Leaderboard



Popular Content
Showing content with the highest reputation on 09/20/22 in all areas
-
2TB 2.5" drives will be SMR, what brand/model? Some SMR models, particularity by Seagate performe decently, SMR drives by Toshiba or WD can have several minutes writing below 5MB/s, even when doing sequential writes.2 points
-
EDIT: As of 2023-02-26 few years active use this solution is confidently stable. Not a single stale and no problems encountered. The Issue and cause When SMB share is mounted to Linux you sometimes might encounter mount hanging and you get error stale file handle. Something in terms of: cannot access '/mnt/sharename': Stale file handle This is caused by file being stored into cache and then moved into another disk by the Mover. The file inode changes and client gets confused because of it. I suspect it could also happen when file moves from another disk inside array, but have not confirmed that and it would be fairly rare issue. Solutions gathered (only one required) Disabling the cache or mover are ways to solve this. However not very practical for many people as it takes away a feature. Disabling hardlinks also fix this problem from occuring. However it also disables hardlinks from whole system. Generally this isn't huge problem. Only certain apps require it and still kind of work with it disabled. Change SMB version to 1.0 at client side. This has some problems as well, such as exposing server to security problems coming with the 1.0 version. It also has some performance problems and lack of features compared to v3. Now for PROPER fix. Key is to add noserverino to mount flags. This forces client to generate its own inode codes rather than using server one. So far I have not noticed any problems by doing this. I can not replicate the issue with this method and I have hardlinks enabled (not required) and SMB v1 disabled (not required). How to replicate the issue Create a file to share that has cache enabled (not prefered). Browse into that directory inside the mount using /mnt/user path Enable the mover Witness the stale file handle error Ramblings Also I found many different variations for the full mount flags and here is what I use: //192.168.1.20/sharename /mnt/sharename cifs rw,_netdev,noserverino,uid=MYLOCALUSERNAME,gid=users,credentials=/etc/samba/credentials/MYLOCALUSERNAME,file_mode=0666,dir_mode=0777 0 0 Let's go thru the mount flags. I'm using these knowing that posix extensions are DISABLED. With them enabled, you might want to use different flags, especially about permissions. Feel free to change them as you like, the noserverino is the ONLY required one. rw - This is just in case and it enabled read/write access to mount. Might be default anyway. _netdev - Makes the system consider this as network device and it actually waits for networking to be enabled before mounting. noserverino - Client generated inodes (required for the fix) uid/gid - These are optional. It makes the mount appear as like its owned by certain uid. Inside the server nothing changes. I'm using these because files are owned by the nobody/users and I can't open files. There is also noperm flag etc. you could use. I just find uid and gid most practical. credentials - This is a file containing username and password for the share. This is just so that people can't see my password by reading /etc/fstab. For more reference how to set this up https://wiki.archlinux.org/index.php/samba#Storing_share_passwords file_mode/dir_mode - These are optional. These make files appear in share as 0666 and 0777 permissions, it does not actually change permissions at server side. Without these the file permissions are not "in sync" and appear wrong in the client side. Such as 0755 directory permissions while it is 0777 in server. Posix/Linux/Unix extensions (not related to stale file handle) Problem I have not been able to solve is how to enable Posix/Linux/Unix extensions. When I try to enable the extensions it errors out saying that server does not support them. Inside samba config in unraid there is unix extensions = No. However turning this Yes in many ways did not enable them. Why this matters? Well those extensions enable certain nice features that makes the share appear as proper linux drive. To confirm that unix extensions are not enabled: mount | grep "//" in the flags you see nounix flag. To enable unix extensions manually add unix to flags. However during mount you get an error and reading dmesg shows you that it reports server not supporting unix extensions. NFS For NFS I still have no real solution other than disabling hardlinks.1 point
-
never mind figured it out: https://github.com/get-iplayer/get_iplayer/wiki/record#pid1 point
-
Did you update via the roon client or will this require an update via docker? Very interested in ARC 2.0 but want to make sure I update properly. Thanks!1 point
-
Not that I'm aware of, but if you use your array like a vast majority of people, it shouldn't hurt you too bad once you get your data loaded, read speeds should be fine, and once your writes are limited to daily updates you can let mover take care of things when you're not actively using the array. Typical Unraid use is a WORM style, with daily updates being relatively small.1 point
-
Thanks all for the feedback. I'm upgrading to 8-16 GB RAM. Honestly I though I had more than 2 GB. Just shows how old these servers are. 😮1 point
-
shame on me apparently one should not activate both adapter when only one is really connected switching is really fast now. sorry for your troubles!1 point
-
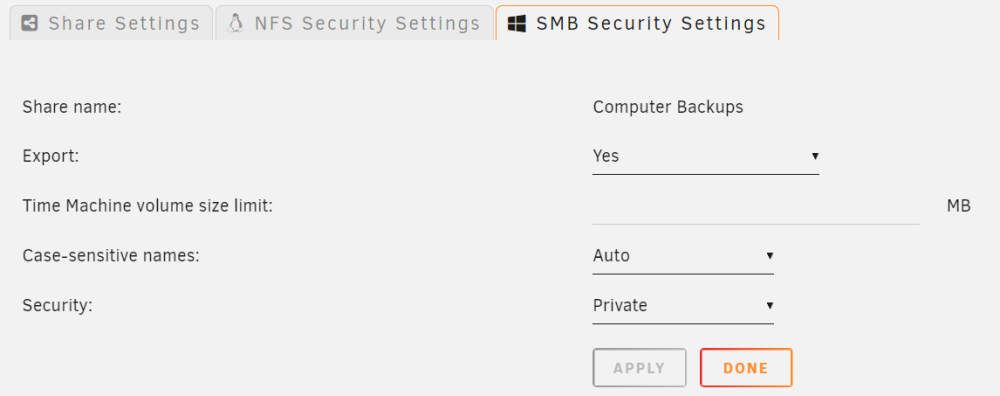
That's not an appropriate way to do the MacOS settings. The vfs_ojects can be overwritten by a plugin - the Recycle Bin will eliminate the vfs_objects when it does it's work when you do it this way. Read the first post on how to copy the smb-fruit.conf file to the flash device and how to make changes there that will be applied correctly to the Unraid shares. In the next rc there is a share setting for time machine volume size limit:
 1 point
1 point -
https://www.kernel.org/doc/html/latest/admin-guide/kernel-parameters.html search split_lock_detect i guess ill try both when i have a chance at rebooting and see which one works1 point
-
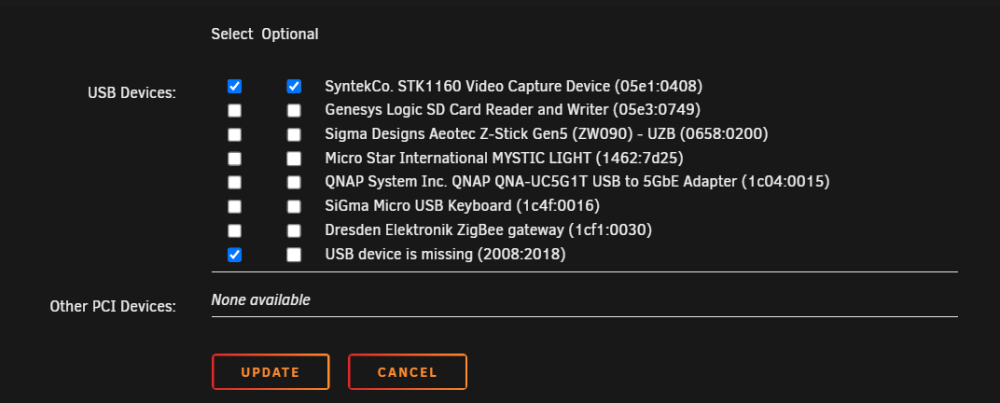
Followed your suggestion and this has now been merged so will appear in the next RC.. Also includes support for missing USB devices so people can change to optional or remove.
 1 point
1 point -
Is this a public facing server? Do you have issues with other plugins updating or installing? I ask this because that IP returns a hostname and visting that IP in the browser returns a NGINX page. You mentioned china. I am not completely sure how they handle NAT and proxying but is it possible you are sharing that IP with multiple households and that might be why you are getting that error. But if both those questions are no then that assumption is wrong.1 point
-
Hello JorgeB, Your guide helps me to solve it. My solution was to disable C-States globally on bios. I didn't find any power supply idle settings, so that was my solution. Thank you!1 point
-
i will try when i at home then reply here1 point
-
Clear.1 point
-
These days, you are. There was a time where every computer case needed space a floppy drive, an optical drive, and one or more spinning hard drives. With the introduction of cloud storage, M.2 NVMe and USB 3.0, both home and corporate systems no longer need a large case to hold everything. Even where I work, many who aren't using a laptop for everything have NUC sized systems as their "desktop" system. The demand for cases that hold a half dozen or more drives has decreased, and likely will continue to do so. A system to hold a large amount of data for multiple users or archival purposes is a server. A market remains for server systems, and the cases available reflect where demand is - new builds with server hardware. DIY raid systems such as Unraid, et al, came about when server hardware was terribly expensive and difficult for the average person to obtain, and used consumer grade components (many which people already had on hand) to replicate servers costing 10 times as much. These days, the price difference is much less.1 point
-
Not quite following, you cannot start the array with 2 missing disks and single parity, it's also not possible to start the array in read-only mode, if there's something you need now you could mount the disk(s) individually with UD in read-only mode just to access the data, if you do a new config without the missing disks and start the array parity will be invalid and it would prevent future recovery if you fix one of the missing disks. Yes, you'd need to new another new config, add new disk(s) and re-sync parity. See here for a recent example: https://forums.unraid.net/topic/128492-multiple-disabled-disks/?do=findComment&comment=11705171 point
-
No, but you could mount the disks individually with UD in read-only mode. Yes, manually, but yes. Tools -> New config - create a new array without the missing disks and re-sync parity.1 point
-
Ich will nur das die User wissen das sie das nur tuhen sollten wenn sie sich der Risiken bewusst sind. Wenn dieser Schalter angeschaltet wird ist es so als ob du direkt auf Unraid arbeitest da du praktisch vollen Zugriff auf das Hostsystem erteils und dies ein wirklich, wirklich, wirklich großes Sicherheitsrisiko darstellt.1 point
-
thanks for your reply ,wait for better message;1 point
-
update again, i think ive solved the problem, it was either the motherboard or cpu....im leaning towards the motherboard but i wont know for shure witch it was as i just went the full send method and swapped both mobo and cpu at the same time for 2 reasons, 1 i didn't really want to have to take the system apart twice or more figuring it out, and the last 3 times i changed the mother board (first was due to incompatibility with something, i don't remember what. the second was a motherboard that refused to boot to the usb after a bios update, and the third was just to add more functionality by adding nvme drives for cache drives instead of 2.5 ssds) i only changed the motherboard, not the cpu, and since i put this system on ryzen nearly 3 years ago now i upgraded the cpu after a year, but it only got the one i took out of my gaming rig when i upgraded it. so i figured it would probably be best to just put both a brand new cpu and mobo in at the same time to save time at the expense of not knowing witch part was bad. i will find out next week if it actually was the cpu/mobo or just a fluke it happened to finish the parity sync this time seeing as it got above 90% in safe mode on the old cpu/mobo before crashing.1 point
-
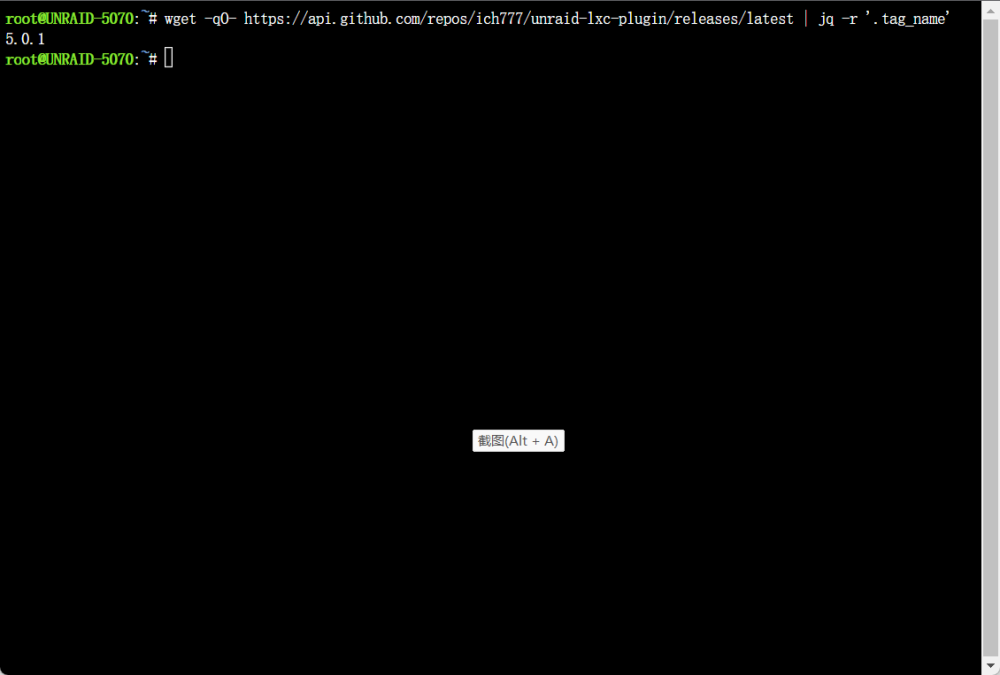
from china , but network is ok image is the out put;
 1 point
1 point -
@VideoVibrations Appreciate it! I wont be using it for plex (no plex pass), but i will be using it for Tdarr.1 point
-
yes it did.1 point
-
I've seen this and the solution was to clear the browser cache. Worth a try.1 point
-
This is fixed in next release...1 point
-
Thank you for the clear explanation. This makes sense now. My hope is to get a motherboard with 8 SATA connectors and to never go beyond that amount of hard drives so a RAID card would never be needed. I have sort of a JBOD card now that I'm hoping to get rid of. Thanks again for clearing it up.1 point
-
Start here: https://forums.unraid.net/topic/46802-faq-for-unraid-v6/?do=findComment&comment=8191731 point
-
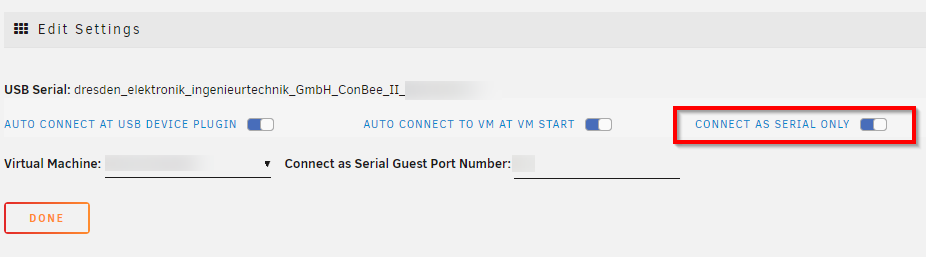
I followed instructions given by SimonF. I use USB manager but did not know that new feature has been added to pass device to VM in serial mode. So instead of modifying XML file, all you need to do is: 1) install USB manager plugin 2) Do not attach any device in the VM properties. Instead go to USB manager menu, locate the device you want to pass to VM, and click on device settings here: 3) Enable "connect as serial only" You can also select auto connect if you want to. Side note - if you did pass the device via USB manager before, then you probably did not use serial only mode. By checking this, mode will change. 4) Shut down your VM and start it again, it should attach device to your selected VM in serial mode: Once that is done, all you need to do is change the path to device. I use Z2M - in Z2M configuration, I just changed path from /dev/serial/by-id/conbeeXYZ to /dev/serial/by-id/qemuXYZ That is it. My Zigbee network works without any additional intervention needed, and I successfully upgraded to 6.10.3 More info can be found here as well: https://community.home-assistant.io/t/solved-conbee-2-fails-to-connect-to-zha-ha-in-unraid-vm/431276/8 One user reported that if you are using ZHA instead of Z2M, you need to change the config (within the VM terminal) to ~/config/.storage/core.config_entries and provide new device path

 1 point
1 point -
Is there any fix for this besides the manual fix in advance settings mentioned here, like is this a bug or what? My dockers on other VLAN worked before with no issue until today...1 point
-
No need to apologize! DEFINITELY appreciate the work you've done! I was probably a bit too discerning myself. I've just seen soooo many apps on CA sit there in various states of functionality (even 'Official' ones) so I kind of soapboxed a bit. This thread was probably the wrong place for it. Your work here is great and I actually use your contribution for Homarr in CA every day! Cheers1 point
-
1 point
-
Folks, I'm currently maintaining the it87 driver that is now being pulled into your systems, and the current version supports the following chipsets: IT8603E, IT8606E, IT8607E, IT8613E, IT8620E, IT8622E, IT8623E, IT8625E, IT8628E, IT8528E, IT8655E, IT8665E, IT8686E, IT8688E, IT8689E, IT8695E, IT8705F, IT8712F, IT8716F, IT8718F, IT8720F, IT8721F, IT8726F, IT8728F, IT8732F, IT8736F, IT8738E, IT8758E, IT8771E, IT8772E, IT8781F, IT8782F, IT8783E/F, IT8786E, IT8790E, IT8792E, Sis950. If you are have any of these chipsets, then you don't need to specify the "force_id" option any further. If you do find you need it please contact me and I'll look at adding any missing chipsets, but it will depend on what details I can find. Unfortunately, for some motherboards, which have multiple chipsets on board, you will need to add the option "ignore_resource_conflict=1" option, in place of the option "acpi_enforce_resources=lax" during the modprobe command, e.g. for similar reasons, although it only affects the it87 module not others. Good luck with the use of this module that various people have been improving over the years.1 point
-
Those issues are being worked through with newer versions. Since you don't list what you are having problems with, I can't point you to the solutions. Out of date software is becoming more and more vulnerable to exploits with each day, if you let your systems access the internet you need to stay up to date. The other option is to continue to use older software and remove internet access to it. Since the my servers plugin services are based around internet access, it doesn't make sense to attempt to keep it running on vulnerable systems.1 point
-
Version 6.11.0-rc5 2022-09-12 Bug fixes Ignore "ERROR:" strings mixed in "btrfs filesystem show" command output. This solves problem where libblkid could tag a parity disk as having btrfs file system because the place it looks for the "magic number" happens to matches btrfs. Subsequent "btrfs fi" commands will attempt to read btrfs metadata from this device which fails because there really is not a btrfs filesystem there. Base distro: cracklib: version 2.9.8 curl: version 7.85.0 ethtool: version 5.19 fuse3: version 3.12.0 gawk: version 5.2.0 git: version 2.37.3 glibc-zoneinfo: version 2022c grep: version 3.8 hdparm: version 9.65 krb5: version 1.19.3 libXau: version 1.0.10 libXfont2: version 2.0.6 libXft: version 2.3.6 libdrm: version 2.4.113 libfontenc: version 1.1.6 libglvnd: version 1.5.0 libssh: version 0.10.4 libtasn1: version 4.19.0 mcelog: version 189 nghttp2: version 1.49.0 pkgtools: version 15.1 rsync: version 3.2.6 samba: version 4.16.5 sqlite: version 3.39.3 Linux kernel: version 5.19.7 CONFIG_BPF_UNPRIV_DEFAULT_OFF: Disable unprivileged BPF by default CONFIG_SFC_SIENA: Solarflare SFC9000 support CONFIG_SFC_SIENA_MCDI_LOGGING: Solarflare SFC9000-family MCDI logging support CONFIG_SFC_SIENA_MCDI_MON: Solarflare SFC9000-family hwmon support CONFIG_SFC_SIENA_SRIOV: Solarflare SFC9000-family SR-IOV support patch: quirk for Team Group MP33 M.2 2280 1TB NVMe (globally duplicate IDs for nsid) turn on all IPv6 kernel options CONFIG_INET6_* CONFIG_IPV6_* Management: SMB: remove NTLMv1 support since removed from Linux kernel startup: Prevent installing downgraded versions of packaages which might exist in /boot/extra webgui: VM Manager: Add boot order to GUI and CD hot plug function webgui: Docker Manager: add ability to specify shell with container label. webgui: fix: Discord notification agent url webgui: Suppress info icon in banner message when no info is available webgui: Add Spindown message and use -n for identity if scsi drive. webgui: Fix SAS Selftest webgui: Fix plugin multi updates1 point
-
Just updated my lsio medusa docker, which has been working fine up to this point, and now it won't run. I just get these errors continuously looping in my log for it: s6-supervise custom-svc-README.txt (child): fatal: unable to exec run: Exec format error s6-supervise custom-svc-README.txt: warning: unable to spawn ./run - waiting 10 seconds Anyone elese getting this or seen it before and have an idea how to fix? edit: It looks like this is due to using a custom startup script and that they've changed how those work now. More info here: https://info.linuxserver.io/issues/2022-08-29-custom-files/1 point
-
In the image below, both the successful pihole docker, and the about:blank#blocked binhex-plex docker are running on the same custom network, and have fixed ip addresses.
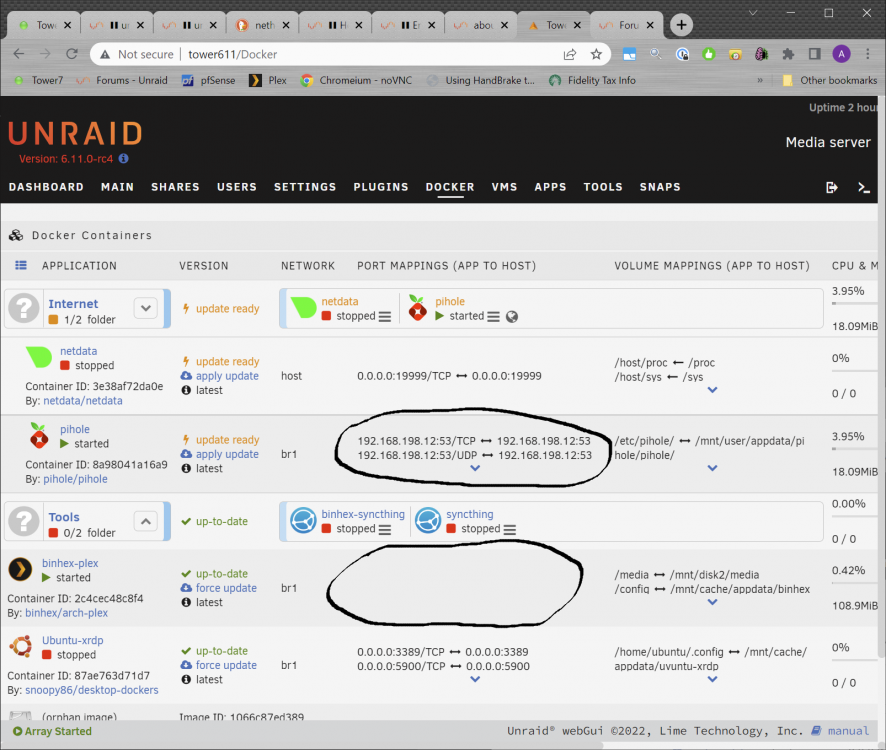 1 point
1 point -
I've also seen no problems since the changes, around the same time - About 2 weeks. I haven't finished rebuilding my permissions yet (still have a lot of the old ID numbers in a few of the shares) but the ones I did rebuild have been working solid. Thanks again for finding and posting about those. Has allowed me to branch out to other projects...1 point
-
Caveat - read carefully - I am by no means an UNRAID expert nor an expert on Samba, this is just want I have found out by reading online documentation and have been advised of on the Samba mailing lists. You should be really sure of what you are doing before you attempt this - you are responsible for your own files and data. It is really unhelpful that someone from Unraid has not responded to this issue with an official solution as this seems to be affecting many users and this does appear to be a misconfiguration issue with Unraid. The problem appears to be that Unraid is using a later version of the Samba Service but with an ID mapper (idmap_hash) that was end of life over 5 years ago and is known to cause issues. The fix is to "correct" Unraid's standard server configuration for Samba to use the correct ID mappers. These sites were of particular use: https://support.microfocus.com/kb/doc.php?id=7007006 https://lists.samba.org/mailman/listinfo/samba https://www.samba.org/samba/docs/current/man-html/ https://www.samba.org/samba/docs/current/man-html/idmap_hash.8.html https://www.samba.org/samba/docs/current/man-html/idmap_tdb.8.html https://www.samba.org/samba/docs/current/man-html/idmap_rid.8.html This did fix the problem with Samba shares not being accessible to certain Windows domain users for me. BUT after this fix, as user IDs get changed, most permissions were messed up and needed to be re-applied. Use this fix at your own risk. It is also helpful to know the wbinfo -i <username> command to check the the ID lookup is working correctly against your domain. Fix UNRAID Samba Access Issues. Open the Unraid terminal, ">_" button on top of each Unraid page. First back up smb-extra.conf file as follows: cp /boot/config/smb-extra.conf /boot/config/smb-extra.conf.bkp Edit the contents of /boot/config/smb-extra.conf and add these lines, replacing <SHORT_DOMAIN_NAME> with the name of your domain (the same as appears in the "AD short domain name" field of your Unraid SMB settings): [global] idmap config * : backend = tdb idmap config * : range = 1000-7999 idmap config <SHORT_DOMAIN_NAME> : backend = rid idmap config <SHORT_DOMAIN_NAME> : range = 10000-4000000000 The idea is that RID ID mappings are consistent and a given domain account will always map to the same local ID on Unraid, so if for some reason the IDs get reset the same domain accounts will remap to the same local IDs and retain access rights. Also a range of tdb IDs is assigned in case any SMB accounts are used without a domain. This will be shown as "extra configuration" on the Unraid SMB Settings page. Other Unraid plugins (such as unassigned devices) may also add configuration to this same smb-extra.conf - leave these as is and just add these extra lines to the top. Then reboot Unraid (just restarting the SMB service does not work fully). Finally check and fix all your permissions. Reset/Re-apply UNRAID Permissions. Open the Unraid terminal, ">_" button on top of each Unraid page. Run the following commands where <share> is the name of the share (each can take a long time if you have many files). chown -R root /mnt/user/<Share> chgrp -R domain\ users /mnt/user/<Share> setfacl -R -b /mnt/user/<Share> chmod -R g+rwx /mnt/user/<Share> If you need Windows permissions on the folder then apply permissions via Windows (NOT via Unraid Share SMB User Access settings). Open UNRAID Shares in File Explorer. Right click on the Share, select Properties. Select Security tab. Click "Advanced". Add, remove and alter permissions as required - note you may need to check the "Replace child object permissions" options to get this to work properly. Hit apply If using NFS from this share just refresh it (add/delete a space on the NFS rule and hit Apply) on UNRAID for some reason these seem to lose access rights when Windows changes the permission even when they should not.1 point
-
I get this also as soon as I specify the appdata directory for config files. Docker won't start up. I've also noticed that only the unbound.conf file is present in the appdata unbound folder. There is also a Dev and var folder. No other config files. Log files show the below @kutzilla Any ideas?1 point
-
@kutzilla When building the container I see their is an option to mount the config to a share/volume. When I put in for instance host Path: /user/appdata/unbound which maps to Container Path: /opt/unbound/etc/unbound/. I see some of the files/directories. However I'm unable to edit them unless I go in to the terminal and change the permissions. Even after doing that the container will not start and throws a critical error listed below. Any thoughts on how to resolve this? I'm hoping that it should be straight forward having share access to the unbound config files to modify them. [1634322343] unbound[1:0] fatal error: Could not read config file: /opt/unbound/etc/unbound/unbound.conf. Maybe try unbound -dd, it stays on the commandline to see more errors, or unbound-checkconf1 point
-
I thought I might post this here as it's taken me a while to piece it all together and it may help someone else get Fan Auto Control working. I have a Gigabute Z390 Aorus Elite board. Unraid can't support the fan PWM controler out of the box. I spent a couple of evenigns playing with sensors-detect btu noting was recognised. Then I found this page: https://github.com/a1wong/it87/issues/1 Essentially, you go to Main -> Boot Devices ->Flash -> Syslinux Configuration -> Unraid OS Change the second line from: append initrd=/bzroot to: append initrd=/bzroot acpi_enforce_resources=lax Then add this line to your /boot/config/go file: modprobe it87 force_id=0x8628 Reboot and Fan Auto Control should see your PWM fan.1 point







































