Leaderboard


Popular Content
Showing content with the highest reputation on 06/29/21 in all areas
-
I'm really tempted to change the title of this thread to something like Cipher Message of the Month or just Soon™️ Especially when the forum automatically inserts the "4 weeks later..." 🤣
 4 points
4 points -
Hi all! Test version (ghcr.io/guydavis/machinaris:test) now has initial support for concurrent farming of the same plots on the Flax network. This is early stages, with some known issues, but feedback on the implementation so far is appreciated. Details on the Flax wiki page. Thanks!
 3 points
3 points -
3 points
-
Ok, so my latest write report came in and I am quite happy with the results. Before disabling docker logs / extending helthchecks to 1hour on a BTRFS formatted drive with a BTRFS docker image: 75-85gb writes/day Disabling the "low hanging fruit" docker logs on the same btrfs/btrfs setup: 50gb/day Disabling almost all the docker logs and extending healthchcks to 1 hour 39gb/day Have a feeling that would come down a bit more if left for longer, so basically cut the writes in half, which is about right when you consider the next datapoint. When I first started logging the writes in docker the activity log was around ~100mb/day. Today I got a mere 2.5mb/day, most of that came when one container did some kind of update and flooded the log, excluding that it is like 0.5mb I also started monitoring writes in appdata and the activity log for it is 75mb/day, so all said, cutting writes in half is about right. If I go back to an XFS formatted drive, I should cut the writes by 3x, dropping me down to ~12gb/day, not bad at all. This is as far as I can reasonably take the docker side of the write issue, the remaining logs I do need on occasion so worth a few writes for them. Everything else is program dependent in appdata.2 points
-
Version 6.10.0 Beta 21 06/27 2021 Is that it?2 points
-
@SpencerJ contacted @nexusmaniac and I while we were playing Stellaris Nemesis. Unfortunately, while traveling to go back to our home planet, a supernova explosion blinded us and now we are stuck with this cryptic message from @SpencerJ "⠠⠧⠑⠗⠎⠊⠕⠝ ⠎⠊⠭.⠞⠑⠝.⠵⠑⠗⠕⠤⠃⠑⠞⠁⠞⠺⠑⠝⠞⠽⠕⠝⠑ ⠞⠺⠕⠞⠓⠕⠥⠎⠁⠝⠙⠞⠺⠑⠝⠞⠽⠕⠝⠑⠤⠵⠑⠗⠕⠎⠊⠭⠤⠞⠺⠑⠝⠞⠽⠎⠑⠧⠑⠝" Soon™️2 points
-
Update: Thank you guys so much seems you guys were on the mark the power to the drives were just not as strong with the splitters. thank you jonathanm for pointing out the molex adapters and recommending not to go for splitters rather those adapters, Thank you everyone else for working together and finding the faults in my system! I switched the cables and got everything hooked up and now my parity will only take 1 day and 2 hours compared to 1060 days! i can finally have security also plex and everything else is working while thats happening in the background so this is wonderful! You guys rock! if theres like a kudo thing to give proper thanks let me know how! im a happy unraid pro user now :32 points
-
Thanks for point that out @sonic6! I'll soon be active development on the server docker again, so I'll be sure to update you @ich777 if anything I change should cause breakages.2 points
-
Unraid does a nice job of controlling HDD's energy consumption (and probably longevity) by spinning down (mechanical) hard drives when idle for a set period of time. Unfortunately the technique used by Unraid to spin down an HDD, true to the time of writing this, works only for ATA drives. If you have SCSI/SAS hard drives, these drives do not spin down (although the UI will indicate they do). The drives continue spinning 24x7, expanding the energy footprint of your Unraid server. Following a long and fruitful discussion here, a solution is provided via this plugin. This is hopefully a temporary stopgap, until Limetech includes this functionality in the mainline Unraid, at which time this plugin will walk into the sunset. Essentially, this plugin complements the Unraid SATA spindown functionality with SAS-specific handling. In version 6.9 and upwards, it enhances the "sdspin" function (focal point for drive spin up/down) with support for SAS drives. In prior versions (up until 6.8.x) it does the following: 1. Install a script that spins down a SAS drive. The script is triggered by the Unraid syslog message reporting this drive's (intended) spin down, and actually spins it down. 2. Install an rsyslog filter that mobilizes the script in #1. 3. Monitor rsyslog configuration for changes, to make sure the filter in #2 above stays put across changes of settings. In addition, the plugin installs a wrapper for "smartctl", which works around smartctl's deficiency (in versions up to 7.1) of not supporting the "-n standby" flag for non-ATA devices (which leads to many unsolicited spin-ups for SAS drives). When this flag is detected, if the target device is SAS and is in standby (i.e. spun down), smartctl is bypassed. You can install this plugin via Community Applications (the recommended way), or by using this URL: https://raw.githubusercontent.com/doron1/unraid-sas-spindown/master/sas-spindown.plg In "Install Plugin" dialog. When you remove the plugin, original "vanilla" Unraid behavior is reinstated. As always, there is absolutely no warranty, use at your own risk. It works for me. With that said, please report any issue (or success stories...) here. Thanks and credit points go to this great community, with special mention to @SimonF and @Cilusse. EDIT: It appears that some combinations of SAS drives / controllers are not compatible with temporary spin-down. We've seen reports specifically re Seagate Constellation ES.3 and Hitachi 10KRPM 600GB but there are probably others. Plugin has been updated to exclude combinations known to misbehave, and to use a dynamic exclusion table so that other combinations can be added from time to time. 19-Nov-20201 point
-
第 1 阶段:启动并完美运行 Unraid 所必要的手动设置 感谢您试用 Unraid。为了确保 Unraid 的启动与完美体验,您需要执行一些额外的步骤,从而获得 Unraid OS 的最佳表现。 我们正在努力使这些步骤自动化进行并在系统内部进行更改,以便将来无需手动执行。感谢您在此期间对我们的支持与理解! 非常感谢 @JavyLiu 提供的所有帮助 https://wiki.unraid.net/入门指南_-_Chinese_Getting_Started_Guide1 point
-
Salut! Si vous aimez Discord, consultez le serveur de @superboki! https://discord.superboki.fr Peut-être que vous pouvez voir un peu de mon mauvais français? 😉1 point
-
Unraid und VM bekommt alle Kerne und die CPU kümmert sich um die Verteilung der Last. Gar kein Problem. Ob nun 2 Kerner oder 4 Kerner... Wenn gerade ein i3-8100 gebraucht für 60 € oder so zur Verfügung steht, würde ich den klar einem neuen G5400 vorziehen. Also ich würde es einfach vom Preisaufschlag abhängig machen.1 point
-
I added a new NVME cache drive so moved my appdata to the array then onto the new cache drive by changing the cache settings (prefer > remove old cache > no > add new cache > prefer). I see that not all has moved so I run the mover but it doesn't do anything but crashes and removes all the shares until I reboot. The log shows a crash right after I invoke the mover but I don't know why: Jun 6 13:40:21 Tower emhttpd: shcmd (86): /usr/local/sbin/mover &> /dev/null & Jun 6 13:40:21 Tower kernel: shfs[9246]: segfault at 0 ip 000000000040548a sp 00001538f9101840 error 4 in shfs[403000+d000] Jun 6 13:40:21 Tower kernel: Code: 48 8b 45 f0 c9 c3 55 48 89 e5 48 83 ec 20 48 89 7d e8 48 89 75 e0 c7 45 fc 00 00 00 00 8b 45 fc 48 63 d0 48 8b 45 e0 48 01 d0 <0f> b6 00 3c 2f 74 43 8b 05 29 3f 06 00 85 c0 78 2f e8 b0 df ff ff Jun 6 13:40:22 Tower kernel: [drm] PCIE GART of 256M enabled (table at 0x000000F400000000). Jun 6 13:40:22 Tower kernel: [drm] UVD and UVD ENC initialized successfully. Jun 6 13:40:22 Tower kernel: [drm] VCE initialized successfully. Can anyone point me in the right direction? I'm not sure how to troubleshoot further. Thanks tower-syslog-20210606-1241.zip1 point
-
Haha done 🙂1 point
-
See if disabling spin down helps with the drives getting disabled, also make sure just one cable goes to the MD1200, Unraid doesn't support SAS multi-path, these errors are likely the result of that: Jun 29 07:30:40 r720 emhttpd: device /dev/sdt problem getting id Jun 29 07:30:40 r720 emhttpd: device /dev/sdz problem getting id Jun 29 07:30:40 r720 emhttpd: device /dev/sdu problem getting id Jun 29 07:30:40 r720 emhttpd: device /dev/sdr problem getting id Jun 29 07:30:40 r720 emhttpd: device /dev/sdx problem getting id Jun 29 07:30:40 r720 emhttpd: device /dev/sdv problem getting id Jun 29 07:30:40 r720 emhttpd: device /dev/sds problem getting id Jun 29 07:30:41 r720 emhttpd: device /dev/sdah problem getting id Jun 29 07:30:41 r720 emhttpd: device /dev/sdy problem getting id Jun 29 07:30:41 r720 emhttpd: device /dev/sdal problem getting id1 point
-
lol, yeah I tend to do that from time to time. Plus seeing the writes slowly add up and the remaining life slowly tick down on the SSD has been an itch I needed to scratch for some time. Figure I will see what is possible under the best case setup and then back off to comfortable compromise after that. For example the above docker side commands are well worth the effort IMHO as they "just work" once you know what containers need which command and have a big effect on writes. Some of the appdata writes are pretty simple fixes as well such as reducing/disabling logging or moving logs to an internal ramdrive instead of writing to appdata etc. My goal is to create another thread with a guide once I finish my testing. For now these posts are basically my journal on the matter for later reference.1 point
-
Yes, I did exactly this. I was expecting to do it once only thats why I made no scripts for that. I hope I'll not need to do it and plugin dev will release update, or plugin dev share his build steps. Anyway I'm with unRAID for a long time, and if it is really needed I can make automated updates for this plugin.1 point
-
Yes and Yes Saw your edit. I saw that the key of blockchains was set to chia, instead of blockchains this fixed it for me atm1 point
-
Your thread, your prerogative. Just edit the first post. 😎1 point
-
1 point
-
In my mind I hear this with a weird voice with a weird accent.1 point
-
Danke. Da ich grundsätzlich nicht mehr mit User Shares arbeite, ist das hier selbstverständlich. Auf Grund eigener schlechter Erfahrungen mit BTRFS (NVMe M.2 Devices) kommt mir das bis auf Weiteres nicht mehr ins Haus. Ich weiß, bei anderen läuft das problemlos, aber bei mir hat es jede Menge Ärger bedeutet. Seit der Umstellung auf XFS vor ca. einem halben Jahr hatte ich nie wieder Probleme mit diesen Devices.1 point
-
I got the new PSU installed, a 1000w modular jobby and everything seems fine, certainly not hearing that chirping sound from various disks, so not sure if the pSU was dying or whether it just wasnt powerful enough when all the disks would spin up, it was only effecting the one row of drive bays. Anyway all good now, and the disk that kept getting disabled has been precleared and put back into the array and is 100% fit...so now i will go grab other disks that were etting disled and see if they can be reintroduced.1 point
-
Für externe WD Platten ist hier ne Übersicht was jeweils verbaut ist/sein kann. Quelle: https://www.satdream.tech/site/file/source/galerie/wd/wdexternals35.png
 1 point
1 point -
Nein, ging von der technischen Angabe bei Geizhals aus: https://geizhals.de/seagate-expansion-desktop-steb-10tb-steb10000400-a2120053.html Scheint aber eine falsche Angabe zu sein: https://www.reddit.com/r/DataHoarder/comments/h8agze/recently_shucked_steb10000400_is_that_cmrpmr/1 point
-
Bro, you are genius, the /config is different. Don't know what did I do, but somehow, the /config in container change to /mnt/user/appdata/binhex-deluge (not delugevpn). That's why it can not find the opvn files. Change it to correct path, the container is running. Only problem the data is not the up-to-date as I remembered. I need to restore it from my backup. Thank you very much Binhex.1 point
-
wow,太棒了。1 point
-
sure, -1 is auto, so have a play and see if you get any improvements by changing it.1 point
-
ok and can you left click delugevpn and select edit, then click on 'show more settings' at the bottom and screenshot what /config is set to, also do the following:- https://github.com/binhex/documentation/blob/master/docker/faq/help.md1 point
-
Version 6.10.0 Beta21 2021-06-271 point
-
感谢 Spencer 以及 Lime Tech 团队为中文化支持做出的不懈努力!1 point
-
Yeah, both ferdi and ferdi-server are under active development. I'm planning to begin working again on ferdi-server-docker soon, once I I finish up another project. Glad you were able to find the things you were looking for though!1 point
-
User scripts plugin will do it, it has options to run scripts on cron schedule and also to run at array startup/stop etc.1 point
-
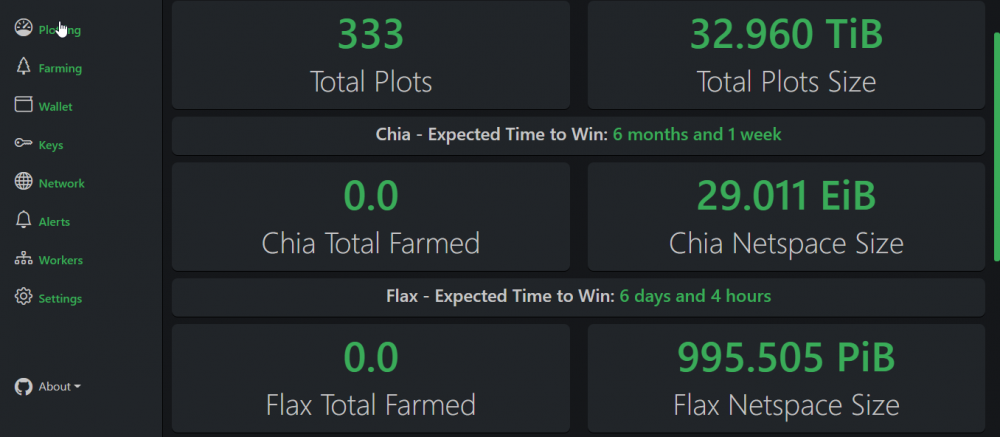
what i do to monitor temp drive space is open several terminal windows and run the following command in each one 1st terminal - watch -n10 du -sh /mnt/plotting <--- put your directory here for tmp 1 2nd terminal - watch -n10 du -sh /mnt/ram <--- put your directory here for tmp 2 they should both empty out after each job hope this helps you trouble shoot EDIT : also you can use an old ipad/iphone or any tablet/phone, that you may have lying and use that to monitor your plotting screen. like i use an iphone 5 and iphone 5c to monitor drive space, and iphone 6 to monitor Machinaris GUI. use safari to login to unraid, open terminal window and type in your commands ALSO make sure to turn OFF sleep mode on phones/tablet1 point
-
Yes I think you can just edot the file and set the time to when your server is on. Restart the container after modifying the file.1 point
-
Maybe a defective controller... And yes, the card is working on your hardware.1 point
-
Can you get to the "bios" of the LSI card (CTRL-S if I remember) when it's itemizing the drives connected to it?1 point
-
Try the Manual Method https://wiki.unraid.net/Articles/Getting_Started#Manual_Method_.28Legacy.291 point
-
This would be great if it had a gui interface, gave a report of what dupes were found, and had options to choose which ones to keep.1 point
-
Look like you had multiple disks drop offline simultaneously. I would suspect that you have some sort of hardware related issue. Since a parity check is when the system is under maximum load it could be power related. Other possibilities that spring to mind are something more obscure like an improperly seated HBA.1 point
-
I hope this does not happen. As one who has attempted to provide forum support on SMB issues the past few years, the last thing I want to see is another variable in the mix.!!! Most of the SMB issues today are the result of attempting modify the Windows 10 SMB by turning off the security changes that MS has added. Most Unraid users would have had fewer SMB problems if we all would have modified our Unraid setup to accommodate those changes rather than working on the Windows side. Let me point out that the present default Unraid setup will serve up everything on your array to the entire world. It is protected only by your router and the password on your Wireless Access Point. Do you really want this situation? The problem was that the SMB changes came slowly out of MS and the PC manufacturers (apparently) delayed incorporating some of the changes into the product they are shipping. Larger organizations which had people/departments with IT expertise and training knew how (or quickly learned) to incorporate these changes into their current practices. MS did not help we little folks out by not providing any information/documentation on how to actually do this. (If any one knows of any MS publicly available information, I would appreciate knowing of it!) Further, complicating the problem is that you google about some SMB problem, you will probably find more bad information than good. A couple of us are working to prepare a set of How-to instructions setting up both the Unraid server and the Windows 10 Client to integrate the two more smoothly in a manner which embraces modern security. An even bigger point is that many folks are spending more time trying to bypass the Windows 10 SMB security than it takes to setup Unraid to accommodate it!1 point
-
For Unraid version 6.10 I have replaced the Docker macvlan driver for the Docker ipvlan driver. IPvlan is a new twist on the tried and true network virtualization technique. The Linux implementations are extremely lightweight because rather than using the traditional Linux bridge for isolation, they are associated to a Linux Ethernet interface or sub-interface to enforce separation between networks and connectivity to the physical network. The end-user doesn't have to do anything special. At startup legacy networks are automatically removed and replaced by the new network approach. Please test once 6.10 becomes available. Internal testing looks very good so far.1 point
-
Settings - Display Settings, change the Header custom text color to be 0000001 point
-
That argument would be fully understandable for me if the was not written... To my mind: If you couple a plugin that much with a product's license model I would say that it's not just an obvious 3rd party plugin.1 point
-
Amazing I spent ages trying to get this to work and this is what was wrong. Removing ,::0/0 sorted it. thanks for sharing1 point
-
Was attempting to set up Mullvad as well, and ran into the same issue. When i would leave the VPN settings page, and returning, the Active slider would become Inactive every time. After manually removing the ,::0/0 it's up and running.1 point
-
The default of 20GB is enough for all but the most demanding applications so it definitely sounds as if you have at least one container incorrectly configured so it is writing internally to the docker image rather that to storage external to the image. Common mistakes are: Leaving off the leading / on the container side of a path mapping so it is relative rather than abrolute Case mismatch on either side of a path mapping as Linux pathnames are case-significant. If you cannot spot the error then what I would suggest is: Make sure all containers are stopped and not set to auto-start Stop docker service delete current docker image and set a more reasonable size (e.g. 20G) Start docker service Use Apps >>> Previous apps to re-install your containers Go to docker tab and click the Container size button This will give you a starting point for the space each container is using. Enable one container, let it run for a short while and then press the Container size button again to see if that particular container is consuming space when it runs. Repeat the above until you track down the rogue container(s)1 point
-
Can you add something about the cache drive missing in 6.4 because of a previous UD format incompatibility and a link to the solution?1 point
-
Both pastebins show the same error - I suspect the connection abort is what caused all the connection errors that followed ("Transport endpoint is not connected"). It however did much worse than abort the connection, it apparently caused system corruption that showed up shortly as a 'general protection fault' with important modules 'tainted' (at which point I wouldn't trust anything the system reported, must reboot). So in both cases, the rsync command is trying to do something with extended attributes on the nathan share. I would start by doing the file system check on those drives containing nathan, including the Cache drive. I have a hazy memory of rare issues in rare circumstances with extended attributes in the Reiser file system, issues that disappeared when they converted to XFS. But my memory is not very good.1 point
-
I think its happening each time mover starts. So i disabled mover for tonight and will see if it dies.1 point