Leaderboard




Popular Content
Showing content with the highest reputation on 03/01/22 in all areas
-
Spaceinvader One's latest video on server backup/failover inspired me to do some tweaks to my setup. I backup share data from one unRAID server to another once a week. His video inspired me to make my setup a full failover scenario as far as my Plex media is concerned. His backup scripts appear to be powering on and off the servers via smartplugs. In my case, both my main and backup servers have IPMI-enabled motherboards so I find it easy to power the servers on and off that way. A great way to do this is to install ipmitool from the Nerd Tools plugin. Once installed, you can just call ipmitool with some parameters to power on or off the desired server. Here are some examples: Power on a server ipmitool -I lan -H {BMC IP address of server to power on} -U {IPMI admin user name} -P {IPMI admin user password} chassis power on Power off a server gracefully ipmitool -I lan -H {BMC IP address of server to power off} -U {IPMI admin user name} -P {IPMI admin user password} chassis power soft Note the IP address to use is the IP address assigned to the BMC NIC, not the server eth0 IP address. On some motherboards the same NIC may be shared by the BMC and eth0. Notes on chassis power states: soft (clean/graceful shutdown - no parity check forced on next startup) Initiate a soft-shutdown of OS via ACPI. This can be done in a number of ways, commonly by simulating an overtemperture or by simulating a power button press. It is necessary for there to be Operating System support for ACPI and some sort of daemon watching for events for this soft power to work. off (unlcean shutdown. Will start a parity check on array startup) Power down chassis into soft off (S4/S5 state). WARNING: This command does not initiate a clean shutdown of the operating system prior to powering down the system If you choose to use the great scripts from Spaceinvader One but you have IPMI capable servers, you can modify the scripts to call ipmitool instead of powering on or off a smartplug.2 points
-
Dutch language is now finally fully translated. Except Parity Check Tuning where it was written in the translation file that is was better to not translate certain things.2 points
-
Das WebGUI von Unraid ist leider kein Responsive Design. Warum, ist mir völlig schleierhaft. Damit wird die Bedienung auf Smartphones und Tablets unterhalb einer Displaygröße von ~ 9" zur Fummelei und de facto unmöglich.2 points
-
Hi all, In the .zip archive file attached to this post is a script I have written in order to backup LUKS headers of encrypted devices attached to Unraid. 1. WHY? Backing up LUKS headers is a paramount precautionary measure given the fact that data corruption in LUKS header may lead to losing all the data present on the device. Please note that in this scenario, knowing the passphrase (or having a copy of the key file used to store the passphrase) is irrelevant and will not help you recover the data. This is because the passphrase is not used in deriving the encryption master key, but only used in decrypting the encryption master key, the latter being randomly generated on each device upon initial creation of the LUKS header. 2. HOW? To backup your LUKS headers, just run the attached script as root. The script is not interactive, therefore you can use it with the wonderful User.Script plugin by @Squid (see: here). 3. WHEN? LUKS headers only need to be backed up upon a change in one of the headers. A change should occur upon events such as: any drive is formatted (or reformatted) as encrypted (this includes the addition of a new encrypted drive) a passphrase (or the key file used to store the passphrase) is added to, changed in or removed from any of the 8 different key slots provided by LUKS (the Unraid GUI allows you to create only one passphrase for the entire array, but the underlying kernel module does allow 8 different passphrases for each encrypted device) Therefore, there is no need to schedule the backup to any particular period. A scheduled backup should even be avoided if you elect to copy the backed up LUKS headers to the Unraid flash drive, as it is considered good practice to keep the read/write operations of the flash drive to a minimum. 4. HOW DO I RESTORE LUKS HEADERS FROM A PREVIOUS BACKUP? As of now, the safest way I have found to restore LUKS headers from a previous backup is to run the command below manually for each drive that needs to have its LUKS header restored (don't forget to replace the <path to relevant LUKS header backup> and <device / device partition> with the correct information for your use case): cryptsetup luksHeaderRestore --header-backup-file <path to relevant LUKS header backup> <device / device partition> IMPORTANT: if the <device / device partition> is assigned to an array protected by parity, ensure that you are pointing to the managed partition device, i.e.: "/dev/mdXp1" (start the array in maintenance mode first) and not to the actual "dev/sdY1" partition device. Indeed, writes to /dev/sdY1 will bypass parity but writes to /dev/mdXp1 do not. 5. WORK IN PROGRESS I am trying to write a command that would restore all LUKS header at once. However, I need to find a way to reconcile (in CLI) each "/dev/mdXp1" device (i.e.: the device that is created after starting the array and which needs to be written on for the restore operation in order to preserve parity) to the corresponding "/dev/sdY" device (i.e.: the actual device which contains the "ID_SERIAL" used to name the LUKS header backup .bin file for that disk). I asked the question here but never got an answer. The command would be something like (note that you should not run it as is because it is not working in its current state): # DO NOT USE / DO NOT USE / DO NOT USE #cd "/directory/where/the/backed/up/LUKS/headers/are/stored" && for i in {/dev/sd*,/dev/nvme*}; do if cryptsetup luksDump $i &>/dev/null; then cryptsetup luksHeaderRestore <WIP: '$i' cannot be used here because it would bypass parity> --header-backup-file "`udevadm info --query=all --name=$i | sed -n 's/.*ID_SERIAL=//p'`.bin"; fi; done # DO NOT USE / DO NOT USE / DO NOT USE 5. ANYTHING ELSE? Feel free to report any issues and make any suggestions. This script is based on exchanges from the following threads, which you can refer to: thread 1 thread 2 as well as on the official LUKS page : https://gitlab.com/cryptsetup/cryptsetup/-/blob/main/FAQ.md#6-backup-and-data-recovery Best, OP unraid_backup-luks-headers-v0.2a.zip1 point
-
Thanks very much!1 point
-
The UD Preclear won't allow preclearing just any unassigned disk. This was done for safety and yes you have to remove the partitions before a disk can be precleared.1 point
-
I completely understand that is par for the course with this thread. I'd be happy to purchase the game for you if that's what will get it working. How do I go about donating to the cause or gifting it to your Steam account? It's on sale until Mar 3rd so I'd be eager to get this done while the sale is still going on. Thank you! Looking forward to the results!1 point
-
I wanted to circle back and let you know that this worked. All Drives are recognized and working. The Array is back to complete. It took longer than expected due to 2 factors: I travelled for a week and was unable to work on this, and I was generally being over cautious about these steps. Plex is all messed up but that's a minor problem. Drive recovery was the priority. Thanks so much for the help!1 point
-
Thanks for your help. I have read that but it seems that the information was not processed by my brain 🙄1 point
-
Disable Int13h is the HBA's bios (if it's not specifically labelled as disabling boot, this the option you're looking for)1 point
-
How are the drives connected? Some BIOS’s get upset if they see more than 12 drives potentially bootable. The fix in such a case is normally to go into the BIOS settings for the HBA and turn off the option to be able to boot from HBA attached drives.1 point
-
Achgott. Wenn ich das richtig sehe, reicht der Eintrag dieser Parameter in der nextcloud.subdomain.conf versucht: location = /.well-known/webfinger { return 301 $scheme://$host:$server_port/index.php/.well-known/webfinger; } location = /.well-known/nodeinfo { return 301 $scheme://$host:$server_port/index.php/.well-known/nodeinfo; } Jetzt zeigts bei allen Browsern , dass aller Sicherheitsüberprüfungen bestanden wurden. Außer auf dem genutzten Browser auf meinem Hauptrechner. Da scheinen die Meldungen immer noch auf, obwohl cache und cookies für die Seite gelöscht. Nach dem dritten mal Löschen und einige Zeit später nun auch auf dem "Hauptbrowser" alles ok. Somit ist alles geklärt. Nochmal vielen Dank für die Hilfe!1 point
-
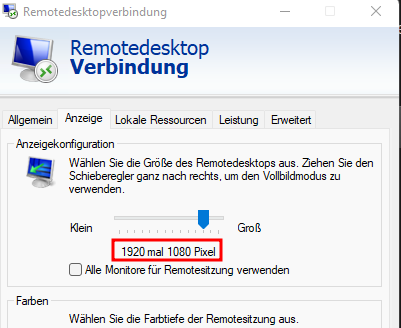
Thinks! My motherboard model is ASRock Z370M pro4, and the CPU is i5-8400. Because my computer's maximum resolution is only 1600X900, RDP cannot use higher resolutions.1 point
-
I can say that the Transcend JetFlash 600 USB-Stick is a reliable (MLC chips) option aswell. UK: https://www.amazon.co.uk/Transcend-JetFlash-Flash-USB2-0-connector/dp/B002QCAN9S US: out of amazon stock DE: https://www.amazon.de/Transcend-JetFlash-Extreme-Speed-32GB-USB-Stick/dp/B002QCAN9S1 point
-
I think I've got this. There is a built-in help when you click on "Disk verification schedule" label and it says: But mostly important:1 point
-
Ein Mainboard hat keinen Grafikchip, außer es ist ein Board mit IPMI (Serverboard). Das ist die iGPU der CPU. Demnach hast du also nur zwei GPUs und die Frage bleibt offen warum im BIOS von dreien die Rede ist. Du musst in jedem Fall die iGPU als primäre GPU im BIOS auswählen und an VFIO darf nur die dGPU gebunden werden.1 point
-
Ich denke mal der SAS Controller hat ein Problem bzw der zusammen mit den HDDs. Firmware aktuell? Mal gezielt nach dem Controller und dem Problem gesucht? In den syslogs keine Fehlermeldungen?1 point
-
try it, but you are in the lucky position that your aperture size is fine, may i ask which mainboard you use ? and keep in mind, v2 should be fine till 1920x1200, but look that your RDP client is not exeeding this resolution, so when your desktop has a higher resolution edit the rdp client resolution manually ... to keep a buffer window open. and watch your syslog, if page errors start, in the end this can result in a crash (unraid crash, hard reboot ...)
 1 point
1 point -
The gpu vram is 1G : I am using V5_4 now, can I continue to use RDP if I use V5_2?
 1 point
1 point -
may dont use RDP as client software, rather switch to VNC, chrome remote desktop, parsec, ... this error is coming when the gpu vram gets on its limits, nothing we can really do aout it and usually coming only on RDP usage. you can read some pages up about aperture size etc, RDP can and will (sadly) end up with issues here ...1 point
-
This fixed my issue. I'd also updated to 6.9.2rc2 before trying this.1 point
-
Dev builds are available. Please see here. https://github.com/deasmi/unraid-tailscale/issues/9 I will probably wait for 1.22.1 before moving latest tag.1 point
-
Whatever you have done witz PhantomBot-1 , now it works Thanks a lot !1 point
-
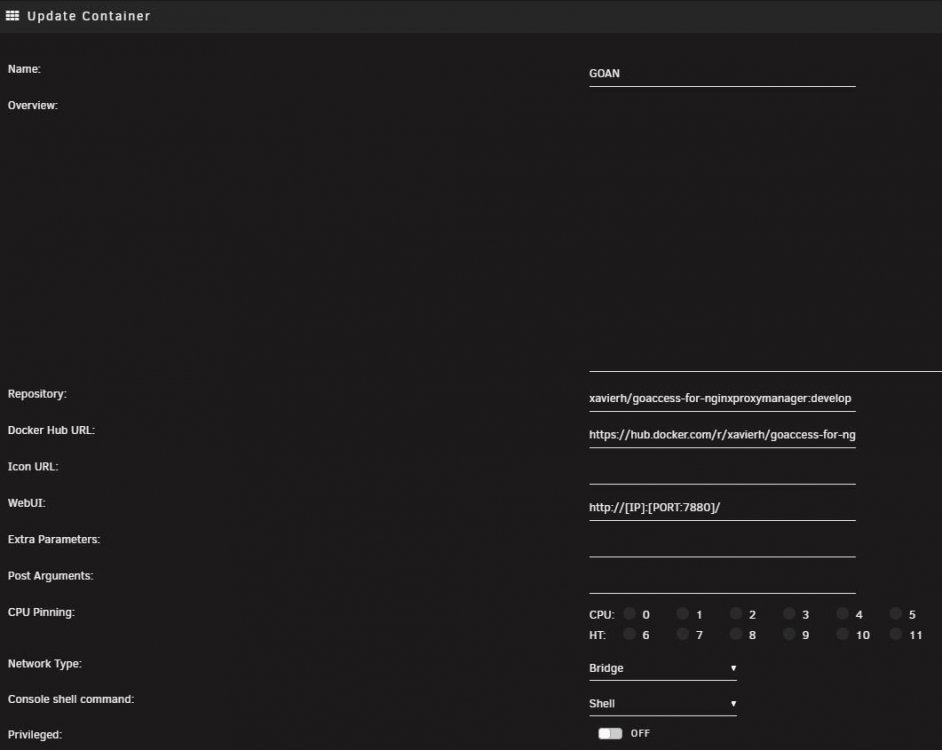
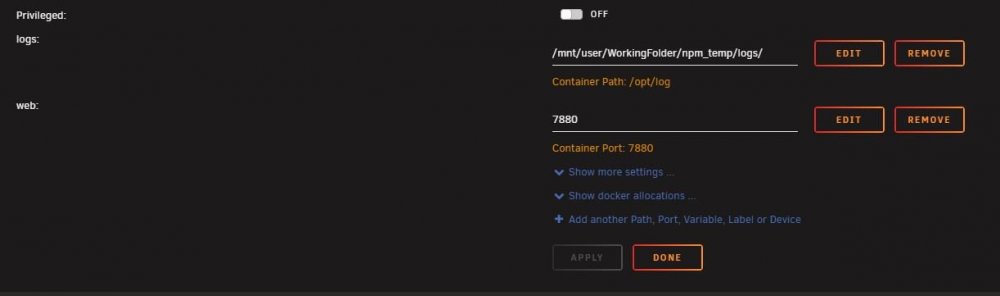
Not sure when you grabbed the latest but the MaxMind database is included now in the image. There is no direct access to the goaccess.conf as this is set currently only to process proxy_host files. But later I'll let the goaccess.conf be loaded from outside the image. You should be able to manually add it to unraid going to docker, add container, then click advanced and set up the parameters appropriately. Name: Whatever you want Repository: xavierh/goaccess-for-nginxproxymanager:develop WebUI: http://[IP]:[PORT:7880]/ Create a path: Name: doesn't matter Container Path: /opt/log Host Path: /mnt/user/*** Access Mode can be read only Create a port: Name: doesn't matter Container Port: 7880 Host Port: 7880
 1 point
1 point -
@skaterpunk0187 Congrats 🎉:
 1 point
1 point -
Hey, I'm also a bit of a noob, but I might be able to help a bit. 1) I read the same guide. The /mnt/user/appdata** path is identical to the /mnt/cache/appdata** path, assuming that your appdata is stored on cache. You can tell this by going to the cache drive in "Main" and clicking the windows explorer-esque logo on the right to see what data is stored on it. You can then go to "Shares" and just sanity check within the share the "use cache pool" setting (see below). Going back to the /mnt/user vs /mnt/cache discussion, the reason that I've read this is a worthwhile change is that the /mtn/cache path is a more "direct" route for want of a better description, to the data, and via /mnt/user which I believe hits a few other sub-systems before ultimately hitting the cahce. I wish I could help on 2) - I know nothing
 1 point
1 point -
@Kaj your guide worked. Thanks a bunch!1 point
-
Thanks for letting me know. It was literally a two line fix of a rather simple problem once I found it.1 point
-
I had the same experience after updating the UD plugin to the latest version just now. All my UD drives had been moved to history. Thanks for the quick fix you provided, it resolved the situation easily.1 point
-
when you edit the docker, click the advanced switch in the upper right. Then when you edit the docker, click the advanced view switch in the upper right. Next, you paste that line above in to the Extra Parameters spot: Click Apply, and you won't see the error any longer. I found this thread just now as I too noticed the error when looking at logs, and tried this, and it works. Cheers!
 1 point
1 point -
I had the same errors and found the comment in the below link about adding " --user telegraf:$(stat -c '%g' /var/run/docker.sock) " to the container parameters worked for me. https://github.com/influxdata/telegraf/issues/100501 point
-
Below I include my Unraid (Version: 6.10.0-rc1) "Samba extra configuration". This configuration is working well for me accessing Unraid shares from macOS Monterey 12.0.1 I expect these configuration parameters will work okay for Unraid 6.9.2. The "veto" commands speed-up performance to macOS by disabling Finder features (labels/tags, folder/directory views, custom icons etc.) so you might like to include or exclude these lines per your requirements. Note, there are problems with samba version 4.15.0 in Unraid 6.10.0-rc2 causing unexpected dropped SMB connections… (behavior like this should be anticipated in pre-release) but fixes expected in future releases. This configuration is based on a Samba configuration recommended for macOS users from 45Drives here: KB450114 – MacOS Samba Optimization. #unassigned_devices_start #Unassigned devices share includes include = /tmp/unassigned.devices/smb-settings.conf #unassigned_devices_end [global] vfs objects = catia fruit streams_xattr fruit:nfs_aces = no fruit:zero_file_id = yes fruit:metadata = stream fruit:encoding = native spotlight backend = tracker [data01] path = /mnt/user/data01 veto files = /._*/.DS_Store/ delete veto files = yes spotlight = yes My Unraid share is "data01". Give attention to modifying the configuration for your particular shares (and other requirements). I hope providing this might help others to troubleshoot and optimize SMB for macOS.1 point
-
Dieses Problem hatte ich öfter wenn rsync noch arbeitet. Und zwar trennt Unraid beim Runterfahren alle Disks. rsync schreibt aber noch und wenn der Pfad zur Disk weg ist, schreibt rsync einfach weiter, erstellt also den Ordner neu, der eigentlich vorher eine gemountete Disk war und flutet damit lustig den RAM. In den Logs erscheint dann immer wieder, dass Unraid versucht die Disk zu unmounten, was aber fehlschlägt, weil der Mount ja schon längst gelöst wurde und nach kurzer Zeit ist der RAM voll und nichts geht mehr. Aus dem Grund habe ich bei mir die Datei /boot/config/stop mit folgendem Inhalt erstellt (also "touch /boot/config/stop" ausführen und dann mit dem Config File Editor bearbeiten): #!/bin/bash # ------------------------------------------------- # Kill all rsync processes # ------------------------------------------------- pkill -x rsync Für eine Analyse ist es in deinem Fall jetzt zu spät. Für den nächsten Fall solltest du dir merken wie man laufende Prozesse anzeigen lassen kann: htop Weiteres zur Abstürzen hatte ich hier geschrieben: https://forums.unraid.net/topic/99393-häufig-gestellte-fragen/?tab=comments#comment-1008640 Du willst ja meine ich, dass Unraid die Verteilregeln anwendet. Dabei opferst du einiges an CPU Leistung. Würdest du in den Global Share Settings die Disk Shares aktivieren, könntest du direkt auf /mnt/disk1/realvideo, /mnt/disk2/realvideo usw kopieren. Dann musst du dir aber überlegen wie viel auf welche Disk kopiert werden soll. Der Vorteil ist aber, dass die CPU Last deutlich sinkt. 30 bis 50% sind keine Seltenheit, gerade beim Schreiben. Da muss man abwägen ob Komfort oder Performance wichtiger ist. Manche wie @hawihoney arbeiten deswegen ausschließlich mit Disk Shares. Ich mache beides im Wechsel, je nach Bedarf. zB schreibe ich über 10G meist direkt auf den Cache statt über den User Share zu gehen. Auch erklärt in meinem Guide unter #3: https://forums.unraid.net/topic/97165-smb-performance-tuning/1 point
-
It turns out this little script seems to do the job: #!/bin/bash DISKNUMBER="1" # Set the disk number which free space should be wiped dd if=/dev/zero of=/mnt/disk"$DISKNUMBER"/zero.small.file bs=1024 count=102400 cat /dev/zero > /mnt/disk"$DISKNUMBER"/zero.large.file sync ; sleep 5 ; sync rm /mnt/disk"$DISKNUMBER"/zero.small.file rm /mnt/disk"$DISKNUMBER"/zero.large.file unset DISKNUMBER I have just tested it in a screen session. The disk filled up as expected and then the "zero.small.file" and "zero.large.file" were deleted to free up the space back. The point of having a small file is to avoid keeping the disk completely filled too long, as it can take time to delete the large file. I hope this helps. Any improvement or remark is obviously more than welcome. OP1 point
-
Self-replying as this is now resolved and I can get a sustained 300mbit+. The solution was to add a new variable to the Syncthing docker container named UMASK_SET with a value of 000. I'm using the linuxserver.io docker image and it appears permissions were the cause of the speed issues.1 point
-
So...this isn't quite what it sounds like. Long story short, I'm giving T-Mobile ISP a shot. Mostly because there's zero data caps (you know, allegedly) and I'm getting better speeds than Comcast offered, and it's $50 a month. If I can get things running the way I want them to, it seems like a workable solution. The biggest problem is that I can't port forward or do a DMZ IP or anything. The options are there in the actual gateway config, but T-Mobile's support, which is mostly pretty good, basically says "yeah, that isn't quite implemented yet. But, you know, it will be eventually. Probably". So, that's not exactly helpful. As a general ISP user, it works fine. But I've got too many docker containers that don't work correctly without the ability to forward ports. Most specifically, OwnCloud and Plex. I'm currently sampling AirVPN, since PIA only allows one port forward. But this is where it gets complicated. Let's say I want to do OwnCloud. I can setup a port forward that gets a random port and then forwards it to 8000. OK, great. But that port forward has to come in on something that's connected to the VPN. My Windows PC doesn't really do me a whole lot of good there. I've messed with SpaceInvader One's VPN forwarding instructions, and they work, but I haven't quite worked out how to do port forwarding with IPtables yet. I figure at worst I can use SpaceInvader One's instructions on an old Zbox dual-nic machine I've got and eventually get the port forwarding working. But this seems like a really long way to go to get around this problem. Another idea that occurred is that I could take an ASUS RT-3200AC that is currently operating as just an access point, install an OpenVPN client on it, and have it as a secondary gateway out of the network. Then point the unRAID machine's default gateway to that device. Then the port forwarding would (presumably) be fairly simple. Man, the lengths people will go to give Comcast the finger. Anyone have any suggestions?1 point

































