Leaderboard




Popular Content
Showing content with the highest reputation on 04/11/23 in all areas
-
Appdata.Backup Support Thread This is the support thread for appdata.backup (formerly known as ca.backup2). This plugin primary takes care of your appdata backup! It allows you to configure backup settings for each of your docker containers. Flash and VM meta backup is integrated as well! If you encounter any issues, post it here with the debug log file attached! For your beta feedback, please post here instead! Why do I need to reinstall the plugin (again)? After my adoption of the ca.backup2 plugin (which needed a manual reinstall from every user the 1st time), I decided to make a complete overhaul of the whole plugin. The main reason was the PHP8 incompatibility. This new plugin is the result. Because it is actually a seperate new plugin, you have to switch to it manually again. This will be the last time Hints The plugin send me here to check for some Plex exclusions. Yes, thats right. You dont need to save Plex cache (and some other) directories. But its up to you to exclude them or not. Currently you are advised to set the following exclusions for plex: Each following paths need to be prefixed with your correct appdata path! Library/Application Support/Plex Media Server/Cache Library/Application Support/Plex Media Server/Media Library/Application Support/Plex Media Server/Metadata The plugin sent me here for help with the grouping function The grouping function allows you to group cotainers. The backup process stops all those containers, backup them and starts them back up before going to the next single container. This works for the mode "Stop, backup, start for each container" only. If the plugin reaches a group, it stops all containers in it, backup them and start them back up. The backup method "Stop all, backup, start all" has no effect here because every single container will be stopped nefore starting backup. The plugin sent me here to get help for the "Mapping used in multiple containers!" message The plugin can detect if you use the same mapping within more containers. That is completely okay but you should know that this can lead to "verification failed: contents differ" messages if you use stop/backup/start method and another container modifies the data during backup of the container that uses that share. The best way to get rid of that message is to add that share to the exclusion in all but the main container. One could also change the backup type but it does not prevent backing that share up multiple times!
 2 points
2 points -
Dashboard Updates, AutoTrim for xfs and btrfs, Linux Multi-Gen LRU, Release bz file restructure - all kinds of stuff!2 points
-
2 points
-
Perfect! Thank you so much, ConnerVT! I'll definitely take a look into those Graphics Cards!2 points
-
Quadro T400 will do all you need for Plex transcoding. New = $150-200 USD. Used around $100. Even the Quadro P400 (which I currently use) will work fine. Can be found on eBay starting around $50.2 points
-
Running `unraid-api restart` fixed it for me.2 points
-
The attachment in this post is a joint effort between @Batter Pudding and myself. @Batter Pudding supplied much of the technical part of the Attached Document and I provide most of the background information. What we are attempting to do is to show that it is easy to actually use Unraid with all of the security features that Microsoft has incorporated into Windows 10. What many of us have been doing (myself included) is to reverse those enhancements to security and use our Unraid network in what is basically a 2010 security environment. @limetechhas announced in the release thread for version 6.9.2 that they are about to increase security on Unraid in future releases. Unfortunately, this list is going to impact a lot of current Unraid users as many have setup their Unraid servers and networking to use these very features. Each user will have two choices. Either embrace security or spend time to undo each new security addition that either LimeTech or MS adds in their updates. If you decide to continue to bypass security, just realize that the number of folks prepared to assist you with any problems doing this will probably decline as more folks adopt increased security as a necessity. In some cases, this is going to present some difficult decisions. For example, I have an old Netgear NTV-550 set top media player (last firmware/software update was in early 2011) that only supports SMBv1 or NFS. Do I open up a security hole to use a well-functioning piece of equipment or do I replace it? (The choice, obviously, is one that only I can make...) Two Important things! Do not post up any problems that you have with networking between Windows 10 and Unraid in this thread! Start a new thread in the General Support forum. Please don’t tell us that there is another way to do something and that we should change our recommendation to employ that method. If you feel you have a better way, you are encouraged to write it up in detail and post it in this thread pointing out the advantages of your way. (One well regarded Windows 10 networking book has over 400 pages in it. Our document is 16 pages long…) EDIT: November 30, 2021. Recently, something has come to my attention about Unraid and SMB. There have been incidences where access to Unraid shares is restricted or blocked completely from users who should have access to it. What has been found in these cases is that a feature, has been enable on the Unraid side, called Access Control Lists (ACL for short). This will show up as an ‘+’ at the end of the Linux permissions. See the screen capture below: Note that the ‘+’ is also on the file as well as the share/directory. ACL changes the way that Linux is going to control access to these resources. After some research, I found out that Windows has used ACL for a long time. The SAMBA group has added ACL into its version of SMB. Unraid does not use ACL in its security scheme. At the present time, I can think of only one way that a ACL could be found on any Unraid server. It was done by a Windows user who was trying to change how SMB worked by applying Windows security features to an Unraid share by changing the default Security settings. (Basically, right-clicking on the Share in Windows Explorer, selecting ‘Properties’, then the ‘Security’ tab and working from there.) The point I am making is that you can’t fix a share access problem by trying to change a Unraid share security using Windows security tools on that share. If you try, you will probably make things worst! (Unless you are a Windows SMB Networking Guru…) It is important to realize that if you are denied permission to an Unraid share resource, the problem can only be fixed on the Unraid side using the Tools in the Unraid GUI (or via the command line for specific problems). If you are having an access problem to a Unraid share and can’t solve it with the tools in the GUI, start a thread in the General Support sub-forum and let the community help you fix it. EDIT: February 25, 2024. It has come to my attention that there is one more setting that was not previously covered. The Network type should be set as 'Private'. For Windows 10 Open up Settings Pick Network & Internet In right panel, click on Properties button In the Network Properties, select the 'Private' radio button. For Windows 11 Open up Settings In left panel, pick Network & Internet In the Right Panel at the top, click on Properties Under Network Profile type, click on the 'Private network' radio button EDIT: March 15, 2024 It has come to my attention that there can be problems in linking the Network Neighborhood folder into Windows File Explorer in Windows 11. While there is a solution to that problem, it has some other side effects and the full scope of those has not been evaluated. In addition, I have become aware of another way to integrate access of servers into Windows File Explorer that works quite well if you have only a few servers. (Things start to look messy if one adds more than two or three servers but that is a matter of each individual’s perception of “messy”.) So if you have having any problems with implementing "Network Neighborhood", try this new approach! This new method is actually quite simple to set up. This method is described in the attached PDF file named: “An Alternative Method to Network Neighborhood.PDF” Unraid & Windows 10 SMB Setup.pdf An Alternative Method to Network Neighborhood.pdf
 1 point
1 point -
Thank you. This will get fixed up tonight. Template error on that app....1 point
-
For anyone curious - test/beta builds are still happening - 6.12.0-rc2.11 just came out1 point
-
It's supported but you are still not able to create one using the GUI, you can import an existing pool using it, or manually add one to an Unraid pool then re-import it.1 point
-
You can try this, note that it will only work if parity is still valid: -Tools -> New Config -> Retain current configuration: All -> Apply -Check all assignments and assign any missing disk(s) if needed, including all the disks that were in the enclosure, assigned slots must the same as before to keep parity2 valid. -IMPORTANT - Check both "parity is already valid" and "maintenance mode" and start the array (note that the GUI will still show that data on parity disk(s) will be overwritten, this is normal as it doesn't account for the checkbox, but it won't be as long as it's checked) -Stop array -Unassign the disk you want to rebuild -Start array (in normal mode now), ideally the emulated disk will now mount and contents look correct, if it doesn't you should run a filesystem check on the emulated disk -If the emulated disk mounts and contents look correct stop the array -Re-assign the disk to rebuild and start array to begin.1 point
-
The FTBSkies container is causing this error to show up in the syslog when viewing the community apps tab because the icon url is broken.1 point
-
If the share needs to start using a new disk and Unraid creates it it will be a dataset.1 point
-
Also started seeing this over the last few days. Edit: Seems to show up when viewing the community apps tab. Edit2: Coming from the FTBSkies container, icon url seems borked in it.1 point
-
If it's not easy to scrub the information you may DM it to me if you're more comfortable with that. The whole file would be more helpful since it's not always obvious where the error is occurring.1 point
-
No worries, it is a point of confusion we are working to improve1 point
-
Sunshine, la partie serveur à installer sur la VM en complément de Moonlight, propose maintenant par défaut d'ouvrir une session Windows toute simple. Car le client Moonlight intègre la possibilité d'envoyer un magic packet, donc ça m'évite de me connecter sur unRAID pour démarrer la VM. Je peux le faire directement depuis ma TV via ma SHIELD et l'application Moonlight. J'ai fais le test avec ma 3090 et je n'ai pas noté de différence donc j'ai laissé comme ça aussi.1 point
-
For anyone who wants it or needs it I've uploaded 1.5.1-RC1. Change to jasonbean/guacamole:1.5.1-RC1 or jasonbean/guacamole:1.5.1-RC1-nomariadb if you'd like to try it out. Once 1.5.1 becomes final I will promote that one to "latest".1 point
-
Thank you, it works now.1 point
-
Folks don't seem to realize that Plex only uses the video encoder/decoder circuitry of the GPU's processor. All of those thousands of CUDA cores on a high end card sit idle when transcoding. The newer the card, the more (and more recent) formats it can handle. The Quadro T400 (and its predecessor P400) both can transcode h.265 which 4K is typically coded. Low cost, and low power (30W, all straight from the PCIe slot - no add'l cable needed) makes it perfect for home media servers. There are times where a more powerful card is needed. If you are running your own private Netflix and have a half dozen (or more) folks remotely transcoding at the same time, you probably need to move up to one of the Quadro's bigger brothers. Someone running facial recognition or some other AI application could possibly put the CUDA cores to use. Users who wish to do this would likely mention it in their posts, and already have an idea what they need for hardware. So it makes the Quadro T400 an easy recommendation.1 point
-
Your icloudpd container is the issue: It has the following volume mappings: ( [0] => /mnt/user/appdata/icloudpd:/config:rw [1] => /mnt/user/iCloud_Daniel:/home/user/iCloud:rw,slave [2] => /mnt/user/appdata/icloudpd/root:/root:rw ) You can see, that /root is inside the mapping for /config. So your unraid path for config is /mnt/user/appdata/icloudpd and your /root path points to /mnt/user/appdata/icloudpd/root. This causes a verification error during backup (at tars side). While it is working, it would make more sense to seperate those mapping into /mnt/user/appdata/icloudpd/root and /mnt/user/appdata/icloudpd/config. This is the 2nd time I see such issue. Maybe the plugin should remove mappings within another mapping automagically. The final backup contents would be the same - but without verification errors.1 point
-
Please attach the debug log.1 point
-
and just for clarity 1.19.4 and 1.19.2 are minecraft versions, not java versions, they are two very different things, if you want to run minecraft 1.19.2 then you would specify that using the tag name, see here for a list of tags:- https://hub.docker.com/r/binhex/arch-minecraftserver/tags1 point
-
Replace this: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x10' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </hostdev> with this: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x10' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0' multifunction='on'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x10' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x1'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x10' slot='0x00' function='0x2'/> </source> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x2'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x10' slot='0x00' function='0x3'/> </source> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x3'/> </hostdev>1 point
-
Open the terminal of the container and do nvidia-smi to check if the passthrought of the GPU is correct. There some issues on systems with 2 GPU dedicated cards so maybe this is what is happening to you. In any case, you can check the logs of the container or the logs inside the webUI to see what is wrong. About the HW accel presets, I suggest you to use this for nvidia: ffmpeg: hwaccel_args: preset-nvidia-h264 For case B (I suggest you to first have the case A running well with nvidia GPU), you must select the option 2 at the deployment (nvidia version), but first you must create the models using the same GPU that you are going to use in frigate and the APP from store called "tensorrt-models" (follow the instructions and requirements of the template). And for you info, I just maintain the frigate templates, I'm not a core developer so give the cheers to them on github not to me.1 point
-
OH MY GAWD you've just opened Pandora's box for me. Did nott know Crafty existed. This is a game-changer for me. Thank you, I have no sufficient words to express my gratitude.1 point
-
Hi, I wanted to use nix / nixos and I couldn't find any info in this thread. So here's my steps for what I did to get nixos working. It's based on the wiki here https://nixos.wiki/wiki/Proxmox_Linux_Container These steps could be stream lined for someone else, but this is what I did. If you have any suggestions on how I can improve this procedure, please let me know. 1. Download the container tarball from hydra as described on the nix wiki and save it to your unraid server. 2. Setup a new lxc container, such as ubuntu jammy. I mostly did this to get the config file. I named my container NixOS 3. cd to the NixOS folder from the unraid terminal. 4. Delete the contents of NixOS/rootfs folder (i.e. rm -rf NixOS/rootfs/*) . 5. Extract the hydra container tarball to NixOS/rootfs 6. `mkdir NixOS/rootfs/.ssh` 7. echo "your ssh public key" > NixOS/rootfs/.ssh/authoriized_keys 8. chown 0600 NixOS/rootfs/.ssh/authoriized_keys 9. Edit the config file and add this line: lxc.init.cmd = /sbin/init 10. (Optional) copy the NixOS folder to NixOS-template so that you can reuse it later. Then, you can just create copies of it 11. Start the NixOS container. Done. 12. (Optional) if you want to create a new container from your template, just copy it the NixOS-Template to it's new name, like NixOS-App. Then, edit the network address of NixOS-App/config and give it new address and modify the path of the rootfs.1 point
-
I'm not ready to fire this up and try it yet. But have been following the threads for some time now. Thanks for all of your time and effort bringing this up to date!1 point
-
It worked! You are Awesome!! Thank you so much!!1 point
-
Hallo zusammen, freut mich auch im Unraid Forum zu sein. ich arbeite mit @renegade03an dem Active Directory "Problem". ich habe derzeit die rc.samba Datei so modifiziert das ich. Der Domäne joinen kann ohne ständig das Arry zu stoppen und zu starten. Datei unten anhängend. Ich arbeite grad noch an den Windows Berechtigungen. rc.samba.new
 1 point
1 point -
I've made as suggested. 1 - Saturday morning started Unraid with only array up and docker down. 2 - At 12:00 AM I've started Docker DuckDns, Swag and MariaDB. Nextcloud off. No problems for all the next night. 3 - Sunday morning at 8:00 AM I've seen that network for MariaDB was set to Bridge instead of the other attached docker (Nextcloud and Swag have network setting with a custom network "proxy net"). Set network for MariaDB same as Nextcloud and Swag. 4 Now is Monday 10 18:54 PM and all works fine. No more problems. I think I've found the problem. Thank you.1 point
-
I managed to upgrade the Intel ME driver and all other Intel drivers, but it didn't change anything. 🙄 😔 Thank you very much @steveme for the guidance. 😇1 point
-
I am happy to announce that the next version of DFM has scheduled jobs. This feature allows to create one or more tasks and put them in a queue, which can be executed upon request. This version is a major rework to make everything possible. Quite a lot of effort was put in developing and testing to ensure correct operation is in place, but please report anything unusual. Once the queue contains operational tasks, these can be viewed by clicking on the JOBS button. Clicking the JOBS button opens a new window, which shows the scheduled jobs in the queue. The user may delete any unwanted jobs before starting, therefor select the jobs to be deleted and then click DELETE, this will reorganize the list or make the list empty when selecting and deleting all scheduled jobs. Click START to begin the schedule. Jobs are executed in the order they appear and the next job starts when the previous job is completed. There is no check for correlation between jobs, it is the responsibility of the user to make sure jobs do not interfere with each other. Once started, progress can be followed in the footer. Press the DFM icon to open the current job and see the details of the operation. To hide the window click the minimize icon at the top right and progress goes back again to the footer. When you CANCEL the job, then the current job terminates, but other jobs in the queue stay there (the queue is not emptied) and the remaining jobs can be started or revised by following the steps as explained before. Hope you like this new addition
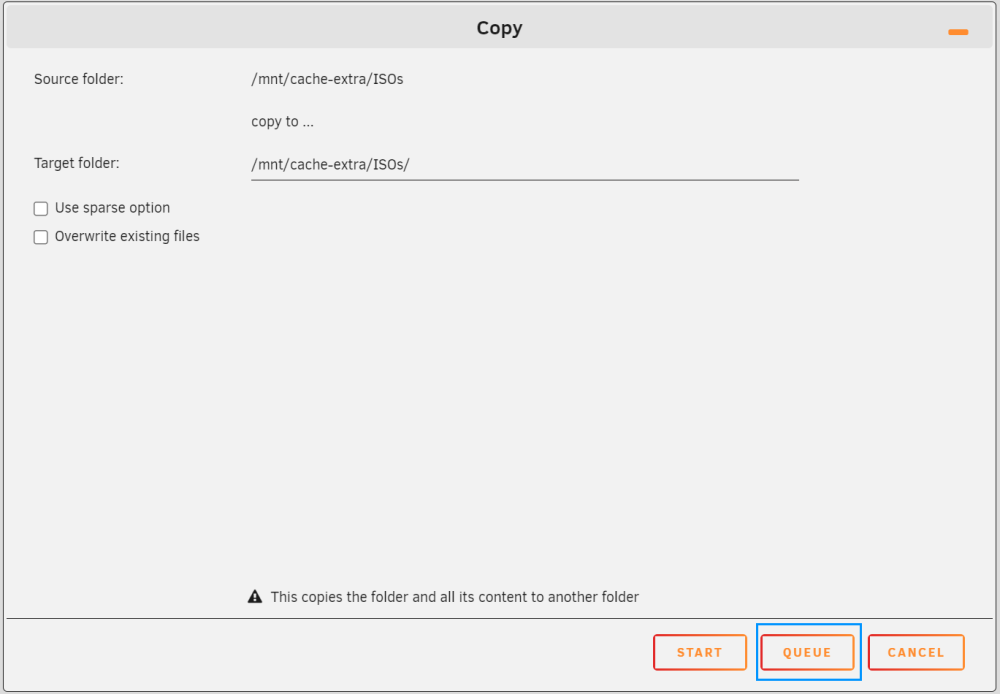

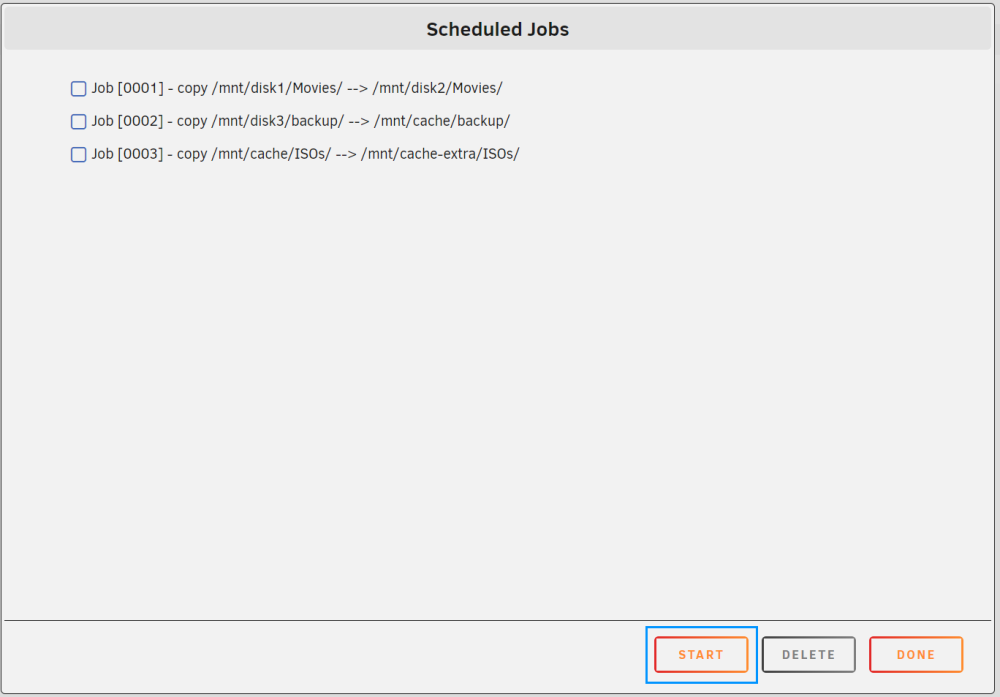

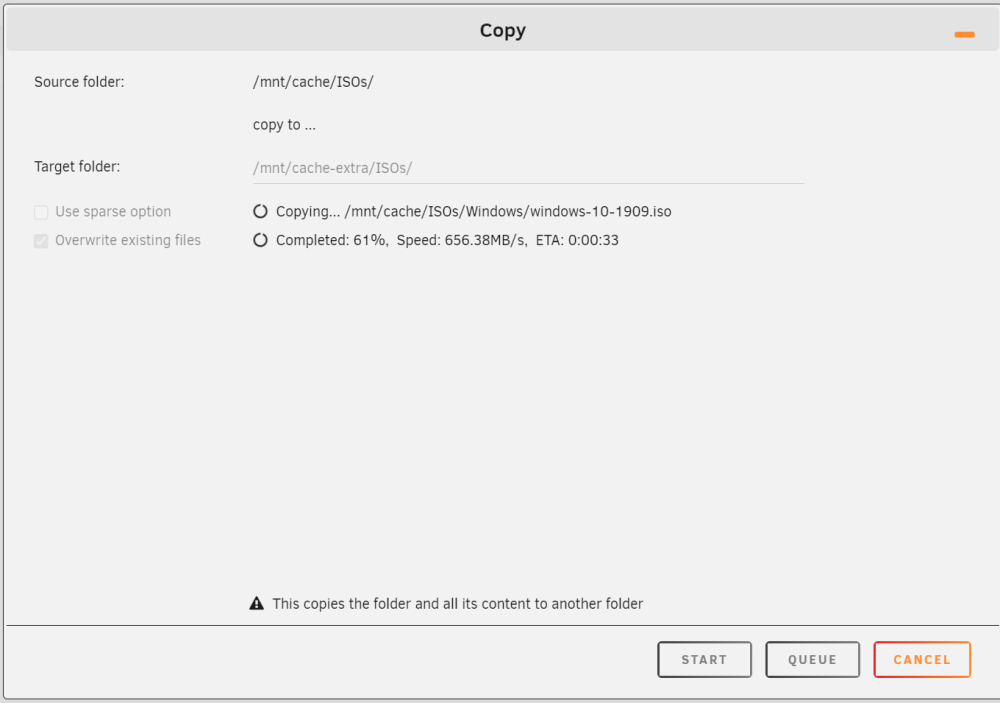 1 point
1 point -
If you are using unraid 6.12 click the little lock icon in the up right bar. Then you can move any panel where ever you want, if you are using an older version I am sorry that is not supported.
 1 point
1 point -
Well, it finally did fix/reconnect. Though the behavior of the terminal and GUI syslog behaved differently than in the past.1 point
-
Had this happen several times last month, then no issues until today. unraid-api restart will not fix it this time. 6.10.31 point
-
Not your complete problem, but you've got two SSDs (disk 1 & 2) and a spinner (parity) Reads are going to be fast, but writes will be slow. The docker image and appdata are effectively read and written to constantly, so the write penalty will be huge. You're going to be better off setting up the SSDs as a cache pool (trim isn't supported in the array). This will significantly increase your speed / response (orders of magnitude) You've got tons of "invalid opcodes" being logged. Could be simple program errors, but also could be bad memory. Run memtest for at least a couple of passes.1 point
-
Qnap makes some well priced managed and unmanaged 10g switches with various combo port (sfp/rj45) configurations. I would recommend something like QSW-M1208-8C, but you can get other configurations with 4 and 2 combo ports too. Look at the QSW series. You can also get 4C or 2C models with some 1G ports if you don't plan to expand further. These are very popular in homelab community I would go managed rather than unmanaged if you plan on learning further. No point getting hamstrung down the line Also, be aware that saturating a 10GB link is fairly difficult in a homelab setup unless you eliminate all io and processing overheads. It really only works when you have fast storage, parallel compute and are not dealing with filesystem overheads of small files1 point
-
Mainboard got me booted back up but the p220 hba has gone dark. Could be the card died at the same time as the mainboard or that the "new" mainboard has a bad pci slot. Ordered a new hba card as it was the cheapest way to test.....1 point
-
This thread is a work in progress. Updated information will be added at the top in this post. Feel free to ask questions or post further problems in this thread. Workstation information is near the bottom. Below are common problems associated with HP servers, and where available, known working fixes. I am not a certified IT technician. The information below was either discovered by scouring the Internet and/or trial and error by myself and several others on this board. Utilize this information at your own risk, though I have done almost everything discussed below. UnRaid Versions Proliants (and HP servers) should run 6.2.4 for the time being. 6.3 caused issues with CPU core numbering and other mild problems. This was due to an update in the Linux kernel or something stupid. Preliminary tests on the 6.4 release show that most if not all the problem from 6.3 have been resolved. But I would wait to update to 6.4 until the official stable release comes out. Proliants (and HP servers) should run 6.4. Many previous issues have been resolved from 6.3.x with a few minor things still prevalent. 6.5.1+ are stable and recommended. As new versions of unRaid are produced, I will update this section if there are any known issues, otherwise assume latest available works. HP Raid Controllers (P410i) Most HP raid controllers can not do JBOD. If you intend to use one, you have to use the raid controlle to create Raid-0 volumes and those are then presented to unRaid. Recovery of data then becomes more difficult. Alternatives include using a pci-e host bus adapter that works in unraid (consult the hardware wiki for working cards.) I currently use an H220, but any compatible one will do. - UPDATE July 2018- I ran into issues using H220 HBA with HP SAS Expnders on my MD1000 (which is just a box with expanders) When using unRaid ver. 6.3.x. I swapped out several H220's and sas expanders to no avail. I also attempted to to a direct connection with and 8087 to 8088 connection. It would see the enclosure but not the disks. I then swapped in an H310 in IT mode which worked using the connection adapter. I an currently running that. 2018: I determined the fault was in the md1000 enclosure. I currently run H220 adapters in 2 different servers without issues, including using an hp expander. External connectivity can be gained via an HP SAS expander or via 8087 to 8088 adapters. HP PCI-E raid cards (P212, P411) [this section untested under 6.4 and above, relevant to 6.2.4] Under certain Bios, unraid will not play nice with some HP PCI-E raid cards. This includes unRaid hanging on boot and experiencing lockup failures on the controller. If you intend to use an HP pci-e raid card, then you must update to the latest bios available on the server. BUT doing this may lead to other issues, including "Device is ineligible for IOMMU domain attach due to platform RMRR" problems. Thread on HP raid cards: -UPDATE- I was working on setting up a temporary server (DL120 G6) using an P212 and H220, just to see if it would work. The server booted on 6.2.4, 6.3.2, and 6.3.5 and showed drives on both controllers. When I attempted to setup a vm using passthrough, I modified the syslinux.cfg as required to include: append vfio_iommu_type1.allow_unsafe_interrupts=1 initrd=/bzroot From that point on, I could not get the server to complete loading unraid and kept getting errors (call traces/lockups/etc.) I gave up on combining the cards in that server and moved them to a Dell T300 that doesn't have hardware passthrough. It again booted successfully on 6.2.4, 6.3.2, and 6.3.5. So the issue does not appear to be with the cards and unraid, so much as it is an issue of needing to allow unsafe interrupts for hardware passthrough causing the issue with the cards. This was verified when I re-added the unsafe interrupts line to the syslinux.cfg and the errors returned. HP Networking Integrated gigabit ethernet seems to work in 6.2.4 when the port(s) are directly attached to the motherboard. If the port(s) are located on a riser card, drivers were implemented beginning in 6.3.x to allow functionality. VM problems - pass-through "internal error: process exited while connecting to monitor/vfio: failed to setup container for group 1/vfio: failed to get group 1/Device initialization failed" Step 1 Typically using PCIE-ACS override does not fix gpu pass-through issues. But regardless, the first step is to ensure that your video card and audio component are in their own IOMMU group. You can view the groups at Tools>System Devices, then search for the maker of your GPU. For example, my 1050 is: 09:00.0 USB controller [0c03]: Fresco Logic FL1100 USB 3.0 Host Controller [1b73:1100] (rev 10) 12:00.0 VGA compatible controller [0300]: NVIDIA Corporation GP107 [GeForce GTX 1050] [10de:1c81] (rev a1) 12:00.1 Audio device [0403]: NVIDIA Corporation Device [10de:0fb9] (rev a1) 80:00.0 PCI bridge [0604]: Intel Corporation 7500/5520/5500/X58 I/O Hub PCI Express Root Port 0 [8086:3420] (rev 22) This shows both the GPU portion and audio in set as 12:00.0 & 12:00.1. Then scroll down to the IOMMU group and verify that only those 2 device are listed their own group. /sys/kernel/iommu_groups/16/devices/0000:04:00.3 /sys/kernel/iommu_groups/17/devices/0000:12:00.0 /sys/kernel/iommu_groups/17/devices/0000:12:00.1 /sys/kernel/iommu_groups/18/devices/0000:09:00.0 In my example, they are the only 2 devices in group 17, the gpu and audio portion. Your group number and device assignment may be different. If your gpu/audio are in their own IOMMU group, SKIP to STEP 3. Step 2 If you have other devices in the same IOMMU group as your GPU, you will either need to also pass those through, or isolate your GPU/Audio into a separate group. You can try enabling PCIE-ACS override and rebooting, and rechecking. If that does not work, then disable acs override, and proceed to Step 2a: Step 2a Obtain the unique device id's of the GPU and audio component. You can view find it at Tools>System Devices, then search for the maker of your GPU. For example, my 1050 is: 09:00.0 USB controller [0c03]: Fresco Logic FL1100 USB 3.0 Host Controller [1b73:1100] (rev 10) 12:00.0 VGA compatible controller [0300]: NVIDIA Corporation GP107 [GeForce GTX 1050] [10de:1c81] (rev a1) 12:00.1 Audio device [0403]: NVIDIA Corporation Device [10de:0fb9] (rev a1) 80:00.0 PCI bridge [0604]: Intel Corporation 7500/5520/5500/X58 I/O Hub PCI Express Root Port 0 [8086:3420] (rev 22) The unique id is the 8 number at the end of the device in brackets. For my 1050, the GPU is, 10de:1c81 and the audio is 10de:0fb9. Once you have obtained your id's, you will need to edit your syslinux.cfg file. To do this, go to Main>Boot Device>Flash. Under Syslinux Configuration, edit the text there for the first "append initrd=/bzroot" to the following (XXXX:XXXX is your GPU id, YYYY:YYYY is your audio component): append pcie_acs_override=id:XXXX:XXXX,YYYY:YYYY initrd=/bzroot My complete edited syslinux.cfg file looks like: default /syslinux/menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 50 label unRAID OS menu default kernel /bzimage append pcie_acs_override=10de:1c81,10de:0fb9 initrd=/bzroot label unRAID OS GUI Mode kernel /bzimage append initrd=/bzroot,/bzroot-gui label unRAID OS Safe Mode (no plugins, no GUI) kernel /bzim3age append initrd=/bzroot unraidsafemode label unRAID OS GUI Safe Mode (no plugins) kernel /bzimage append initrd=/bzroot,/bzroot-gui unraidsafemode label Memtest86+ kernel /memtest Save and reboot. Verify that the GPU and audio component are either in their own IOMMU group, or more likely, they are each in their own independent groups (2 groups total with a single device in each.) You can try your pass-through now, but it probably won't work. Step 3 The server needs to allow "unsafe" interrupts. This is achieved by modifying the syslinux.cfg file. To do this, go to Main>Boot Device>Flash. Under Syslinux Configuration, edit the text there for the first "append initrd=/bzroot" to the following: append vfio_iommu_type1.allow_unsafe_interrupts=1 initrd=/bzroot The full syslinux.cfg would then look like: default /syslinux/menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 50 label unRAID OS menu default kernel /bzimage append vfio_iommu_type1.allow_unsafe_interrupts=1 initrd=/bzroot label unRAID OS GUI Mode kernel /bzimage append initrd=/bzroot,/bzroot-gui label unRAID OS Safe Mode (no plugins, no GUI) kernel /bzimage append initrd=/bzroot unraidsafemode label Memtest86+ kernel /memtest OR if you had to follow step 2, it would look like this default /syslinux/menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 50 label unRAID OS menu default kernel /bzimage append pcie_acs_override=10de:1c81,10de:0fb9 vfio_iommu_type1.allow_unsafe_interrupts=1 initrd=/bzroot label unRAID OS GUI Mode kernel /bzimage append initrd=/bzroot,/bzroot-gui label unRAID OS Safe Mode (no plugins, no GUI) kernel /bzimage append initrd=/bzroot unraidsafemode label unRAID OS GUI Safe Mode (no plugins) kernel /bzimage append initrd=/bzroot,/bzroot-gui unraidsafemode label Memtest86+ kernel /memtest Save and reboot. You can now try your pass-through. If the vm shows that it started on the dashboard, you're good to go. If you don't have output or distorted video, that's a non-related issue. IF if doesn't work, go to step 4. Step 4 After you have reverified that your gpu and audio component are in their own IOMMU group(s), examine your system logs after a failure to start a vm. Tools>System Log. Look at the bottom or search using your web browser for "Device is ineligible for IOMMU domain attach due to platform RMRR" If it is there, it is most likely likely your audio component listed as the problem. There are a couple ways to try to resolve it, but that depends on your hardware. According to HP, the RMRR problem stems from an upgrade to Linux above kernel version 3.16. There are discussions around the Internet about an unofficial path but with varying results. HP has a published sheet on this, with a fix for some: https://h20565.www2.hpe.com/hpsc/doc/public/display?sp4ts.oid=7271259&docId=emr_na-c04781229&docLocale=en_US If you are on Gen 8+ hardware, there is a bios fix: https://docs.hpcloud.com/hos-4.x/helion/networking/enabling_pcipt_on_gen9.html If you are pre-Gen 8 or the previous link does not work/apply you have 3 options: 1. Roll back to a previous bios. During boot, access the bios menu and select an older bios if available. It appears that bios versions that are 2011 and before do not have the RMRR issue, and pass-through of both video and audio are able to occur. 2. If you are 2012 or newer: Look online for an older bios and HP procedure to roll it back. If that is not an option, then: 3. Don't pass through the audio component of the video card. This can be achieved by following Step 2a. Then in the vm manager, only pass-through the video component to the vm, leaving out the ineligible audio device. You can get audio in your vm by utilizing a usb audio device. Not elegant, but functional. If using acs override for just the card doesn't separate out the gpu and its audio component, then try using the following acs setting instead: pcie_acs_override=multifunction 4. You may also omit the previous 3 steps and attempt to use the unRaid Proliant Edition patch located here: Further reading: Bios - Firmware Updates The 2017.04.0 SPP is the last production SPP to contain components for the G7 and Gen8 server platforms. For additional information, please refer to Reducing Server Updates. http://h20564.www2.hpe.com/hpsc/swd/public/detail?swItemId=MTX_3f6b4074ed734dc3baf007612d#tab5 At the time of writing this info, this was true, but it appears they have issues some other updates along the way, probably for mitigations or similar. I don't follow them anymore for this older hardware, so you'll have to google it for yourself to find the latest for your particular machine. Currently there is no reason to update the server rom to a "newer" bios, but you can update controller drivers/etc using the SPP. Do not use the auto installer as it will update the server rom and introduce issues outlined above. After the system runs a scan, you can select to update your ethernet/raid/etc which have shown no unwanted effects in unRaid so far. HP ProLiant DL120 G6/ProLiant DL120 G6, BIOS O26 07/01/2013 works on 6.2.4/6.4 with pass through. ACPI Error Messages Some servers complain with an error message similar to the following: Oct 28 23:06:10 Tower kernel: ACPI Error: SMBus/IPMI/GenericSerialBus write requires Buffer of length 66, found length 32 (20170531/exfield-427) Oct 28 23:06:10 Tower kernel: ACPI Error: Method parse/execution failed \_SB.PMI0._PMM, AE_AML_BUFFER_LIMIT (20170531/psparse-550) Oct 28 23:06:10 Tower kernel: ACPI Exception: AE_AML_BUFFER_LIMIT, Evaluating _PMM (20170531/power_meter-338) Bug details are here: https://community.hpe.com/t5/ProLiant-Servers-Netservers/ACPI-Error-SMBus-or-IPMI-write-requires-Buffer-of-length-66/td-p/6943959 This is essentially a misreading and does not affect anything but spamming your system log. To remove, disable "acpi_power_meter" module from the kernel by adding this line to the /boot/config/go file: rmmod acpi_power_meter HT to @perfecblue for this fix. Further reading can be done here: https://lime-technology.com/forums/topic/59375-hp-proliant-unraid-information-thread/?do=findComment&comment=634360 HPZ420 workstation info While not technically a proliant, I picked one of these up recently and here are the important discoveries: You do not need the RMRR patch If attempting to use onboard sata ports, you must use UEFI booting with unRaid. Otherwise it just sits there and blinks the cursor at you regardless of any specified boot order (3 hours of my time on that one....) Would be nice to find a fix, as per below, legacy boot is needed for some stability. I was also getting unexpected hard server resets and the following: 928- fatal pcie error pcie error deteted slot 5 completion timeout This is on a known good GPU. It would occur when shutting down a vm the GPU was assigned to. Multiple places on the Internet said possible bad board, bios error, etc. I did change some bios settings but it still happened. Only after I applied the unsafe interrupts fix from above did it stop. CPU 0 stuck at 100% usage TLDR: add the following to your syslinux.cfg acpi=force have time to read: https://lime-technology.com/forums/topic/73537-cup-0-100-on-2-different-usb-licenses/?tab=comments#comment-676484 Weird VM issues I started getting weird crashes and inability to launch vm's when the server was booting into UEFI. Returning to Legacy appears to solve the issue. I'll retest in subsequent versions of unRaid to determine if it persists (last checked 6.5.3)1 point
-
Hi All - We're aware of this issue and are looking into it. Thanks for all the reports!1 point
-
I was told to do write this " unraid-api restart My Servers Dashboard " in terminal, of course, with out quotations1 point
-
 This is Serverus. He's nestled off the ground, connected to a keyboard that's never touched and a monitor that's never on. He's a three-headed, headless beast.1 point
This is Serverus. He's nestled off the ground, connected to a keyboard that's never touched and a monitor that's never on. He's a three-headed, headless beast.1 point -
Settings, display settings - color codes in hex
 1 point
1 point -
Currently it says "Parity" as the default name and my OCD is not liking it. I'd like to request it to say "Parity 1" when there are two parity drives.
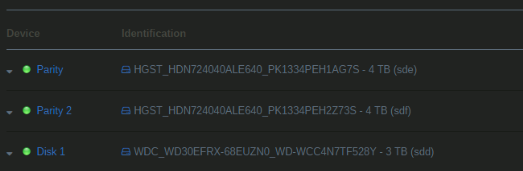 1 point
1 point -
I have Unraid 6.9.2 and have the same request in2022. I would have loved to be able to rename my disk drives or at least get the Parity 1 fixed when having more than one parity disk. At least the Manual can state that this is "not possible due to .... " because I took it for granted that I would find information on this in the documentation.1 point
-
i have these problems on different telegrammbots i use... my solution that works for me is: after entering the chat in the telegramm client, i sent theses commands: 1.) /start 2.) /get_messages_stats after these two commands i receive the testmessage from unraid
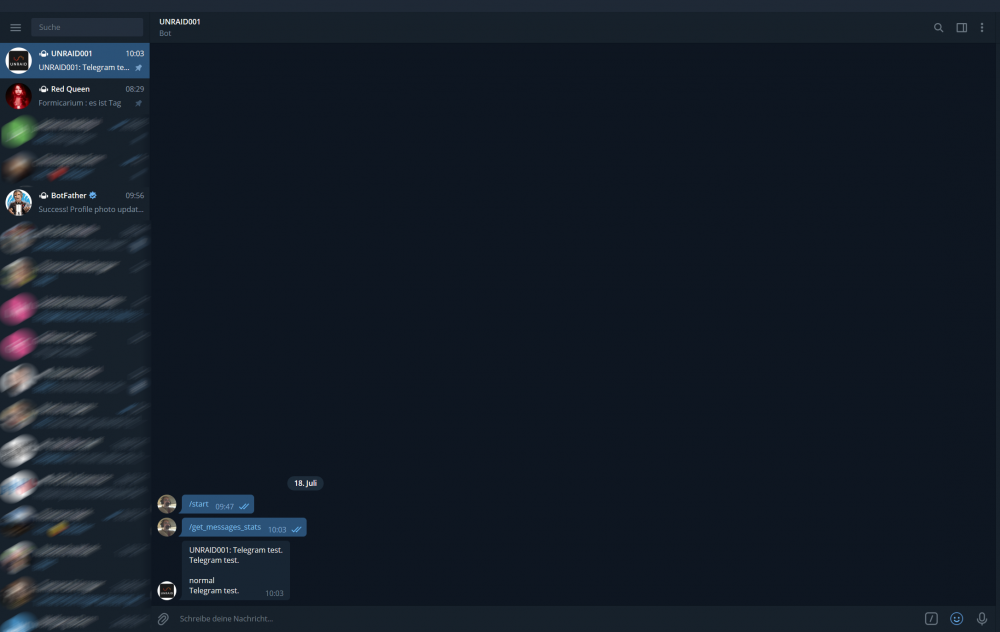 1 point
1 point -
During one of our Private Message discussions, @Batter Pudding suggested that ‘Short Sheets’ of the steps involved in each procedure could be beneficial. I know that when I am doing any multi-step procedure, I like have have a printout of the procedure and check off each step as I complete it. The attachments to this posting are the short sheets for each procedure in the document in the first post. EDIT: March 15, 2024 Added the PDF for "An Alternative Method to Network Neighborhood". How To #1-Advance Network Settings.pdf How to #2-Fixing the Windows Explorer Issue.pdf How to #3– Turning Off “SMB 1.0_CIFS File Sharing Support”.pdf How to #4-Adding a SMB User to Unraid.pdf How to #5-Adding a Windows Credential.pdf An Alternative Method to Network Neighborhood.pdf1 point
-

From the album: Community Created Banners
1 point -
You need to install the dynamix Schedules plugin to be able to adjust the Daily/Weekly/Monthly times1 point


















.thumb.jpg.9c900475a190e09178af717c36f0be14.jpg)























