Leaderboard



Popular Content
Showing content with the highest reputation on 12/26/22 in all areas
-
But why would he intentionally or accidentally strike his server with lightening? Why would he intentionally or accidentally have his server stolen? Why would he intentionally or accidentally set his house on fire? Why would he intentionally or accidentally submerge his house with water? 🙈🙊🙉 /s5 points
-
My wife unintentionally deleted a whole year's worth of photos from my server. She has no idea how it happened because she did not intend to do it. Since I keep three backups of all the important data on unRAID (external USB drives, second unRAID server with weekly backup, in the cloud), restoring that folder for a whole year of photos was pretty easy. There is no way parity was going to save me (her) from that. Now that I know better, I have told my wife to never accidentally or intentionally delete something again because that has to be a deliberate action even if she claims she does not know how she did it!2 points
-
CA Appdata Backup / Restore v2.5 Welcome to a new epsiode of the appdata backup plugin The previous thread is located here: https://forums.unraid.net/topic/61211-plugin-ca-appdata-backup-restore-v2/ IMPORTANT! Starting with Unraid 6.12, this plugin will be deprecated. As already stated, there will be a complete rewrite of it. Please have a look at the new thread for it ----------------------------------------------------------------------------------------- What happened? I stumbled upon some bugs while using Squids plugin and made pull requests. Squid told me, he has only limited time and asked me if I want to publish a new version of the plugin. So we decided to deprecate his version in favor of "my" version. For now, the plugin has fixed for error detection and some other new features (see changelog). More to come. Anything I should consider? YES! Since the updated version shows you error during backup/verification (and even while stopping/starting containers), it COULD happen, that you see errors after update which were not there before. In most cases, these errors/warnings were there before but supressed. Errors like "File changed as we read it" or "Contents differ" (during verification) tells you, that some files are still in use. Post here (with your log) in that case.
 1 point
1 point -
UPDATE: I restored my USB flash drive and it seems like the data on it was corrupted. As mentioned I had running scripts on daily schedule (4:40am) and one of them was a flash backup script. In fact none of the scripts was causing this issues but the corrupted data on the flash drive. After the complete data restore on the usb stick the server is stable again and the running scripts are not causing any freezes anymore. (did not changed anything on the scripts)1 point
-
It seems to be working now. I think I was supplying an invalid directory name to the scandir function, and the error that was being returned was a red herring. Thanks for your help, SimonF! p.s. Turns out that wasn't the root cause of the problem. I was pasting in some code snippets, and what looked to be spaces in the code were actually a non-space character. Once I figured that out and over-typed with actual spaces, everything started working smoothly. I sure was getting some strange results until I found the actual problem.1 point
-
Could have asked in 7DAC discord as I dont check the forums a lot. opposite of Ich. The restart button issues the shutdown cmd to the7d server. CSMM rarely needs to be restarted. Besides updates I think ive restarted it 2 times for any syncing issue. Discord. make sure you linked your discord in your csmm profile.1 point
-
Ich nutze Unraid seit 2008 und es gab zu dieser Zeit keine Standard-Shares - weder isos noch appdata. Es gab noch nicht mal das Docker- oder KVM-Subsystem. Und die Community-Applications waren ebenfalls noch Jahre entfernt: https://wiki.unraid.net/Legacy/Unraid_4.7_Manual Ich habe das aber mit Hilfe des Support-Threads lösen können. Vielen Dank.1 point
-
Well said! Any RAID solution with parity is not in itself a backup of irreplaceable data if the RAID server contains the only copy of that data. There needs to be an second copy of that data on some other physical storage media to be a backup! (If the data is replaceable from another source, then that source is (by definition) a backup.)1 point
-
Several years ago, my wife got a new laptop. Before she gave the old one away to a friend, she deleted her chrome bookmarks from it. Of course, that propagated throughout chrome on her other devices and so she no longer had chrome bookmarks anywhere. Fortunately, I had our desktop computer imaged to my Unraid server, so I recovered them. Which also illustrates the fact that Unraid can indeed be a backup, just not the only copy of anything important and irreplaceable.1 point
-
Just to warn you that if both (with different case) exist then it matters when configuring locally, but if shared over the network the contents of only one of them will be shown (since Samba is case independent) and it may not be the one you expect. You do not want therefore folders with the same spelling but different case to exist at the Linux level.1 point
-
No. The drives in the array can use any mix of the file systems supported by Unraid - no requirement for them to all be the same.1 point
-
Nothing obvious in the log that I can see, do you now the time you've lost internet? Do other devices in the same network still have internet?1 point
-
It's planned as an option for both array and pools.1 point
-
Thanks for your help, problem solved!1 point
-
Sure I just looked at other posts and found a solution1 point
-
been more than 20 hours that 3 Samsung 980s stopped throwing 84c warnings hourly, fix works Running Unraid 6.11.5 3xSamsung 980 1tb NVMEs 2xSamsung 980 PRO 1tb NVMEs1 point
-
What happens if the server is a victim of a lightening strike? What happens if the server is stolen? What happens is your house/business catches fire and is a total loss? What happens if the server is 'drowned' due a flood or pipe breakage? There are a lot ways to end up with a catastrophic loss of data that no parity system can prevent!!!1 point
-
Accidents do happen. You think nobody has ever accidentally deleted a file? Or perhaps overwrote a file and wished they could get the original file back? Nobody that knows anything relies on parity or mirrors as a backup solution, whether Unraid or some other implementation of RAID.1 point
-
No it is definitely not a backup solution. This is true whether using Unraid or any other system with parity or mirrors or whatever. A very simple example should make this perfectly clear. Suppose you delete a file by accident. How is parity going to help you recover that file? With a backup, you just get the file from your backup. What if someone, intentionally or accidentally, formats a disk? Lots of other examples that parity can't help you recover from, and mirror won't help you recover from either, since parity or mirror just lets you get the latest contents, whether it is missing an accidentally deleted file, or if the whole disk was formatted. You must always have another copy of anything important and irreplaceable. Parity is NEVER a substitute for backup, whether Unraid or some other more traditional RAID system.1 point
-
Added two interesting things to the initial post:1 point
-
It was doing many multiple transfers at the same time and not completing any of them. It seems whenever I start a file move from that part, it just breaks and even stopping the process won't stop rsync. You do have to kill them. Anyway, I tried midnight commander again. I realise the last time I tried it was after the other method, which meant the transfers would have still been going on in the background. Anyway, on a fresh attempt MC transferred the remaining 2TB overnight with no issue. So either there's something wrong with my setup when attempting moves from the browse disk function or it's a bug. Either way, avoiding it and using MC was the solution.1 point
-
/etc/cron.d/root But usually you would manage cron jobs either via user scripts or by putting an applicable .cron file on the flash drive1 point
-
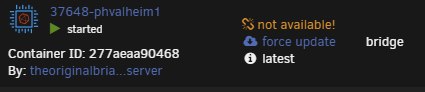
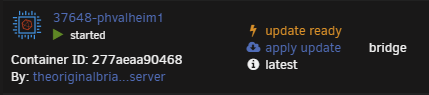
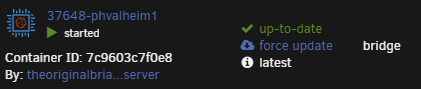
I figured it out. This isn't a CA or unRAID issue. It's OCI compatibility with DockerHub. Hopefully this can help someone else. My debugging process: I grepped through the entire directory /usr/local/emhttp/plugins/dynamix.docker.manager/include for "not available" which is the HTML label shown in the Unraid Docker UI To prove to myself that I found the right label, I added the "!" you see in the screenshot above. This label is inside a case/switch condition. I.e., 0="up-to-date", 1="update ready", 2="rebuild ready" else, "not available" within the DockerContainers.php file. My containers were returning a NULL value which results in the "default/else" (not available message). This condition evaluates the variable "$updateStatus". This variable is set by an array read of the $info['updated'] array element. This variable is set by DockerClient.php and where most of my debugging occurred. /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php: I added the following to the "getRemoteVersionV2" function to assist in debugging. $file = '/tmp/foo.txt'; file_put_contents($file, PHP_EOL . $image . '(' . $manifestURL . ')' . ' ', FILE_APPEND); This sent me on a reverse engineering journey and helped me create a little test script: #!/bin/bash repo="theoriginalbrian/phvalheim-server" TOKEN=$(curl --silent "https://auth.docker.io/token?scope=repository:$repo:pull&service=registry.docker.io" | jq -r '.token') curl --header "Accept: application/vnd.docker.distribution.manifest.v2+json" --header "Authorization: Bearer $TOKEN" "https://registry-1.docker.io/v2/$repo/manifests/latest" The output of this little test script: {"errors":[{"code":"MANIFEST_UNKNOWN","message":"OCI manifest found, but accept header does not support OCI manifests"}]} A bit of research landed me in DockerHub API documentation...in short, OCI images do not contain the SHA256 image digest (at least in the location DockerHub expects). This led me to look at how I'm building my images. My dev system is just a simple Rocky 8.6 (EL) VM, which runs podman. By default, podman builds in the OCI format. Simply passing "--format=docker" to my podman build command solved the issue. Results: After clicking "check for updates": After clicking "apply update": After clicking "apply update" and "check for updates:" TL;DR: add "--format=docker" to your docker/podman build command. -Brian
 1 point
1 point -
Known issues & planned features Known issues If container autoupdate is enabled, the container gets started and producing a "Already started" info Currently being accepted as ok - produces some debug info inside the log but does not treat it as error 02.2023: Some users facing "tar verify failed!" issues although all dockers are stopped. Currently searching possible root causes. Planned features Complete overhaul of the code including PHP8 compatibility ✔️Files/Folder config per container ✔️Maybe extra sources apart from containers? ✔️Option (separate) to disable encoutered errors (containers, tar backup, tar verify) ✔️Multicore backup (zstdmt) ✔️PreRun/PreBackup/PostBackup/PostRun custom scripts ✔️Restore single container data ❌Treesize view of all source data? ✔️Include the docker templates in backups ✔️Some easy diag functions Share diag docker infos and the config ❌Some anonymous statistic collection Opt-In ❌ Not now / Never / Not planned ✔️ Done ⏳ In progress Notes Multiple appdata volume sources possible Save to single archive removed The backup will always create seperate files now Flash backup is back! It uses unraids native way for doing it VMs backup also included Basic operation. More to come - maybe1 point
-
Solltest du Container installiert haben, solltest du prüfen, ob nach dem ersten Array Start jetzt nicht alles doppelt auf dem Array installiert wurde, was vorher auf dem Cache lag. Wenn ja, dann muss es von da gelöscht werden. Vorsichtshalber aber Docker beenden und die entsprechenden Ordner erstmal sichern.1 point
-
Hallo, ich habe auch powertop autotune ausgeführt und bin jetzt bei 12-17 W im idle, was ich schon sehr beachtlich finde. Ein paar Eckdaten. Mainboard: Gigabyte W246M - WU4 Netzteil: be quiet! PP11 FM 550W Festplatten: 2x Seagate IronWolf 8TB 1x Crucial MX500 1TB SSD 2x WD Red SN700 1TB NVMe RAM: 2x 32GB Micron DDR4 - 3200 EUDIMM Prozessor: i3 9100 Ich weiß nicht genau, welche Befehle ich jetzt in die go Datei einfügen muss, damit es jetzt nach dem Reboot auch verfügbar ist?
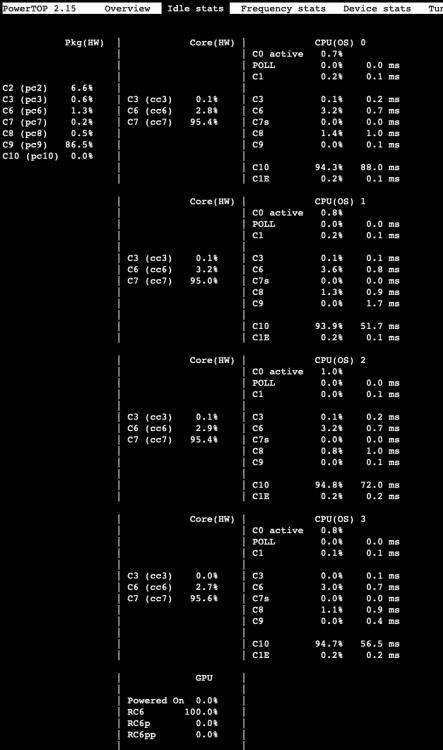 1 point
1 point -
@JorgeB I found the following post that claims to 'fix' this issue https://forum.proxmox.com/threads/smart-error-health-detected-on-host.109580/#post-475308 Where and how do I use this command in Unraid?1 point
-
Shares, user shares, size, compute?1 point
-
During one of our Private Message discussions, @Batter Pudding suggested that ‘Short Sheets’ of the steps involved in each procedure could be beneficial. I know that when I am doing any multi-step procedure, I like have have a printout of the procedure and check off each step as I complete it. The attachments to this posting are the short sheets for each procedure in the document in the first post. EDIT: March 15, 2024 Added the PDF for "An Alternative Method to Network Neighborhood". How To #1-Advance Network Settings.pdf How to #2-Fixing the Windows Explorer Issue.pdf How to #3– Turning Off “SMB 1.0_CIFS File Sharing Support”.pdf How to #4-Adding a SMB User to Unraid.pdf How to #5-Adding a Windows Credential.pdf An Alternative Method to Network Neighborhood.pdf1 point
-
I also have been trying to get in to proxmox but seems like everything you have to do cli, including zfs pools. The gui is a waste of time, makes you appreciate unraid more it really does1 point
-
Failed SMART tests can't be caused by cable issues, so it was really a disk problem, though an internement one, I would probably give it a second chance but any more errors or failed SMART tests replace it.1 point






















