Leaderboard




Popular Content
Showing content with the highest reputation on 09/04/21 in all areas
-
Hello, Excuse my pronunciation, english is not my natural language. Shelf is a NetApp DS4243 / IOM6. The controller is a NetApp PMC-Sierra PM8003 SCC 4-Port QSFP PCIe x8. The 6.8.3 Version has the kernel: pm80xx 0000:27:00.0: pm80xx: driver version 0.1.39. The 6.9.0-beta30 last working version. The 6.9.0 rc2 Version stable has the kernel: pm80xx 0000:27:00.0: pm80xx: driver version 0.1.40 The controller didn't find my drives with the new driver. The 6.9.1 same problem. The 6.9.2 same problem. Is there any way to get back the older driver or a patch? Thank's for reading T. PS.: Justification from limetech There were some changes in that driver in kernel 5.10.26 https://cdn.kernel.org/pub/linux/kernel/v5.x/ChangeLog-5.10.26 Unraid 6.9.2 will include those changes. 😀😀😀😀😀😀😀😀😀😀 Good news, there is a patch for us. Big thank's to @Linux und @DrBeaker. You make a great work. Please give booth a like 👍 👍👍👍👍👍👍👍👍👍👍👍 !!!!!!!!! Everything at your own risk !!!!!!!!!! You are responsible yourself !!!!!!!!!!!! The NetApp PMC-Sierra PM8003 SCC 4-Port QSFP PCIe x8 works. Adaptec 6805H HBA Controller can't be confirn, I don't have one. Thank you1 point
-
What files are still on cache ? Did you try to disable VM and Docker services from Settings ? You can also try to enable Mover logging from the Scheduler and run Mover again. You should have more information in the log on why the files are not moving.1 point
-
I have the almost ready to go. Just holding off while other stuff is tested. You could try them out by adding my Dev plugin repo. https://raw.githubusercontent.com/Josh5/unmanic-plugins/repo/repo.json1 point
-
Just use a cron job to run whenever you want on the user script page set to custom Example every 6 hours use: 0 */6 * * * As long as your upload script is setup correctly it will auto run every 6 hours without failing if there are files to upload and if you used below 750gb. Sent from my SM-A305F using Tapatalk1 point
-
my upload doesn't let me bust 750GB/day (moved home) anymore. stop on limit stops the download when the error occurs, not before i.e. it is not preventative - it just stops the script constantly hammering away for 24 hours to upload files. If you want to upload >750GB/day, use service accounts with the script.1 point
-
Maybe someone is interested: I added a guide how to setup NPM to forward traffic for multiple minecraft servers: https://forums.unraid.net/topic/110245-support-nginx-proxy-manager-npm-official/?tab=comments#comment-10111611 point
-
Managed to replace those controllers. All the drives were in their proper locations when I powered up the machine with the new hba's. Could not have gone smoother. Took me longer to find a vga monitor cable so I could watch the post process than it did to swap the cards, boot up and verify no changes had to be made. I will add, the LSI MPT2 Bios on these controllers is slow to cycle. By slow I mean it will likely cause you anxiety (5 or more minutes to display text). Just wait it out before you panic. I read that if you flash them and remove some part of the bios you can speed that up, but these shouldn't reboot often enough for this to really be an issue. Cards I installed: LSI Logic Controller Card LSI00301 SAS 9207-8i 8Port x21 point
-
It's 1 disk as far as the OS is concerned, treat as such1 point
-
...ich werd welk...natürlich geht es jetzt 🤪1 point
-
The initial copy is probably being buffeted to RAM and then stalling as the RAM buffers get flushed to the drives. in a parity protected array you are never get anywhere close to the raw disk speed as discussed here in the online documentation accessible via the ‘Manual’ link at the bottom of the Unraid GUI. You normally want the ‘Turbo Write’ option enabled to get the best speed achievable in such a scenario.1 point
-
Just to emphasise this point, if you have the array protected by parity in my experience it is actually faster to do the copies serially to avoid excessive head movement on the parity drive.1 point
-
I’ll leave it here in case someone runs into the issue - Unassigned devices and NTFS does not play well. So if you have your disk file on a SSD that is NTFS formatted - you’ll get terrible speeds in the macOS VM - spinning beach ball everywhere. I tore my hair trying to find out the cause of the issue until finally formatting the disk to XFS and restoring the img file to it solved it.1 point
-
Already did that earlier and got a refuse connection error that's why I changed to "br0". Now I tried again and this time it's working. Hehe. Thank you @ich7771 point
-
Yes, because parity need to be updated simultaneously, if you need to do this for a large amount of data best to temporarily disable parity, of course array will be unprotected.1 point
-
I am an idiot. When going over the configuration for the 10th time I found that the IP-address of the unRAID Plex server in the firewall group for Plex servers was missing a number at the end. Correcting the FW ip group fixed this problem so 100%user configuration error. Thanks all for your kind help!1 point
-
PERFECT! Thats it. Thanks, I appreciate your effort.1 point
-
Okay, I figured it out. Please refer to your docker container's log. Shortly after the initial startup a password was written into it that you can use to login using the example email. (that didn't change) Apparently Directus needs to update their documentation here. The reason why this didn't affect me is that I have a way overblown personal template I used to set this up with my own custom password passed into the environment. I simply believed that the default credentials would work for other users. I'm very sorry for the friction here. My guess is your Directus experience will be pretty fly otherwise. I'll change the description to reflect that the password is passed in the log and give an optional choice to pass it directly through the template as a non-required field (in case you don't want your logs password scanned even though you should obviously ALWAYS change default passwords. Good password hygiene is always advisable. ) Thank you so much for the patience, let me know if this helps!1 point
-
No experience with that model. My favorite is Kingston SE9 USB 2.0 version https://www.amazon.com/dp/B00B4G2YXA/1 point
-
I'll be able to investigate this in about 5 and a half hours1 point
-
Yes There is also a Shutdown time-out in Disk Settings. Click on a setting label for help on the setting.1 point
-
No announcement for Uncast 7 ?1 point
-
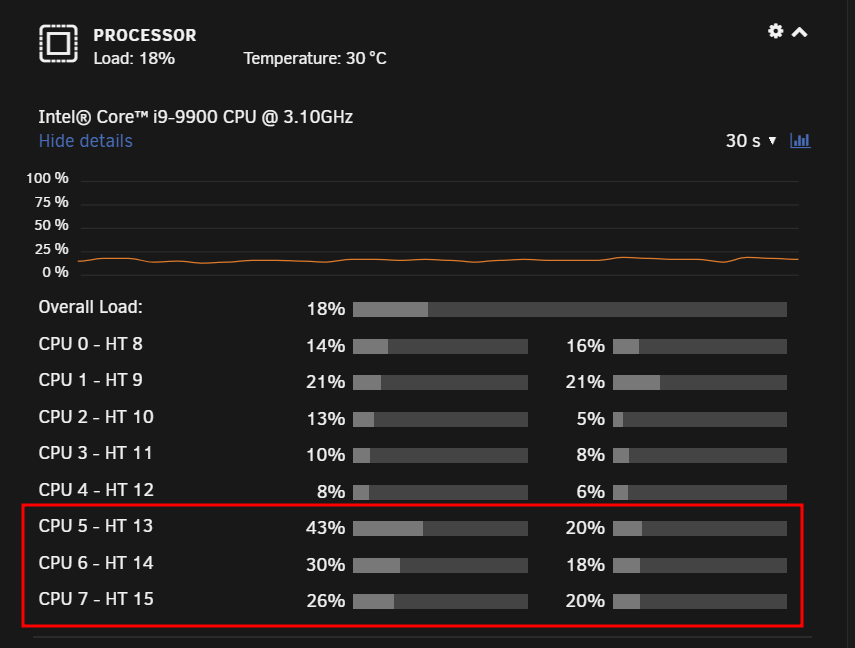
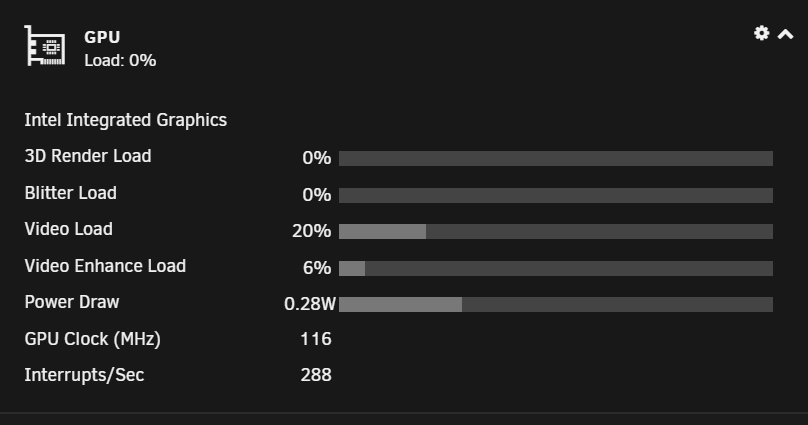
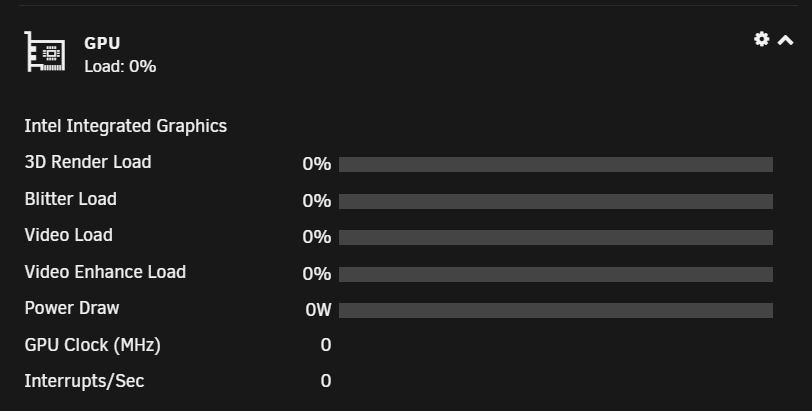
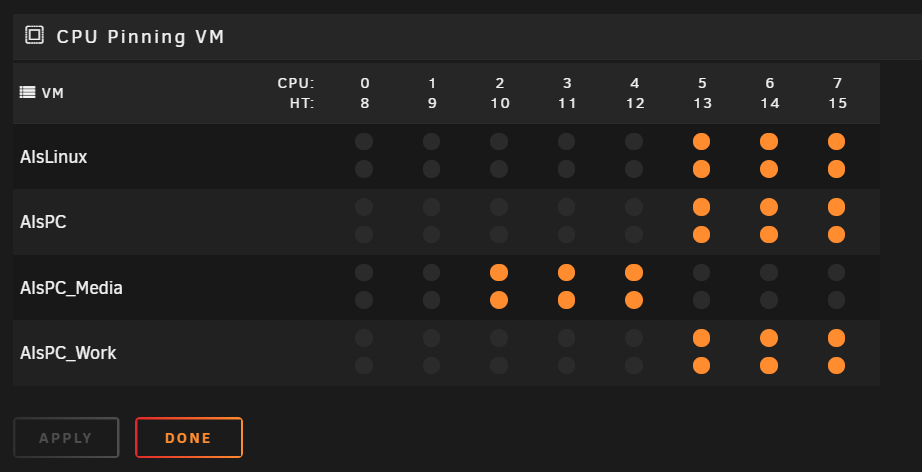
this is while a rdp session is open here now while playing back a 1080p video in browser, the cores are actually double proven, 2 VM's using them ... one with a dedicated gpu /gt1030) as desktop PC annd the gvt--g VM (workspace) now, just closing the session without logoff, gpu is immediately offloaded, thats when i understand you correctly where your issues starting and CPU is back to normal idle state here (2 win VM's in idle, core 1 (CPU5) is a little higher, thats the only recognition here), nothing more ... all good. here you see the current running VM's (AlsPC_Work is the gvt-g one) here the CPU pinning as you see, AlsPC and ApsPC_Work using the same cores so thats all normal here, also after a RDP session with a close (no logoff). when i logoff its even more in idle state, i guess the same to you as you say no issue when u logoff. so, i tested now 20 Minutes RDP session from my laptop (also a 1080p device) so i dont run into trouble ... all fine here, so in the end i cant reproduce the behaviour you describe when only closing the rdp session without logoff, sorry but i cant help here.


 1 point
1 point -
If you chuck the iGPU at Plex, the 11700 won't even start to breathe heavy until you REALLY get up there in concurrent streams1 point
-
Starting from Monterey beta 5 there's a new issue, which still needs to be solved in opencore. Update: the issue is server side, it seems that all the smbios with the VMM flag will not get the update with Monterey (Apple, this is odd!!!!) and also smbios with T2 chip; developers are at work. On some SMBIOS, in particular that having a T2 chip, including iMacPro1,1, the OTA delta update will not show; workaround is to download the full installer and upgrade from there. This will probably not change in next betas and 12.0 release. More info here: https://github.com/acidanthera/bugtracker/issues/1769 https://github.com/dortania/OpenCore-Legacy-Patcher/issues/4711 point
-
OVMF is the bios of our uefi virtual machines: it consists of 2 parts: OVMF_CODE, which is the code of the bios and OVMF_VARS, which is a file where uefi variables are stored. If you look at your xml template you will find where these 2 files are stored on your pc. OVMF is updated by edk2 every 3 months, it's like a bios update.1 point
-
Just checking in. Uptime is now 3 days 13 hours 9 minutes since I last issued the netfilter fix command. Not one call trace in the log or hard lock up / crash since.1 point
-
Difficult to say much, you should share your diagnostics. Go to Tools / Diagnostics and attach the full zip to your next post.1 point
-
Moin, würde es vielleicht Sinn machen einen Sammelthread im Deutschen Bereich zu den erstellten Guides anzupinnen? Mittlerweile gibt es hier ja einiges und ich persönlich finde, dass gerade Guides auf Deutsch sehr dabei helfen, die Zusammenhänge und Abläufe unter Unraid zu zu verstehen. Besonders neuen Usern bietet man hier eine große Hilfestellung und auch Möglichkeiten Hilfe-zur-Selbsthilfe zu schaffen. Dem Ein oder Anderen der einfach nur mal im Forum stöbert, wird man hier vielleicht auf neue Idee für seinen Server bringen. Klar gibt es einen gesonderten Bereich für Guides, dieser ist aber primär auf Englisch. Das kann aber eine Hürde bei einigen Usern sein. Hier würde man diesen Leuten einen Anlaufpunkt geben, sich mehr mit Unraid auseinander zu setzten. Gleichzeitig fördert man das Erfolgserlebnis und senkt die Hemmschwelle neues zu probieren.1 point
-
Awesome. Thanks for the detailed report and logs. @SuberSeb, @harriedr I believe @rbourassa44 just identified your problem. I'll add a fix for this in the next release.1 point
-
Hi there. Have had this up and running for a couple months now, and works great. Not, I'm working through converting my dockers over to a custom network, rather then using the default bridge network. I noticed Urbackup is setup with HOST networking. Any reason I can't change it to use the custom network and manually forward the 3 ports (55413, 55414, and 55415)?1 point
-
I strongly recommend moving to henryw3's docker.1 point
-
You are probably running into this browser resctriction: https://docs.organizr.app/books/troubleshooting/page/redirect-looping---samesite-errors1 point
-
Yet another possibility, assuming you are working on the server with the /mnt/... paths. A move from /mnt/user/some-cache-only-share to /mnt/user0/some-cache-no-share appears to do the correct thing, as I would expect. I just tested it in Midnight Commander. /mnt/user is the user shares including cache. /mnt/user0 is the user shares excluding cache. Linux sees /mnt/user and /mnt/user0 as different mounts so doesn't try to rename the path and actually moves the file from cache to array.1 point






















