

GGANNAS
-
Posts
46 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by GGANNAS
-
-
On 8/15/2023 at 5:11 PM, JorgeB said:
Parity dropped offline and reconnected multiple times, this is usually a power/connection problem, for the MX500 this may help.
So I find a spare psu to test this, to my surprise, Both SSD and HDD is working as it should after conntect to spare psu, Look like I need to change out the psu.
Edit: what is more surprising about this is that even on the same PSU, once I used Molex to the sata power connector, everything was fixed, no more reconnected problem, so I started to check which sata connecter was broken, was last one in both sata power cable, d*** you this broken sata power connecter, waste me a few harddisks to second hand sold out.
-
gxlnas-diagnostics-20230815-0500.zip
Some disk like 1100, Toshiba NAS 4TB, is so unstable, One AMD sata can't, another HBA sas2308 also can't, The Toshiba one even RMA two times, But Still the same.
But the MX500 if in usb case is stable in ubuntu, but the BORG just fill up to no space left, so 🤷♀️
I start to think is my psu problem, and what I have for testing is 10 years old psu.
Why edit: I mess up the ssd model, Is 1100, not MX500, Sorry.
-
9 hours ago, GGANNAS said:
Hi, I use Borg, And I need 1.2.x for borg compact.
But the borg on Nerdpack is 1.1.x, do not have compact command.
So can I do what to get Borg 1.2.x?
So I try to do borg update, Successful make borg-1.2.1.txz by https://github.com/dmacias72/unRAID-NerdPack/issues/66#issuecomment-1167378639, but the size is strange, from nerdpack is 4.2MB, from me is less for 1MB, Have anyone have this problem before?
-
Hi, I use Borg, And I need 1.2.x for borg compact.
But the borg on Nerdpack is 1.1.x, do not have compact command.
So can I do what to get Borg 1.2.x?
-
4 minutes ago, trurl said:
Run an extended SMART test on the parity disk and if it passes it should be OK and you can rebuild parity onto it.
Probably connection problem caused disk1 to get disabled. Rebuilding parity will also be a good way to check that everything is working well now.
Thanks!
-
12 minutes ago, trurl said:
OK, I see what's going on.
You have a single data disk and parity. Disk1 is disabled, so filesystem check is using the emulated disk1. That means it is parity that is really causing this result. And parity has a few reallocated despite being fairly new.
And you say the disk mounts in another OS so that also indicates disk1 is OK, and parity is the problem.
Try New Config with only disk1 assigned and see if it mounts. If it does, then you can reassign and rebuild parity.
Wow,is working!
So test again the 4TB one, make sure is safe to use, or rma the 4TB.
But how to avoid the same problem happed again?
-
4 minutes ago, trurl said:
Try check filesystem from the webUI again and post a screenshot.
Like This?

-
12 minutes ago, trurl said:
Start the array and post new diagnostics.
-
6 hours ago, trurl said:
Are you doing this from the webUI or the command line? If from the command line, what is the exact command used?
You should capture the exact output so you can post it.
I try both,the webui is xfs_repair -n first, after wait a bit, webui show "Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 67108872 bytes) in /usr/local/emhttp/plugins/dynamix/include/DefaultPageLayout.php(518) : eval()'d code on line 735", so try the command line,xfs_repair -n /dev/md1, say "xfs_repair: rmap.c:696: mark_inode_rl: Assertion `!(!!((rmap->rm_owner) & (1ULL << 63)))' failed.
Aborted"And that is a lot log, cover the bofore log and i need delete the personal information, so i not sure what to do.
Before make this post, I also try xfs_repair -L in webui and command line.but not work.and after this xfs_repair, i cross check with ubuntu,and everthing is fine,no lost+found.
-
So server back to I5-6500 set.buy some spare part to rebuild and start trying.
Add the diagnostics.
Try again xfs_repair,show Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 67108872 bytes) in /usr/local/emhttp/plugins/dynamix/include/DefaultPageLayout.php(518) : eval()'d code on line 735
Only backup most inportant,because only have 2TB disk.
-
On 1/28/2021 at 3:35 AM, liangsi said:
1.在6.9rc2版本wdss会导致cpu单核飙升至100%,只能kill掉。
2.退到rc1,之前新建用户然后共享文件夹用的很好,但是最近几天共享文件夹中有一部分无法正常删除了,显示没有权限,我所以共享文件夹设置均是一样,随之docker的管理权限也不管用了,有时同一个共享文件夹删除时竟然显示没有nobody权限或者没有我新建的用户权限。十分困扰我。
3.不知是不是试用测试版的关系,每次登录并不用输入密码,共享文件夹也不需要输入凭证即可在window访问查看,无论是公开还是安全模式。
4.硬盘设置了自动休眠没有反应,一直活动状态。
5.对amd显卡的支持~
顺带一提.插件无法显示以及docker慢的问题倒是均可以自行搜索搞定,包括新的ca即使改hosts也无法访问也是可以解决。
如果有大佬可以解释一下问题2将特别感激~毕竟unraid是一款不错的系统,不想止步于此~
我这里是使用AMD的RX560,日常使用(显卡直通)还是蛮不错。但是如果没有正常的关闭和重新启动的话,它会给我来一个整台机器必须重新启动的状况。而且據我所知,這好像不是UNRAID的事情,這好像是AMD家的事情。
-
9 hours ago, Vr2Io said:
從你的 syslog 與 stats 可看到, 當寫入時, 速度很慢, 兼且 CPU 佔用奇高. Preclear 讀取測試時去到 170MB/s (橙色部份), CPU 佔用都只是 25% 左右, 是正常, 但寫入時 (黃色部份) 就不正常了.
Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --cycles 1 --no-prompt /dev/sdh Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: Preclear Disk Version: 1.0.20 Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: S.M.A.R.T. info type: default Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: S.M.A.R.T. attrs type: default Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: Disk size: 2000398934016 Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: Disk blocks: 488378646 Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: Blocks (512 bytes): 3907029168 Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: Block size: 4096 Jan 8 17:40:57 GANNAS preclear_disk_W520DG20[4095]: Start sector: 790 Jan 8 17:41:01 GANNAS preclear_disk_W520DG20[4095]: Pre-read: pre-read verification started (1/5).... Jan 8 17:41:01 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: dd if=/dev/sdh of=/dev/null bs=2097152 skip=0 count=2000398934016 conv=noerror iflag=nocache,count_bytes,skip_bytes Jan 8 18:00:18 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 10% read @ 172 MB/s Jan 8 18:19:56 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 20% read @ 165 MB/s Jan 8 18:40:28 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 30% read @ 158 MB/s Jan 8 19:02:52 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 40% read @ 153 MB/s Jan 8 19:25:10 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 50% read @ 143 MB/s Jan 8 19:53:32 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 60% read @ 135 MB/s Jan 8 20:19:04 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 70% read @ 125 MB/s Jan 8 20:47:32 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 80% read @ 114 MB/s Jan 8 21:19:27 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: progress - 90% read @ 98 MB/s Jan 8 21:57:28 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: dd - read 2000398934016 of 2000398934016 (0). Jan 8 21:57:28 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: elapsed time - 4:16:24 Jan 8 21:57:28 GANNAS preclear_disk_W520DG20[4095]: Pre-Read: dd exit code - 0 Jan 8 21:57:28 GANNAS preclear_disk_W520DG20[4095]: Pre-read: pre-read verification completed! Jan 8 21:57:29 GANNAS preclear_disk_W520DG20[4095]: Zeroing: zeroing the disk started (1/5).... Jan 8 21:57:29 GANNAS preclear_disk_W520DG20[4095]: Zeroing: emptying the MBR. Jan 8 21:57:29 GANNAS preclear_disk_W520DG20[4095]: Zeroing: dd if=/dev/zero of=/dev/sdh bs=2097152 seek=2097152 count=2000396836864 conv=notrunc iflag=count_bytes,nocache,fullblock oflag=seek_bytes Jan 8 21:57:29 GANNAS preclear_disk_W520DG20[4095]: Zeroing: dd pid [327] Jan 8 23:32:47 GANNAS preclear_disk_W520DG20[4095]: Zeroing: progress - 10% zeroed @ 31 MB/s我做了点測試, 用以下方法, 写入再讀回 (沒用記憶體 cache), 再重覆多次, 目的盤是軟 raid0, 所以性能可去到 500MB/s+, 你可看到CPU 佔用都不會很高, 可能是軟 raid0, 讀取時 CPU 佔用還高於寫入.
dd if=/dev/zero of=/mnt/disks/9AB/test bs=10M count=1000 oflag=direct sleep 15 dd of=/dev/null if=/mnt/disks/9AB/test bs=10M count=1000 iflag=direct sleep 15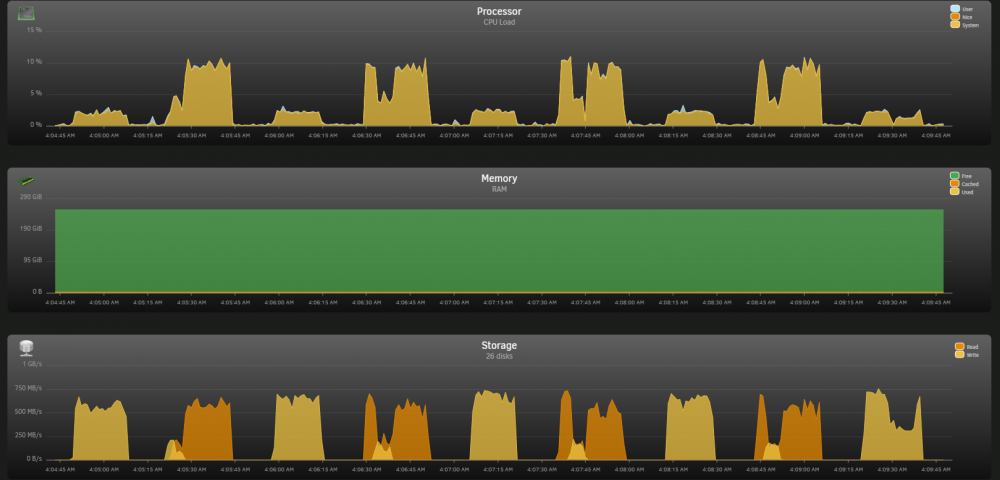
同樣的測試在 array disk, 單碟讀寫只有 170MB/s 左右, CPU 佔用都沒有明顯增加 (大量 xor 運算) , 讀寫時與 idle 時相差不多.
dd if=/dev/zero of=/mnt/disk1/test bs=10M count=1000 oflag=direct sleep 15 dd of=/dev/null if=/mnt/disk1/test bs=10M count=1000 iflag=direct sleep 15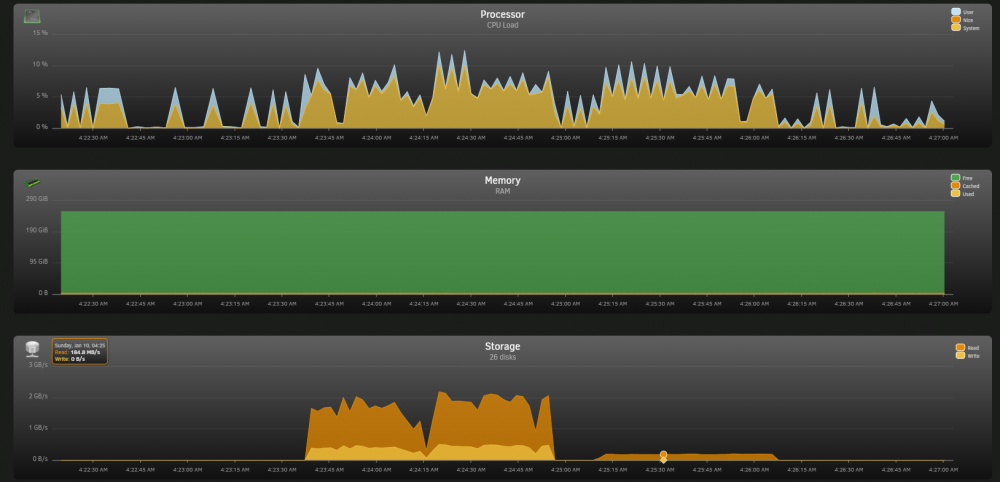
所以你試試啟動安全模式, 即是停止所有 plugin / docker 情況下, 再試試吧.
OK,我进入安全模式,停止所有 plugin / docker / vm,从我的电脑到NAS,速度有一点回到100MB/S,但是不稳定
顺便一提刚才做完的preclear的那个二手硬碟没有报出任何的警告
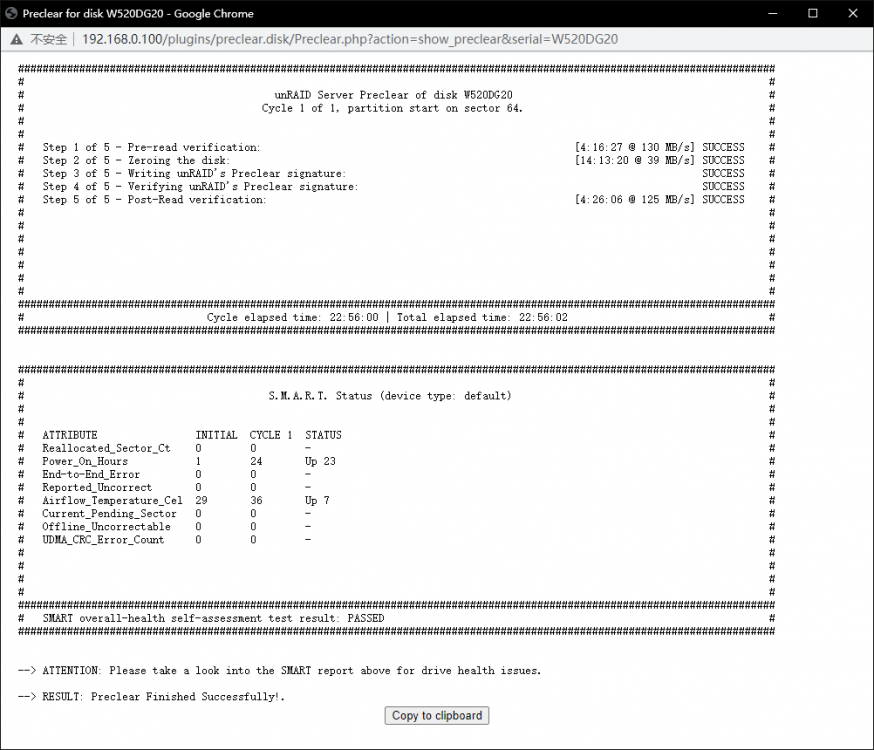
-
5 hours ago, Vr2Io said:
為什麼說不是 CPU 問題呢, 因為我以前用 ATOM J1800 這麼低效 CPU 帶 13隻硬盤都沒有問題, 速度 100MB/s+ (單 parity disk), 最差的 775 socket CPU 都不會比它差吧. 另一方面, dd 亦只是直接輸入輸出, 不需運算 xor.
"买来的二手硬盘" 亦可能有問題, 你能在 SSD 上再做点測試, 將 of=/dev/sdX 轉成 of=file 便可.
另外 Unraid CPU usage 是包含 iowait time, 所以 iowait 高, 佔用亦會高, 但我不太肯定 "state" 是否一樣, 你可用 USB 手指試試是否轉輸很低 ,但 CPU usage 是否一樣地高.
不要見 CPU usage 高就斷定是 CPU 問題.
在 CPU 接近滿載時,用 watch grep \"cpu MHz\" /proc/cpuinfo 看看 CPU 運作在甚麼 freq 吧
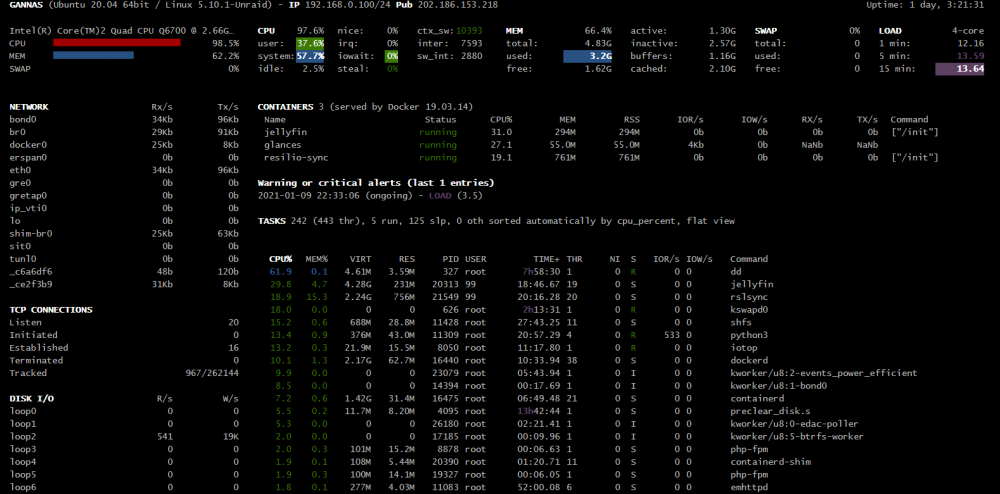
of=/dev/sdX 轉成 of=file?在终端机打入这两行没有什么反应的样子。
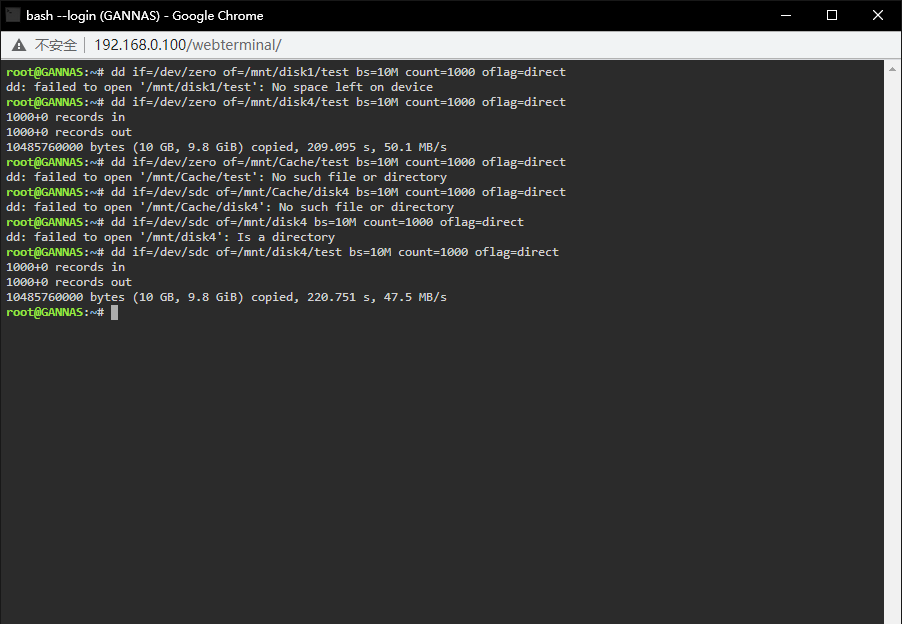
我开了Glances,只有看到Warning or critical alerts (last 1 entries) 2021-01-09 22:33:06 (ongoing) - LOAD (3.5)

-
15 minutes ago, sdwjh said:
就是不知道怎么解决,显示 XFS(md1)有数据损坏,开始以为是磁盘1 有问题,我试了把第一个盘的数据转移到另一个硬盘上并更换了第一个磁盘,问题依然存在
首先,可以请你用quote吗?这样子我也比较能拿到通知来回复你,之后,我觉得你可以使用检查xfs系统。进去的方式是你看到一个绿色的一个点或者是一个三角形的,右边有个蓝色字眼,你按那个你要检查的那个磁碟,按Check Filesystem Status,但是在用这个功能之前,你必须确保已经进入维护模式
然后,如果是磁碟有问题,最糟糕的情况下,unraid它会显示一个打叉,最基本上它会发出一个通知跟你说哪里一个磁碟的S.M.A.R.T有问题,请记得如果磁盘有问题,这个(S.M.A.R.T)一定会警报,除非你把它(警报)关掉了
-
我也想知道,可是我的感觉是好像它(GUI)至少要一个显卡进行画面输出
-
我之前也遇到这个问题,你能不能检查是不是用xfs,xfs没法使用多过一个硬盘。如果是的话,请把插槽(slots)设回1。
如果不是,真的要花时间去找了
-
先说明下,我不是大神,我还有另外有另一个问题想办法处理中,但是我看到有几个metadata corruption detected at xfs_inode_verify,会不会是这个导致的问题?
-
4 hours ago, uniartisan said:
校验会做大量的与、或运算,看您的配置校验应该是CPU带不动了。
我也是这么认为,就算我把CPU从Xeon 3040换成Intel Core 2 Quad Q6700,性能上我觉得好像只是核心上的差别而已,因为是品牌机的原因,再升级上去的话,就是整机都要换掉的那种。
-
2 hours ago, Vr2Io said:
不會是 CPU 問題, 執行 parity check 或 文件轉送,就不要有其它 disk 存取. 可用 iotop 看看.
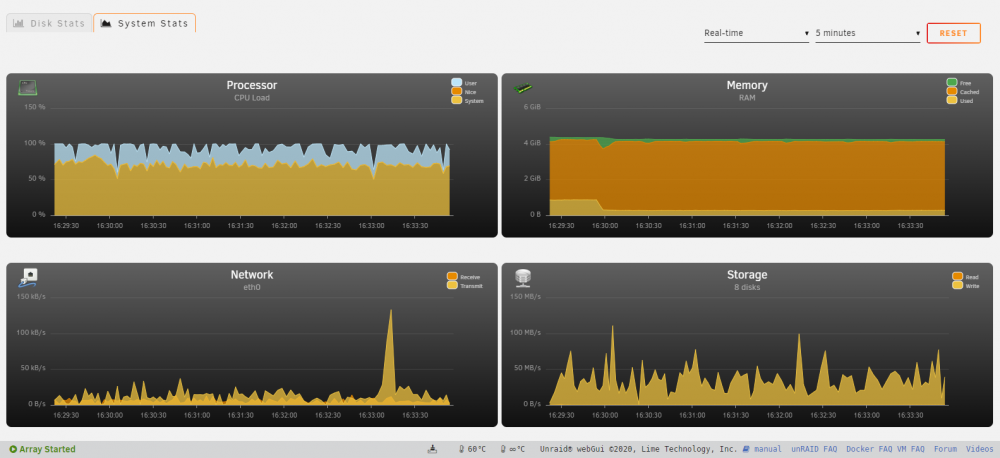
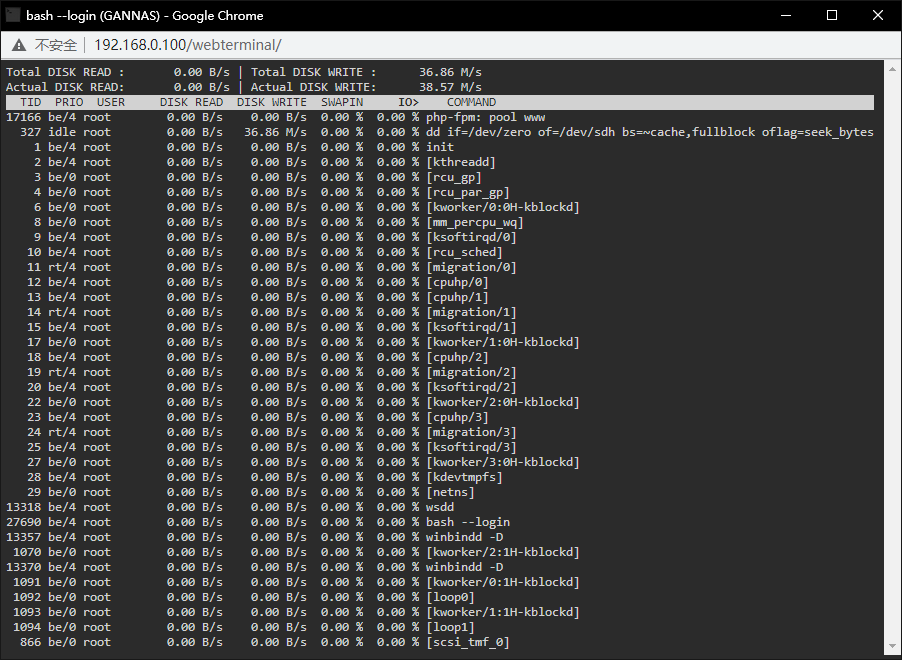
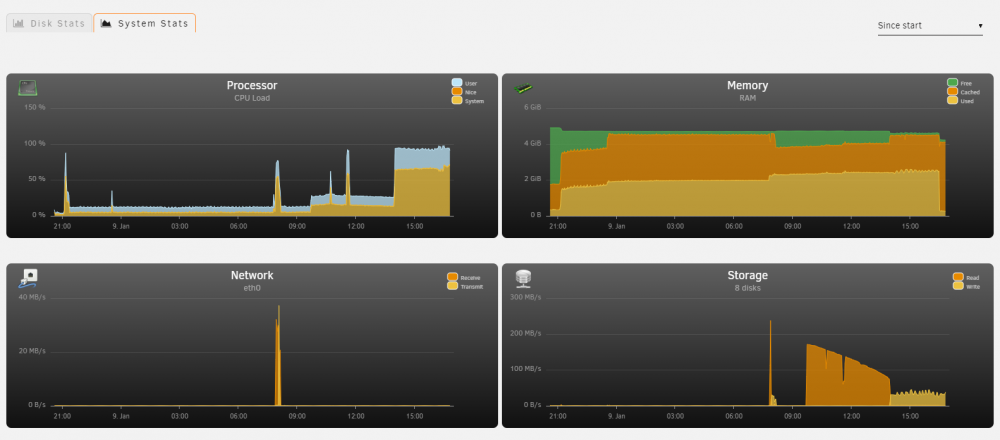
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 12899 nobody 20 0 1757444 662720 7200 S 106.9 13.1 87:26.65 rslsync 12860 root 20 0 0 0 0 R 96.6 0.0 124:36.87 unraidd0 4885 root 20 0 6084 2736 2192 R 37.9 0.1 0:00.14 top 13752 root 20 0 2262712 79888 39040 S 31.0 1.6 78:38.38 dockerd 9821 root 20 0 1425044 518160 22888 S 27.6 10.2 140:40.28 qemu-syst+ 16397 nobody 20 0 4512256 220524 17256 S 27.6 4.4 98:13.15 jellyfin 10773 root 20 0 0 0 0 R 24.1 0.0 18:28.58 mdrecover+非常抱歉,但是我有一个感觉, CPU就是问题,因为一旦CPU的使用率下降的时候,写入速度会提升。可是CPU使用率上升,它的写入速度就下降。现在的话,是在用这一个preclear在做买来的二手硬盘的测试,就算我把两个东西(VM,Docker)都关掉,它的写入速度并没有很好的提升
gannas-diagnostics-20210109-1637.zip
-
Today, I receive the Fix Common Problems say "Out Of Memory errors detected on your server","Your server has run out of memory, and processes (potentially required) are being killed off. You should post your diagnostics and ask for assistance on the unRaid forums"
The diagnostics file is attach
Can help fix the problum?
-
15 hours ago, lyqalex said:
需要用hba卡连接sas硬盘,就插上测试。不插是因为hba也有坏的可能,最简配置只是利于发现故障点,如刚开始2个组件可以运行,然后发现正常的,就2+1个组件测试,2+2、2+3、2+4等等接着测试。。。。。。也可以刚开始把怀疑的件排除,直接测试是否正常,不正常再进行前面简单配置测试。
把主力电脑当做测试机来测试之后,发现 有可能我作为NAS的那一台775电脑实在是太老了,它跑不动了, 主力电脑是I5-6500,16GB DDR4,NAS是Q6700,5GB DDR2, 主力奇偶检查可以达到100MB/S~150MB/S,NAS?12.5 MB/S这样吧?已经确认都是全千兆环境下做测试。
-
Just now, lyqalex said:
速度过慢。建议进行最小配置进行排除软硬故障,先确认主板bios设置,不要插hba卡等等,换不同硬盘、线材、逐步增加硬盘数量和sata、sas端口,运行奇偶校验测试检查。
Ok, 理解,可是我有两个SAS硬盘,除了插入hba卡,还有什么办法去做测试吗?
-
2 hours ago, lyqalex said:
主界面-阵列操作-检查。PS:去掉了阵列里的坏的磁盘,要进行工具-新配置重新配置磁盘阵列,否则会一直提示错误。
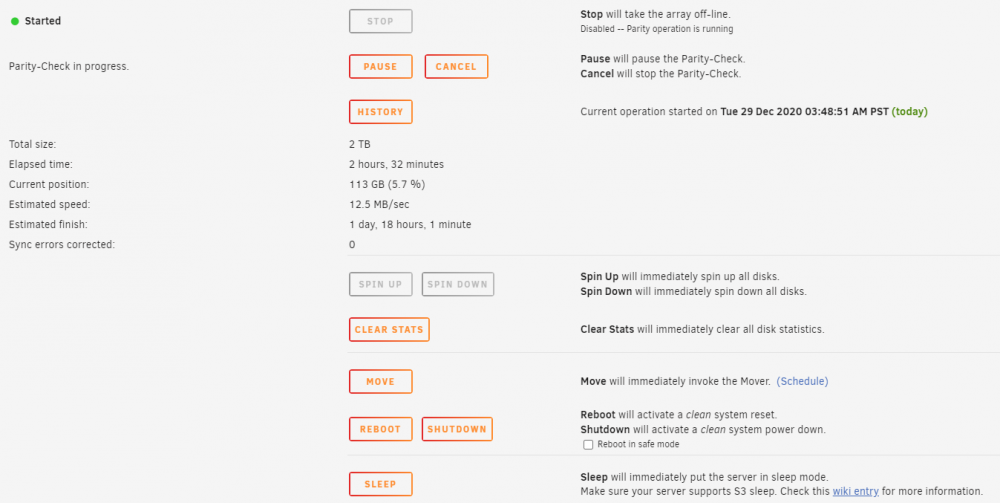
请问你认为这个速度正常吗?
-
4 minutes ago, lyqalex said:
主界面-阵列操作-检查。PS:去掉了阵列里的坏的磁盘,要进行工具-新配置重新配置磁盘阵列,否则会一直提示错误。
已经在做了, 做完了之后我会告诉你还有什么问题,谢谢












I start to Think is the PSU Problem
in General Support
Posted · Edited by GGANNAS
https://forums.unraid.net/topic/143617-i-probably-burnout-for-some-disks-help-me-for-why-some-disk-after-rma-still-the-same/
https://forums.unraid.net/topic/144460-after-fixed-a-problem-it-come-back-again (By the way, how to unhide this one?)
So I bought a new disk, a Seagate IronWolf, But When I used it, the same thing happened again, The Same Controller, amd one and the sas2308 were not the problem, and the Same power and data were not the problem, Same When I used a spare Psu were the fix.
And When I just connect one disk it is fine, but when I connect another disk, the same problem happens again.
So Should I change the 550w psu from 2016ish?