Leaderboard



Popular Content
Showing content with the highest reputation on 07/01/21 in all areas
-
Please post the diagnostics: Tools -> Diagnostics2 points
-
Love the dashboard but it would be nice if we could hide specific Docker apps and VMs. Don't really need quick access to every app1 point
-
@SpencerJ?1 point
-
Install the Unassigned Devices plugin. This will see devices attached to the server that are not in the array as and unassigned device, NTFS is supported by Unassigned Devices. See the above linked thread for a description of Unassigned Devices and its uses. I have two external USB NTFS drives that I attach to the server from time to time to make backups. You could also just put them in the server as SATA drives not assigned to the array and they will be seen as Unassigned Devices. Dev 1 in my screenshot below is a 1TB SSD that I am using as an unassigned device.
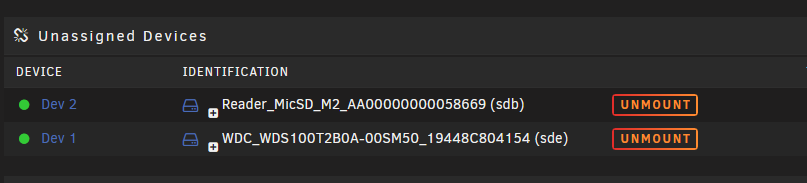 1 point
1 point -
In UNRAID, go to the "Tools" menu, then select "New Config". That should wipe out all previous disk assignments and allow you to reassign drives. It should also tell the OS that these are not UNRAID prepared disks, so it should do a clear on them. Of course, you can also do a preclear on the disks to ensure they get wiped, but when you start the system after doing a "New Config", that should do the trick.1 point
-
Click on first cache disk to get to this setting.1 point
-
Mover is by schedule, default daily in the middle of the night. There is a plugin to run mover according to other criteria.1 point
-
Looks like you have corrupted cache by overfilling Jul 1 08:51:27 Tower kernel: BTRFS warning (device sdb1): csum failed root 5 ino 264 off 1637920768 csum 0xc05895db expected csum 0xd8ca49a2 mirror 1 Jul 1 08:51:27 Tower kernel: BTRFS error (device sdb1): bdev /dev/sdb1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Jul 1 08:51:27 Tower kernel: BTRFS warning (device sdb1): csum failed root 5 ino 264 off 1637920768 csum 0xc05895db expected csum 0xd8ca49a2 mirror 2 Jul 1 08:51:27 Tower kernel: BTRFS error (device sdb1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Jul 1 08:51:27 Tower kernel: BTRFS warning (device sdb1): csum failed root 5 ino 264 off 1637920768 csum 0xc05895db expected csum 0xd8ca49a2 mirror 1 Jul 1 08:51:27 Tower kernel: BTRFS error (device sdb1): bdev /dev/sdb1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Jul 1 08:51:27 Tower shfs: copy_file: /mnt/cache/Arkiv/Backup4/En måned i naturen/1 mnd i naturen/dag 1/569_0902_01.mxf /mnt/disk1/Arkiv/Backup4/En måned i naturen/1 mnd i naturen/dag 1/569_0902_01.mxf (5) Input/output error and so on1 point
-
That will happen if the minimum free space for the share is not set to more than the largest file you copy to that share, usually recommendation is to set to twice that. That's about right for default writing mode, see turbo write.1 point
-
You need to set Minimum Free for cache1 point
-
What file system is in use for the current cache drive? If it is BTRFS then yes you can add a drive at any time. If it is XFS then you would first need to back it up elsewhere as a multi-drive pool HAS to use a BTRFS file system.1 point
-
Hi, thanks for posting. Sure, they're generally decent drives. But you will probably need to live with them spinning 24x7 😞 Basically, there's conflicting data as to their behavior. I started with excluding them, then started a mini-project of collecting data points from users. Since I did receive a couple of positive data points for these drives, I commented the exclusion out, "for now". My controller is based on the same chip. I use HGST drives. They spin down/up without a hitch. So it could be a combination of the controller/HDDs, or just the latter. I tend to believe it's the latter (the HDDs), but the jury's still out. At any rate, these drives have given much more thumbs-down data points than thumbs up. As I said I started collecting this data. Whatever seemed conclusive is in the exclusions file. Perhaps compiling it to a list of "what works" may indeed be a good idea, time permitting. Not as far as I'm aware, but that's up to Limetech to answer authoritatively.1 point
-
Did a quick test without the plugin installed, if a rebuild is running at the time scheduled for a parity check it will attempt to start one but since the rebuild is already running nothing happens, on the other hand if the rebuild is paused, I did it manually but it would be the same if paused by the plugin, then it re-starts the current rebuild from the beginning, so it's an Unraid bug, it's a minor one and one that won't affect many users but it might still be worth reporting.1 point
-
I just ran a test to try to see when it was called and it looks like it will work perfect! I just ran a simple loop to print the date into the syslog and it started basically first thing when I clicked shutdown in the GUI and it waited until it was finished to continue the shutdown procedure! Exactly what I was looking for! Found I can runthis command to shutdown all the docker containers before doing the final rsync so they can close the files properly. docker stop $(docker ps -q) The more I look at this, the more I think it could be turned into a plugin pretty easily from someone that knows how the plugin system works. The commands are very simple and the risks minimal for most use cases (you loose an hours worth of data from sonarr/plex, big deal). Create ramdisk of user selected size (it could calculate the size of the appdata folders to let the user know the minimum size as well) select docker containers / appdata folders to move to ramdisk Rsync them to the ramdisk update docker files for said containers to point to ramdisk. Rsync the ramdisk data back to disk at user selected interval rsync and umount ramdisk at shutdown It could also have the ability to disable docker logging on selected containers / add ramdrive to /tmp in them using the above commands I posted as well. A 1 stop shop to prevent excessive writing since this issues does not appear to be going away.1 point
-
That IS a PCT bug but as you say cosmetic. Still it will get fixed Happy to have any reports on PCT issues as that is the way issues get identified and fixed. What I am trying to avoid is simple dismissing of a problem report if the PCT plugin is installed when the actual issue is probably something else.1 point
-
Sounds like a potential bug if the parity check is started while a rebuild is in progress The Parity Check Tuning Plugin does nothing that you could not simulate manually by using the Pause/Resume buttons on the Main tab at appropriate times so as such it should not be the plugin that causes this issue although the plugin might make it more likely by extending the time for the rebuild to complete. I can see the plugin getting a little confused if a rebuild suddenly changes to a parity check mid-flight but I think it should handle this but i need to check this is correct. I will have to see if I can recreate this exact sequence of events and if necessary raise an appropriate bug report to get clarity on what is expected behaviour. You do not normally get an entry added to the Parity History for a rebuild (or clear). If it is thought it would be of use I could enhance the Parity Check Tuning plugin to add such entries.1 point
-
It really depends on how you use the vm. Most of users, including me, are using one or more vm just as if they use a traditional pc: if this is the case, we want performance on our vm, so we start to passthrough hardware, cpu, gpu, sata controllers. nvme drives, usb controllers, ethernet cards, etc. Why we do this? In my case I'm using a mac os vm with most hardware passed through, I decided to go with a vm because it's faster to set up the environment and you have less headache, moreover I have a complete separated environment, so the bootloader cannot mess with windows 10 installed on another drive, which I boot bare metal. Others prefer performance vms because they can have "more computers" into the same pc, for example different vms for different operating systems, different vms for different fields (school, work, media, firewall, gaming, etc.). Virtual machines can boot uefi with ovmf, so the malware will act the same if it finds a vulnerability in the firmware: but in this case the firmware is a file (OVMF_CODE and its OVMF_VARS), so if it gets infected all you need to do is delete the files and replace instead of flashing the bios chip. But if a malware infects the os in the cases I described above it's near the same as having a malware on a bare metal installation. Another case is if you use vms in a different way, consider for example online services for antivirus scan, all the malwares run on virtual machines which are created and deleted before and as soon as the scan finishes: the base os can be in a vdisk and all you have to do to start fresh is delete and replace the vdisk (some seconds?). Or if you need only few apps in your vm, installed in vdisk: again backup a copy of the base vdisk and of the firmware and if you get infected just start fresh in few minutes. What microsoft is choosing, i.e. add secure boot and tpm as mandatory (in addition to a series of other things), doesn't agree with me (but this is a personal opinion, I am the owner of my pc and I want to do all that I want, without having limits).1 point
-
This forum is about Unraid OS, not Windows, I didn't notice before you were talking about Windows, not the right forum to be posting about that, though someone might still be able to help you're more likely to get help if you post in a more appropriate forum.1 point
-
That script is not needed for that controller, it has however known issues with Unraid and is not recommended, but if the drives are not being detected this works for some: https://forums.unraid.net/bug-reports/stable-releases/disks-missing-after-upgrading-to-670-r536/?do=findComment&comment=45831 point
-
Nur ist "mit Umwegen" noch keine konkrete Erklärung. Ergo: Nichts. Aber alles gut. Der Vorschlag kam dann ja im 2. Anlauf. *Seufz* Ach, man benutzt doch schon für alles mögliche (Dritt)Anbieter. Genau genommen haben wir uns mit dem Kauf und der Nutzung von Unraid bereits in eine Abhängigkeit begeben. Aber das führt ab hier zu einer bodenlosen und pseudo-philosophisch/religiösen Endlosdiskussion. Wenn Du mal in Hamburg bist, lade ich Dich gerne auf ein Getränk ein und wir reden darüber Face to Face. 😉1 point
-
Ich habe gerade mal die Verbindung aktiviert und dann mein Android Smartphone neu gestartet. Es wurde keine neue Verbindung aufgebaut. Danach habe ich in den Android Einstellungen beim Zerotier VPN die Option "Durchgehend aktives VPN" ausgewählt und wieder neu gestartet. Diesmal wurde die VPN Verbindung automatisch wiederhergestellt. Sollte also das sein was du erreichen möchtest. Sollte das Smartphone die Verbindung im Hintergrund kicken, könnte es evtl helfen die Zerotier App zu locken. Dazu die letzten Apps öffnen und lange auf Zerotier gedrückt halten und das Schloss-Symbol anklicken: Ich lasse jetzt mal die Verbindung offen und schaue mal ob das bei mir notwendig ist. Mein Xiaomi killt nämlich normalerweise alles was im Hintergrund länger aktiv ist.

 1 point
1 point -
Zerotier ist ein SDN. Es bietet Dir ein Transfer-Netz in der Cloud (über zerotier-central), über das alle clients, die Teil Deines/Deiner Netzwerke sind kommunizieren können (wie in einer LAN-zu-LAN Kopplung). Es braucht an den Endpoints eben nur noch Clients, keine Portfreigaben im Router mehr nötig. Aus Sicht des Clients funktioniert es wie ein VPN, nur verbindet der nicht nach Hause, sondern zum zt-Service und Deinem/Deinen zt-Netzwerk(en).1 point
-
thank you.... also for improving my french1 point
-
Skipped over this portion of the reply this morning. I would say I'm doing Chia the way the developers said to, I am utilizing spare resources I have laying around the office. With that, installing a small/not obtrusive harvester exe seems harmless and low key. But installing docker service on each server starts to get a little more intrusive on office utilized equipment. Several of my harvesters are also 2012r2 servers which I believe by default do not support Dockers. I do have a couple backup only 2016 servers maybe I will see if I can expand an instance or two to those.1 point
-
I restarted using unraid-api restart since I shut it down remotely and it seems to be working just fine. Thanks for the quick fix again.1 point
-
Unraid 入门指南 Blog1 point
-
The purpose of a Parity Check to assure that the hard drives that are being used in the array are not having any issues. If a problem is detected, you want to find it when it is still a single point of failure! Those are fixable. If you extend the interval, you are more likely to find two points of failure and, while some are fixable, many more of those will result some data loss. If one looks at it from a statistical standpoint, if you make the interval too long, you might as well not never do a Parity Check! Remember if you suddenly get a read error when retrieving data from your array, you already have two points of failure! At that point, you are beyond a simple repair procedure to recover your data.1 point
-
Update the docker container. Go to docker tab, check for updates and then apply the update. Restarting the docker only updates Zoneminder, not the docker container.1 point
-
I found the problem 🙂 blackplane issue that caused disk to drop. you put me on the right track ! thanks1 point
-
You have to wait for the docker to be updated.1 point
-
Bevor man das Feld beschreibt, sind entsprechende Beispiele (in blau) aufgeführt:
 1 point
1 point -
Versuche es mal mit 15G statt 15....1 point
-
Sorry to revive an old thread. New to unraid and recently built a machine with a 5700g, not realizing that there isn't much useful info that will display on the monitor connected to the actual unraid machines attached monitor. Been searching for some kind of status plugin or something that will display useful info on the machines monitor. This old post is sort of what I'm looking for. But it hasn't been updated in a while. Is there something like this that is current, or can someone suggest search terms to help me find something that will display stats or statuses of some sort on the monitor connected to the actual unraid box?1 point
-
For Unraid version 6.10 I have replaced the Docker macvlan driver for the Docker ipvlan driver. IPvlan is a new twist on the tried and true network virtualization technique. The Linux implementations are extremely lightweight because rather than using the traditional Linux bridge for isolation, they are associated to a Linux Ethernet interface or sub-interface to enforce separation between networks and connectivity to the physical network. The end-user doesn't have to do anything special. At startup legacy networks are automatically removed and replaced by the new network approach. Please test once 6.10 becomes available. Internal testing looks very good so far.1 point
-
Same problem , every Hour Smart Spin Up, it was the Mover Config. I changed from every Hour to Daily and the Smart Spin Up stopps.1 point
-
Odds on either sab or deluge (or possibly sync) is winding up downloading into the docker image (and things like that don't really show up under the virtual size) Check your path mappings on the template for those apps AND the settings within the apps for where they are downloading to. And expanding is simple. Settings - docker - disable docker. Advanced view. Increase the size and reenable docker. Apply Off the top of my head, when properly configured your installed apps would utilize maybe 10Gig.1 point
-
Just an idea. Lol You know me if I can make more work for you and less for me its a for sure request.1 point
-
what im trying to achieve.. let's say i have a tv show. the structure looks like this tvseries - show -- season 01 --- show.s01e01.avi --- show.s01e02.avi .. --- show.s01e24.avi all of those episodes right now are spread out on multiple disks. the problem with this is that if i enable the disk spin down option, all of the drives these files reside on need to be spun up again. what i'm trying to achieve is spinning up the smallest amount of disks as possible. if i can just ssh to the array and move the data on the command line then i'll do that.1 point





















