Leaderboard


Popular Content
Showing content with the highest reputation on 07/28/21 in all areas
-
When installing or editing a container, if there are any conflicts (or if another error happens which prevents starting), it will appear in the docker run command which is listed. If just starting an already installed container and due to a conflict / error it won't start you'll see "Server Execution Error", at which point you can easily see that actual issue by editing, make a change, undo the change and then hit apply As an aside, 6.10 when changing any of the ports in the UI does a check to see if the port is already in use and won't let you apply the changes.
 3 points
3 points -
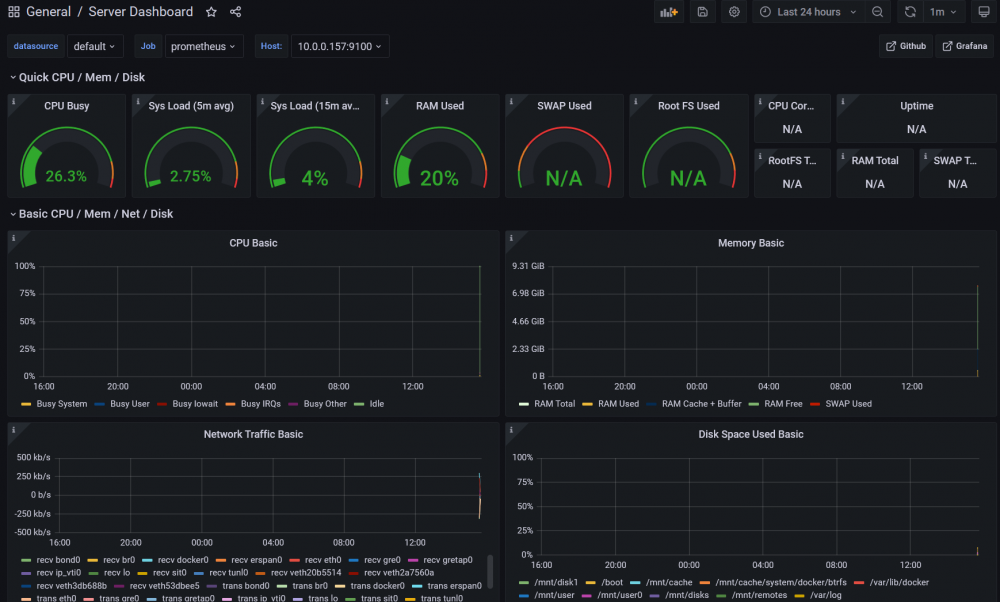
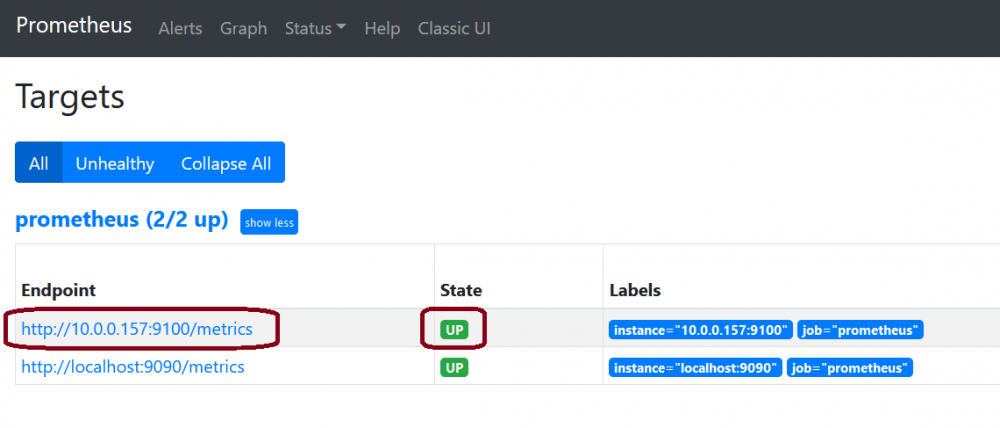
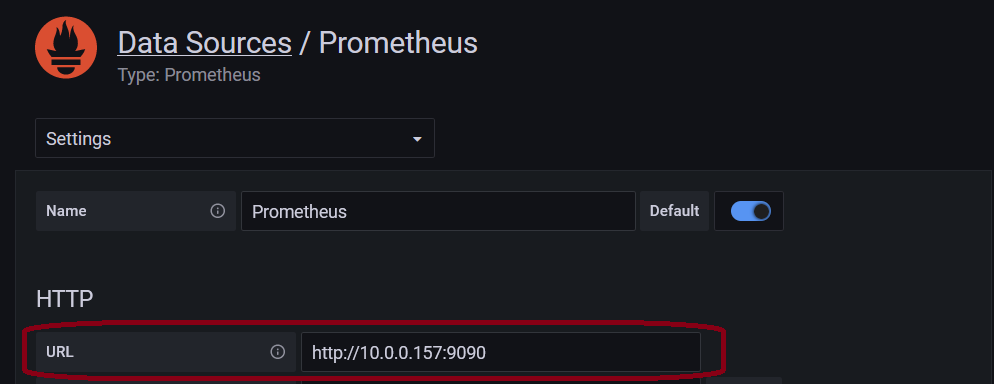
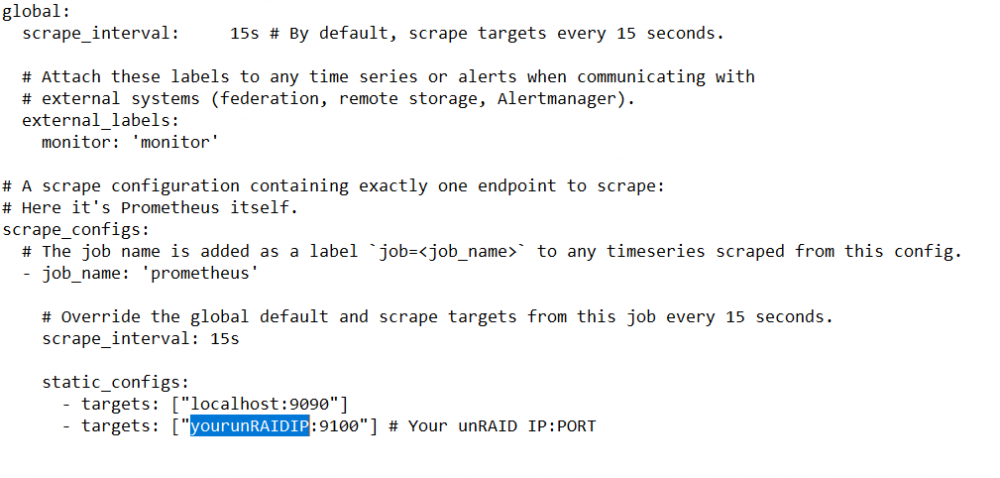
Prometheus unRAID Exporter Plugins This is the support thread for the Prometheus unRAID Exporter plugins. If you got a request for a Prometheus Exporter plugin feel free to ask here in the thread. Following plugins for Prometheus Exporters are available (click on the name to go to the tutorial post): Node Exporter (this post) Data from your unRAID Server nvidia-smi Exporter Data from your Nvidia card(s) passed through to Docker PiHole Exporter Data from your PiHole, whether from Docker or your local network MSI Afterburner Exporter Data from your local PC/VM Wireguard Exporter Data from unRAID Wireguard AdGuard Exporter Data from your AdGuard, whether from Docker or your local network Fritzbox Exporter Data from your Fritzbox Tutorial Grafana, Prometheus & Node Exporter base configuration to get the basic readings from unRAID: Go to the CA App and download the Grafana Docker container: Download the Prometheus Docker container from the CA App (please note that it will be stopped after the installation, that's just fine and will be fixed in the next steps): Download and install the Prometheus Node Exporter plugin from the CA App: Download the 'prometheus.yml' and place it in your '.../appdata/prometheus/etc' directory on your unRAID server: prometheus.yml Open the prometheus.yml and edit the part 'YOURUNRAIDSERVERIP' so that it matches your server IP, save and close the file: Go to your Docker page and start the Prometheus Docker container: After it is started click the Prometheus container again and select WebUI: On the top click on "Status -> Targets": You should see now a list with two entries, the entry "YOURSERVERIP:9100" should display "UP" like in the following screenshot: Go to the Docker page and start the Grafana WebUI: Login with your Username and Password (default: admin | admin): If you left it at default you should change the password in the next screen to something secure or press "Skip": Next we are going to configure the Prometheus datasource in Grafana, click on the "Gear Icon -> Data sources": Click on "Add data source": At Prometheus click on "Select": In the next screen enter the IP and Port from your Prometheus container like this: (You can check the IP:PORT on your Docker page): At the bottom click on "Save & Test": You should see this message: In Grafana click on "+ -> Import": Now we are going to import a preconfigured Dashboard for the Node Exporter from Grafana.com (Source), to do this simply enter the ID from the Dasboard and click "Load": In the next screen be sure to select "Prometheus" as the data source and rename the Dashboard to your liking: Click on "Import": Now you should be greeted with something like this (please keep in mind that the Dashboard can display N/A at some values since there is not enough data available, wait a few minutes and you will see that the values are filled in): (Please also keep in mind that some values will not be filled at all because unRAID by default don't have a SWAP)






 1 point
1 point -
Not sure where to post this but man this unRaid stuff just WORKS, rock solid. Almost a year now with two installs and they're both absolutely ROCK SOLID. Love the simplicity and stability of this setup. I would say money well spent. Keep up the good work gents.1 point
-
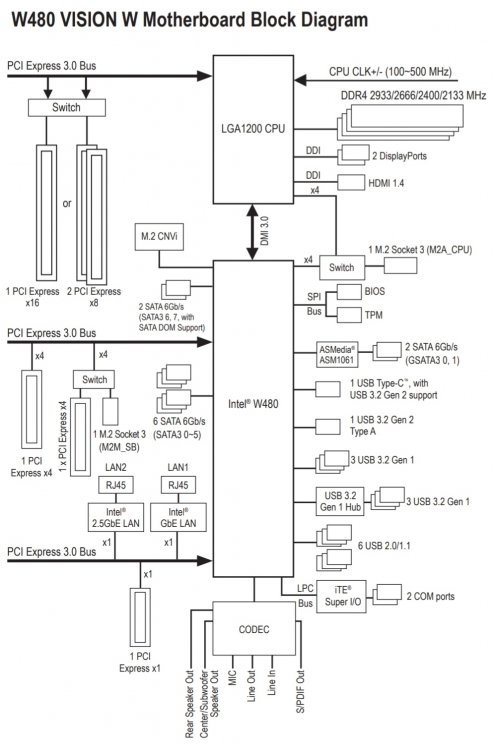
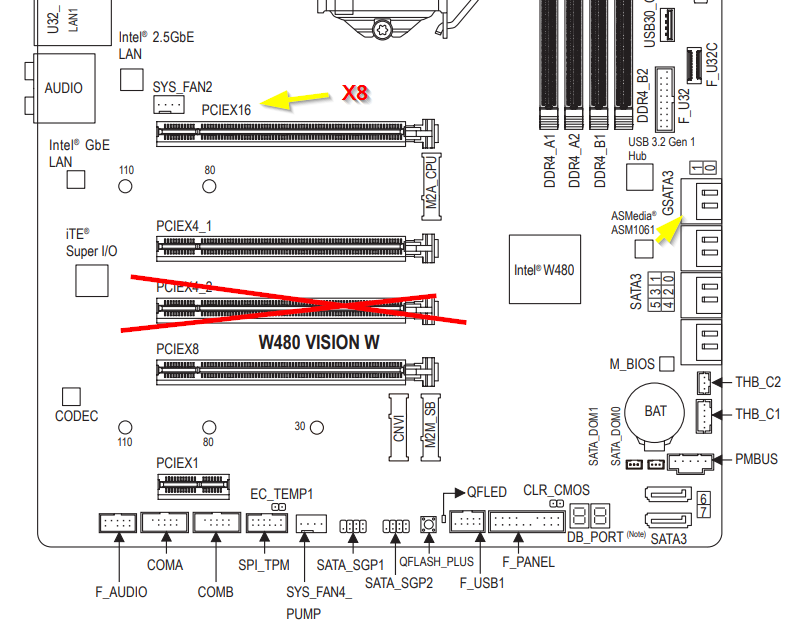
Wie gesagt X8 und X8 gehen über die CPU und der dritte X4 über den Chipsatz. Chipsatz ist immer ein Flaschenhals durch DMI, aber wenn nicht alles parallel voll ausgelastet wird (also X4 Karte, M.2 SSDs und SATA Buchsen), sollte das gehen. Ich würde also da keinen Expander reinstecken. Eher die 10G Karte. DMI 3.0 hat 4 GB/s. Würde man also ein SSD RAID machen, über 10G hochladen und parallel läuft ein Parity Check, dann würde es vermutlich spürbar drosseln. hier das Diagramm:
 1 point
1 point -
Prozesse können bis zu 15% schneller sein. Ich bezweifle aber, dass man das bei unRAID oder Docker merkt. Daher empfehle ich auch immer einzelne 32GB Module. Nachkaufen kann man ja immer noch1 point
-
Awesome. I was going to buy a new motherboard but found an 8 port card with the LSI chip. Thanks.1 point
-
Problem solved, I am a noob and blind. Thanks for making it clear1 point
-
Docker image is corrupt, delete and re-create, VM service is disable in the diags posted, enable and post new diags if there are still problems.1 point
-
You need at least one data device assigned in the array.1 point
-
I think switching from NFS to SMB fixed the problem. Don't know why though.1 point
-
I think something is very wrong here, seems like the Prometheus Docker can't connect to the Afterburner exporter that runs on your Server. From what I see in the screenshot you experience a http 500 error from the exporter itself, but I really can't tell why. Really can't help here... I'm out of ideas...1 point
-
I made this post last week and since I can't access the server at all without rebooting, the logs I had weren't helpful. So I followed the recommendation and turned on syslog mirror, which I've attached to this post. I had to prune them because they were too large. Let me know if I need to add anything else back in. As you can tell via the logs I had to power cycle the system at roughly 15:41 on July 26th. Right before then I was unable to access unraid either via remote login, pinging, or with a monitor hooked up directly to the machine. Problem though is that there's no errors logged immediately prior to that so not sure if this is going to give us any info to help diagnose it. I had a recycle bin plugin which I've disabled just in case that was causing the issue. Here's all my details: Version: 6.9.2 I'm running the following: msi z490-a pro Intel 10850k Supermicro AOC-S3008L-L8E 12Gb/s 8-Port HBA IT-Mode Controller SAS IO Crest SATA III 4 Port PCI-e 2.0 x 2 Controller Card with Low Profile Bracket (SI-PEX40062) Cooler Master V700 - 700W Power Supply with Fully Modular Cables and 80 PLUS Gold Certification Team T-FORCE VULCAN Z 64GB (2 x 32GB) 288-Pin DDR4 SDRAM DDR4 3200 (PC4 25600) Intel XMP 2.0 Desktop Memory Model TLZGD464G3200HC16CDC01 CPU is running base clock, Memory has XMP profile enabled. At the time it crashed I had the following dockers running: binhex-nzbget prowlarr binhex-qbittorrent binhex-radarr binhex-sonarr machinaris Additionally I had a windows 10 VM running. At the time of crash, no parity check was running. I have the fix common problems plugin installed and it had no items although I'm running an extended test now to see if anything pops up. Any recommendations on how to diagnose? Thanks in advance. syslog-192.168.50.109 pruned.log1 point
-
You should definitely try turning off XMP until you have your server in a stable state. The problem with any over-clocking is that it is impossible to predict with any certainty when it might cause a failure regardless of tests you do in advance. it seems that servers are more prone to this sort of issue than desktops, but I suspect it is just more noticeable as they tend to be left running 24x7.1 point
-
Reiserfsck checks can take a long time (many hours) particularity with large disks, with the only sign of activity being fact that the disk is still being read.1 point
-
I hate silence from tech companies. At least give some BS canned answer like "we are looking into the issue". When you email support they say go to the forums and check.......... 🙄1 point
-
Eventuell das? https://www.gigabyte.com/de/Motherboard/W480-VISION-W-rev-10#kf ca 200 € Das Board hat x8, x8 und x4 (bei voller Belegung), 8x + 2x SATA und 2x M.2. Andere Boards mit dem Chipsatz sind teurer: https://geizhals.de/?cat=mbxeon&xf=1244_8~317_W480 Zum W-1290P gibt es auch günstigere Optionen: https://www.cpubenchmark.net/compare/[Dual-CPU]-Intel-Xeon-E5-2630L-v3-vs-Intel-Xeon-W-1270P-vs-Intel-Xeon-W-1250P-vs-Intel-Xeon-W-1250/2818.2vs3839vs4362vs3827 Da du eh keine VMs einplanst, sollte dir denke ich ein W-1250 ausreichen: https://geizhals.de/intel-xeon-w-1250-bx80701w1250-a2486799.html Wobei, bitte nicht falsch verstehen. Mit dem kann man natürlich auch problemlos mehrere VMs betreiben. Die Frage ist nur wie viel Last die verursachen. Den W-1250 bekäme ich evtl für 300 € (Ende August). Müsste ich aber erst mal im Großhandel anfragen. RAM ist "egal". Hauptsache passt und ist das Maximum was die CPU kann. Also beim W-1250 entsprechend 2666 Mhz. Oder man hält sich offen, dass man irgendwann auf den W-1270P/W-1290P aufrüstet. Dann würde ich gleich 2933 Mhz nehmen. Langsamer laufen die immer.
 1 point
1 point -
Let's just take it one disk at a time with the filesystem checks and see what each looks like in turn. Could be original disk1 is actually in the best condition, but whether or not it could be used to retry a rebuild of disk2 is unclear. Probably too many other things have happened to parity since then.1 point
-
Which was already pretty full1 point
-
You should disable docker service in Settings until you get your system stable again.1 point
-
Nur auf Plex bezogen nein. Das liegt auch daran, weil ja ein Teil der Datenbank immer auch im RAM liegt. Aber sobald du mehrere Container und vielleicht sogar eine VM hast, wird die NVMe deutlich mehr Durchsatz bieten, da SATA ja nur einen Weg kennt (hin oder zurück), während NVMe auf 8 Kanälen gleichzeitig Daten transferieren kann (4 Lanes).1 point
-
Du musst beides separat betrachten. Kein Mechanismus wird universell funktionieren. Bin gerade im Urlaub, deshalb nur kurz: Plex macht schon die ganze Arbeit mit seinen Scannern. Die XML Dateien aus der Plex Web API enthalten alle Informationen. Mit dutzenden Skripten hole ich das nachts raus und interpretiere das. Suche nach geänderten Metadaten etc. Nach der Musicbrainz ID habe ich noch nicht gesucht. Ich würde mir Mal die Musicbrainz ID von einem Album von der Musicbrainz Webseite holen und damit den Datenbank Dump von Plex durchsuchen. Vielleicht ist die drin. Lass uns nächste Woche Mal drüber sprechen.1 point
-
Thats exacly the way you go. Remember to run that as post execution with every start of the container. Cheers.1 point
-
Didn't read everything , but the rebuilt disk2 will be mostly corrupt. if you still have the old one don't wipe it, is disk1 the old disk or was also replaced?1 point
-
You can use the same ports on several dockers as long as they do not run at the same time. Preventing this might cause issues for some users.1 point
-
@ich777 i also updated my dll from guru3d due connection issues when i remember correctly @Masterwishx where are you getting these errors now ? plugin settings looks like ? prometheus.yaml looks like ? result in targets section in prometheus looks like ?
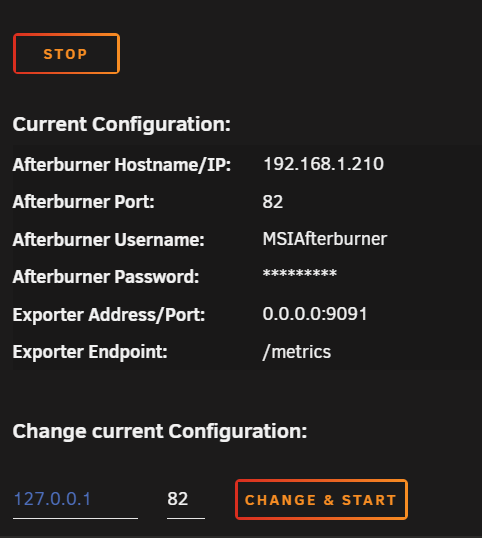
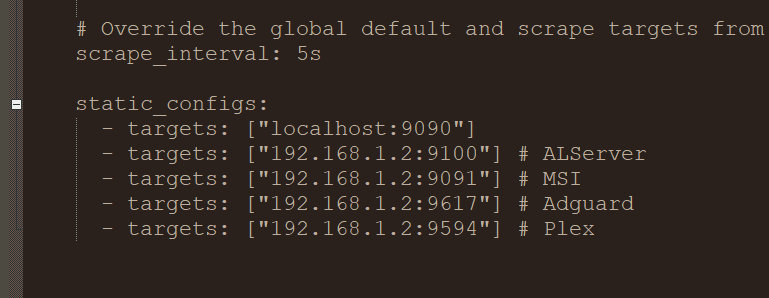
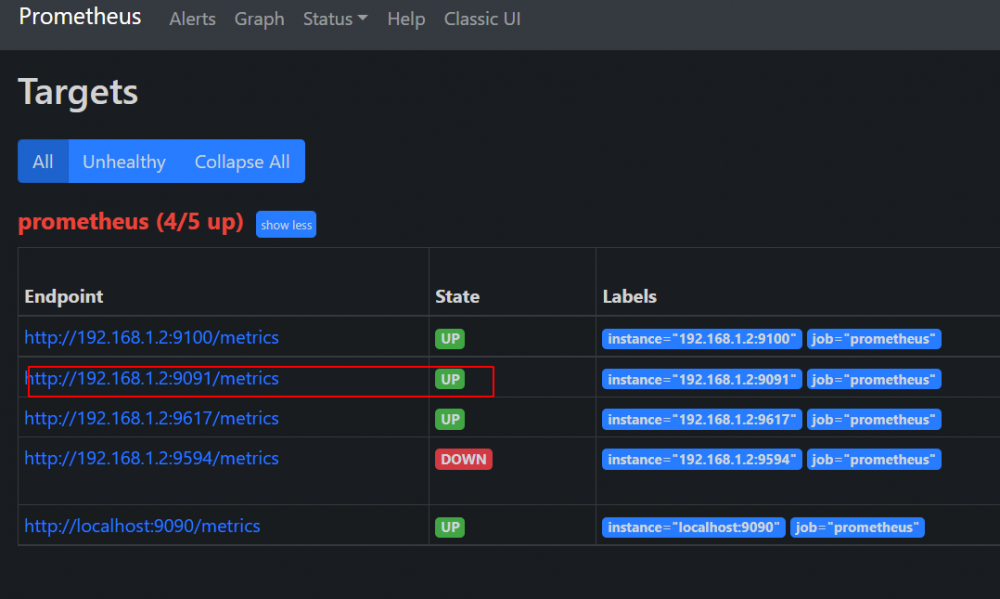 1 point
1 point -
Be sure to capture the output so you can post. Probably my last post for tonight.1 point
-
Looks like you have filesystem corruption on both disk1 and disk2 so they have been mounted read-only: Jul 27 19:06:05 Mongo kernel: REISERFS warning: reiserfs-5090 is_tree_node: node level 57074 does not match to the expected one 2 Jul 27 19:06:05 Mongo kernel: REISERFS error (device md1): vs-5150 search_by_key: invalid format found in block 3192265967. Fsck? Jul 27 19:06:05 Mongo kernel: REISERFS (device md1): Remounting filesystem read-only Jul 27 19:06:05 Mongo kernel: REISERFS error (device md1): vs-13070 reiserfs_read_locked_inode: i/o failure occurred trying to find stat data of [2700 226491 0x0 SD] Jul 27 19:06:07 Mongo kernel: REISERFS error (device md2): vs-4080 _reiserfs_free_block: block 741669133: bit already cleared Jul 27 19:06:07 Mongo kernel: REISERFS (device md2): Remounting filesystem read-only No indication of the connection problems you had earlier that might have caused all this. Disk1, Disk2, and Unassigned (original disk1) SMART all looks good though none have had SMART tests. Check filesystems on disk1 and disk2: https://wiki.unraid.net/Manual/Storage_Management#Running_the_Test_using_the_webGui1 point
-
I don't know what to say... Was it working before? The thread is from 2018... I still can't reproduce this error in my case it is just working, I will update the plugin soon so there will be a timeout if the VM or computer isn't started at the time when starting the plugin. @alturismo do you know eventually what's the problem here, eventually a wrong version from MSI Afterburner Server?1 point
-
It worked after I restarted it a second time. Thank you.1 point
-
Do you know which user shares those files are in? You should be able to see them since all disks are mounted (disk1 is disabled but the emulated disk1 is mounted).1 point
-
The diagnostics you posted 3 hours ago in this post: are 5 and a half hours old and you have rebooted since then. I reviewed the thread and I see those diagnostics are actually older than the diagnostics you posted 4 hours ago here: That is why I was having a problem understanding your current situation.1 point
-
It doesn't agree with those diagnostics. Do you have multiple tabs or browsers working with your server? Post new diagnostics.1 point
-
Worked good, thanks.1 point
-
I ended up figuring it out. With setting xmp memory profiles in BIOS to 3600 Unraid does not like. Setting it to recommended 3200 does the trick. Hopefully this helps someone who runs into the same concern/issue in the future.1 point
-
AH! I was trying to do everything from within the machinaris configuration settings from the webUI! Thank you so very much.1 point
-
Linux Systems Administration. Sysadmins spend a lot of time being intimately familiar with configuration files, packages and their dependencies and resolving conflicts between them. They would be expected to have some familiarity with programming languages (C/C++ generally) as well as being comfortable with a terminal and scripting languages. Modern sysadmins also work with automated deployment systems a lot, things like CHEF/Docker/Kubernetes are going to be premium skills to acquire. This is the field I would like to get into, but never feel confident enough with my skill level to dive right into.1 point
-
Can you post or PM me your .xml from flash drive config/plugins/dockerMan/templates-user/ , should be name something like "my-Handbrake.xml"1 point
-
Same error on my 6.9.2 box after the latest container update. Looks like there is already a GitHub issue targeting a fix in Glances 3.2.3 release: https://github.com/nicolargo/glances/issues/1905. Workaround would be to add a version tag to the container config like this:
 1 point
1 point -
I suspect latest tag works fine, the issue you had is that you had the old broken latest image cached on disk, you need to click on force update when switching back to latest. Sent from my CLT-L09 using Tapatalk1 point
-
Have you got a spare disk that is not assigned to the Array or to a Cache Pool? If not that's the problem.1 point
-
I've been complaining about this for (seems like) months. I understand and respect that LimeTech want to make server access secure for people that might be less than intellectually capable of securing things for themselves (how else am I supposed to say it?). The UnRAID WebUI doesn't work. 6.1 point
-
I finally got around to making some brackets for my 8tbs and the 804 case, here’s some pictures in case anyone else needs it for reference i originally planned to put the brackets inside the drive holder however the fit was too tight so they went on the outside, that’s why I lined them with red felt previously to avoid any marks or heat transfer from the drives on the holder nearest to the rear fans the bolts were too long and clashed with the fan so luckily I only have 4x 8tbs and mounted them in the other holder

 1 point
1 point





















































