Leaderboard



Popular Content
Showing content with the highest reputation on 07/06/21 in all areas
-
No you do not need a port number. The important part is http or https. I assume you are getting some data from the UnraidAPI? Does the array status panel show Started? Yesterday when i checked the Dynamic Image Panel plugin in Grafana, it said it wasn't loaded because it was unsigned. Check the plugin tab of Grafana for the status of your plugins. IF it was not loaded by Grafana, you will need you add a ini file. I created a conf folder in the Grafana app folder. Next create a file called custom.ini. In the custom.ini file add the following: [plugins] allow_loading_unsigned_plugins = "dalvany-image-panel" Save it. You will need to restart Grafana for it to be loaded After doing the above, i did not need to open the icons in another tab or log into the server again.1 point
-
Good to see that you managed to sign in again.1 point
-
@Chris Mot Ended up having to manually add https:// before the ip. I actually had the port forwarding correct but had to ssh in and delete the ssl certs and reprovision to get [hash].unraid.net working again.1 point
-
Disk look mostly OK, still not a bad idea to run an extended SMART test before using it again, if it passes and only if the emulated disk is mounting correctly you should replace/swap cables to rule that out then can rebuild on top: https://wiki.unraid.net/Manual/Storage_Management#Rebuilding_a_drive_onto_itself1 point
-
So I ran Memtest and checked for other hardware issues. Then I ran the XFS_Reapir, I wound up having to run it with the -L switch to clear the logs as the disks were unmountable. This appears to have worked. Chatting with The Wiz, we came to the conclusion that the system got too hot as this occured during a parity check. The door was closed to the room it is in and it just got too hot and the controller probably went offline briefly. This in turn offlined several disks at once and the resulting havoc ensued. Thanks for the assistance.1 point
-
Yep Sent from my Mi 10 Pro using Tapatalk1 point
-
Tried again today with 6.4.10.2 also, but still broken Sent from my Mi 10 Pro using Tapatalk1 point
-
I don't dispute that, in fact like mentioned I've gotten similar results in the past, but it's not always possible, curiously user shares are currently still faster for me when using SMB than when doing an internal server transfer: This is my other main server, better but still not great: My point was that this has been a known issue for many years now, that affects some users particularly bad, here's just one example, and if this could be improved it would be much better than a setting that will only help SMB, also last time I checked Samba SMB multichannel was still considered experimental, though it should be mostly OK by now, but of course if it's currently not possible to fix the base user share performance than any other improvements are welcome, even if they don't help every type of transfer.
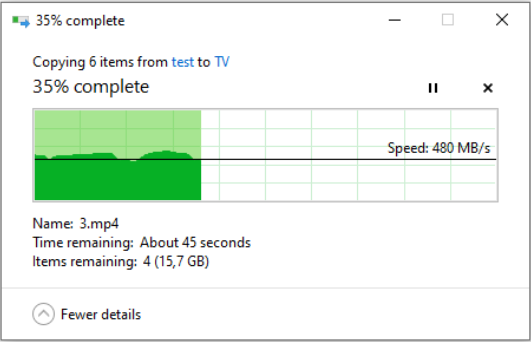
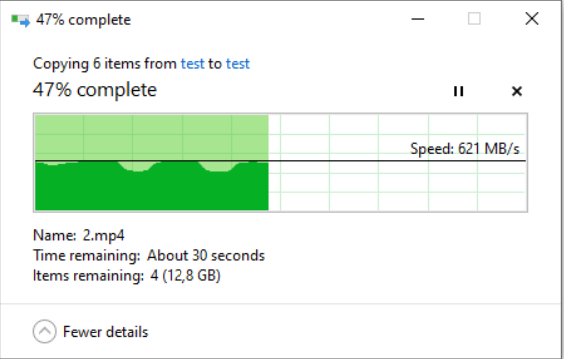 1 point
1 point -
I´ve sorted that issue out. It was a faulty cache drive. This can now be closed. Thanks !1 point
-
Unfortunately I don't know any one to test the theory so I am going to go with it at chance, and keep this post open until it arrives and I will update the post for anyone else searching in the future (fingers crossed with good news!) 😀1 point
-
I would check (if you can), that you won't have issues and unexpected "surprises" with the passthrough of the thunderbolt controller to the vm, because you will passthrough that controller to the vm, without passing through directly the GTX: when you passthrough a controller everything that it's connected to it will be seen only by the vm to which the controller is passed through.1 point
-
Thank you - I see what I've done! Yes instead of VNC, I need to select Intel UHD Graphics 630. However I cant do that as UNRAID uses it at the moment. So I have to accept no hw transcoding. Seems like I need to get that egpu thunderbolt enclosure pretty swift for my GTX1660S Thank you for your help ghost82
 1 point
1 point -
Hi, what I understood is that you want hardware transcoding inside a vm. To do this you need obviously the hardware inside the vm to be able to transcode. Your cpu has a igpu, which should be able to do so, however when you passthrough your cpu (host passthrough) you are not passing through the igpu. As far as the "graphic card" in the gui of the settings of the vm you selected "VNC", i.e. you connect to the vm through vnc (with the qxl driver); qxl video, which is an emulated card, is not able to perform any hardware transcoding. You need to passthrough to the vm a dedicated pcie gpu (easy), with hardware transcoding capabilities, or the igpu (in some cases a lot less easy )1 point
-
Plex Intro Detection processing causing very high memory usage and OOM This post is more a headsup for others who might be running into similar issues. The actual problem is inside Plex (Intro Detection processing) and should be fixed there. About a week ago my server started having memory related issues. Plex was being killed by the OOM reaper due to excessive memory usage. I haven't set any memory limits for Plex so the OOM was protecting the whole server from running out of memory. I have 32GB of mem and normal utilisation is ~60%. When analysing the issue through Grafana statistics (TIG stack) I realised the issue had started already on 10.8.2020 and had been slowly creeping up until a week ago it passed the final limit causing the OOM. It also became evident that the problem occurred daily at the time when Plex scheduled maintenance tasks were running. I quite quickly found this thread on Plex forums: https://forums.plex.tv/t/server-maintenance-leads-to-excessive-resource-utilization/611012/18 The root cause in that case was the intro detection processing stumbling on some badly encoded media. So I yesterday temporarily disabled intro detection (and only that) and the problem went completely away as can be seen from the docker memory utilisation graph below (last day missing the mem spikes). And yes, I have a weekly backup/update routine running which also restarts all dockers hence the drop on 3.7. So most likely I have added some bad media on 10.8.2020 since the intro detection feature was released way before that. The referenced thread also included ffmpeg scripts for detecting bad media. I think I will have to go that route too. Unfortunately the Plex logs do not tell anything about problematic files. I will in case up the server memory 32 -> 64GB just to see if it makes a difference. But that is just a band aid. Plex should definitely not be using >15GB of memory.
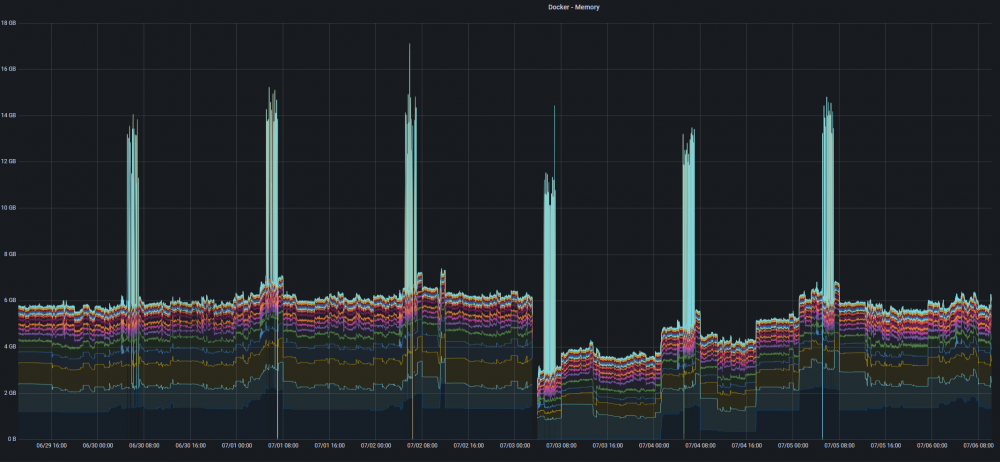 1 point
1 point -
Hi @shiftylilbastrd, Default are: HTTP port: 80 HTTPS port: 443 Try https://ipaddress:443 as suggested on https://wiki.unraid.net/My_Servers#How_to_access_your_server_when_DNS_is_down Good luck.1 point
-
Next time please post the complete diagnostics instead, disk dropped offline and reconnect with a different letter, post output of: smartctl -x /dev/sdi1 point
-
My problem with this was fixed by editing the following. Assuming you have the Dynamic Image Panel plugin installed and unblocked. Check the base url in the Dockers (Running) panel. (see attached) The http or https needs to match the setup for the API docker container. If it says http, change it to https and see if that works. If it does, you will need to change it in each panel, Dockers and VMs.
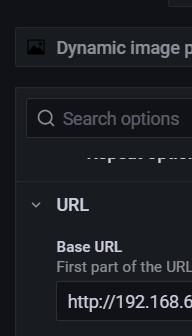 1 point
1 point -
Ah right I see. Yeah you connect to Owncast from OBS via the unRaid IP. You may have to adjust the hardware resources or the stream settings in Owncast itself if you're experiencing buffering the Owncast stream page. My Owncast is set for 3000Kbps but you'll have to tailor yours for your hardware/bandwidth. There's also a buffer/delay setting to be mindful of, too low and your end users might have issues. With regard to OBS. I have the stream set to use the x264 CPU encoder, CBR, 3000Kbps, fast CPU usage. I tried NVENC but the result was a pixelated stream on the Owncast side. Remember Owncast does a transcode of it's own. My setup is OBS on a Win 10 VM hosted on unRaid streaming to Owncast docker on the same machine. I have four cores (8 threads) assigned to both the docker and the VM. I also tested tested it from various bare metal machines ony CAT6 network with no issues either. I wouldn't recommend trying this on WiFi though. Feel free to ask any more questions if needed.1 point
-
I am on 6.9.2 and can passthrough gpu(s). Asus rogstrix 470 MB, Ryzen 3900x.1 point
-
All of a sudden this container won't load. When trying to bring up the WebGUI all I get is "Cannot Connect". There are no errors in the logs and I haven't even logged into the GUI in months because everything worked. Tried reinstalling it, changing branches, changing to bridge/host/br0, deleted all appdata and copied it back over. What's going on? How do I fix this?1 point
-
Bei der 250GB ist das ein Problem: https://www.computerbase.de/2014-12/samsung-850-evo-test-250-500-1000-gb/#abschnitt_transferraten_und_haltbarkeit Wie du siehst ist das Maximum dann nur noch 300 MB/s. 🤷😅
 1 point
1 point -
The Unraid power users that care already back up the things that they feel the need to. All the info is either easily searchable, or available for the asking if you are motivated enough to ask. I get that you want Limetech as a company to step in, but @jonp already made their current position clear when you originally asked in this thread. VM's are tricky if you insist on backups while they are running, but cold backups are simple to handle either with the existing plugin or manually. Personally I backup my VM's exactly like I do any other machine on my network, with a client that runs inside the VM (I use UrBackup that's running as a container on unraid) or your client of choice.1 point
-
Answering my own question in case someone else stumbles upon this, found this excellent community App: and its database here: http://strangejourney.net/hddb/index.cfm?View=Drives&Vendor=Seagate&Model=ST8000DM0041 point
-
@eds in case, take a look at your dns settings in CF, turn off "proxy" feature (orange cloud = on, grey = off, then its just like a dns service ... but like i said, rtmp is a different protocoll and needs some setup (to use the rtmp module) to proxy a rtmp stream, which is then not going through the http part and not really using the domain selection, you will figure it. https://obsproject.com/forum/resources/how-to-set-up-your-own-private-rtmp-server-using-nginx.50/ there you see the server block (streaming server part on its own port, not http by domain ...), take a look if you really want to go through it.1 point
-
hi my servers are identically configured and yet one says cant connect to mothership and the other one is online and working great. any specific things I can do to fix this? EDIT: removed plugin, restarted server, installed plugin and logged in. waited 5 minutes and now its working.1 point
-
https://1drv.ms/u/s!AlHg8pmWgJJ_gr9mLid6muLTIMOddA?e=KbfHe21 point
-
Enjoyed the podcast, but IMHO more important than using other things to get around the performance penalty introduced by user shares would be to try and improve that, for example I still need to use disk shares for doing internal transfers if I want good performance, and any SMB improvements won't help with that, e.g., transfer of the same folder contents (16 large files) from one pool to another done with pv, first using disk shares, then using user shares: 46.4GiB 0:00:42 [1.09GiB/s] [==============================================>] 100% 46.4GiB 0:02:45 [ 286MiB/s] [==============================================>] 100% If the base user shares performance could be improved it would also benefit SMB and any other transfers.1 point
-
No joke: I missed this part in the docs: I will update the container and remove the external DB. SQLite is the easier option for the user.1 point
-
Got it to work! Thanks to Ghost82 and glennv. Here are the steps I used, I will try to keep it simple so everyone can try it out. -Install macinabox just as normal (default settings)-- Test to make sure it bootloops for you -Shutdown the macinabox VM -Connect to Unraid terminal -Mount the opencore image file modprobe nbd max_part=8 qemu-nbd --connect=/dev/nbd0 /mnt/user/isos/BigSur-opencore.img mkdir /mnt/user/isos/temp/ mount /dev/nbd0p1 /mnt/user/isos/temp/ -Edit the config.plist nano /mnt/user/isos/temp/EFI/OC/config.plist -Paste the patch after the PENRYN entry - glennv has a post on page 80 that explains it -Save you file -Dismount the image file umount /mnt/user/isos/temp/ rm -r /mnt/user/isos/temp/ qemu-nbd --disconnect /dev/nbd0 rmmod nbd -Rerun the user script - make sure you change the name in the settings of the script to match your VM name (I also set REMOVETOPOLOGY="yes" , not sure if that is needed) -Test it out! Macinabox PENRYN Patch 11_3.txt1 point
-
Settings - Docker, Disable. Then you can delete docker image on that same page and change its size to 20G. Also enable docker log rotation. Enable docker and docker image will be recreated with the new settings. Then go to Apps and use the Previous Apps feature which will reinstall your dockers exactly as they were.1 point


















