Leaderboard



Popular Content
Showing content with the highest reputation on 01/16/23 in all areas
-
Down the line could there be a way to assign priority values for mover.. maybe 1-5 per share. 1 = move files as normal (daily or low value user defines) 3 = move every 7 days 4 = move monthly or value user defines as high 5 = skip mover unless space is needed We have the mover tuning plugin but still could use a little more wiggle room. Downloaded media content to stay on drive as long as possible before moving to array while archive folders etc are cached then moved on to array quicker. Could do it with custom scripts but sure others would enjoy this too?2 points
-
Overview: Support thread for NetBird Application: NetBird-Client, NetBird-Dashboard, NetBird-Management, NetBird-Signal - https://netbird.io About: Connect your devices into a single secure private WireGuard®-based mesh network with SSO/MFA and simple access controls. Docker Hub: https://hub.docker.com/r/netbirdio/netbird GitHub: https://github.com/netbirdio/netbird Documentation: https://netbird.io/docs NGINX Conf: https://github.com/dannymate/unraid-templates/tree/master/Conf Samples/SWAG/nginx/proxy-confs Please post any questions/issues relating to this docker you have in this thread. 2023-07-25 - I've updated the NGINX conf after looking at updated NETBIRD docs.1 point
-
I wasn't sure where to post this kind of thing - it's not exactly 'forum feedback', nor is it really a 'feature request for UnRAID' (if the capitalization is wrong here, please do let me know - I may've been writing it wrong all this time 😕 ), but more a 'business feature request' I guess... An ask of the team as far as planning goes I guess? The request: For Limetech to publish a Feature Roadmap which gives a generalized direction for wherever Limetech is planning to take the core OS over the next (however long you feel is realistic). What would be super helpful (and hopefully more realistically possible now that the team's grown a bit!) is to publish a Feature Roadmap, updated perhaps once per every major release (6.8, 6.9, 7.0, etc), or every 3-6ish months (whatever makes sense based on your internal structure and cadence), which outlines the 'big new things' planned for the next (however many releases can be semi-accurately forecast). _____ Some background: A Little Justification: Ideas for what it looks like: <To be filled out once I get back from the day out with the fam>1 point
-
Just a quick note to finish out the differences, parity1 is mathematically simpler, and also doesn't require the disk slot numbers to be the same to stay valid. For example, with valid parity1, you can rearrange any data drives you wish to different slot numbers, like swapping disk1 and disk4, and as long as all the disks are present and none added, parity1 remains valid. Parity2 on the other hand is a much nastier set of equations, and one of the factors of the parity2 math is the slot number of the drive. So all disks must remain in the same slots for it to remain valid, and it requires more CPU power to calculate. That also can cause a difference in write speed, depending on available CPU power. Recent CPU's you really can't even tell the difference, but on older CPU's with limited math power it can be quite noticeable.1 point
-
Swapfile is not needed at all.1 point
-
Sorry didn't realize parity build hadn't completed. Let it complete then worry about parity2 disk Parity2 isn't seen in diagnostics so you won't be able to do anything with it until you can get it to connect. After parity build is complete, shutdown, try to fix connection to parity2, see if it is detected in BIOS.1 point
-
Done, Please check it ...1 point
-
I see, sorry I missed the third port in the docs. Thank you for explaining it. I'm learning a lot of new skills as I work on this unraid server thing, so I just hadn't been exposed to those details before. Thanks for taking the time to talk to a dummy like me. In any case, I got it working now so thanks for your help!1 point
-
I have forked the plugin repository and commited a fix for the stray warning. May you check if you still have the warning after a restart so I'll make a Pull Request? @mrslaw @Snowman @Mat W @GigaTech Can't restart my server to test this unfortunately. https://github.com/uraid/unraid-theme-engine/raw/fix-stray-dash/plugins/theme.engine.plg The only change I've made is this: https://github.com/Skitals/unraid-theme-engine/compare/master...uraid:unraid-theme-engine:fix-stray-dash1 point
-
Your Unraid Wireguard VPN allows secure remote access to your server or LAN. Applications such as delugeVPN use a VPN service to allow them to connect to other things on the internet anonymously.1 point
-
OK, started the array. Not seeing any unmountable filesystem messages and the rebuild seems to be running smoothly now 🤞 diagnostics-20230116-1244.zip1 point
-
Ahh ok. Makes sense, I will run one 👍 Cheers1 point
-
https://forums.unraid.net/topic/131857-soon™️-612-series/?do=findComment&comment=12139011 point
-
Also mein Ansatz war/ist, dass Client unabhängig jeder 4K Film läuft bzw. laufen soll. Mir gefällt der Gedanke, dass eine CPU mit iGPU das transcoden sehr effizient übernehmen kann. Das man dazu den Plex Pass benötigt, war mir nicht klar. Aber 1-2 im Jahr gibt es den glaube ich auch für 60-80 EUR Lifetime, wäre jetzt nicht DAS hindernis. Der aktuelle Client ist ein LG TV aus 2018. Wenn ich auf dem Server das transcoden deaktiviere, hat der LG bei gewissen Filmen Probleme, besonders wenn man es wagt mal etwas zu spulen. Dann ist der manchmal etwas zickig. Als ich dann mal testweise einen Plexserver über meinen PC (Ryzen 3600 hat das transcoden übernommen) habe laufen lassen, war alles wieder top. Somit wird DIESER Client (LG TV) langsam zu alt für bestimmte Formate, deswegen diese zugegebenermaßen übertrieben Hardware. Ich weiß auch einfach noch nicht, auf welche Idee ich mal so komme (Beisp. Gamestreaming, Virtualisierung Windows Arbeitsplatz). Da würde ich einfach ungerne wieder irgendwann mal aufrüsten müssen. Dazu sind meine bisherigen Erfahrungen mit gebrauchter Hardware leider sehr schlecht gewesen. Deswegen mein Ansatz alles neu und aktuell. Nur so wie ich das jetzt so sehe, steht das alles mit der Frage ECC ja oder ECC nein. Welche ich im übrigens für mich noch immer nicht mit einem JA od. NEIN beantworten kann. Im Zweifel einfach ja, das schadet dann weniger als wenn man es nicht hat und dann doch benötigt. Denn 1700 Mainboards mit ECC gibt es quasi nur als W680 und die sind verdammt teuer. Da wird der 1151 Sockel dann wohl doch wieder attraktiv...... Alles nicht so leicht1 point
-
So good news, the fresh install of Unraid, resolved the issue. No idea what was wrong but going to mark this as solved now.1 point
-
Thats even more impressive. Thanks a lot for your effort.1 point
-
Ah ok. I did not know its windows only. Thanks a lot for your quick answer. I dont play the game myself but I'm the one with an unraid server^^1 point
-
Start the array and post new diags.1 point
-
Yep, it's logged as a disk problem and SMART is showing various issues.1 point
-
@JorgeB just a final update on this. There seems to be something wrong with the WD Blues being able to do the extended test. The extended test is hung at 90% as I've tried running the test on 2 of them, Disk1 has been running since the 3rd and I started Disk2 about 3 days ago. However my WD Golds the Extended test finished in about a day or two (wasn't exactly watching the time). I'm going to try to swap out cables a monior and troubleshoot from that angle, thanks again!1 point
-
Please have a look under Settings / Management Access. My Server Plugin changed "Allow Remote Access" from Yes to No on my server tonight. Unfortunately, this isn't the first time this has happened.1 point
-
PCIe versions aren't too bad, you just need to power via a riser, same as the ones GPU miners use. Some non-pcie pwoered options I know: Intel RES2CV240 (regular molex power connector) Dell 5R10N (needs custom pinned 4 pin connector)1 point
-
Power only, won't use PCIe.1 point
-
When updating to the latest version last week I ended up having this issue (stumbled around for about a week until I came across this exact log with the Prepared transactions error). I can't confirm if it was the update that caused it, or if it was circumstantial. long story short I had to open up the shell for the Guacamole Docker and run this command: mysqld --tc-heuristic-recover=COMMIT. things started working again after that. hope this helps someone in the future.1 point
-
Hi guys, I have another data point for this problem. I'm using LSI 2008 HBA's into HP sas expanders, with an assortment of drives (including Seagate Archive and EXOS) with spindown set, and am seeing exactly this thread's problem on drive spinup. Although the server is running a different Linux distro, I think the root cause might be the same as later versions of Unraid are seeing. I have narrowed the problem down to affecting Linux kernel 5.17 and onwards. I've tested 5.17, 5.18, 5.19 and 6.1.6, all which behave identically when trying to spin up drives. (some Hitachi and western digital drives are also affected). Linux Kernel 5.16 and prior are working fine. I'm almost positive this is the same issue you're having with versions of Unraid past 6.8.* series, perhaps due to a backported patch (6.10 is running a late version of 5.15). I really hope a dev stumbles upon this and it helps narrow down the root cause. For the sake of searchability, I'll include kernel logs from both working and non working situations. First up is 5.16 (and prior) which is working perfectly. It produces the following errors on spin-up (but operates normally). I'm using bcache on these drives and the kernel readahead seemingly errors out with I/O errors due to spin-up timeout - but once the drive is spun up, everything operates normally and user space processes never receive any IO errors. Processes trying to access the drive are hung until its online however, which is normal. The contained BTRFS filesystem never complains, confirming data integrity is good, as its a checksummed filesystem. Note the cmd_age=10s on the first line, indicating spinup is taking longer than 10s. [Jan18 05:08] sd 0:0:13:0: [sdn] tag#705 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=10s [ +0.000011] sd 0:0:13:0: [sdn] tag#705 Sense Key : 0x2 [current] [ +0.000006] sd 0:0:13:0: [sdn] tag#705 ASC=0x4 ASCQ=0x2 [ +0.000006] sd 0:0:13:0: [sdn] tag#705 CDB: opcode=0x88 88 00 00 00 00 02 3c 46 f5 f0 00 00 03 e0 00 00 [ +0.000003] I/O error, dev sdn, sector 9601218032 op 0x0:(READ) flags 0x80700 phys_seg 124 prio class 0 [ +0.123623] bcache: bch_count_backing_io_errors() sdn1: Read-ahead I/O failed on backing device, ignore Next up is 5.17 (and onwards) which produces this upon drive spin up (which hangs the affected drive until it comes online): [Jan16 08:49] sd 1:0:13:0: attempting task abort!scmd(0x0000000052c3e39b), outstanding for 10028 ms & timeout 60000 ms [ +0.000015] sd 1:0:13:0: [sdak] tag#1552 CDB: opcode=0x1b 1b 00 00 00 01 00 [ +0.000004] scsi target1:0:13: handle(0x0017), sas_address(0x5001438018df2cd5), phy(21) [ +0.000007] scsi target1:0:13: enclosure logical id(0x5001438018df2ce5), slot(54) [ +1.449183] sd 1:0:13:0: task abort: SUCCESS scmd(0x0000000052c3e39b) [ +0.000010] sd 1:0:13:0: attempting device reset! scmd(0x0000000052c3e39b) [ +0.000005] sd 1:0:13:0: [sdak] tag#1552 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00 [ +0.000003] scsi target1:0:13: handle(0x0017), sas_address(0x5001438018df2cd5), phy(21) [ +0.000004] scsi target1:0:13: enclosure logical id(0x5001438018df2ce5), slot(54) [Jan16 08:50] sd 1:0:13:0: device reset: FAILED scmd(0x0000000052c3e39b) [ +0.000006] scsi target1:0:13: attempting target reset! scmd(0x0000000052c3e39b) [ +0.000006] sd 1:0:13:0: [sdak] tag#1552 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00 [ +0.000003] scsi target1:0:13: handle(0x0017), sas_address(0x5001438018df2cd5), phy(21) [ +0.000003] scsi target1:0:13: enclosure logical id(0x5001438018df2ce5), slot(54) [ +3.000146] scsi target1:0:13: target reset: SUCCESS scmd(0x0000000052c3e39b) [ +0.248868] sd 1:0:13:0: Power-on or device reset occurred And then occasionally (only on 5.17 onwards) I'm seeing this: [Jan16 10:15] mpt2sas_cm1: sending diag reset !! [ +0.480071] EDAC PCI: Signaled System Error on 0000:05:00.0 [ +0.000011] EDAC PCI: Master Data Parity Error on 0000:05:00.0 [ +0.000003] EDAC PCI: Detected Parity Error on 0000:05:00.0 [ +0.466972] mpt2sas_cm1: diag reset: SUCCESS [ +0.057979] mpt2sas_cm1: CurrentHostPageSize is 0: Setting default host page size to 4k [ +0.044426] mpt2sas_cm1: LSISAS2008: FWVersion(18.00.00.00), ChipRevision(0x03), BiosVersion(07.39.02.00) [ +0.000009] mpt2sas_cm1: Protocol=(Initiator,Target), Capabilities=(TLR,EEDP,Snapshot Buffer,Diag Trace Buffer,Task Set Full,NCQ) [ +0.000078] mpt2sas_cm1: sending port enable !! [ +7.814105] mpt2sas_cm1: port enable: SUCCESS [ +0.000314] mpt2sas_cm1: search for end-devices: start [ +0.001358] scsi target1:0:0: handle(0x000a), sas_addr(0x5001438018df2cc0) [ +0.000011] scsi target1:0:0: enclosure logical id(0x5001438018df2ce5), slot(35) [ +0.000117] scsi target1:0:1: handle(0x000b), sas_addr(0x5001438018df2cc1) [ +0.000006] scsi target1:0:1: enclosure logical id(0x5001438018df2ce5), slot(34) [ +0.000086] scsi target1:0:2: handle(0x000c), sas_addr(0x5001438018df2cc3) etc (all drives reset and reconnect) which and causes some problems with MD arrays etc as all drives are hung whilst this is going on and heaps of timeouts occur. Between these two scenarios, it might explain the dropouts you're seeing in unraid. Hope this helps! I'm looking into changing HBA to one of the ones quoted in this thread to work around the problem - I dont want to be stuck on Linux kernel 5.16 forever. I will be back with updates!1 point
-
Do it again without -n. If it asks for it use -L1 point
-
Thanks for reporting, I'm fixing this.1 point
-
From the compose page select the gear and then edit stack. Choose the button that says UI Labels and on the lines that say Shell enter the shell that is available in your containers (typically bash or sh).1 point
-
Sure , i hope will have time for it in this week ...1 point
-
Totally pointless, but harmless if it was done before assigning them to the array. Rebuild completely overwrites the disk, doesn't matter at all if the disk was newly formatted to an empty filesystem, cleared, completely full of pron, whatever. It always makes me nervous when anybody talks about formatting in a thread where they are replacing disks. I think many don't actually know what format does. Format means "write an empty filesystem (of whatever type) to this disk". That is what it has always meant in every OS you have ever used. Fortunately, you didn't format a disk in the array. Many have made that mistake, thinking they can rebuild. Unraid treats that write operation just as it does any other, by updating parity. So after formatting a disk in the array, the only thing it can rebuild is an empty filesystem. disk1 is an array disk. If the disk was disabled/emulated/rebuilding and unmountable, that has absolutely nothing to do with the physical disk you pointlessly formatted in UD. Good thing too, since your data is on that emulated/unmountable disk. Did you do check filesystem from the webUI? Post the complete output from that.1 point
-
I can wait. Mostly wanted to work on parallelization/docker restart mechanics, like what's been discussed in the thread.1 point
-
Thanks!1 point
-
Don't try this. It is imperative that parity always be correct. On the next parity check, you'll have parity errors on the new drive if it is not zeroed before being installed. Just let Unraid do its thing or preclear the drive before installing it.1 point
-
Update the pci-e expansion sata card worked….. now I have to buy another drive or 2 to fill it up..1 point
-
Das wird sicher auch noch kommen mit der Zeit. Jetzt muss ich erst mal lernen mit dem Unraid Server umzugehen. Das wichtigste ist erst mal eine Nextcloud die aktuell noch auf dem Raspberry läuft.1 point
-
Open a web terminal and run: unraid-api restart Wait a few minutes, then run this again unraid-api report -v If it still isn't able to connect, we are in the process of finalizing a new release which should resolve this.1 point
-
Not normally - it would keep restarting such operations from the beginning. if you install the Parity Check Tuning plugin then it has the option to resume such operations from the point reached (as long as the shutdown was a tidy one). 0ne restriction (at the moment) is that the array is not auto-started so you have to manually start the array to continue the operation.1 point
-
Ran into an odd issue where websites would get a 502 Gateway error after today's rebase to Alpine 3.17. The following error will fill the logs: nginx: [emerg] "stream" directive is not allowed here in /etc/nginx/conf.d/stream.conf:3 Ending up figuring out you can do the following, then restart your Container and it'll fix it. ls -al /etc/nginx/conf.d/ /etc/nginx/stream.d/ mv -v /etc/nginx/conf.d/stream.conf /etc/nginx/stream.d/ I did open https://github.com/linuxserver/docker-nginx/issues/871 point
-
hello everybody, did this apps is alive or stop for dev ? Second question is there any label that we can add to an docker-compose that will automaticly put the container in a specific existing folder or more create a folder ? thansk1 point
-
Warning: Illegal string offset 'BONDING' in /usr/local/emhttp/plugins/dynamix/include/DefaultPageLayout.php(693) : eval()'d code on line 31 Warning: Illegal string offset 'BRIDGING' in /usr/local/emhttp/plugins/dynamix/include/DefaultPageLayout.php(693) : eval()'d code on line 32 moecat-diagnostics-20221228-0855.zip1 point
-
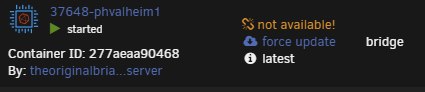
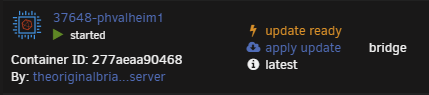
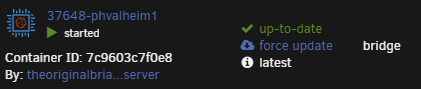
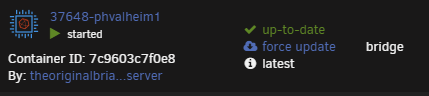
I figured it out. This isn't a CA or unRAID issue. It's OCI compatibility with DockerHub. Hopefully this can help someone else. My debugging process: I grepped through the entire directory /usr/local/emhttp/plugins/dynamix.docker.manager/include for "not available" which is the HTML label shown in the Unraid Docker UI To prove to myself that I found the right label, I added the "!" you see in the screenshot above. This label is inside a case/switch condition. I.e., 0="up-to-date", 1="update ready", 2="rebuild ready" else, "not available" within the DockerContainers.php file. My containers were returning a NULL value which results in the "default/else" (not available message). This condition evaluates the variable "$updateStatus". This variable is set by an array read of the $info['updated'] array element. This variable is set by DockerClient.php and where most of my debugging occurred. /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php: I added the following to the "getRemoteVersionV2" function to assist in debugging. $file = '/tmp/foo.txt'; file_put_contents($file, PHP_EOL . $image . '(' . $manifestURL . ')' . ' ', FILE_APPEND); This sent me on a reverse engineering journey and helped me create a little test script: #!/bin/bash repo="theoriginalbrian/phvalheim-server" TOKEN=$(curl --silent "https://auth.docker.io/token?scope=repository:$repo:pull&service=registry.docker.io" | jq -r '.token') curl --header "Accept: application/vnd.docker.distribution.manifest.v2+json" --header "Authorization: Bearer $TOKEN" "https://registry-1.docker.io/v2/$repo/manifests/latest" The output of this little test script: {"errors":[{"code":"MANIFEST_UNKNOWN","message":"OCI manifest found, but accept header does not support OCI manifests"}]} A bit of research landed me in DockerHub API documentation...in short, OCI images do not contain the SHA256 image digest (at least in the location DockerHub expects). This led me to look at how I'm building my images. My dev system is just a simple Rocky 8.6 (EL) VM, which runs podman. By default, podman builds in the OCI format. Simply passing "--format=docker" to my podman build command solved the issue. Results: After clicking "check for updates": After clicking "apply update": After clicking "apply update" and "check for updates:" TL;DR: add "--format=docker" to your docker/podman build command. -Brian
 1 point
1 point -
You do not need a GPU to use Unmanic. That is a pretty outrageous statement to make. Using a GPU inside the official Unmanic Docker container is an optional thing that you can do if you wish. You can also use Unmanic on the VM that you have passed your GPU into if you like. Unmanic is a tool with a lot of capabilities of which only a very small sub-set would even have the option to take advantage of a GPU.1 point
-
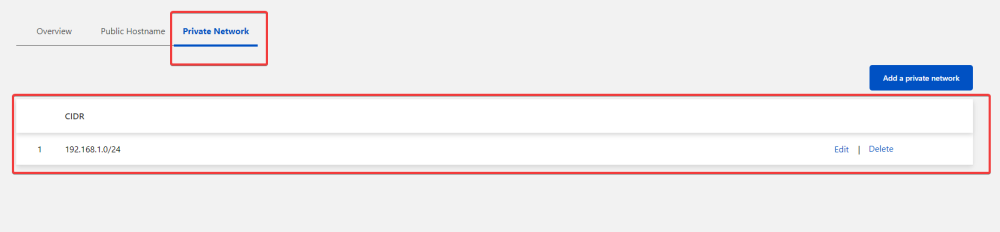
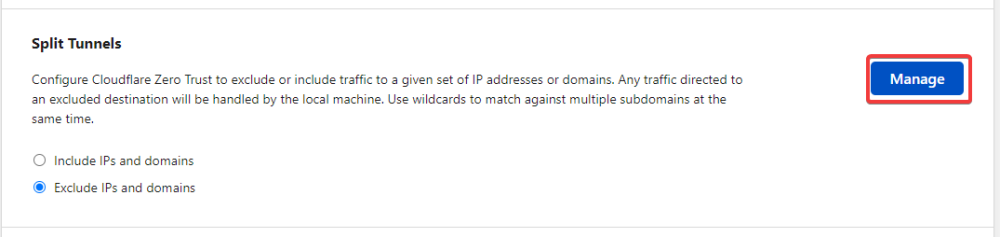
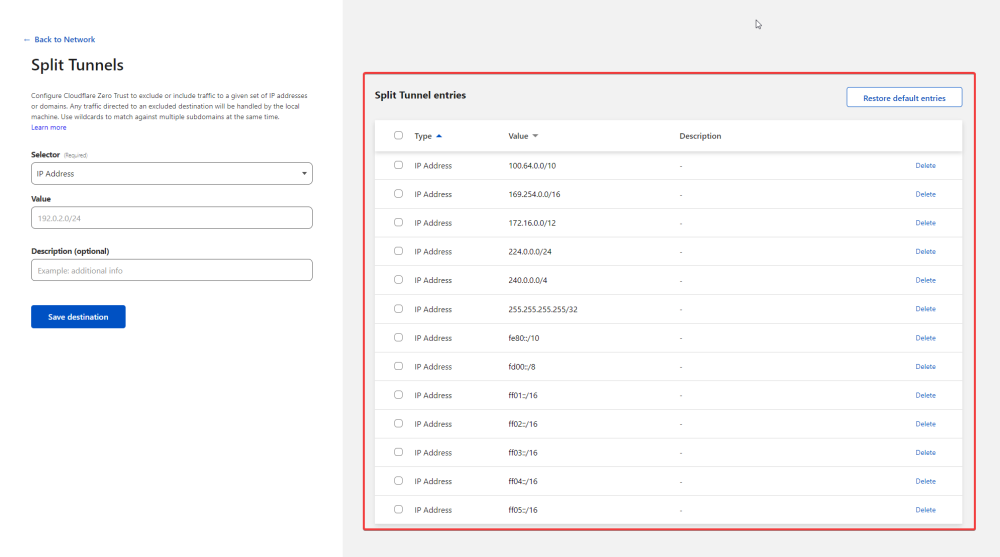
This here is the only thing I added under the tunnel in cloudflare's zero trust dashboard. Then under zero trust settings (not under the tunnel) in settings > network, under firewall you will see split tunnels in the manage page make sure the CIDR of your network that you added to the tunnel before is not in this list if you have "Exclude IPs and domains" selected. If you have Include selected make sure it is in the list. After this I just connected to the warp client (make sure you are authenticated with your zero trust login) and you should be able to access local IPs from outside your network via Warp. Hope this helps
 1 point
1 point -
I'm curious how other users do it. I run the cron directly from the Unraid host using User Scripts. #!/bin/bash docker exec -i nextcloud sudo -u abc php -f /config/www/nextcloud/cron.php I run it every 5 min: */5 * * * *1 point
-
after a ton of research i have figured it out. under <os> put <smbios mode='host'/> directly below that put this under <features> <kvm> <hidden state='on'/> </kvm> under <cpu mode ='host-passthrough'....... put <feature policy='disable' name='hypervisor'/> and i also deleted any lines pertaining to hyper-v hope this helps anyone in the future1 point
-
@limetech This should be fixable by editing /usr/local/sbin/in_use and adding this: [[ -L "$file" ]] && exit 1 # ignore symlinks before this: fuser -s "$FILE" && exit At the moment I'm testing this in the go-file: # ------------------------------------------------- # Workaround for mover bug (tested with Unraid 6.9.2, 6.11.2, 6.11.3) # https://forums.unraid.net/bug-reports/prereleases/690-rc2-mover-file-does-not-exist-r1232/ # ------------------------------------------------- if md5sum --status -c <<<"01a522332c995ea026c6817b8a688eee /usr/local/sbin/mover" || md5sum --status -c <<<"0a0d06f60de4a22b44f634e9824245b6 /usr/local/sbin/mover"; then sed -i '/shareUseCache="yes"/a\ \ \ \ \ \ \ \ find "${SHAREPATH%/}" -type l -depth | \/usr\/local\/sbin\/move -d $LOGLEVEL' /usr/local/sbin/mover fi It fixes1 point
-
I needed ctrl-alt-del disabled on Unraid as well. Kept trying to login to my VM using it, without first remembering to bind the keyboard to the VM. Which would of course reboot the Unraid host instead. What I added to /boot/config/go -> # Disable ctrl-alt-del on Unraid host sed -i 's/ca::ctrlaltdel/# ca::ctrlaltdel/' /etc/inittab /sbin/telinit q1 point
-
there are ongoing issues with PIA DNS, you can try setting NAME_SERVERS to the following (removes PIA DNS):- 84.200.69.80,37.235.1.174,1.1.1.1,37.235.1.177,84.200.70.40,1.0.0.11 point
-
Could I setup a docker image to run through this router?1 point
-
Array start means that all plugins, etc are installed, so that would be the best. An alternative to only run at boot is to manually add the command to the /boot/config/go file1 point


.thumb.png.17851aece2a22632d74cf27bdb68bec5.png)









































