Leaderboard



Popular Content
Showing content with the highest reputation on 01/18/22 in all areas
-
Since the 5.x kernel based releases many users have been reporting system hangs every few days once the i915 module is loaded. With reports from a few users detailed in the thread below we have worked out that the issue is caused by the i915 module and is a persistent issue with both the 6.9.x release and 6.10 release candidates. The system does not need to be actively transcoding for the hang to occur. 6.8.3 does not have this issue and is not hardware related. Unloading the i915 module stops the hangs. Hangs are still present in 6.10.0RC2. I can provide a list of similar reports if required.1 point
-
Ich habe gerade wieder was Nerviges gefunden: Intel CPUs der 12ten Generation unterstützen nur noch X8X8 Bifurcation. Ich hatte ja auf X4X4X4X4 gehofft, aber sie haben sogar X8X4X4 gestrichen. Dh wenn das Board zwei PCIe Slots hat, die mit der CPU verbunden sind, dann ist jetzt im Gegensatz zu früher keine weitere Aufteilung, zb per Dual M.2 Adapter, mehr möglich. Auch wird es keine Boards mehr geben, wo über die CPU zwei M.2 NVMe angebunden sind (weil das ja direkt X8 kosten würde). Zusätzliche NVMe laufen jetzt immer über den Chipsatz. Intel verfolgt eine wirklich komische Politik.1 point
-
Sure, I'm using the Sapphire Pulse AMD Radeon RX6600 8GB (VD7869 11310-01-20G)1 point
-
Thank you for the feedback . By giving permission to access the folder I was able to finalize the installation1 point
-
Bonsoir @duch et bienvenue. N'hésite pas à poser tes questions, on répondra au mieux de nos connaissances.1 point
-
Just finished...took about 2 hours. Everything looks good! Thanks a million for the help!1 point
-
Looks like if from Jorge's answer. It will probably depend on the amount of data on the pool. Good idea to move what is not needed before I guess. Jorge might have a better idea of the time it takes.1 point
-
Bonjour à tous, Duch, 40ans, Seine et marne, je suis passé de OMV à UNRAID, C'est un bon en avant ! Je ne suis pas très doué, Je patauge un peu, mais avec une communauté comme celle-ci et Superboki, ça va le faire. J'ai une config qui chauffe un peu, mais bon ... tant pis. Ravi de vous rejoindre1 point
-
das ist ein schlechter Vergleich, wenn dann geht es darum das die AUS ist und die GPU gerade nicht verwaltet wird (von einem OS), daher der p8 mode wie oben beschrieben abschalten geht nicht, was geht, siehe Teil 2 meines Posts bzw. mein Endstand1 point
-
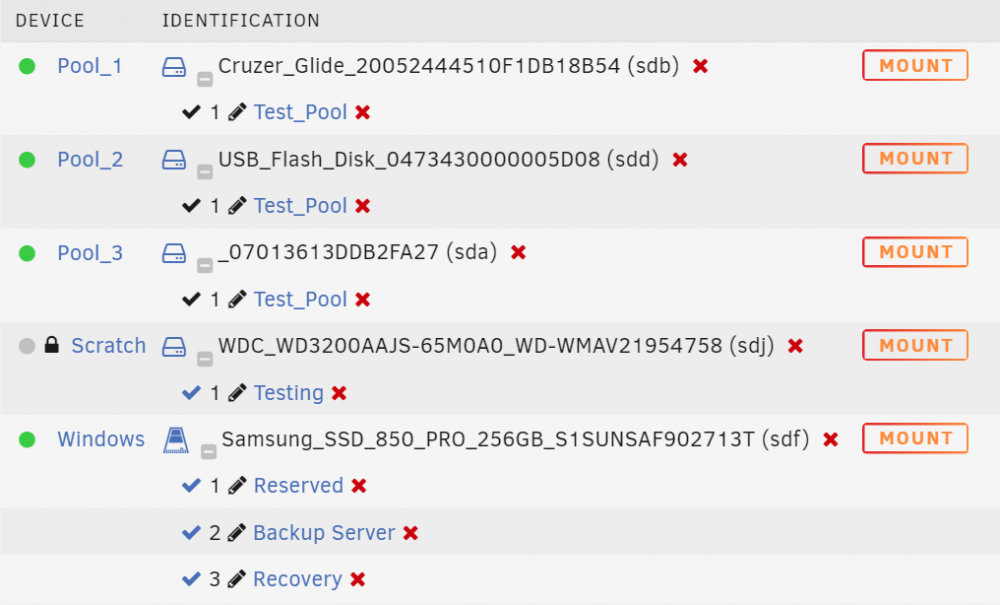
I'm finishing up a new feature that allows you to add an alias name to a disk device and then use that name to mount, unmount, and spin down a disk. Using this feature, you can spin down a disk when it is unmounted by changing the device script like this: 'REMOVE' ) # do your stuff here /usr/local/sbin/rc.unassigned spindown name=Scratch After the disk is unmounted the 'REMOVE' event is sent to the device script and at that time the spindown can occur. The caveat is that this only works in 6.9 and later. Here is a screen shot to show how the alias naming works. Don't use the hdparm command on 6.9 and later because it confuses the spin down logic in Unraid.
 1 point
1 point -
I can recommend the P11C-I from ASUS with a 300W Power supply for a NAS only device ( 9100, too ). I just replaced it with a z-Board for gaming. I can test the power usage in idle if you are interested in using this board. You can write me a PM if you need more information ( german / english )1 point
-
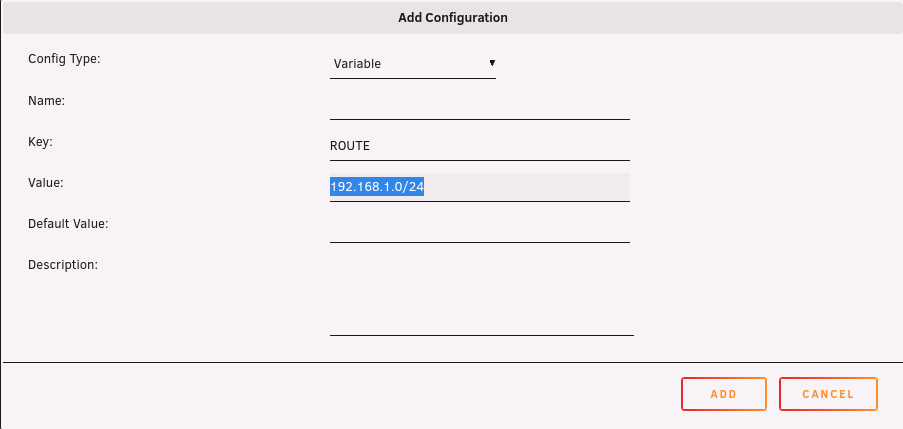
@Ford Prefect ja das sollte so funktionieren, hab aber in den nächsten Tagen keine Zeit zu testen: Link Einfach eine Variable im Docker Template anlegen mit dem Key: "ROUTE" und dem Value: "DEINNETZWERK/24" ca. so: Danach solltest du den container als Gateway verwenden können. Kannst du mal testen ob das funktioniert @Fidel84?
 1 point
1 point -
It should be quite simple: disable Docker and VM services in Settings (maybe optional, not sure) access the pool configuration by clicking on "cache" run a scrub on the Pool to be sure to start with something clean (optional) In the "Balance" section, select the RAID profile you desire (RAID1 for you) and click "Balance" Enable the services you disabled earlier I do not think it is even required to disable Docker and VM services in Settings (to be confirmed by users with more experience in the matter). In any case, if it was for me, I'd do it.1 point
-
@SpencerJ told me he loves bacon, wait what ? baaab abaaa babab baaba aabaa abbaa babbb aabaa baaaa abbab baaaa aaaba baaba baaaa abbab abaaa baaab aabab1 point
-
No idea on final version, but there has already been comments that rc3 will have the 5.15 kernel (or later I guess).1 point
-
Getting close to the Stable? Or not quite there yet?1 point
-
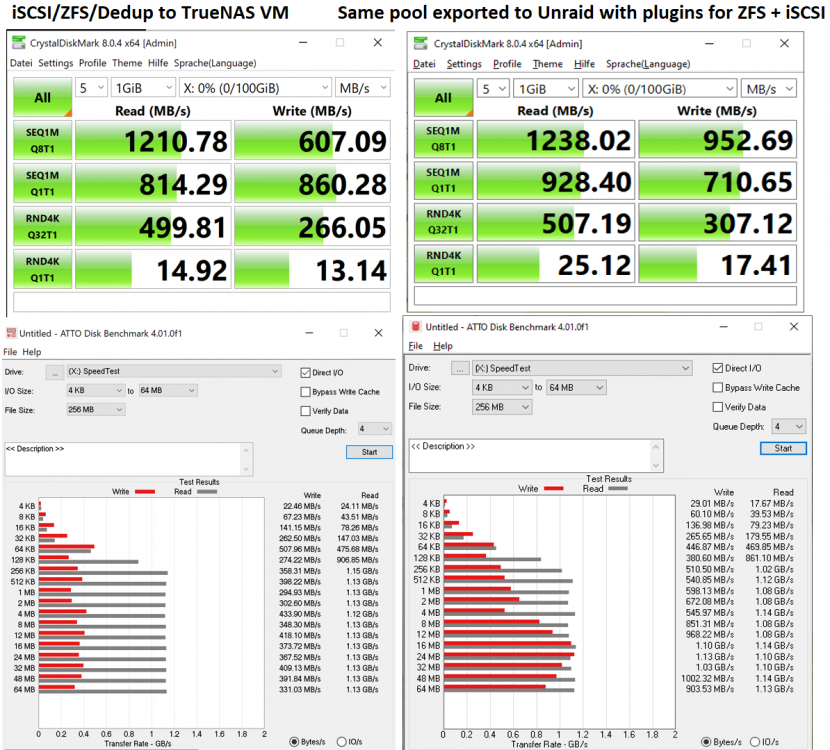
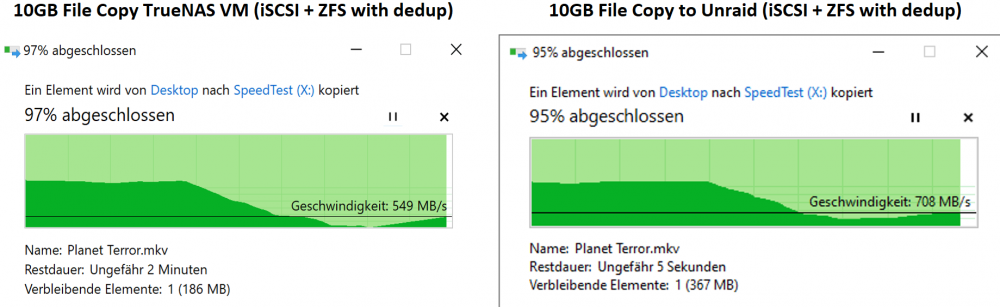
And now my speed compare ZFS/Dedup/iSCSI to TrueNAS (as VM on Unraid) vs. ZFS/Dedup/iSCSI to native Unraid... I mean to the awsome community plugins on Unraid 😇 !!! Thanks a lot at this point for all your work. As I hoped the performance is (mostly) better. It could be because of no virtio layer needed (I don't know the performance of the FreeBSD/TrueNAS virtio driver). The "real world" 10GB movie file copy doesn't drop as much and runs really faster on "native unraid". Conclusion: Will I use iSCSI => yes, the performance for games over 10G network is great, normally just a few seconds compared with local Nvme which is not noticable if you have to watch intos... Will I use ZFS => yes! Will I use Dedup => it depends... the dedup ratio could be better for that and the drawbacks of slower performance with more data in the future is a big point. I've another idea to test... Next idea: Prepare one game lib as zvol with really everything installed, take a snapshot/clone of it for every client. The clones should only use the space on disk for the changed data and no additional RAM needed for dedup table. With such a setup I need to update only the initial/primary "game lib zvol" and a reset/redo new clones via a user-script should be possible.
 1 point
1 point -
You have to blacklist the i915 module like it is described in the error message, the GVT-g plugin will handle the activation from GVT-g in the i915 module (and of course the GVT-g plugin loads the i915 module so that you can use it like usually in Plex or wherever).1 point
-
Hi Guys, I was hoping that someone could help me, my JellyFin instance recently decided it needed an update so I did and now it refuses to start. All of my other containers start no issue. The error it gives is: I have checked the logs and there is nothing there at all so there is no other indication as to why the failure. I was looking for others with the same issue and there seems to be some. I found this thread with the exact same issue but there doesn't seem to be an answer that works here. Can someone please assist in sorting this issue? https://forums.unraid.net/topic/117030-jellyfin-execution-error-server-error/1 point
-
Hopping in here with a similar problem. Unraid Plus Ryzen 3700x x570x gaming MB 32GB Win 11 VM- 16GB, 4 cores/8 threads. Currently has an nvidia GTX 1050, used to have an AMD 7850. I do have PCI ACS override enabled for IOMMU separation (annoying, necessary) Reproducible problem: If the system is in active use, it runs flawlessly, no timelimit. If the nobody is using it, it will freeze after 10 minutes with all cores/threads pinned to 100% (as per unraid dashboard). I've disabled all power management, disabled screen savers, removed hardware (I thought maybe bluetooth mouse was sleeping/causing a problem). Windows logs showed Radeon software failing repeatedly, so I was optimistic that was the problem. uninstalled, and persists. Freezing with version 22000.376.0 I'll try the suggestion to join the insider and will report back. Edit: forgot to add that this VM can also run as bare-metal and the issue is not present in that state.1 point
-
Thanks for the heads up. I've never actually used GitHub (noob here) so I'll have to look into how to communicate on that platform. Appreciate the lead.1 point
-
When these system hangs happen for me (started on 6.9.2 and have continued with 6.10.0 RC), there is nothing meaningful in the syslog around the time of the hang but this is sometimes reported in the IPMI log. An OS Stop/Shutdown sounds like a kernel/driver issue to me. It's like the rest of the system is working but the OS just decided to shutdown. FWIW, I have never seen these shutdowns as a result of hardware transcoding.
 1 point
1 point -
the problem is already evident in your comment, you say crypto currency because you dont want to imply using a certain one. Problem is there are a bazillion crypto currencies now and whenever you start accepting one people will spam around why Doge coin is accepted by Shiba Inu coin is not Then you also need a service in between that updates the pricing as crypto currencies are far from stable so you usually end up with a payment provider which defeats the purpose of using crypto in the first place. Then you also need to convert that crypto back to FIAT currency as crypto usually isnt accepted to pay the bills so they need a tax guy to handle this stuff on top of the usual stuff. Same for customers, depending on where you are buying something with your crypto could be a realized gain which is then taxed so you need documentation to track all this for tax season. Overall its just one giant effort for a relatively small group of people who if they would practice what they preach not use cryptos anyways because they will HODL forever.1 point
-
Yeah, was looking for what ^ said, "none of the above," consider me a control group. Really I only care for credit/debit card, I see extra options as unnecessary.1 point
-
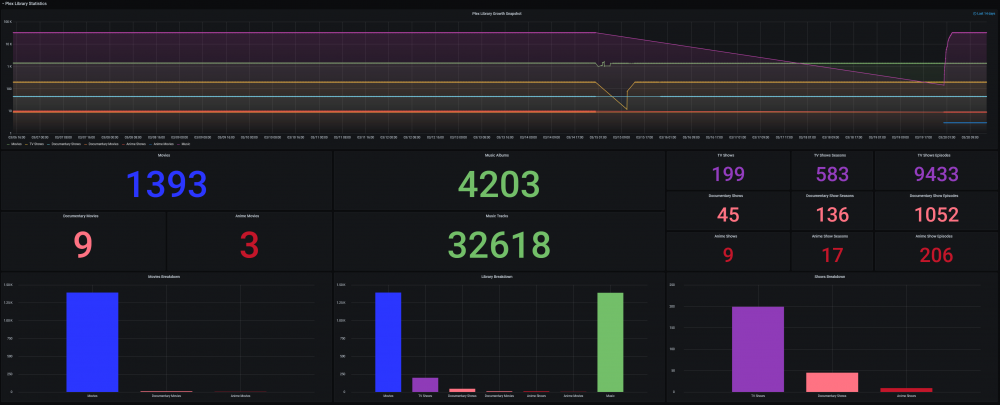
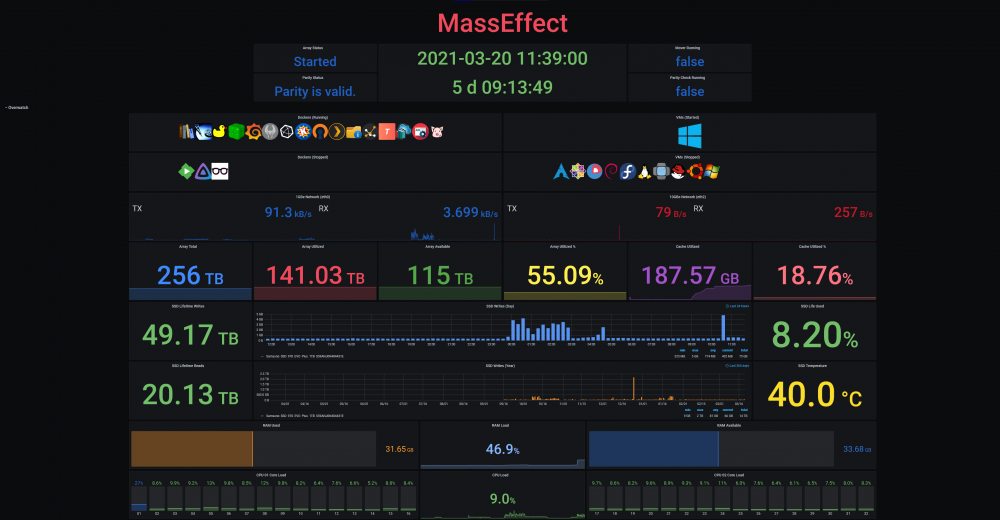
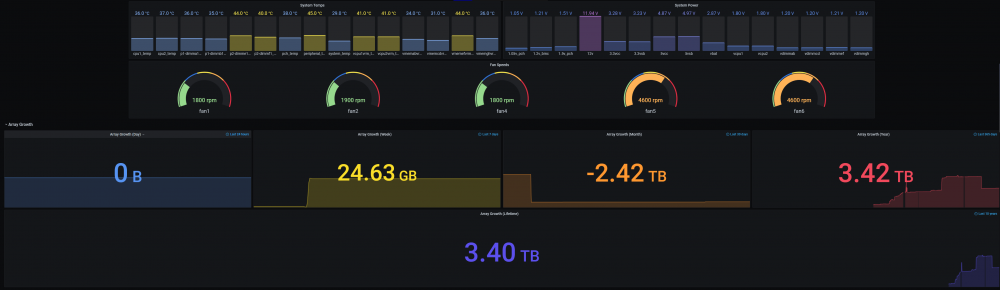
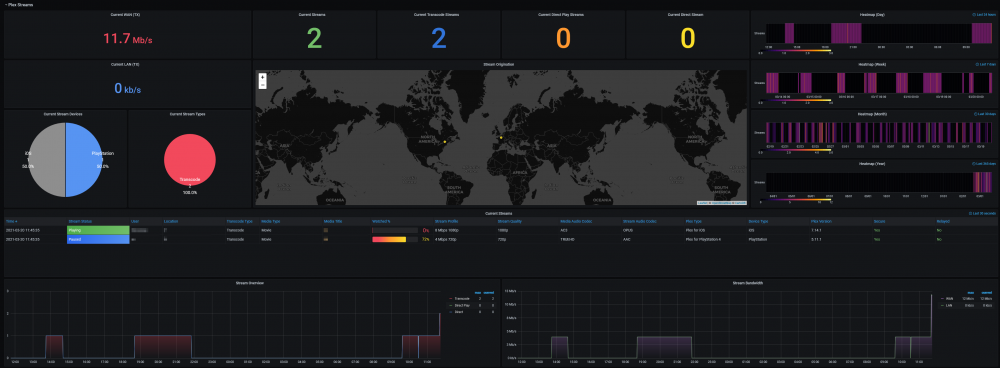
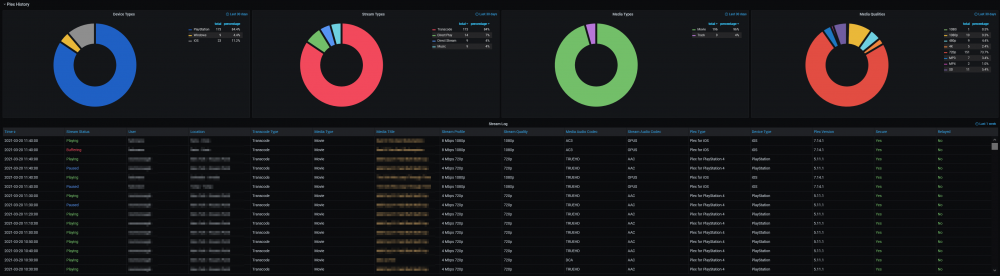
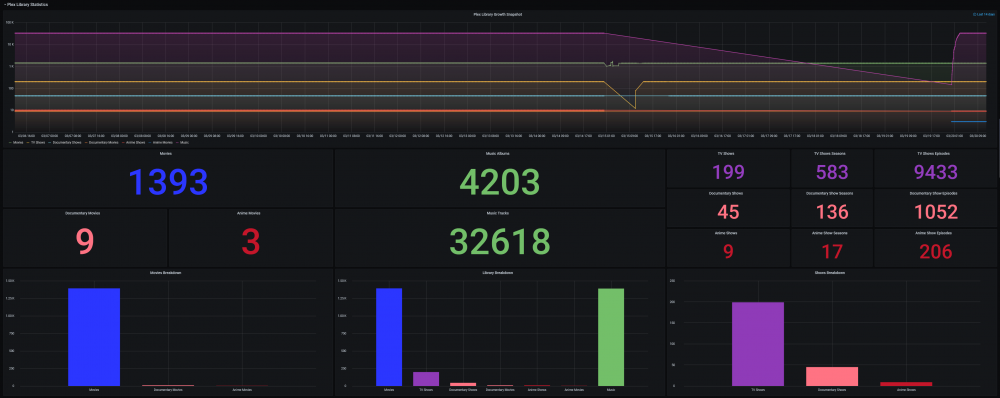
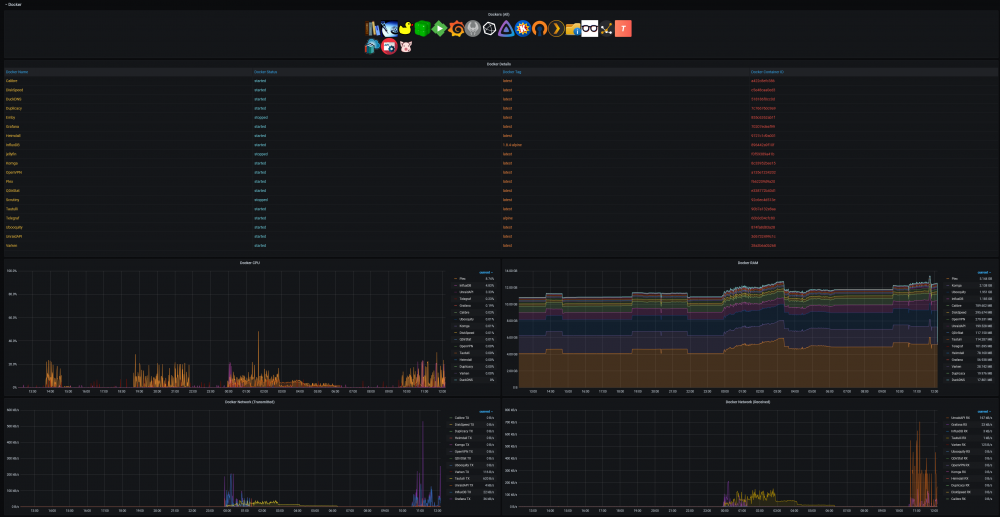
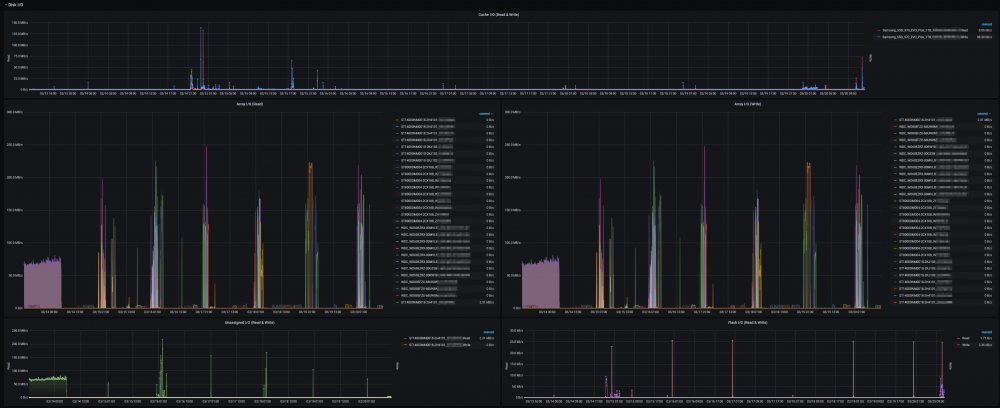
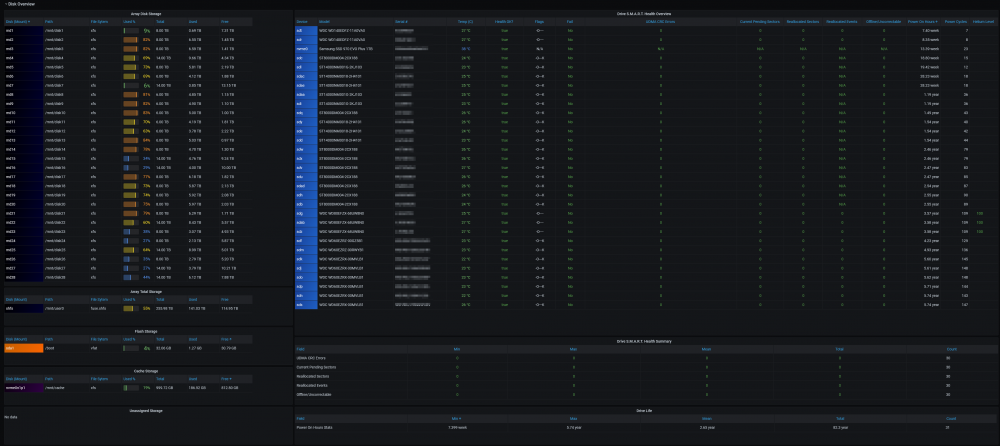
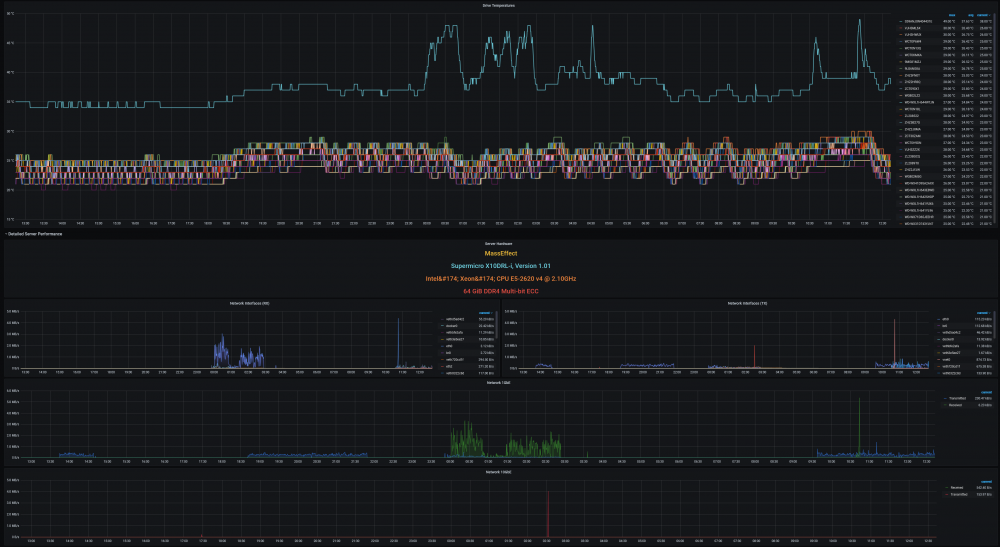
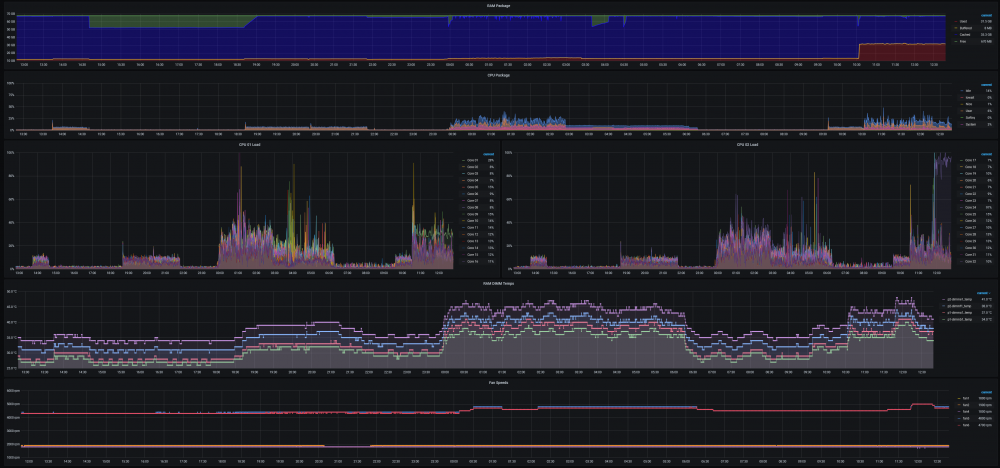
@SpencerJ @limetech The Ultimate UNRAID Dashboard Version 1.6 is here! This is the largest release yet 😁. Leveraging the power of the UNRAID API I bring you Array, VM, and Docker Monitoring. This new version also adds a dedicated SSD (Cache or otherwise) monitoring section complete with TBW monitoring to show SSD % of drive life used. There are a ton of other features, enhancements, bug fixes, improvements and continued refinement of the UI and color scheme. In total, UUD Version 1.6 adds 25 new Panels across 7 sections. Enjoy! 😉 New Dependencies: Dockers: UNRAID API (Install With Default Setup / Follow Current Project Install Guide) Download from Community Apps https://github.com/ElectricBrainUK/UnraidAPI New Grafana Plugins JSON API https://grafana.com/grafana/plugins/marcusolsson-json-datasource/?pg=plugins&plcmt=featured-undefined&src=grafana_footer Run Following Command in Docker: grafana-cli plugins install marcusolsson-json-datasource Dynamic Image Panel https://grafana.com/grafana/plugins/dalvany-image-panel/?pg=plugins&plcmt=featured-undefined&src=grafana_footer Run Following Command in Docker: grafana-cli plugins install dalvany-image-panel New Grafana Data Source: "UNRAID API" Dashboard Variables Please Note: This release is an example tailored to MY UNRAID Server. The intent here is that you will take this and modify it for your Setup. You have everything you require to template new panels and tailor it to your own needs. Highlights: New UNRAID API Related Panels Dynamic Header Host Name Array Status Parity Status Mover Running (True/False) Parity Check Running (True/False) Overwatch Docker Monitoring with Real Time Dynamic Images/Statuses Dockers (Running) Dockers (Stopped) VM Monitoring with Real Time Dynamic Images/Statuses VMs (Started) VMs (Stopped) Docker Dockers (All) Docker Details Virtual Machines VMs (All) VM Details Server Hardware Shows More Detail Regarding Specific Server Hardware Specifications Array Growth Array Growth (Lifetime) Shows Array Growth Over Rolling Last 10 Years (1 Data Point Per Day) SSD (Cache) Drive Health SSD Writes (Day) Shows SSD Writes For Rolling Last 24 Hours at 15 Minute Intervals Controlled By New SSD Drive Variable SSD Writes (Year) Shows SSD Writes For Rolling Last Year at 1 Day Intervals Controlled By New SSD Drive Variable SSD Lifetime Writes Measures SSD Lifetime Writes Math Based on Manufacturer Max TB Written (TBW) Specification Color Based on Thresholds (Derived From Manufacturer TBW) SSD Lifetime Reads Measures SSD Lifetime Writes Math Based on Manufacturer Max TB Written (TBW) Specification Color Based on Thresholds (Derived From Manufacturer TBW) SSD Life Used Calculates Used Drive Life Based on Lifetime Rights Divided by Manufacturer Max TBW Math Based on Manufacture Max TB Written (TBW) Specification Color Based on Thresholds (% of Manufacturer TBW) SSD Drive Temperature (Dynamic Colors Based Temp Thresholds) Plex Library Statistics Combined Growth Chart Across All Libraries The old way was just ugly and too performance intensive This is a nice one stop shop! Completely Overhauled with New Panels with Media Type Breakdowns Across Sub Libraries Changes Variable Now Used for Varken Datasource (Set at Top of Dashboard) Updated GUI Panels/Sizes/Locations/Colors/Themes Change Uptime Panel to Fit New Theme System Power Panel Changed System Power to Bar Charts Scaled the Volts to a Range Between 1V and 12V Array Growth Changed All Panels to Rolling Timelines Today So Far = Last 24 Hours This Week So Far = Last 7 Days This Month So Far = Last 30 Days This Year So Far = Last 365 Days Plex Stats Renamed to Plex Streams Plex Heatmaps Changed All Panels to Rolling Timelines Today So Far = Last 24 Hours This Week So Far = Last 7 Days This Month So Far = Last 30 Days This Year So Far = Last 365 Days Plex History Device Types Changed Chart from Pie to Donut Stream Types Changed Chart from Pie to Donut Media Types Changed Chart from Pie to Donut Media Qualities Changed Chart from Pie to Donut Changed Panels to Rolling Timelines Today So Far = Last 24 Hours This Week So Far = Last 7 Days This Month So Far = Last 30 Days This Year So Far = Last 365 Days Plex Library Growth Changed All Panels to Rolling Timelines Today So Far = Last 24 Hours This Week So Far = Last 7 Days This Month So Far = Last 30 Days This Year So Far = Last 365 Days CPU 01 Core Load Changed Labels So Cores Reflect Only the Core Number Before: Core01, Core02, ... After: 01, 02, ... This Improves Readability and Scalability on Smaller (Non 4K Displays) Array Disk Storage Used % Field: Removed Cell Background Colors and Changed Override to Basic Gauge Improved Visual Experience and Readability Array Total Storage Used % Field: Removed Cell Background Colors and Changed Override to Basic Gauge Improved Visual Experience and Readability Flash Storage Used % Field: Removed Cell Background Colors and Changed Override to Basic Gauge Improved Visual Experience and Readability Unassigned Storage Used % Field: Removed Cell Background Colors and Changed Override to Basic Gauge Improved Visual Experience and Readability Flash Storage Used % Field: Removed Cell Background Colors and Changed Override to Basic Gauge Improved Visual Experience and Readability Drive S.M.A.R.T. Health Overview Temp (C) Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Drive S.M.A.R.T. Health Overview Temp (C) Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability UDMA CRC Errors Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Current Pending Sectors Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Reallocated Sectors Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Reallocated Events Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Offline/Uncorrectable Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Helium Level Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Drive S.M.A.R.T. Health Summary Min Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Max Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Mean Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability Total Field: Removed Cell Background Colors and Changed Override to Colored Text Improved Visual Experience and Readability UPS Stats UPS Runtime Left Removed Exclamation Point From Panel Name Changed All Panels to Rolling Timelines Today So Far = Last 24 Hours This Week So Far = Last 7 Days This Month So Far = Last 30 Days This Year So Far = Last 365 Days Removed Cell Background Colors Improved Visual Experience and Readability Fixes/Improvements All Panels are Now Driven by Datasource Variables Adjusted All Drive Path Panels to Use Regex Resolves ROOTFS Issue Some Users Were Experiencing UUD Should Now Not Care How Your Paths are Setup and Just Work Adjusted Drive Variables to Select Distinct Based on Selected Time Interval Removes Missing/Old Drives From Panels and Removes Legacy Data Prevents Old Device IDs "SD*" From Showing Up After Reboots Provided You Select a Timeframe After the Reboot Varken Geolocation Map Fixed Bug Where Geo Map Header Was Hidden Behind UI Elements Gave Panel a New Name of "Stream Origination" Map Now Automatically Centers on Current Stream (Last Geo Hash) Changes Default Zoom Level to 3 (Zoom Out By Factor of 1) Changed Geo Location Blips to Yellow to Match Plex Color Theme Added Mouse Zooming/Scrolling (Wheel) to Map General Graphs Now Start at "0" Where Applicable (Docker Ram) % Graphs Now Cap at 100% (CPU Graphs) Drive Queries Now Correctly Account For Dynamic Host Variable (Custom Query and Parenthesis Placement) UUD 1.6 Screenshots (With Personal Info Redacted): A TREMENDOUS amount of work has gone into this release. There are a ton of people who have contributed to this release whether it be bug fixes, suggestions, improvements, or new ideas. I will do an updated post to specifically call out each and every person who helped with this 1.6 build. First, though, I just want to get this out to you guys ASAP. There are a few tips and tricks that I will also release in a post soon that will detail some of the gotchas with the UNRAID API and new Grafana Plugins. I just need some time to put that together. In the meantime, please let me know how your baseline 1.6 install is going. I really hope you guys enjoy this release!!!




.thumb.png.92808247ef39a7d2f3080e02af29897d.png)





.thumb.png.c57838a767decc3c3500219f31029d73.png) 1 point
1 point -
Here's a post to get you started1 point
-
Update: if somebody else has to do this The following steps worked for me and the VMs are running stable so far. Installing the drivers before converting / moving the disk is not necessary. - Create a Backup of the Servers - Shut down servers and convert vdisks to raw format (I used qmu-img with the following command ) .\qemu-img convert -O raw "D:\location\disk.vhdx" 'G:\location\vdisk1.img' - Create new VM in unRAID for Server 2016 and disable automatic start - Replace vdisk1 one with the converted disk. Set disk type to SATA - Add second disk with 1M size and raw format - Add newes VirtIO drivers ISO to VM (https://fedoraproject.org/wiki/Windows_Virtio_Drivers) - Start VM and install VirtIO Drivers on the device manager (same way as shown in the guide below) - Replace GPU drivers and Install Guest driver (as shown in the guide below) - Stop VM and remove disk 2 and change disk 1 to raw format done1 point
-
Woo hoo!! So no need for plan B?? Moving forward with Plan B. I realized I still needed a way to transfer the movies between boxes. 2.5 hours into a 843 GB transfer right now with 6 or 7 batches of roughly the same size to follow. I actually do this over the network. Why not? You already have the mechanism in place with the mount that you performed. Here's what you can do: login via console on tower1 (I'll call them tower1 and tower2 for now). type "mc" to bring up midnight commander. browse to your "source" on the left and your "target" on the right. Select the items on the left you want to move to the right by hitting "ctrl + t" on the keyboard (you can tag multiple files / folders). Hitting F5 (on your keyboard) will then initiate a "copy" whereas F6 could be used to initiate a "move" There is even an option to have the job run in the background so you don't have to leave your terminal session open to do this. I've literally copied terabytes of data with this method and had zero problems. I was even still streaming movies and running VMs while the copies were going. no problems.1 point
-
Woo hoo!! So no need for plan B??1 point





























.png.22e490e87cea389a3192d554fbb028bb.png)
















.png.c49ac940143d11db30092fa7a8afec72.png)

