Nuke
Members
-
Joined
-
Last visited
Everything posted by Nuke
-
-
Using 6.12.10 and see no problems in log even i use 1gbps fully sometimes. I don't need this plugin, right?
-
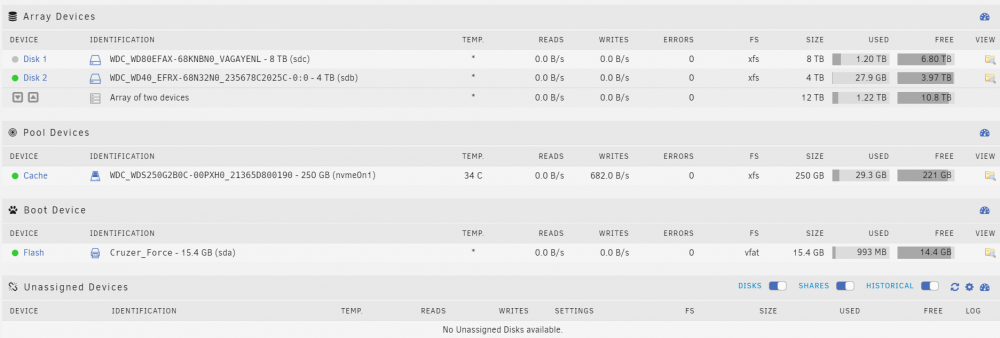
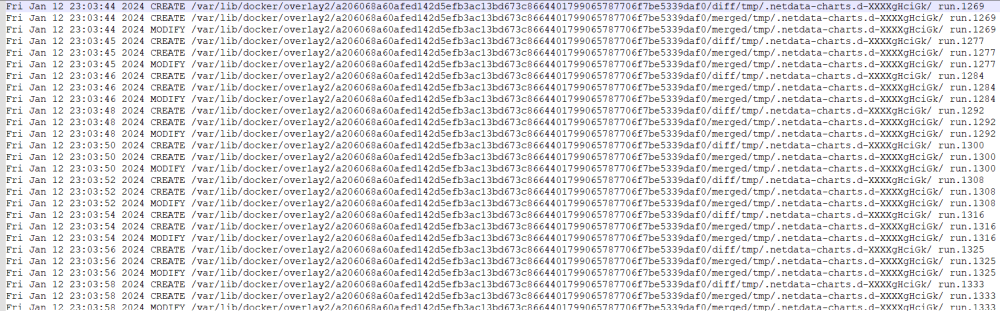
This docker creates massive writes to cache drive. How to solve it?
-
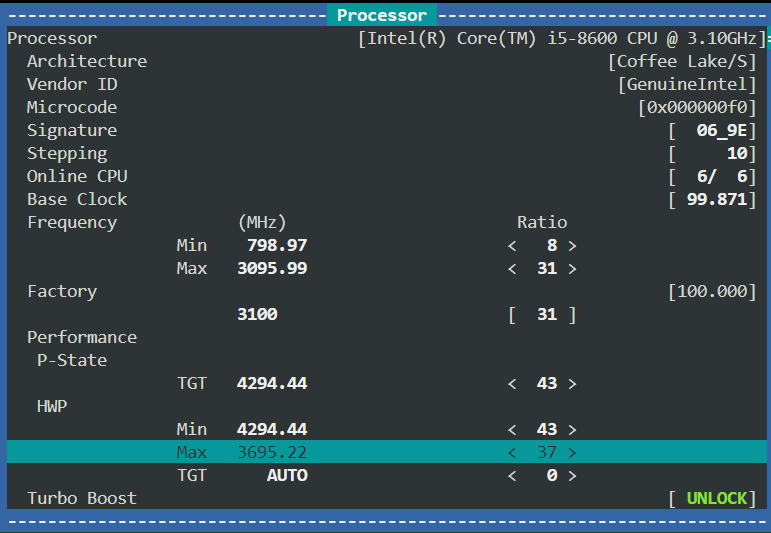
I found that CPU still jumping to 43 even if 37 was truly settled automatically after reboot (i see it in F4 - p). I change it manually to 43 and again to 37 and now it works as expected - not exceed 37 and shows lower temperature and MHz during stress.
-
Any tips how to read memory timings etc with modern Unraid versions? Unraid-Kernel-Helper is deprecated.
-
-
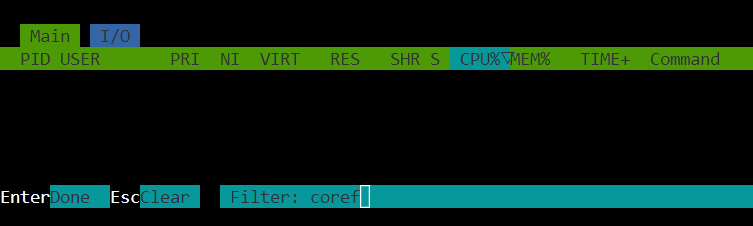
No processes coref*
-
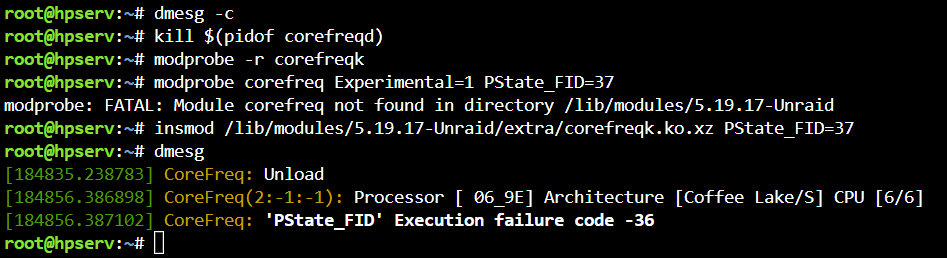
Nope. I can't find properly directory. I see only *.ko.xz file

-
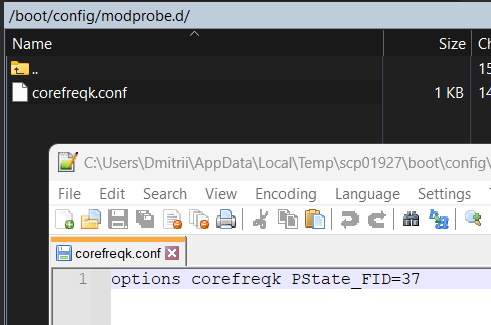
Not applied. All ratio still 43 after reboot. Am I do wrong?
-
Yep. I guess "Ratio_HWP" is what i'm looking for but what "array of int" i should type for change "Max" to 37 ?

-
I need a little slow-down my CPU for hold temperature under 70C instead of >85C, so i change max ratio from 43 to 37. How can i make it persistent? I see the new module options section but I don't see the required line.
-
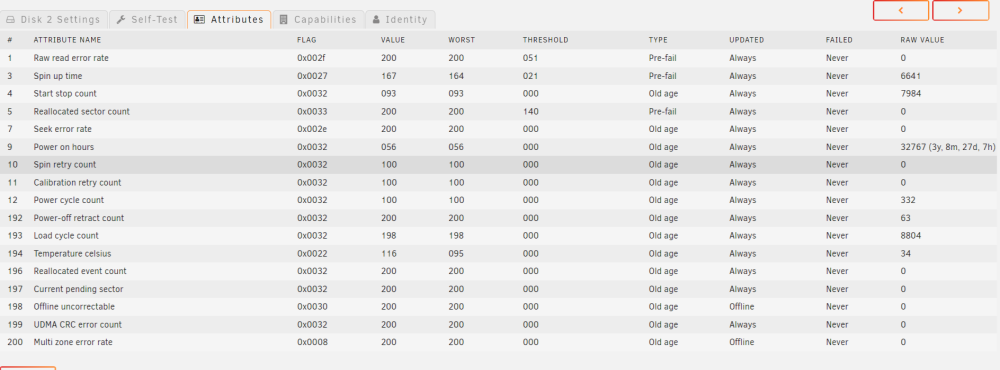
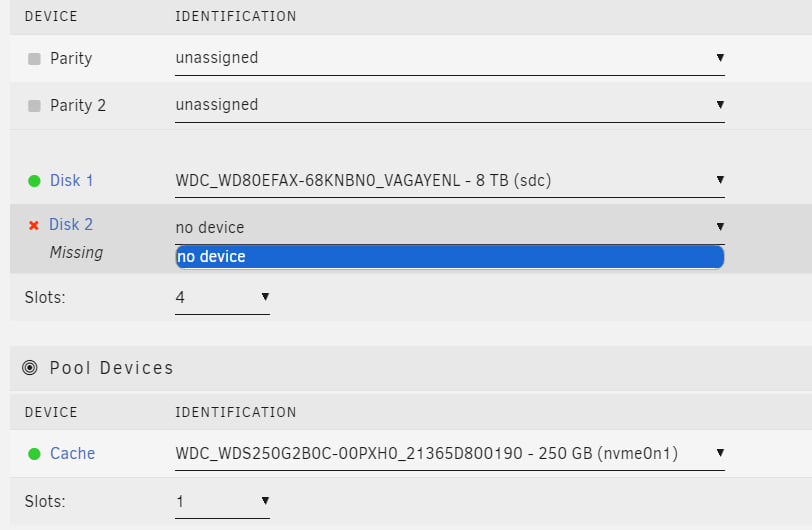
👋🏼👋🏼👋🏼 Unraid says one of my hdd get 2 errors. After reboot array not online, drive is missing (i don't use parity). Fully powered off pc remotely via smart outlet, 5 min waiting and powered on again. No problems now. What type of problem i have? power/sata cable? Drives is sleeping 99.9% of time, spinned up every night for syncing etc. hpserv-diagnostics-20230812-1017.zip smartctl -x /dev/sdb (https://justpaste.it/6dh2t) shows hundreds repeating error: Error 1684 [3] occurred at disk power-on lifetime: 32767 hours (1365 days + 7 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 04 -- 61 00 02 00 00 00 00 00 00 a0 00 Device Fault; Error: ABRT Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- ef 00 10 00 02 00 00 00 00 00 00 a0 08 1d+21:05:04.675 SET FEATURES [Enable SATA feature] ec 00 00 00 00 00 00 00 00 00 00 a0 08 1d+21:05:04.675 IDENTIFY DEVICE ea 00 00 00 00 00 00 00 00 00 00 e0 08 1d+21:05:04.657 FLUSH CACHE EXT ef 00 10 00 02 00 00 00 00 00 00 a0 08 1d+21:05:04.656 SET FEATURES [Enable SATA feature] ec 00 00 00 00 00 00 00 00 00 00 a0 08 1d+21:05:04.655 IDENTIFY DEVICE
-
Anyone use it or more new ghcr.io/motioneye-project/motioneye:edge ? One of two disks still spinning up with 50% chance when i open motioneye web interface. Don't understand why - i keep all records only in cache drive without sync to hdd.
-
How can I delete it? Stuck

-
Am i change things correct?

-
Tonight my machine rebooted by itself, after that "Machine Check Events" was detected. Could you help me to find reason? Unfortunately remote syslog was not started but i have mcelog file. Machine stopped responding at 4:12 started again at 4:16, mcelog shows some errors at 04:13:28. Is that CPU or RAM? hpserv-diagnostics-20220818-0918.zip mcelog
-
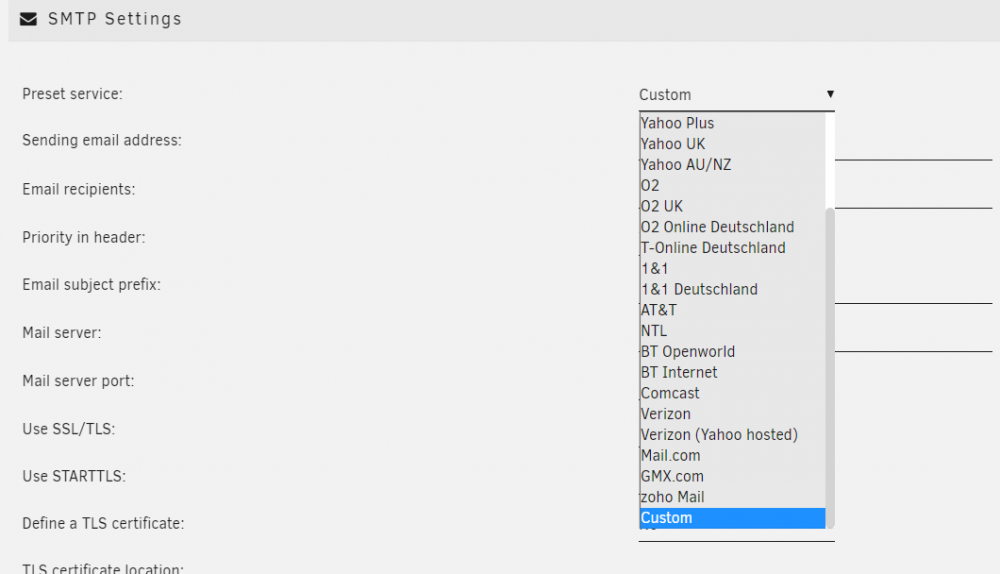
I only need telegram notifications. How can I completely disable email authorization and notifications? There is no "disable" option. If i choose custom then all fields must be filled. If i leave it at "google" then it spam in logs about unsuccessful authorization. Even if all "email" box is unchecked.

-
Dynamix Schedules latest version 2020.06.21, right? I'am faced with same problem:
-
I use https://hub.docker.com/r/djaydev/motioneye/ (deleted) docker. All paths mounted to NVMe disk. When I open motioneye website to watch my camera - both HDDs start spining, in syslog i see read SMART. This is bad. 99.9% of the time my hdd's should sleep. That happens not each time. But each ~12 hours or more.
-
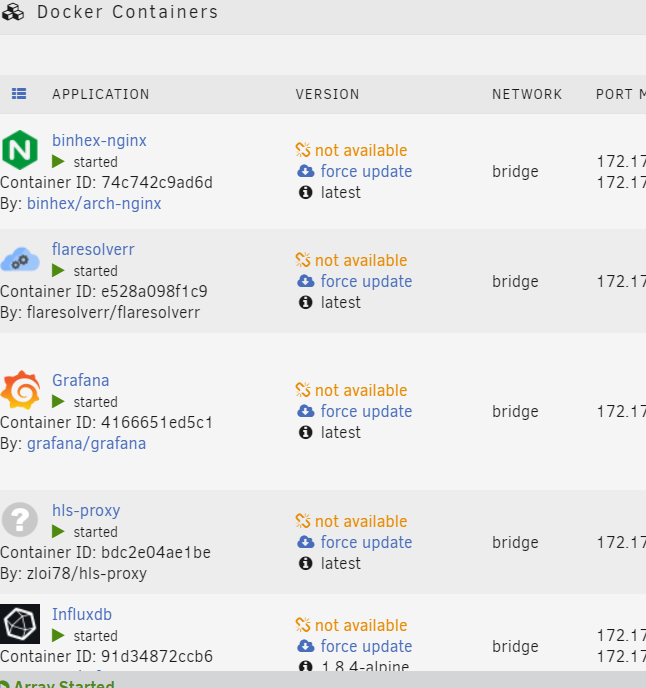
After downgrade CA to 2021.08.31 (to work with Unraid 6.8.3) all containers loose ability to autoupdate - link "not available". How to fix that? Force update works well.
-
i have a strange bug. i have test script, here it is: #!/bin/bash echo hello if i set cron to * * * * * then each minute all other scripts is force rebooting Is last versions is broken?
-
Also i can say problem started to be since i swap cache drive from cheap chinese s**t ssd to new wd blue nvme m2.
-
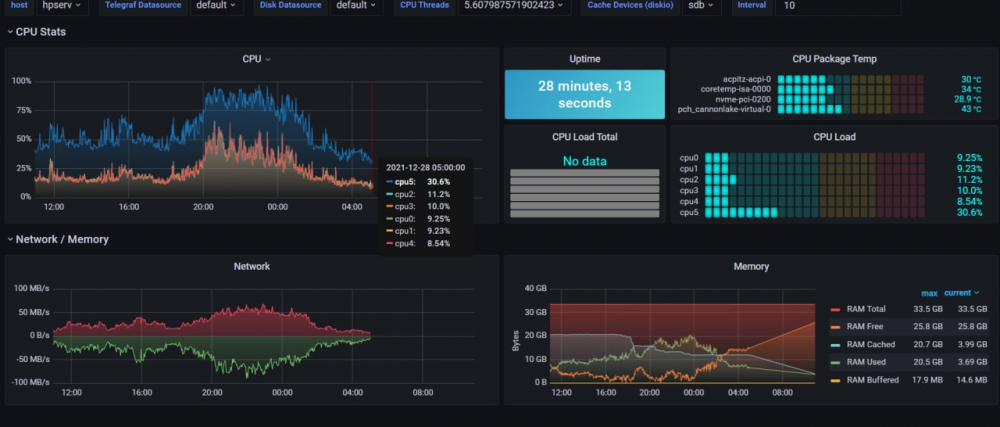
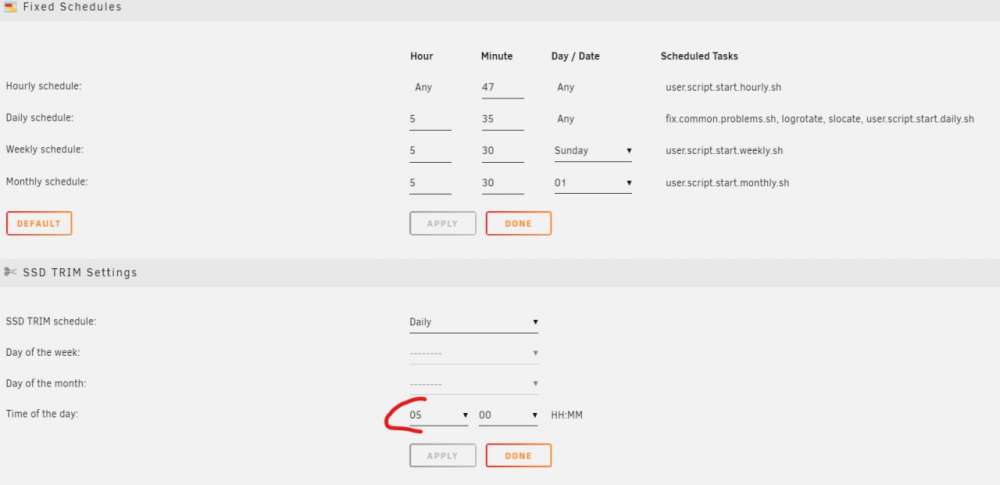
Ok i found that server stoped working at 5:00 - look at my grafana stat I found only one schedule for this time: SSD Trim. Will try to disable this for one month.
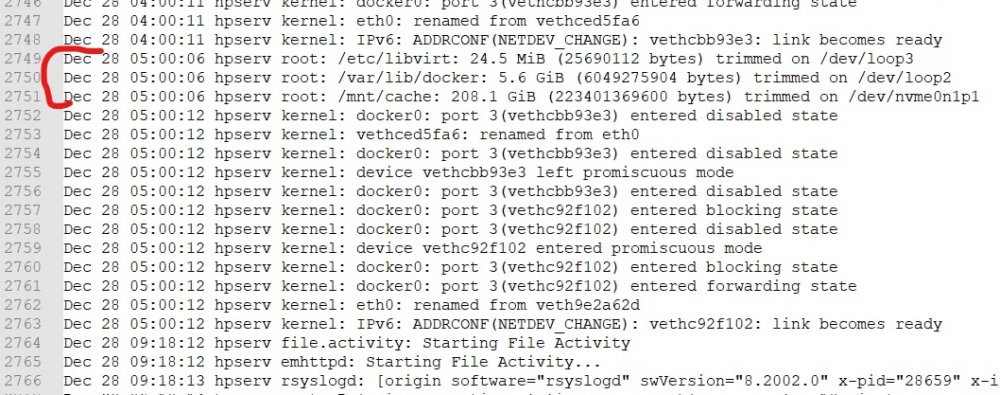
-
My server started to hangs, one time for 1-2 weeks, power button not shutting it down as when normal operation, wake-on-lan also does not help. So i should hold button for 4 sec. Last time it was few hours ago, between Dec 28 ~5:00 - 6:00 I am not live with this server near me so each time it is headache to do hard reboot for it. Tools-Diag after done after reboot. Tools - Syslog Server hold last days information but i don't see any problem, it just stoped and then resumed after i reboot machine. syslog-192.168.0.9.log anon_hpserv-diagnostics-20211228-0929.zip
-
I have 2 different drives - 8tb and 4tb. I have no parity drive and have no plan to buy it. All i need is have a backup from 8tb to 4tb. What is best method to use Unraid for that? Rsync?