Leaderboard




Popular Content
Showing content with the highest reputation since 02/21/17 in Report Comments
-
It appears that the docker images --digests --no-trunc command is showing, for whatever reason, the digest of the manifest list rather than the manifest itself for containers pushed as part of a manifest list (https://docs.docker.com/engine/reference/commandline/manifest/#create-and-push-a-manifest-list). I'm not sure if that's always been the case, or is the result of some recent change on the Docker hub API. Also not sure if it's intentional or a bug. This causes an issue since in DockerClient.php (/usr/local/emhttp/plugins/dynamix.docker.manager/include), the request made to get the comparison digest is /** * Step 4: Get Docker-Content-Digest header from manifest file */ $ch = getCurlHandle($manifestURL, 'HEAD'); curl_setopt( $ch, CURLOPT_HTTPHEADER, [ 'Accept: application/vnd.docker.distribution.manifest.v2+json', 'Authorization: Bearer ' . $token ]); which retrieves information about the manifest itself, not the manifest list. So it ends up comparing the list digest as reported by the local docker commands to the individual manifest digests as retrieved from docker hub, which of course do not match. Changing the Accept header to the list mime type: 'application/vnd.docker.distribution.manifest.list.v2+json' causes it to no longer consistently report updates available for these containers. Doing this however reports updates for all containers that do not use manifest lists, since the call now falls back to a v1 manifest if the list is not available and the digest for the v1 manifest doesn't match the digest for the v2 manifest. If the Accept header is instead changed to 'application/vnd.docker.distribution.manifest.list.v2+json,application/vnd.docker.distribution.manifest.v2+json' docker hub will fallback correctly to the v2 manifest, and the digests now match the local output for both containers using straight manifests and those using manifest lists. Until docker hub inevitably makes another change. /** * Step 4: Get Docker-Content-Digest header from manifest file */ $ch = getCurlHandle($manifestURL, 'HEAD'); curl_setopt( $ch, CURLOPT_HTTPHEADER, [ 'Accept: application/vnd.docker.distribution.manifest.list.v2+json,application/vnd.docker.distribution.manifest.v2+json', 'Authorization: Bearer ' . $token ]);21 points
-
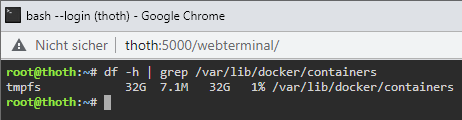
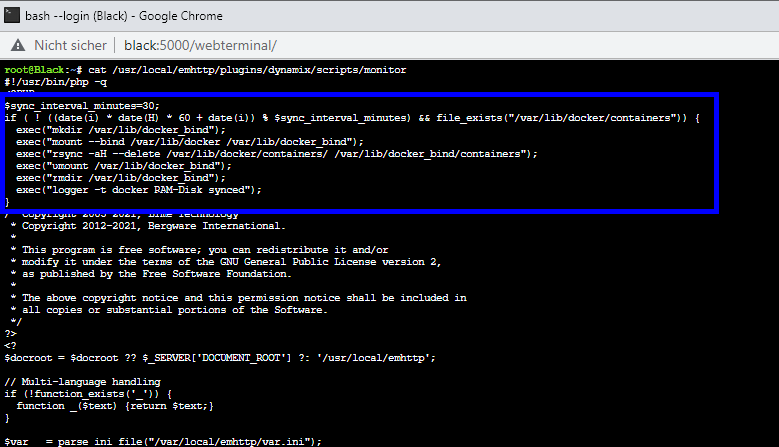
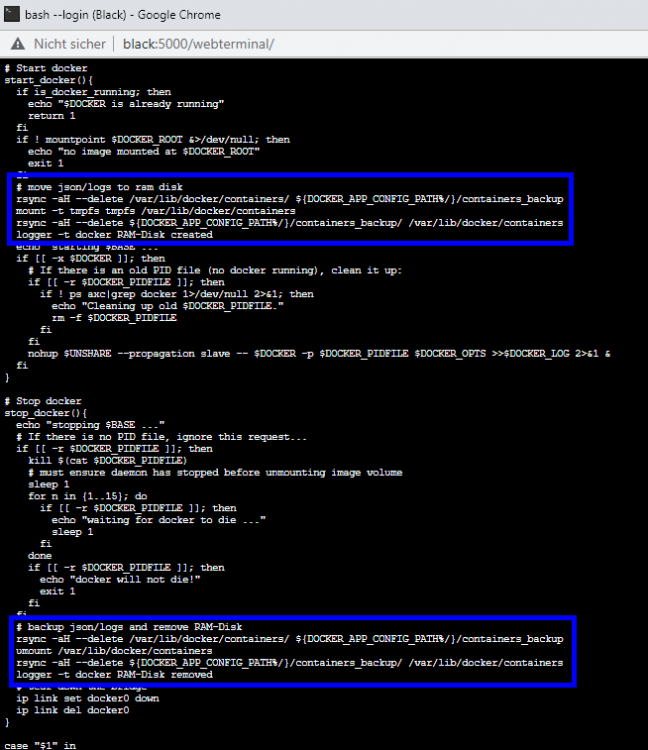
@limetech I solved this issue as follows and successfully tested it in: Unraid 6.9.2 Unraid 6.10.0-rc1 Add this to /boot/config/go (by Config Editor Plugin): Optional: Limit the Docker LOG size to avoid using too much RAM: Reboot server Notes: By this change /var/lib/docker/containers, which contains only status and log files, becomes a RAM-Disk and therefore avoids wearing out your SSD and allows a permanent sleeping SSD (energy efficient) It automatically syncs the RAM-Disk every 30 minutes to your default appdata location (for server crash / power-loss scenarios). If container logs are important to you, feel free to change the value of "$sync_interval_minutes" in the above code to a smaller value to sync the RAM-Disk every x minutes. If you like to update Unraid OS, you should remove the change from the Go File until it's clear that this enhancement is still working/needed! Your Reward: After you enabled the docker service you can check if the RAM-Disk has been created (and its usage): Screenshot of changes in /etc/rc.d/rc.docker and /usr/local/emhttp/plugins/dynamix/scripts/monitor


 20 points
20 points -
I’ve been around a little while. I always follow the boards even though I have very little life time to give to being active in the community anymore. I felt the need to post to say I can completely appreciate how the guys at @linuxserver.io feel. I was lucky enough to be apart of the team @linuxserver.iofor a short while and I can personally attest to how much personal time and effort they put into development, stress testing and supporting their developments. While @limetech has developed a great base product i think it’s right to acknowledge that much of the popularity and success of the product is down as much to community development and support (which is head and shoulders above by comparison) as it is to the work of the company. As a now outsider looking in, my personal observation is that the use of unRAID exploded due to the availability of stable, regularly updated media apps like Plex (the officially supported one was just left to rot) and then exploded again with the emergence of the @linuxserver.ionVidia build and the support that came with it. Given the efforts of the community and groups like @linuxserver.io is even used in unRAID marketing I feel this is a show of poor form. I feel frustrated at Tom’s “I didn’t know I needed permission ....” comment as it isn’t about that. It’s about respect and communication. A quick “call” to the @linuxserver.io team to let them know of the plan (yes I know the official team don’t like sharing plans at risk of setting expectations they then won’t meet) to (even privately) acknowledge the work that has (and continues to) contribute to the success of unRAID and let them be a part of it would have cost Nothing but would have been worth so much. I know the guys would have been supporting too. I hope the two teams can work it out and that @limetech don’t forget what (and who) helped them get to where they are and perhaps looks at other companies who have alienated their community through poor decisions and communication. Don’t make this the start of a slippery slide.19 points
-
I do not use any of these unofficial builds, nor do i know what they are about and what features they provide that are not included in stock unraid. That being said, i still feel that devs that release them have a point. I think the main issue are these statements by @limetech : "Finally, we want to discourage "unofficial" builds of the bz* files." which are corroborated by the account of the 2019 pm exchange: "concern regarding the 'proliferation of non-stock Unraid kernels, in particular people reporting bugs against non-stock builds.'" Yes technically its true that bug reports based on unofficial builds complicate matters. Also its maybe frustrating that people are reluctant to go the extra mile to go back to stock unraid and try to reproduce the error there. Especially since they might be convinced (correctly or not) it has nothing to do with the unoffial build. Granted from an engineers point of view that might be seen as a nuisance. But from a customer driven business point of view its a self destructive perspective. Obviously these builds fill a need that unraid could not, or else they would not exist and there wouldn't be enough people using them to be a "bug hunting" problem in the first place. They expand unraids capabilities, bring new customers to unraid, demonstrate a lively and active community and basically everything i love about unraid. I think @limetech did not mean it in that way, but i can fully see how people who poured a lot of energy and heart into the unraid ecosystem might perceive it that way. I think if you would have said instead: "Finally we incorporated these new features x,y, and z formerly only available in the builds by A, B and C. Thanks again for your great work A,B and C have being doing for a long while now and for showing us in what way we can enhance unraid for our customers. I took a long time, but now its here. It should also make finding bugs more easy, as many people can now use the official builds." then everybody would have been happy. I think its probably a misunderstanding. I can't really imagine you really wanting to discourage the community from making unraid reach out to more user.17 points
-
Below I include my Unraid (Version: 6.10.0-rc1) "Samba extra configuration". This configuration is working well for me accessing Unraid shares from macOS Monterey 12.0.1 I expect these configuration parameters will work okay for Unraid 6.9.2. The "veto" commands speed-up performance to macOS by disabling Finder features (labels/tags, folder/directory views, custom icons etc.) so you might like to include or exclude these lines per your requirements. Note, there are problems with samba version 4.15.0 in Unraid 6.10.0-rc2 causing unexpected dropped SMB connections… (behavior like this should be anticipated in pre-release) but fixes expected in future releases. This configuration is based on a Samba configuration recommended for macOS users from 45Drives here: KB450114 – MacOS Samba Optimization. #unassigned_devices_start #Unassigned devices share includes include = /tmp/unassigned.devices/smb-settings.conf #unassigned_devices_end [global] vfs objects = catia fruit streams_xattr fruit:nfs_aces = no fruit:zero_file_id = yes fruit:metadata = stream fruit:encoding = native spotlight backend = tracker [data01] path = /mnt/user/data01 veto files = /._*/.DS_Store/ delete veto files = yes spotlight = yes My Unraid share is "data01". Give attention to modifying the configuration for your particular shares (and other requirements). I hope providing this might help others to troubleshoot and optimize SMB for macOS.14 points
-
I like to highlight other improvements available in 6.10, which are maybe not so obvious to spot from the release notes and some of these improvements are internal and not really visible. - Event driven model to obtain server information and update the GUI in real-time The advantage of this model is its scalability. Multiple browsers can be opened simultaneously to the GUI without much impact In addition stale browser sessions won't create any CSRF errors anymore People who keep their browser open 24/7 will find the GUI stays responsive at all times - Docker labels Docker labels are added to allow people using Docker compose to make use of icons and GUI access Look at a Docker 'run' command output to see exactly what labels are used - Docker custom networks A new setting for custom networks is available. Originally custom networks are created using the macvlan mode, and this mode is kept when upgrading to version 6.10 The new ipvlan mode is introduced to battle the crashes some people experience when using macvlan mode. If that is your case, change to ipvlan mode and test. Changing of mode does not require to reconfigure anything on Docker level, internally everything is being taken care off. - Docker bridge network (docker0) docker0 now supports IPv6. This is implemented by assigning docker0 a private IPv6 subnet (fd17::/64), similar to what is done for IPv4 and use network translation to communicate with the outside world Containers connected to the bridge network now have both IPv4 and IPv6 connectivity (of course the system must have IPv6 configured in the network configuration) In addition several enhancements are made in the IPv6 implementation to better deal with the use (or no-use) of IPv6 - Plugins page The plugins page now loads information in two steps. First the list of plugins is created and next the more time consuming plugin status field is retrieved in the background. The result is a faster loading plugins page, especially when you have a lot of plugins installed - Dashboard graphs The dashboard has now two graphs available. The CPU graph is displayed by default, while the NETWORK graph is a new option under Interface (see the 'General Info' selection) The CPU graph may be hidden as well in case it is not desired Both graphs have a configurable time-line, which is by default 30 seconds and can be changed independently for each graph to see a longer or shorter history. Graphs are updated in real-time and are useful to observe the behavior of the server under different circumstances14 points
-
For Unraid version 6.10 I have replaced the Docker macvlan driver for the Docker ipvlan driver. IPvlan is a new twist on the tried and true network virtualization technique. The Linux implementations are extremely lightweight because rather than using the traditional Linux bridge for isolation, they are associated to a Linux Ethernet interface or sub-interface to enforce separation between networks and connectivity to the physical network. The end-user doesn't have to do anything special. At startup legacy networks are automatically removed and replaced by the new network approach. Please test once 6.10 becomes available. Internal testing looks very good so far.13 points
-
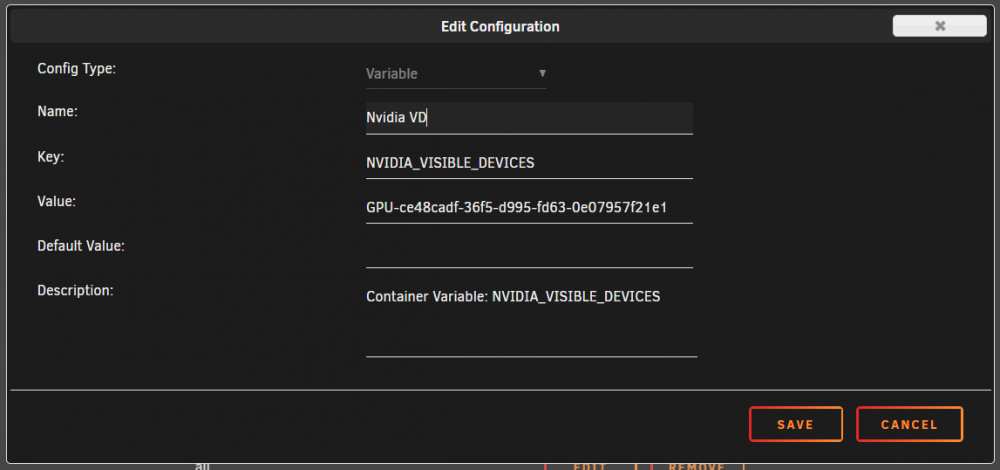
Just a little feedback on upgrading from Unraid Nvidia beta30 to beta35 with Nvidia drivers plugin. The process was smooth and I see no stability or performance issue after 48h, following these steps : - Disable auto-start on "nvidia aware" containers (Plex and F@H for me) - Stop all containers - Disable Docker engine - Stop all VMs (none of them had a GPU passthrough) - Disable VM Manager - Remove Unraid-Nvidia plugin - Upgrade to 6.9.0-beta35 with Tools>Update OS - Reboot - Install Nvidia Drivers plugin from CA (be patient and wait for the "Done" button) - Check the driver installation (Settings>Nvidia Drivers, should be 455.38, run nvidia-smi under CLI). Verify the GpuID is unchanged, which was the case for me, otherwise the "NVIDIA_VISIBLE_DEVICES" variable should be changed accordingly for the relevant containers - Reboot - Enable VM Manager, restart VMs and check them - Enable Docker engine, start Plex and F@H - Re-enable autostart for Plex and F@H All this is perhaps a bit over-cautious, but at least I can confirm I got the expected result, i.e. an upgraded server with all functionalities up and running under 6.9.0-beta35 !13 points
-
I know this likely won't matter to anyone but I've been using unraid for just over ten years now and I'm very sad to see how the nvidia driver situation has been handled. While I am very glad that custom builds are no longer needed to add the nvidia driver, I am very disappointed in the apparent lack of communication and appreciation from Limetech to the community members that have provided us with a solution for all the time Limetech would not. If this kind of corporate-esque "we don't care" attitude is going to be adopted then that removes an important differentiating factor between Unraid and Synology, etc. For some of us, cost isn't a barrier. Unraid has an indie appeal with good leaders and a strong community. Please understand how important the unraid community is and appreciate those in the community that put in the time to make unraid better for all of us.13 points
-
The corruption occurred as a result of failing a read-ahead I/O operation with "BLK_STS_IOERR" status. In the Linux block layer each READ or WRITE can have various modifier bits set. In the case of a read-ahead you get READ|REQ_RAHEAD which tells I/O driver this is a read-ahead. In this case, if there are insufficient resources at the time this request is received, the driver is permitted to terminate the operation with BLK_STS_IOERR status. Here is an example in Linux md/raid5 driver. In case of Unraid it can definitely happen under heavy load that a read-ahead comes along and there are no 'stripe buffers' immediately available. In this case, instead of making calling process wait, it terminated the I/O. This has worked this way for years. When this problem first happened there were conflicting reports of the config in which it happened. My first thought was an issue in user share file system. Eventually ruled that out and next thought was cache vs. array. Some reports seemed to indicate it happened with all databases on cache - but I think those reports were mistaken for various reasons. Ultimately decided issue had to be with md/unraid driver. Our big problem was that we could not reproduce the issue but others seemed to be able to reproduce with ease. Honestly, thinking failing read-aheads could be the issue was a "hunch" - it was either that or some logic in scheduler that merged I/O's incorrectly (there were kernel bugs related to this with some pretty extensive patches and I thought maybe developer missed a corner case - this is why I added config setting for which scheduler to use). This resulted in release with those 'md_restrict' flags to determine if one of those was the culprit, and what-do-you-know, not failing read-aheads makes the issue go away. What I suspect is that this is a bug in SQLite - I think SQLite is using direct-I/O (bypassing page cache) and issuing it's own read-aheads and their logic to handle failing read-ahead is broken. But I did not follow that rabbit hole - too many other problems to work on13 points
-
Version 6.11.0-rc5 2022-09-12 Bug fixes Ignore "ERROR:" strings mixed in "btrfs filesystem show" command output. This solves problem where libblkid could tag a parity disk as having btrfs file system because the place it looks for the "magic number" happens to matches btrfs. Subsequent "btrfs fi" commands will attempt to read btrfs metadata from this device which fails because there really is not a btrfs filesystem there. Base distro: cracklib: version 2.9.8 curl: version 7.85.0 ethtool: version 5.19 fuse3: version 3.12.0 gawk: version 5.2.0 git: version 2.37.3 glibc-zoneinfo: version 2022c grep: version 3.8 hdparm: version 9.65 krb5: version 1.19.3 libXau: version 1.0.10 libXfont2: version 2.0.6 libXft: version 2.3.6 libdrm: version 2.4.113 libfontenc: version 1.1.6 libglvnd: version 1.5.0 libssh: version 0.10.4 libtasn1: version 4.19.0 mcelog: version 189 nghttp2: version 1.49.0 pkgtools: version 15.1 rsync: version 3.2.6 samba: version 4.16.5 sqlite: version 3.39.3 Linux kernel: version 5.19.7 CONFIG_BPF_UNPRIV_DEFAULT_OFF: Disable unprivileged BPF by default CONFIG_SFC_SIENA: Solarflare SFC9000 support CONFIG_SFC_SIENA_MCDI_LOGGING: Solarflare SFC9000-family MCDI logging support CONFIG_SFC_SIENA_MCDI_MON: Solarflare SFC9000-family hwmon support CONFIG_SFC_SIENA_SRIOV: Solarflare SFC9000-family SR-IOV support patch: quirk for Team Group MP33 M.2 2280 1TB NVMe (globally duplicate IDs for nsid) turn on all IPv6 kernel options CONFIG_INET6_* CONFIG_IPV6_* Management: SMB: remove NTLMv1 support since removed from Linux kernel startup: Prevent installing downgraded versions of packaages which might exist in /boot/extra webgui: VM Manager: Add boot order to GUI and CD hot plug function webgui: Docker Manager: add ability to specify shell with container label. webgui: fix: Discord notification agent url webgui: Suppress info icon in banner message when no info is available webgui: Add Spindown message and use -n for identity if scsi drive. webgui: Fix SAS Selftest webgui: Fix plugin multi updates12 points
-
Someone please help me understand this? What if I don't wanna associate my keys and my home installs with my unraid forum account? I really like my privacy honestly and what is is my home have no business being associated with any cloud or external servers. This is a very slippery slope and I just don't like it. Is there an option to continue be offline just the way I am right now? I just don't want to be part of this new ecosystem unraid is creating. I trust my privacy and I trust no one, I am sorry..... And there’s absolutely no reason why you can’t support both ways of activating / running unraid. I should not be forced to connect with you if I have a valid key. "UPC and My Servers Plugin The most visible new feature is located in the upper right of the webGUI header. We call this the User Profile Component, or UPC. The UPC allows a user to associate their server(s) and license key(s) with their Unraid Community forum account. Starting with this release, it will be necessary for a new user to either sign-in with existing forum credentials or sign-up, creating a new account via the UPC in order to download a Trial key. All key purchases and upgrades are also handled exclusively via the UPC"12 points
-
I wonder if I need to enter the NO HEALTHCHECK parameter for all these containers? Will they work stably after that?
 12 points
12 points -
Everyone please take a look here: I want to request that any further discussion on this to please take place in that topic.12 points
-
Since the UPC seems to be stirring up a lot of adverse reaction, maybe the easiest option is to set up a setting under either Settings->Identification or Settings->Management Access (whichever is deemed most appropriate) to remove the Login prompt from the top of the GUI? It can then be defaulted to Enabled until explicitly disabled by the user so new users see it is an option. That might also help with making it clearer that this is purely an optional feature11 points
-
As a user of Unraid I am very scared about the current trends. Unraid as a base it is a very good server operating system but what makes it special are the community applications. I would be very sad if this breaks apart because of maybe wrong or misunderstandable communication. I hope that everyone will get together again. For us users you would make us all a pleasure. I have 33 docker containers and 8 VM running on my system and I hope that my system will continue to be as usable as before. I have many containers from linuxserver.io. I am grateful for the support from limetech & the whole community and hope it will be continued. sorry for my english i hope you could understand me.11 points
-
Thanks for the fix @bluemonster ! Here is a bash file that will automatically implement the fix in 6.7.2 (and probably earlier, although I'm not sure how much earlier): https://gist.github.com/ljm42/74800562e59639f0fe1b8d9c317e07ab It is meant to be run using the User Scripts plugin, although that isn't required. Note that you need to re-run the script after every reboot. Remember to uninstall the script after you upgrade to Unraid 6.8 More details in the script comments.11 points
-
NOTE Any plugin which has been hacking its way into the dashboard has now been marked as being incompatible. These plugins: GPU Stats, Corsair Power Supply, Disk Location and Plex Streams now actually crash the dashboard and it is highly recommended to uninstall them. They will not be available again via Apps until such time as the respective authors update their plugins to be compatible and notify me of this. Also ensure that all other plugins are up to date. Notably, NUT and IPMI (versions from dmacias) will also crash the dashboard, but replacements for these are available within CA (from SimonF)10 points
-
An interesting read regards THP, which looks to be triggering the crash:- https://blog.nelhage.com/post/transparent-hugepages/ if you are feeling brave then you can try the following to disable THP which SHOUILD then prevent the crash without the need to downgrade libtorrent:- drop to 'terminal' for unraid (not the containers console) and copy and paste the following:- echo '# temporarily disable hugepages to prevent libtorrent crash with unraid 6.11.x' >> /boot/config/go echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /boot/config/go echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /boot/config/go then reboot your system, and then run the following to confirm THP is disabled:- grep -i HugePages_Total /proc/meminfo # output should be 0 cat /proc/sys/vm/nr_hugepages # output should be 0 from the article linked above this MAY actually increase your performance!, or at the very worst you may see a 10% drop in performance (depends on usage). keep in mind the above is a temporary hack, libtorrent/kernel/app will no doubt resolve this issue at some point, im simply posting this as a workaround for now, so you will then need to remove the above from your go file and reboot to reverse this hack.10 points
-
You know you could have discussed this with me right? Remember me, the original dev, along with @bass_rock! The one you tasked @jonp to discuss how we achieved the Nvidia builds back in December last year? That I never heard anything more about. I'm the one that spend 6 months f**king around with Unraid to get the GPU drivers working in docker containers. The one that's been hosting literally 100s of custom Unraid builds for the community to use for nearly five years. With all due respect to @ich777 he wasn't the one who did the bulk of the work here. Remember? You'll be pleased to know I will no longer be producing any custom "unofficial" builds for all the things you've not wanted to pick up and support for the last 10 years. A bit like unassigned devices and @dlandon, hell that should have been incorporated half a decade ago. In fact, I won't be doing anything here from this point on. Nearly 5 years of DVB and nearly 2 years of Nvidia. You're welcome to them. DVB is all yours now as well. Good Luck.10 points
-
Version 6.11.0-rc3 2022-08-06 Important: The Linux Community has deprecated reiserfs, and has scheduled it to be removed from the kernel in 2025. Improvements Spin down for non-rotational devices now places those devices in standby mode if supported by the device. Similarly, spin up, or any I/O to the device will restore normal operation. Display NVMe device capabilities obtained from SMART info. Added necessary kernel CONFIG options to support Sr-iov with mellanox connectx4+ cards Bug fixes Quit trying to spin down devices which do not support standby mode. Fixed AD join issued caused by outdated cyras-sasl library Do not start mcelog daemon if CPU is unsupported (most AMD processors). Change Log vs. 6.11.0-rc2 Base distro: aaa_glibc-solibs: version 2.36 cyrus-sasl: version 2.1.28 cryptsetup: version 2.5.0 glibc: version 2.36 gnutls: version 3.7.7 harfbuzz: version 5.1.0 iproute2: version 5.19.0 libevdev: version 1.13.0 nano: version 6.4 nettle: version 3.8.1 rpcbind: version 1.2.6 sysvinit-scripts: version 15.1 talloc: version 2.3.4 tevent: version 0.13.0 util-linux: version 2.38.1 Linux kernel: version 5.18.16 CONFIG_FIREWIRE: FireWire driver stack CONFIG_FIREWIRE_OHCI: OHCI-1394 controllers CONFIG_FIREWIRE_SBP2: Storage devices (SBP-2 protocol) CONFIG_FIREWIRE_NET: IP networking over 1394 CONFIG_INPUT_UINPUT: User level driver support CONFIG_INPUT_JOYDEV: Joystick interface CONFIG_INPUT_JOYSTICK: Joysticks/Gamepads CONFIG_JOYSTICK_XPAD: X-Box gamepad support CONFIG_JOYSTICK_XPAD_FF: X-Box gamepad rumble support CONFIG_JOYSTICK_XPAD_LEDS: LED Support for Xbox360 controller 'BigX' LED CONFIG_TLS: Transport Layer Security support CONFIG_TLS_DEVICE: Transport Layer Security HW offload CONFIG_TLS_TOE: Transport Layer Security TCP stack bypass CONFIG_NET_SWITCHDEV: Switch (and switch-ish) device support CONFIG_MLX5_TLS: Mellanox Technologies TLS Connect-X support CONFIG_VMD: Intel Volume Management Device Driver Management: emhttpd: improve stanby (spinning) support webgui: Update Disk Capabilities pages for NVME drives webgui: chore(upc): v1.6.09 points
-
Next release of 6.9 will be on Linux 5.9 kernel, hopefully that will be it before we can go to 'stable' (because Linux 5.8 kernel was recently marked EOL).9 points
-
Before anyone else beats me to it: Soon™9 points
-
This sums up my stance too. I can understand LimeTechs view as to why they didnt feel the need to communicate this to the other parties involved (as they never officially asked them to develop the solution they'd developed and put in place). But on the flip side the appeal of UnRaid is the community spirit and drive to implement things which make the platform more useful. It wouldnt have taken a lot to give certain members in community a heads up that this was coming, and to give credit where credit is due in the release notes. Something along the lines of: "After seeing the appeal and demand around 3rd party driver integration with unraid as its matured over recent years we've introduced a mechanism to bring this into the core OS distribution. We want to thank specific members of the community such as @CHBMB and @bass_rock who've unofficially supported this in recent times and which drove the need to implement this in a way which allows better support for the OS as a whole for the entire community, and remove the need for users to use unofficial builds." Also for them to be given a heads up and at least involved in the implementation stages at an advisory or review level as well... Anyway, I hope this communication mishap can be resolved. It was obviously not intentional, and 2020 as a whole has meant we're all stressed and overworked (I am anyway!), so it makes situations like this a lot easier to trigger. Hopefully lessons can be learned here and changes similar to this can be managed with a little more community involvement going forward.9 points
-
Just wanted to share a quick success story. Previously (and for the past few releases now) I was using @ich777's Kernel Docker container to compile with latest Nvidia. Excited now to see this be brought in natively, it worked out of the box for me. I use the regular Plex docker container for HW transcoding (adding --runtime=nvidia in the extra parameters and setting properly the two container variables NVIDIA_VISIBLE_DEVICES and NVIDIA_DRIVER_CAPABILITIES). To prepare for this upgrade, while still on beta 30: - disabled docker service - upgraded to beta 35 - uninstalled Kernel Helper Plugin - uninstalled Kernel Helper Docker - rebooted - Installed Nvidia Drivers from CA - rebooted - reenabled docker So far all is working fine on my Quadro P2200 Install Nvidia Drivers Docker Settings: Validate in Settings (P2200 and drivers detected fine) HW transcoding working fine
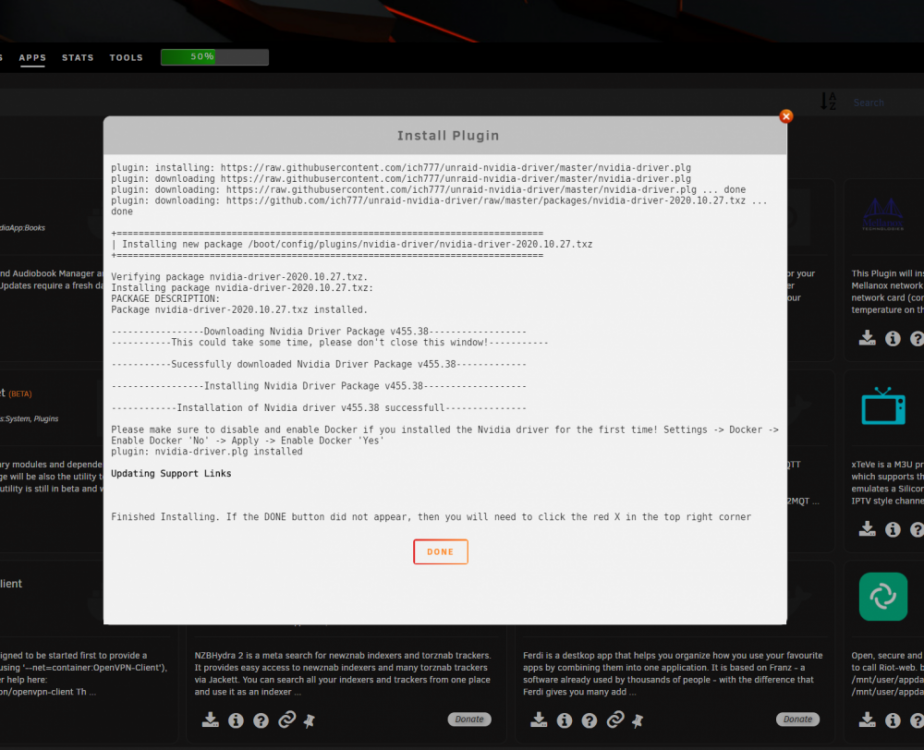
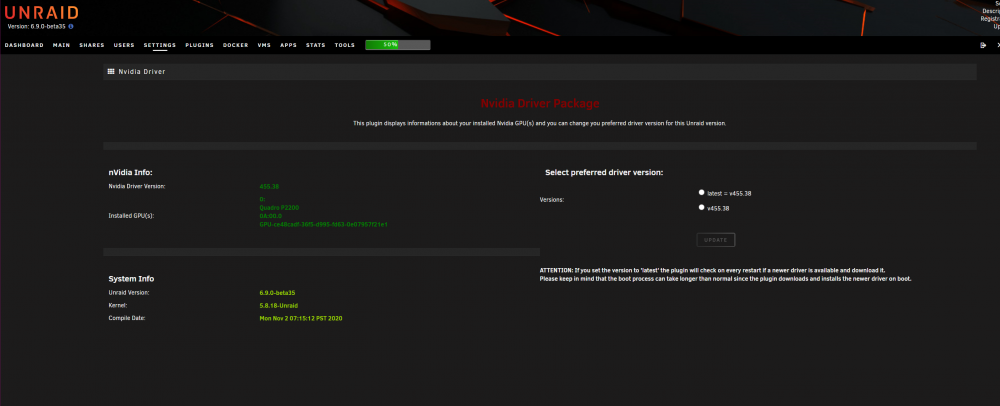
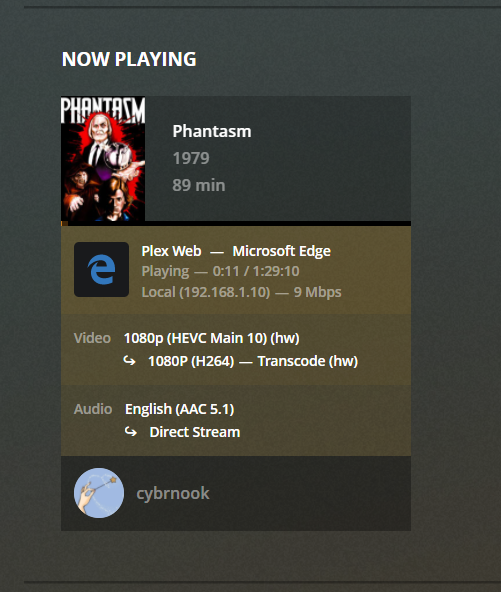


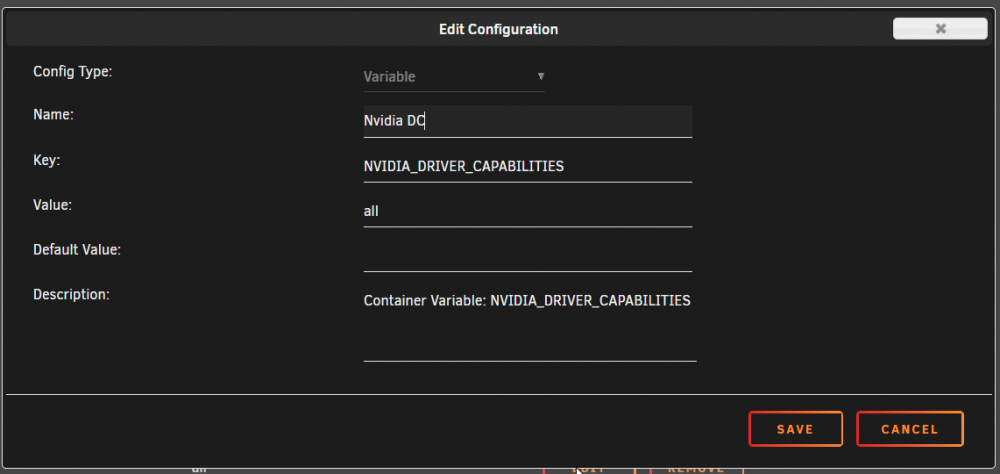
 9 points
9 points -
Normal humans often can't see all the ways messaging can be interpreted (this is why we have comms people) The most offensive sounding things are often not intended in that fashion at all. Written text makes communication harder because there are no facial or audio cues to support the language I expected our community developers (being that they've clearly communicated in text behind screens for many years) would understand that things aren't always intended as they sound. In this regard, I support @limetech wholeheartedly. Nevertheless the only way to fix this is probably for @limetech to privately offer an apology and discuss as a group how to fix, then publish back together that it's resolved. (30 years managing technical teams - seen this a few times and it's usually sorted out with an apology and a conversation).9 points
-
@limetech Not wanting to dogpile on to you, but you would do well to go above and beyond in rectifying the situation with any communality developers that have issues. The community plugins and features that supply so much usability and functionality to unraid that are lacking in the base product actually make unraid worth paying for. if you start loosing community support, you will start to loose it all. with that I am sure I and others will not recommend people to purchase and use your software. @CHBMB @aptalca @linuxserver.io Maybe a cool down period is needed, but don't just pack up your things and go home, it's all too common for companies to ignore users and communities, a large part of the community is often invisible to them hidden behind keeping the business running and profits. it makes it easy for customer facing employees to make statements that might be taken as insensitive.9 points
-
Install the referenced plugin. It will install the Nvidia driver and tools needed for transcoding in Docker containers. If you don't care about this, no need to deal with it. The plugin is more of a "work in process" right now and will mature over time, including being added to Community Apps. We didn't include the Nvidia vendor driver built-in to the release for several reasons: The package is very large, over 200MB and no need for everyone to download this thing if they don't need it. Including the driver "taints" the Linux kernel. There is something of a longstanding war between the Linux community and Nvidia because large parts of the Nvidia are not open source. Due to how the driver has to integrate into the kernel, this "taints" the kernel. For us it means if we have an kernel-related issues, no developer will help out if they see the kernel is tainted. Also don't want that message appearing in syslog by default The Nvidia driver might change faster than we want to update Linux kernel. In this case we can build and publish a new driver independent of Unraid OS release.9 points
-
Great news. Crazy how they constantly focus on features benefiting more than 1% of the maximum userbase, right. 🤪9 points
-
https://github.com/electrified/asus-wmi-sensors <- this would be nice to for 6.9 for ASUS peoples. It directly reads the WMI interface that ASUS has moved to and displays all sensors properly.(Supposedly)9 points
-
Preparing another release. Mondays are always very busy but will try to get it out asap.9 points
-
If all you have is the array, and no cache or other pools, then your Primary is the array, and secondary is none If you have a pool named 'cache', then cache:no = Primary:array, Secondary:none cache:only = Primary:cache, Secondary:none cache:yes = Primary:cache, Secondary:array, Mover action: cache->array cache:prefer = Primary:cache, Secondary:array, Mover action: array->cache Just substitute another pool name for 'cache' above for other pools.8 points
-
Version 6.11.0-rc4 2022-08-23 Improvements Merged Dynamix SSD Trim plugin into Unraid OS webGUI. Preliminary support for cgroup2. Pass 'unraidcgroup2' on syslinux append line to activate. Included perl in base disro. Bug fixes Fix nginx not recognizing SSL certificate renewal. wireguard: check the reachability of the gateway (next-hop) before starting the WG tunnel. Base distro: bind: version 9.18.6 btrfs-progs: version 5.19 cifs-utils: version 7.0 git: version 2.37.2 glibc-zoneinfo: version 2022b gdk-pixbuf2: version 2.42.9 gtk+3: version 3.24.34 iperf3: version 3.11 kernel-firmware: version 20220810_ad5ae82 libdrm: version 2.4.112 libffi: version 3.4.2 libglvnd: version 1.4.0 libjpeg-turbo: version 2.1.4 libnftnl: version 1.2.3 libnl3: version 3.7.0 libtirpc: version 1.3.3 libwebp: version 1.2.4 libxcvt: version 0.1.2 libxslt: version 1.1.36 mcelog: version 188 nfs-utils: version 2.6.2 nginx: version 1.22.0 nchan: version 1.3.0 pango: version 1.50.9 perl: version 5.36.0 rsync: version 3.2.5 sysstat: version 12.6.0 xf86-input-synaptics: version 1.9.2 xf86-video-mga: version 2.0.1 xorg-server: version 21.1.4 xz: version 5.2.6 Linux kernel: version 5.19.3 added additional sensor drivers: CONFIG_AMD_SFH_HID: AMD Sensor Fusion Hub CONFIG_SENSORS_AQUACOMPUTER_D5NEXT: Aquacomputer D5 Next watercooling pump CONFIG_SENSORS_MAX6620: Maxim MAX6620 fan controller CONFIG_SENSORS_NZXT_SMART2: NZXT RGB & Fan Controller/Smart Device v2 CONFIG_SENSORS_SBRMI: Emulated SB-RMI sensor CONFIG_SENSORS_SHT4x: Sensiron humidity and temperature sensors. SHT4x and compat. CONFIG_SENSORS_SY7636A: Silergy SY7636A CONFIG_SENSORS_INA238: Texas Instruments INA238 CONFIG_SENSORS_TMP464: Texas Instruments TMP464 and compatible CONFIG_SENSORS_ASUS_WMI: ASUS WMI X370/X470/B450/X399 CONFIG_SENSORS_ASUS_WMI_EC: ASUS WMI B550/X570 CONFIG_SENSORS_ASUS_EC: ASUS EC Sensors md/unraid: version 2.9.24 patch: add reference to missing firmware in drivers/bluetooth/btrtl.c rtl8723d_fw.bin rtl8761b_fw.bin rtl8761bu_fw.bin rtl8821c_fw.bin rtl8822cs_fw.bin rtl8822cu_fw.bin patch: fix commet lake: https://www.spinics.net/lists/kernel/msg4467076.html Management: Add sha256 checks of un-zipped files in unRAIDServer.plg. webgui: Plugin system and docker update webgui: System info - style update webgui: Plugins: keep header buttons in same position webgui: Prevent overflow in container size for low resolutions8 points
-
No. If you have the latest version, you are good to go.8 points
-
I've been saddened and disheartened today to see what was supposed to be a momentous occasion for us in releasing a substantial improvement to our OS being turned into something else. I have nothing but respect for all of our community developers (@CHBMB included) and the effort they put into supporting extended functionality for Unraid OS. Its sad to see that something we intended to improve the quality of the product for everyone be viewed as disrespectful to the very people we were trying to help. It honestly feels like a slap in the face to hear that some folks believe we were seeking to intentionally slight anyone. It really makes me sad that anyone could think that little of us. And while I'm not interested in engaging in the rest of the back-and-forth on this topic, I do have to address a specific comment where my name was brought into the mix: @CHBMB, unless I'm mistaken, you're referring to the PM thread that we had back in December of 2019, yes? If so, I re-read that exchange today. I never asked you how you created those builds. I never asked you for build instructions or any code. And in that same thread, I expressed our concern regarding the "proliferation of non-stock Unraid kernels, in particular people reporting bugs against non-stock builds." That was the entire purpose of me reaching out to you at the time: to find out what you were talking about in the post about NVIDIA and legal concerns, to make you aware of our concern about having non-official Unraid builds in the wild, and to see what ideas you had to assuage those concerns. I would not describe that as us discussing how you achieved the Nvidia builds. If I'm misremembering and there was another conversation we had over another platform (email, chat, etc.), please remind me, because like everyone here, I'm only human. At the end of the day, I really hope that calmer heads prevail here and we can all get along again. As Tom has already stated, no disrespect was intended. If some folks here feel that we've done something unforgiveable and need to leave our community, I'll be sorry to see that.8 points
-
@aptalca You also know that I had to test things and do also much trail and error but I also got a lot of help from klueska on Github. One side note about that, I tried asking and getting help from you because I don't know nothing about Kernel building and all this stuff but no one ever answered or did anything to help me. I completely understand that @CHBMB is working at healthcare and doesn't have that much time in times like this... @aptalca, @CHBMB & @bass_rock Something about my Unraid-Kernel-Helper container, I know the initial plugin came from you (in terms of the Nvidia driver) but I also wanted to make the build of this some more open and needed a way to integrate DVB drivers with the Nvidia driver to my Unraid system. My work was manly inspired by you guys and I also gave it credit for that but I also want to share it with the community in general if someone want's to integrate anything other than the Nvidia or DVB drivers like now I have support for the Mellanox Firmware Tools or iSCSI... I will also keep updating my Unraid-Kernel-Helper plugin if someone wants a all in one solution and build the bz* images on their own. If you want to blame anyone about this then you have to blame me, when I read about that @limetech is going to integrate the Nvidia drivers into one of the next Unraid beta builds, I wrote a PM to @limetech and offered my help. And that's all what I have to say about that, I think Unraid is one of the best Server OS's out there in my opinion and I simply want to push it forward...8 points
-
The instant we do this, a lot of people using GPU passthrough to VM's may find their VM's don't start or run erratically until they go and mark them for stubbing on Tools/System Devices. There are a lot of changes already in 6.9 vs. 6.8 including multiple pools (and changes to System Devices page) that our strategy is to move the Community to 6.9 first, give people a chance to use new stubbing feature, then produce a 6.10 where all the GPU drivers are included.8 points
-
To expand on my quoted text in the OP, this beta version brings forth more improvements to using a folder for the docker system instead of an image. The notable difference is that now the GUI supports setting a folder directly. The key to using this however is that while you can choose the appropriate share via the GUI's dropdown browser, you must enter in a unique (and non-existant) subfolder for the system to realize you want to create a folder image (and include a trailing slash). If you simply pick an already existing folder, the system will automatically assume that you want to create an image. Hopefully for the next release, this behaviour will be modified and/or made clearer within the docker GUI.8 points
-
There is a Samba security release being published tomorrow. We will update that component and then publish 6.8 stable release.8 points
-
Why are you running something so critical to yourself on pre-release software? Seems a little reckless to me...8 points
-
The issue is that writes originating from a fast source (as opposed to a slow source such as 1Gbit network) completely consume all available internal "stripe buffers" used by md/unraid to implement array writes. When reads come in they get starved for resources to efficiently execute. The method used to limit the number of I/O's directed to a specific md device in the Linux kernel no longer works in newer kernels, hence I've had to implement a different throttling mechanism. Changes to md/unraid driver require exhaustive testing. All functional tests pass however, driver bugs are notorious for only showing up under specific workloads due to different timing. As I write this I'm 95% confident there are no new bugs. Since this will be a stable 'patch' release, I need to finish my testing.8 points
-
Thanks to the help by a guy from the Samba Support mailing list I think I am getting somewhere. I have at least managed to get access to my Unraid shares for all AD users - although all the permissions are now messed up and need re-applying. It looks like the Unraid SMB configuration is just plain wrong for the version of Samba installed. The Unraid SMB configuration uses a way to map AD users to local users that has been unsupported for over 5 years now and there's explicit warnings not to use it. Reconfiguring to use a different method for ID mapping was what got me working. Currently I am working with the Samba Support mailing list to work out what the "best" way is to configure this - as soon as I have that figured out I will post here.7 points
-
I wonder if it's as simple as the "bluez-firmware: version 1.2" upgrade in 6.10.0-rc1 causing the issue as the NMBluezManager is a different version on the two logs you've attached?7 points
-
I'll add it back, don't want to get between anyone and their WINE7 points
-
Yes Tom, that's how I viewed it when we developed the Nvidia stuff originally, it was improving the product. The thread has been running since February 2019, it's a big niche. 99 pages and 2468 posts.7 points
-
You have just described how almost all software functions 🤣7 points
-
I made a video on what the new 6.7.0 looks like etc. There is a mistake in this video where I talk about the webgui: VM manager: remove and rebuild USB controllers. What I thought it was, I found out after it was available in 6.6.6 as well so wasnt it !! Also shows how to upgrade to rc for those who don't know and downgrade again after if needs be. https://www.youtube.com/watch?v=qRD1qVqcyB8&feature=youtu.be7 points
-
This is from my design file, so it differs a little bit from the implemented solution, but it should give you a general feel about how it looks. (Header/menu and bottom statusbar is unchanged aside from icons) Edit: So I should remember to refresh before posting. Anyway you might not have seen it yet, but the logo on the "server description" tile can be edited, and we have included a selection of popular cases to start you off!
 7 points
7 points -
I have created a nchan monitoring script which will terminate the running nchan processes when no more subscribers are present. With this solution there is no need to add the ":stop" option as explained earlier. Running nchan processes will stop automatically when the user closes the browser(s) to the GUI. I'll make this solution available in the next version, there is no need to do anything by the user.6 points
-
Yes we are looking into this.6 points







































