net/blog/nvidia-gpu-support Wie gesagt würde ich mir eine GT710 besorgen und die als primäre GPU verwenden. Deine 210 hat ja nicht ordentlich funktioniert. Es gibt hier User, die das Problem damit lösen konnten.1 point
-
Selbst ein Atom Prozessor ist stärker. Viel besser. Gerade für Plex hättest du dann auch eine potente iGPU. Allgemein ist es auch einfacher in Unraid mit iGPU. Vergleich der Leistung: https://www.cpubenchmark.net/compare/Intel-Xeon-E5-2420-vs-Intel-Pentium-Silver-J5040-vs-Intel-i5-7600K/1213vs3665vs2919 Wichtig ist Single Thread. Möglichst kleines Netzteil und je nach Board kann das auch stromsparend werden. Hat das Board genug SATA Ports? Vielleicht findest du sonst ein gebrauchtes C236 Board mit 8x SATA.1 point
-
If you ever want to create something else than k-32 , the CLI tool also accepts the '-k 33' parameter for instance. If '-k' is not specified, it defaults to '-k 32' which is the current minimal plot size. All options are documented here https://github.com/Chia-Network/chia-blockchain/wiki/CLI-Commands-Reference , and 'chia plots create -h' is a good reference also 😉1 point
-
Hi, Thanks for your interest in my post, I'll try to answer your numerous questions, but I think you already got the general idea of the architecture pretty well 😉 - The RPi doesn't have a M.2 slot out of the box. By default, the OS runs from a SD card. The drawback is that SD cards don't last so long when constantly written, e.g. by the OS and the chia processes writing logs or populating the chain database, they were not designed for this kind of purpose. And you certainly don't want to lose your chia full node because of a failing 10$ SD card, as the patiently created plots are still occupying space, but do not participate in any challenge... So, I decide running the RPi OS from a small SATA SSD was a much more resilient solution, and bought an Argon One M.2 case for the RPi. I had an old 120 GB SATA SSD which used to host the OS of my laptop before I upgraded it to a 512 GB SSD, so I used it. This case is great because it's full-metal and there are thermal pads between the CPU and RAM and the case. So, it's essentially a passive heat dissipation setup. There's a fan if temps go too high, but it never starts, unless you live in a desert I suppose. There are many other enclosures for RPis, but this one is my favorite so far. - The RPi is started with the 'chia start farmer' command, which runs the following processes : chia_daemon, chia_full_node (blockchain syncing), chia_farmer (challenges management and communication with the harvester(s)) and chia_wallet. chia_harvester is also launched locally, but is totally useless, as no plots are stored on a storage accessible by the RPi. To get a view on this kind of distributed setup, have a look at https://github.com/Chia-Network/chia-blockchain/wiki/Farming-on-many-machines, that was my starting point. You can also use 'chia start farmer-no-wallet', and sync your wallet on another machine, I may do that in the future as I don't like having it on the machine exposed to the internet. - The plotting rig doesn't need any chia service running on it, the plotting process can run offline. You just need to install chia on it, and you don't even need to have your private keys stored on it. You just run 'chia plots create (usual params) -f <your farmer public key> -p <your pool public key>' , and that's all. The created plots will be farmed by the remote farmer once copied into the destination directory. - I decided to store the plots on the xfs array with one parity drive. I know the general consensus is to store plots on non-protected storage, considering you can replot them. But I hate the idea of losing a bunch of plots. You store them on high-density storage, let's say 12TB drives, which can hold circa 120 plots each. Elite plotting rigs with enterprise-grade temporary SSDs create a plot in 4 hours or less. So recreating 120 plots is circa 500 hours or 20 days. When you see the current netspace growth rate of 15% a week or more, that's a big penalty I think. I you have 10 disks, "wasting" one as a parity drive to protect the other 9 sounds like a reasonable trade-off, provided you have a spare drive around to rebuild the array in case of a faulty drive. To sum up, two extra drives (1 parity + 1 spare) reasonably guarantee the continuity of your farming process and prevent the loss of existing plots, whatever the size of your array is. Of course with a single parity drive, you are not protected against two drives failing together, but as usual it's a trade-off between available size, resiliency and costs, nothing specific to chia ... And the strength of Unraid is you won't lose the plots on the healthy drives, unlike other raid5 solutions. - As for the container, it runs only the harvester process ('chia start harvester'), which must be setup as per the link above, nothing difficult. From the container console, you can also optionally run a plotting process, if your Unraid server has a temporary unassigned SSD available (you can also use your cache SSD, but beware of space ...). You will run it just like on your plotting rig : 'chia plots create (relevant params) -f <farmer key> -p <pool key>'. The advantage is that the final copy from the temp dir to the dest dir is much quicker, as it's a local copy on the server from an attached SSD to the Unraid share (10 mins copy vs 20/30 mins over the network for me). - So yes, you can imagine running your plotting process from a container on the Unraid server if you don't have a separate plotting rig. But then I wouldn't use this early container, and would rather wait for a more mature one which would integrate a plotting manager (plotman or Swar), because managing all that manually is a nightmare on the long run, unless you are a script maestro and have a lot of time to spend on it 😉 Happy farming !1 point
-
They don't make them. In North America EVGA used to market and sell PSU's made by Super Flower. Now that the exclusive marketing deal is over Super Flower now sells and market PSU's under its own name.1 point
-
It is normal when UPS in battery mode, a big transformer were inside the UPS ( thats why UPS usually quite heavy ). The buzzing increase with the loading.1 point
-
You can even enable it part way through a file copy, if you want to.1 point
-
Yes, you can actually use gvt-g with a macOS vm. There are some extra things to do if I remember correctly, but yes it does work! Gesendet von iPhone mit Tapatalk1 point
-
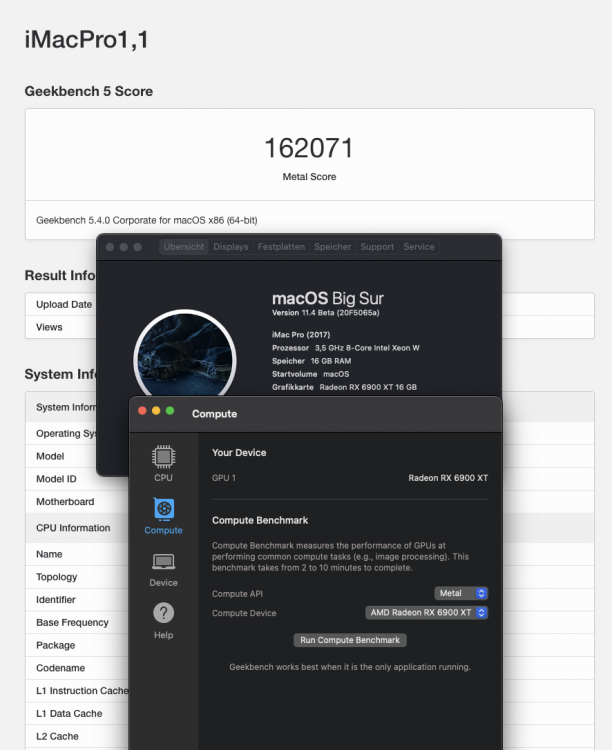
Hello guys!! Just wanted to share something with you. I tested a 6900xt in macOS Big Sur 11.4beta. Metal performance is outstanding:
 1 point
1 point -
The 750 is a supported card and the plugin should work with it just fine. From the two comments that you've made you actually don't need the Nvidia-Driver plugin since the plugin is only a addon for Docker containers to use the cards in containers and as you said you use them in VM's you have not much of a benefit installing it. You can of course use the 10900K with QuickSync (I'm also using it on my 10600 and from a technical point the QuickSync engine is on both CPUs the same). It should be capable of transcoding 4 to 5 simultaneous HEVC streams (depending on the settings) without a problem, also like the 1660. That depends on what you prefer but you can't use the 1660 in a VM and also for a Docker container at the same time. You setup would be perfect if you do it like that: 750 for VM 1660 for VM iGPU for Docker If you do it like above you only have to install the Intel-GPU-TOP plugin (the plugin handles the installation and enabling of the iGPU and also sets the permissions), in Plex add the device: '/dev/dri' (without qutoes) and you should be good to go (and of course you can use the output of the Intel iGPU for your Unraid terminal/GUI - please also make sure that you actually set the primary video card to the iGPU in the BIOS and connect a monitor or dummy plug so that the iGPU is properly enabled when you boot up the machine). What I also recommend is to uninstall the Nvidia-Driver plugin since you don't have much benefit if you are using the Nvidia cards in VMs and not in Docker containers. Hope that helps.1 point
-
Yes. its often referred to as Turbo which there is a plugin for that will check how many drives are spinning and enable that mode and disable automatically.1 point
-
What power supply are you using that has an "ECO" mode? I've never heard of that. nevermind. didn't know evga made power supplies. As @jonathanm said, you're probably hearing various transformer vibrating when put under load. All my APC units have a distinct "hum" to them when they're on battery power; it's the transformer in the inverter coming under load, and the plates in it are vibrating. Every transformer does it, just better/expensive ones do it less. You could possibly be hearing an interaction between the transformers in the PSU and UPS, such that they're "beating" against each other electrically (feedback), due to the "Simulated Sine Wave Output" on the UPS.1 point
-
This might be a stupid question, but the cable I talked about also has a SATA power connector, do I need to plug this connector for the cable to work? EDIT: Found myself a 4pin to SATA cable to connect this SATA 15pin power end on the Mini SAS cable and everything works now. I'm dumb. Thanks for everyone help and sorry for my lack of knowledge1 point
-
Normal. The simulated sine wave is "dirty" compared to mains.1 point
-
Without port 8444 forwarded to the full node, you'll have sync issues, as you will only have access to the peers which have their 8444 port accessible, and they are obviously a minority in the network.... Generally speaking, opening a port to a container is not such a big security risk, as any malicious code will only have access to the resources available to the container itself. But in the case of chia, the container must have access to your stored plots to harvest them. An attacker may thus be able to delete or alter your patiently created plots from within the container, which would be a disaster if you have hundreds or thousands of them ! And one of the ways to maximise one's netspace ownership could be the deletion of others' plots ... That's one of the reasons why I decided to have a dedicated RPi to run the full-node, with the firewall allowing only the strictly required ports, both on the WAN and LAN sides. There's no zero risk architecture, but I think such a setup is much more robust than a fully centralised one where a single machine supports the full set of functions.1 point
-
So I have swar plot manager running, had time to play with it today. This setup isn't elegant and probably isn't following best practices but it works for me. Please be mindful of this, if you break something, lose plots, etc.. don't come cryin' Open the docker console (click on the docker --> console) NOTE: not the unraid main console We are going to pull swar's git and install its python dependencies. Installing into /root/.chia in the docker which points to /mnt/user/appdata in unraid. cd /root/.chia git clone https://github.com/swar/Swar-Chia-Plot-Manager cd Swar-Chia-Plot-Manager /chia-blockchain/venv/bin/pip install -r requirements.txt cp config.yaml.default config.yaml You can now edit the config.ymal file using an editor supported within this docker OR from the appdata/chia/Swar-Chia-Plot-Manager folder within unraid (unraid console, krusader, a windows share if you set that up) Here are some values to be used along with whatever else you set in the config... chia_location: /chia-blockchain/venv/bin/chia folder_path: /root/.chia/logs/plotting temporary_directory: /plotting destination_directory: /plots now test if it's working . /chia-blockchain/activate python manager.py view make sure the drives look like they have the correct space and used space values (if not then your probably mapping to a folder inside your docker image. /plotting and /plots are the mappings used during the default chia docker setup, that's why we used them here. If you start a chia plotting process and these aren't right you will fill your docker to 100% usage! If you're running "fix common problems" plugin, you will see warnings in the unraid GUI. You'll have to clean up the mess you made buy deleting whatever incorrect folders you created in the docker. CTRL+C to get out of view mode If everything looks good lets start swar manager python manager.py start Now whenever you want to use the swar manager open the chia docker console and view (or replace which ever command you need.. start, restart). You need to activate the python virtual environment everytime before your manager.py command as stated by the swar documentation. This is the second line you see here.. cd /root/.chia/Swar-Chia-Plot-Manager/ . /chia-blockchain/activate python manager.py view Want to use the main unraid console instead of being stuck inside the docker console, heck even use tmux? Do the following then repeat the commands directly above... docker exec -it chia bash Enjoy! I look forward to any suggestions for improvement, I'm sure there are better methods.1 point
-
Pardon my rudeness but your sed command replaces the entire line with just that text. I adjusted it a bit and use this instead, so it only replaces the found text ( I almost always use different delimiters because the slashes get in the way of seeing what is being done with the backslashes in the way) sed -i 's#@Docker-Content-Digest:\\s*\(.*\)@#\@Docker-Content-Digest:\\s*\(.*\)@i#g' /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php I used https://sed.js.org/ to check the syntax1 point
-
Just wanted to say thanks to @ich777 - I put an old GTX 960 into my Dell R720 and now Plex transcoding is all being done so smoothly (particularly subtitled shows). Amazing instructions, all worked first time. Beautiful work.1 point
-
^This If you install puTTY you can connect via ssh to a Linux terminal running on your server and in that terminal you could run mc (Midnight Commander), which is a very powerful file manager. It's text based but pseudo-graphical and fairly easy to learn and it can access all the files on the server, including the ones you really don't want to mess with!1 point
-
As @tjb_altf4 said, this thread has nothing to do with assigning one GPU to multiple VM's. This violates the Nvidia EULA, I think you know what that means... Also keep in mind you have to buy licenses from Nvidia for every VM that you want to run a vGPU on.1 point
-
We have to be careful about making promises, but I do not want this to be a permanent warning1 point
-
P and Q are the long standing names from the existing Mathematical Realm Algorithms for parity protection.1 point
-
DEVELOPER UPDATE: 😂 But for real guys, I'm going to be stepping away from the UUD for the foreseeable future. I have a lot going on in my personal life (divorce among other stuff) and I just need a break. This thing is getting too large to support by myself. And it is getting BIG. Maybe too big for one dash. I have plenty of ideas for 1.7, but not even sure if you guys will want/use them. Not to mention the updates that would be required to support InfluxDB 2.X. At this point, it is big enough to have most of what people need, but adaptable enough for people to create custom panels to add (mods). Maybe I'll revisit this in a few weeks/months and see where my head is at. It has been an enjoyable ride and I appreciate ALL of your support/contributions since September of 2020. That being said @LTM and I (mostly him LOL) were working on a FULL Documentation website. Hey man, please feel free to host/release/introduce that effort here on the official forum. I give you my full blessing to take on the "support documentation/Wiki" mantel, if you still want it. I appreciate your efforts in this area. If LTM is still down, you guys are going to be impressed! I wanted to say a huge THANK YOU to @GilbN for his original dash which 1.0-1.2 was based on and ALL of his help/guidance/assistance over the last few months. It has truly been a great and pleasurable experience working with you man! Finally, I want to say a huge thanks to the UNRAID community and its leadership @SpencerJ @limetech. You guys supported and shared my work with the masses, and I am forever grateful! I am an UNRAIDer 4 LIFE! THANKS EVERYONE!1 point
-
Hi - had the same problem. I did solve it with this command in ssh: So - reboot isn't neccessary.1 point
-
Cache Dir plugin works most of the time so I can browse folders without spinning up drives. Tested it and it works. Parity check will have to spin up all drives anyway so I don't think that's relevant. And I did not mention anything about RAID. Within the context of unRAID, if 2 people access 2 different files on the same HDD, the disk will have to spin back and forth to get the data. If 2 people access 2 files on 2 HDD then each HDD serves its own file, no seeking. That's the performance point. I think we can agree to disagree and keep it there as it really depends on each's perspective.1 point























