Leaderboard




Popular Content
Showing content with the highest reputation on 05/31/22 in all areas
-
The error with "DMAR: ERROR: DMA PTE for vPFN" is also reported on the Ubuntu Bug page. Affected system: Linux kernel 5.15.0.27.30 on an HPE ProLiant DL20 Gen9 server. See here: https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1970453 With the same work around: Setting the intel_iommu=off kernel boot parameter seems to work around the problem. Also an interesting comment in the Bug Report I hit this bug upgrading my home server (proliant microserver gen9) and it seems to be causing memory corruption when it occurs ( at least in combination with zfs ). Using zfs mirrored root I experienced this issue after only a few minutes uptime, with DMAR messages flooding the log and very high CPU usage. After rebooting with intel_iommu=off things are back to normal, but a zfs scrub indicated several thousand checksum errors detected on the root volume, some of them unrecoverable that had to be restored from backup, and a separate zfs RAIDZ1 volume experienced corrupted metadata and had to be rolled back with some data loss.3 points
-
Right there with you. I just went back to 6.9.2 until this all gets sorted out. Can't say I was comfortable with the thought that I might not have data corruption. I also had a problem with My Servers that is now resolved now that I went back to 6.9.2. It was giving me an unraid-api error. Thanks and good luck to the team investigating this DMAR error situation!2 points
-
When you click 'Check for Updates" it downloads 'unRAIDServer.plg' file from our download server. When this file is 'executed' and detects tg3 present and iommu enabled it does this: echo "NOTE: combination of NIC using tg3 driver and Intel VT-d enabled may cause DATA CORRUPTION on some platforms." echo "Please disable VT-d in BIOS or pass 'intel_iommu=off' on syslinux kernel append line." echo "Alternaltely create 'config/modprobe.d/tg3.conf' file:" echo " touch /boot/config/modprobe.d/tg3.conf # if your platform is not affected" echo "or" echo " echo 'blacklist tg3' > /boot/config/modprobe.d/tg3.conf # to blacklist the tg3 driver" echo exit 1 The script only checks for existence of modprobe.d/tg3.conf file, not it's content. Hence user can choose to blacklist or not.2 points
-
AFAIK it's not possible to programmatically disable VT-d. The way the kernel initializes is based on whether VT-d is enabled or not. The current approach was taken in an abundance of caution. Going into a 3-day holiday here in the US I decided it's better for users to lose network connection (which I agree sucks) than to suffer data loss, when we know about possible data loss (that would suck even more). I've just added some code to the downloaded 'unRAIDServer.plg' file that will detect the combination of 'tg3' module loaded and VT-d enabled, and will bail out of the upgrade unless ./config/modprobe.d/tg.conf file exists. This should greatly help those upgrading but new users on affected platform will still see no ethernet. This is going to take us some time to get this fixed; probably will have to go purchase a known-affected platform. The issue is acknowledged here: https://support.hpe.com/hpesc/public/docDisplay?docId=emr_na-c04565693 Why this has suddenly happened is a mystery.2 points
-
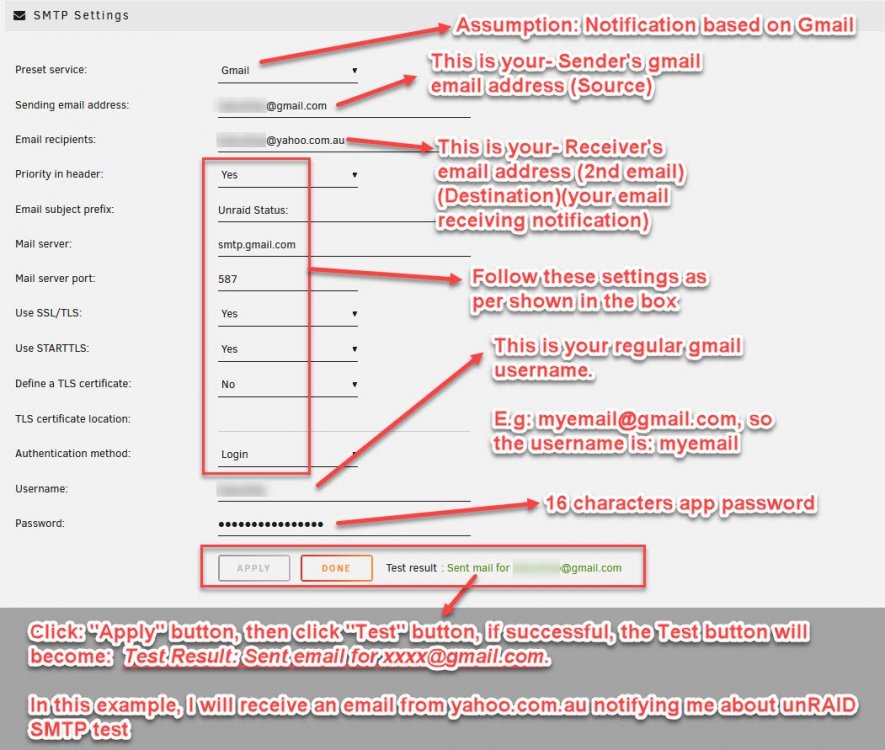
Hi All, Just want to share out my findings about unRAID notification. My notification settings are based on Gmail. This how-to will enable the user to send email notification from Gmail to Yahoo email. If you like my how-to, then make it a sticky. Thank you.🙂 ======================================================================== Requirements: A) Setup a gmail account. This account will be the SENDER's email address << Assumption: you have setup 2-step authentication via you mobile phone for logging into your gmail account >> B) Setup a second gmail or any other free webmail account. eg: [email protected] This account will be the RECEIVER's email address ======================================================================== You need to set up google App Password. 1) login into: accounts.google.com 2) Go to "Security" on your left section. 3) Under the heading: "Signing in to Google" 3.1) Click on App passwords 3.2) Sign in your normal gmail accounts 3.3) click: Select app, then select: Mail 3.4) click: Select device, then select: Custom 3.5) Give a name for the unRAID server e.g: midtowerunraid 3.6) Press Generate button 3.7) A window will pop out and app password for the device is display in the yellow box. Copy the password and keep in a safe place and save in notepad. This password is 16 character long. Next click the button: Done e.g: sskwowcomemtyufg <----- 16 character long app password. 3.8) Finally sign out all accounts Follow the steps below, to complete SMTP settings within unRAID server
 1 point
1 point -
Overview: Support for Servas Docker Container Application: Servas - https://github.com/beromir/Servas Docker Hub: https://hub.docker.com/r/beromir/servas GitHub: https://github.com/beromir/Servas Documentation: https://github.com/beromir/Servas For Any Non UnRaid related question please go to projects Home This is not my project. I just created the template. All credits go to: Beromir Description (from Dev): A self-hosted bookmark management tool. Servas is based on Laravel and Inertia.js and uses Tailwind CSS and Svelte for the frontend. It still needs a lot of work but developer is active and available at github Requirements: MySQL / Mariadb Database already running and available. Create a User and DB for servas on your MySQL/Mariadb Instance. Created config file (filename is : ".ENV" just a dot plus env ) and place inside servas config folder (/mnt/user/appdata/servas/) the content as follow: APP_NAME=Servas APP_ENV=production APP_KEY= APP_DEBUG=false APP_URL= DB_CONNECTION=mysql DB_HOST=**** Enter IP/Hostname of mysql/mariadb **** DB_PORT=3306 DB_DATABASE=**** name you assigned to servasdb ex. servasdb **** DB_USERNAME=**** username allowed to access servasdb **** DB_PASSWORD=**** password for user allowed to access servasdb **** Once Container is running open the container console run the following 2 commands one at a time: php artisan migrate php artisan key:generate Restart container and you should have acces to WebUI at port:8086 go to http://UnraidIP:8086/register to create a user.
 1 point
1 point -
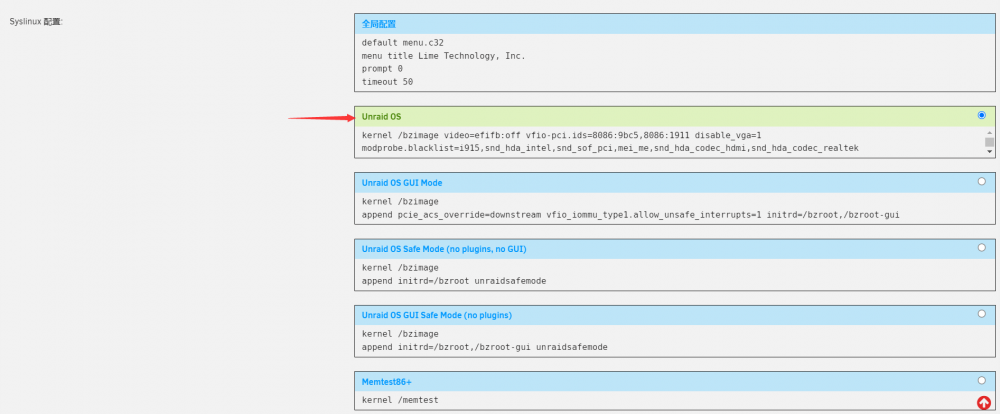
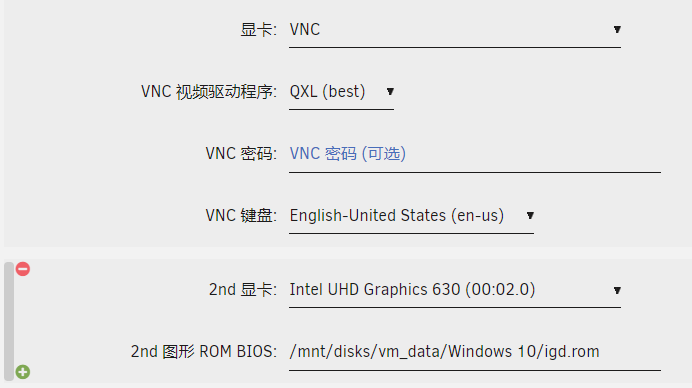
纵观整个论坛,尤其是简体中文板块,几乎没有类似的解决方案,即便有也是比较旧的了。 本文基于 UNRAID 6.10.0-rc2 版本演示,实际上 6.9.2 也是可以的,不过只有在 6.10.0-rc2 中才有对 Windows 11 的完整支持,如果需要安装 Windows 11 建议也升级至 6.10.0-rc2。 大前提:BIOS中打开了Intel vt-x和vt-d(AMD端应该叫AMD-V和IOMMU),并且设置 IGD 为第一显示设备(也就是 BIOS 之类的默认从核显输出),且需要至少一个显示器连接到主板上的视频输出端口(也可以是欺骗器,总之需要系统识别到)。 1. 直通核显 实际上直通核显和独显并不严格要求顺序,如果对独显的直通没有信心,也可以先做直通独显。直通核显应该算是最难的了,建议先整(整不好可以直接劝退了哈哈哈) (1) 进入MAIN→Flash→Syslinux configuration→Unraid OS (中文版是主界面→Flash→Syslinux 配置→Unraid OS,看到右边绿色的那个框就对了) 内容替换为: kernel /bzimage video=efifb:off vfio-pci.ids=8086:3185,8086:3198 disable_vga=1 modprobe.blacklist=i915,snd_hda_intel,snd_sof_pci,mei_me,snd_hda_codec_hdmi,snd_hda_codec_realtek append initrd=/bzroot 其中,vfio-pci.ids=8086:3185,8086:3198 这一段,不同的CPU和主板都有所差异,以我的为例是: 有些CPU第二个设备是音频输出,其实都随意吧。这里试错成本也比较低,搞错了大不了再来一次( 至于如何查看,可以先看第三点的地方。 (2) 进入 SETTINGS→VM Manager→ADVANCED VIEW (中文版:设置→虚拟机管理器,然后点一下右边的高级视图) 设置如下属性: PCIe ACS override: Downstream VFIO allow unsafe interrupts: Yes 中文版如图所示: (3) 前往TOOLS→System Devices (中文版:工具→系统设备) 把刚刚填的vfio-pci.ids对应的设备勾上即可。 (4) 重启主机,新建虚拟机,配置要求如下: Windows 最好使用 i440fx,Linux 最好使用Q35,都选最新版本。 其中,VNC 必须先行保留,因为显卡可能还驱动不起来,需要用 VNC 装系统。等装完系统,驱动程序也会自动安装,到时候可以将第一显卡设为核显,不需要保留 VNC。图形 ROM BIOS 需要从这里下载:https://github.com/my33love/gk41-pve-ovmf,并且放在自己知道的地方,把路径填到该选项中。如果不指定图像 ROM BIOS,大概率是无法正常输出视频的。貌似 Intel 核显都可以用这个,所以不需要查型号了,如果有不可用的情况请回复到帖子中。 其他的设置根据自己的喜好或者用默认设置即可。 (5) 启动虚拟机,安装系统,最后等 Windows 自动安装驱动即可。如果使用 Windows 8.1 及以下操作系统,大概率是需要自己手动下载驱动程序的(而且不一定有兼容低版本操作系统的驱动程序),所以还是建议直接 Windows 10 或 Windows 11。 核显部分就到这里,接下来是较为容易的独显部分。 2. 直通独显 这一部分没有太多讲究,也可以完全不按我的步骤来做,不过为了确保尽可能一次成功还是按步骤来做。 (1) 前往TOOLS→System Devices (中文版:工具→系统设备) 将显卡对应的框勾上,例如: 可能会有很多子设备,但是没关系,一般来说不需要配置它们,让它们自动勾上就行了。(如果需要声音输出可以在声卡一项选择) (2) 创建虚拟机,配置随意,但是 BIOS 最好选 OVMF/OVMF TPM。 显卡选择跟核显的差不多,不过图形 ROM BIOS 一般来说可以留空,但是部分显卡可能无法正常启动或者驱动报43错误,这种情况下就需要整 vbios 了。由于感觉比较麻烦(需要一个打好驱动的物理机系统,用GPU-Z导出vbios,也许还需要小小修改一下),我这里就放弃了一些显卡。不过至少我的 GTX 1660 SUPER 还是可以正常驱动的,就不需要指定了。(GT 740 无法驱动,懒得整了) (3) 启动虚拟机,安装系统,安装独显驱动,然后看看设备管理器的显卡设备有没有叹号,没有的话就大功告成! (如果有的话,慢慢折腾吧,我也帮不了你)(尤其是万恶的43错误) 那么核显和独显直通的分享就这么多了,希望能够帮到初入 UNRAID 的大家。我大概花了3天来解决这些问题,期间还更换过方案,最终还是定下核显+独显的方案(主要还是考虑到 PCIe 以后的分配问题),虽然在论坛里问了但是并没有人理我(哭哭),最后也是按着外面的教程一步步试错,最终总结出这样的步骤。当然也会有按我的步骤不行的人,我希望能够多多探讨,而不是直接丢下一个“没用”就拍拍屁股走人了,如果你真心想说这话的话,我建议你还是直接关掉这个帖子吧,此贴不适合这类言论。 参考: https://www.right.com.cn/forum/thread-6006395-1-1.html https://github.com/my33love/gk41-pve-ovmf https://post.smzdm.com/p/ag8l254m/



 1 point
1 point -
Is anyone else having this problem? I checked on my backup server at another site and same problem.1 point
-
Unless you manually change the mount point, UD will use a default mount point it puts together that can change. Once you manually change the mount point, it will stay committed to that mount point and not change again. Due to some changes lately (probably from udev, not UD), the default mount point changed on some devices.1 point
-
The drive showing signs of failure isn't new, it's got 44k power on hours, I'd replace it if I were you if it's still needed1 point
-
Thank you, I was able to get it upgrade to 6.10.2 after creating tg3.conf1 point
-
Please post diagnostics.1 point
-
It's been a while since I've looked at the MD boxes, but per this guide (https://downloads.dell.com/manuals/common/MD_1200_MD1220_Reference Guide_EN.pdf) the last page indicates a maximum chain of 4 MDs is supported. Now, I'm sure more than that will work - 4 is only what Dell will officially support - but it would explain what's happening here.1 point
-
Yes, but you need to manually resume the preclear. When you start the preclear, you will see a choice to resume preclear where it left off.1 point
-
I couldn’t find what you’re referencing, but I only skimmed. Using presets did work for me, server hasn’t had any issues so far, but they override the other files, which I found out. Sent from my iPhone using Tapatalk1 point
-
Just repost there.1 point
-
What I'll do : * replace controller card from broadcom to LSI * upgrade disk4 (I was planning to upgrade disk3 as it's the smallest / nearly full but let's do that ) I'll keep you posted. Do you prefer that I mark your proposal as "solution" or do we wait for the hardware?1 point
-
So I got it working. I found that KVM already had AMD extensions and nested Virtualisation enabled: root@primary:~# modprobe -r kvm_amd modprobe: FATAL: Module kvm_amd is in use. root@primary:~# systool -m kvm_amd -v | grep nested nested = "1" root@primary:~# Enabling the nested module did nothing (As expected): root@primary:~# modprobe kvm_amd nested=1 root@primary:~# I've had issues with this before, because I remember last year I enabled Docker extensions in Visual Studio Code and bricked my VM (Restored from nightly backup so no big deal) but I never tried that again. So I checked my VMs, and per advice around the forums I added the vmx CPU flag: <cpu mode='host-passthrough' check='none' migratable='on'> ... <feature policy='require' name='vmx'/> ... </cpu> ...and started up my VM, installed Hyper-V and Docker and got it running in WSL2. No errors in Device Manager were seen. I didn't even need to reboot because the nested extensions were enabled. For good measure, I downloaded SpaceInvaderOne's script and enabled it (And fixed it because there is an error in there on line 20), but it is mostly redundant because the extensions are already enabled. Still, gives me a little more control if I want it in future. I have to say though, the performance took a hit. I've seen reports that SeaBIOS is more performant, but I'd rather stay with OVMF if I can. Just looking at Task Manager was a big oof! I'm going to have to assign more resources to this VM! Thanks for all your help!
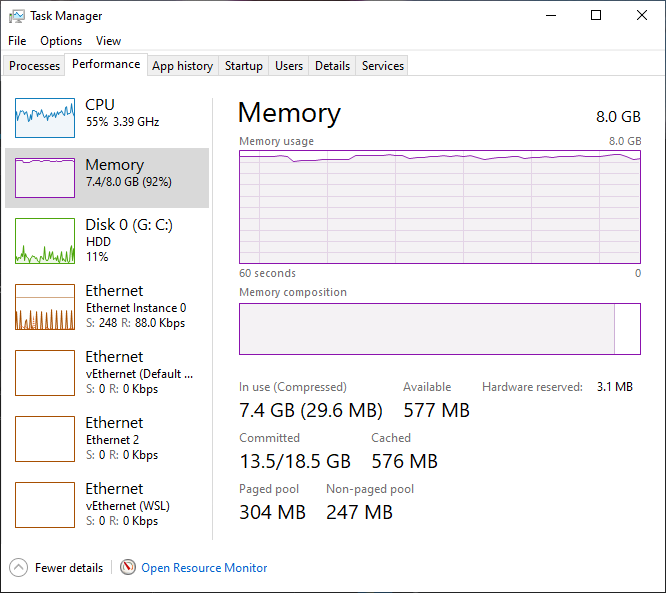 1 point
1 point -
Still Learning and appreciate the input. thank you1 point
-
Thank you very much for this template, love the service! As a note, you could add all the required variables in the same template, so you won't need to edit the '.env' file. Also, it supports the use of Redis, which makes it faster.1 point
-
Just to add to this - and I don't want to jynx myself - but I have run a scrub and a parity check and both come back fine (54TB array... phew!) .. I am running Gen8, Xeon CPU E3-1240 V2, VT-D was enabled. Either way thank you @JorgeB for your help and advice.1 point
-
YES,Master
 1 point
1 point -
Good find, looks like the exact same issue.1 point
-
It can be 2 things: 1. bios bug: errors come from acpi tables, if the bios is bugged you can have that errors (you have bios 1.1, latest version should be 1.2, if you are confident you could try an update) 2. kernel bug/outdated: it may be fixed one day with a kernel update _CPC is continuous performance control related tocpu: with cpc enabled the system will use for amd cpus amd-pstate function, otherwise it will fall back to acpi legacy P-states. On intel it enables futures like speed shift (p-states) without consulting acpi. Having that errors should not compromise at all your experience.1 point
-
OK It works now ,thanks. but still wish the plugin support checkpoints.1 point
-
Currently CRIU is not delivered with my plugin and I'm not sure if I will add it but the possibility is there. You can of course run: lxc-snapshot CONTAINERNAME to create a snapshot from the whole container but keep in mind you have to first stop the container! After that you can list the available snapshots with: lxc-snapshot CONTAINERNAME -L I hope that helps for now.1 point
-
Thank you very much, I have found it now. I didn't realise that the folders were hidden.1 point
-
& @brain:proxy Which file did you edit or better speaking in which location, please read the description from the container where the files are located. I am able to change the clan size to eg 6 on my server. Also make sure that you stop the server first, edit the file and then start the server again.1 point
-
besides the issues now with the plugin, here @ich777 can rather help out, you know your GT1030 cant do any transcoding as it doesnt have any NVENC options ? its a nice desktop card for office or multimedia playback ...1 point
-
I understand you feel comfortable and have various methods that you have used to do this restore procedure and it seems simple. I am simply giving you my feeling as someone who is a non expert and I feel my experience is both valid and possibly even shared with other users who are also in the same non expert position I am in. However I will also leave it at that. If you are happy with how the update rollout is going and that there is no need to improve the situation then I am happy to leave it to you guys and just get the all clear when its safe to upgrade. Not being mean or anything I really am happy to chill out and just get told when to jog on and hit update. It doesnt phase me and I dont feel any need to be combative about any of it if thats what people like. Peace1 point
-
It works for me my 1950X, has been working for about 12 months now. Steps were something like: unraid: backup vm (if nested doesn't work properly, vm will brick) unraid cmd: modprobe -r kvm_amd unraid cmd: modprobe kvm_amd nested=1 unraid: reboot win10 vm: install wsl2 (and associated restart) win10 vm: install docker desktop Performance was crap for me in 6.9 when nested virt was enabled, but perf got a lot better in 6.10 (but this may have been my other dockers being ram hogs during 6.9 time)1 point
-
If the system does not boot it is not as easy as unplugging a stick and plugging in the cloned stick, regardless of how easy it is claimed to be. Unplugging one thing and plugging in another thing is literally going to be the easiest conceivable option in a disaster situation where your entire network is down with no internet because the single device that homes everything is down. Just saying. That is why enterprise equipment has a flash and a backup flash for example and you can select which flash to boot up from when it starts up eg like netgear switches and whatever else has a duel boot type thing. I think even some home motherboards have like a duel boot bios thing. Same reasoning. Its just how other people solve a problem with 100% guarantee rollback since its a different chip being relied upon, or different flash boot. Or different cloned stick. I feel you have to go the extra mile to reassure people that rollback cant fail rather than just be like ‘yeah you read these instructions and its super easy to follow if something breaks’ as this has an element of user needing not to be an idiot like me to complete the task correctly. Its also a time element. Follow instructions = time. Unplug one thing and plug in another thing = 30 seconds. Very different scenario in a time sensitive window.1 point
-
(Not sure if we can just be candid and post our thoughts but assuming its ok). been thinking that I am unsure if my worries are unfounded but perhaps if people avoid upgrading due to the process being considered a possible risk then it could be the case that not a lot of people actually try the RC versions of releases as a result. This might make limetechs job difficult when releasing a new version. Maybe we as the members in the unraid community should try to form a beta testing task force that would or possibly could assist limetech if it worked within constraints they provided. At the moment my impression (which could be incorrect) is that its more of a passive testing. As in, the RC release is posted to the forum and anyone can feel like trying it out and providing feedback. This passive testing might not be as effective as say a committed group of like 100 people who pledge to update and will email their logs, along with hardware info that is relevant, for limetech to review even if no real issues are detected at all. This provides many different real systems both with or without issues to compare and for them to look at. The other problem is many of us (like me) might not know what errors to really look for even of things appear to be working in the short term but a once over from limetech might uncover inconsistencies in logs we dont fully appreciate and provide a more active ‘search and identify’ type beta testing path. if something like that was desirable then im sure a bunch of us could get together and step up to commit to testing RC versions and giving any info and logs to limetech to review. Pretty sure as long as there was a semi reasonable way to revert in case of a non bootable or unusable system then a lot of people could pledge to commit to testing. Might be like a fun thing for a group of us to get together and do not sure what other people think Im just saying we all hang around the forums anyway. If everyone disagrees thats ok too I was just saying what came into my head. Im not telling anyone what to do.1 point
-
I ordered a $15 NIC and installed it and it fired right up. That other NIC can suck it. LOL Thanks for ther help all.1 point
-
has anyone been able to change the clan size in v-rising? I changed the setting in the servergamesettings.ini and restarted the docker but the server is stuck on 4 player clans1 point
-
The biggest advantage is performance. I've been able to get north of 1.1m IOPs out of mine, something thatd be nearly impossible with any btrfs setup. The disadvantage though is that if one simply dives into zfs without doing any tuning (or worse, just applies something they read online without understanding the implications), they're likely to end up worse off than they would've with virtually any other filesystem/deployment.1 point
-
UPDATE v1.5 (2022-05-31) - New: Added APP_NAME, SECURE_CONNECTION, UMASK, VNC_PASSWORD variables. - Other: Changed backup paths (TO/FROM) to more convenient ones, placing them under a single directory: '/data/*' in the root of the container. - Other: Other minor changes on the template.1 point
-
After reading this forum post I am now too scared to update unraid. Very worrying if we are between no network or possible data loss after an update. The update procedure is already very much a risky process at times since cloning a usb stick means the original is blacklisted so reverting back is not easy (as the cloned stick is useless) and now we are heading into territory where specific hardware can cause catastrophic service impact on things as simple as a NIC. Obviously not trying to say anyone is to blame nor suggest I have a better solution to the problem but as a user of unraid I can see how this would cause reactions I am seeing on the forums. It is very much a product that encourages consolidating many services onto one dedicated box, so when that service is broken, it can be multiple different parts on the network affected, NAS, DHCP, DNS, Web services etc etc etc. I feel like not everyone is a forum user and this could be better communicated or something into the update procedure could be implemented like a "known issues tick this box to proceed the upgrade" type thing where when you update it says "some users may lose connectivity, click I agree here to accept this and continue the update and agree you have read what to do if this affects you (link to instructions here) or something. (Not claiming this is the best solution just saying what came into my head upon reading this).1 point
-
I've just replaced all the cables in the server, looks good so far 👍1 point
-
Dell r720xd affected aswell1 point
-
I don't know if that's possible, but if it is, yes, I agree it would be better.1 point
-
Watching from the sideline because my Gen8 still has its original non VTd-capable Celeron processor, but wouldn't a better solution be to disable VT-d automatically via syslinux.cfg when the problematic configuration is detected instead of disabling the NIC? It would still take some users by surprise, of course, but at least they'd still be able to connect to their servers.1 point
-
same, updated remotely then discovered that remote not working anymore connected a display locally to the server and boot with gui I found that the bonding was set to "Yes" in network setting which resulting network failure, I have to : manually set the Bonding of eth0 to "No" > apply click "port up" of eth1 > apply reconfig both network cards done currently work great after reconfiguration1 point
-
English is not my native language but: Maybe you missed it.1 point
-
not good?did you read the first post/changelog before update? It seems you have an issue with your caps lock.1 point
-
***Data Corruption possible with tg3 driver when Intel VT-d is enabled.*** Cloud this not have been mentioned in the changelog as a warning? Or noted more clearly on there? Not everyone goes to the forum prior to updating! I did read the Change log, but there is no mention of this in the Change log which is shown on the server! And as I am not reading the Beta forum every day: I have a HP MicroServer Gen 8 with a E3-1265LV2, and had a very nasty suprise of a server which was unreachable with the error "ETH0 Not found".1 point
-
I can confirm that I experience this issue as well. Haven't found a workaround beyond doing a backup/restore of my appdata folder. Not entirely sure why it happens.1 point
-
Hi all, any chance of a mobile friendly ui being implemented? Current experience on mobile is terrible.1 point
-
use "docker ps -s" to see where the usage is, and then figure out how to clean it up. mine was in pydio: # docker ps -s CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE 2d6bc0931a8c limetech/plex "/sbin/my_init" 3 weeks ago Up 6 days PlexMediaServer 377.3 kB (virtual 557.3 MB) ad63faa6b9f5 linuxserver/letsencrypt "/init" 4 weeks ago Up 6 days 0.0.0.0:1180->80/tcp, 0.0.0.0:11443->443/tcp letsencrypt 624.1 kB (virtual 180.2 MB) e22be497a65d linuxserver/rutorrent "/init" 4 weeks ago Up 6 days 0.0.0.0:51413->51413/tcp, 0.0.0.0:6881->6881/udp, 0.0.0.0:51444->51444/tcp, 0.0.0.0:10080->80/tcp rutorrent 4.924 MB (virtual 123.9 MB) c717743877a1 linuxserver/pydio "/init" 5 weeks ago Up 6 days 80/tcp, 0.0.0.0:33443->443/tcp pydio 58.47 GB (virtual 58.66 GB) 83792be00581 linuxserver/mysql "/sbin/my_init" 5 weeks ago Up 6 days 0.0.0.0:3306->3306/tcp mysql 796.8 kB (virtual 533.7 MB) 655e33471cbe linuxserver/sonarr "/init" 6 weeks ago Up 6 days 0.0.0.0:18989->8989/tcp sonarr 22.27 MB (virtual 528.1 MB) 7088b4c76ff3 linuxserver/couchpotato "/init" 6 weeks ago Up 6 days 0.0.0.0:15050->5050/tcp couchpotato 18.56 MB (virtual 164.1 MB) b1aa37b16af1 linuxserver/jackett "/init" 6 weeks ago Up 6 days 0.0.0.0:19117->9117/tcp jackett 12.13 MB (virtual 510.9 MB) 4776efea5f09 linuxserver/plexpy "/init" 6 weeks ago Up 6 days 0.0.0.0:18181->8181/tcp plexpy 89.75 MB (virtual 324.2 MB) da4cf5fb541d linuxserver/plexrequests "/init" 6 weeks ago Up 6 days 0.0.0.0:3000->3000/tcp plexrequests 43.48 MB (virtual 373.4 MB)1 point




































