

guythnick
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by guythnick
-
-
No, it appears that the directory structure was maintained.
-
Want to put a pin on this - after the second rebuild finished the drive was still unmountable. I did some searching online and it looks like running xfs_repair was the right way to try to fix it. I started the array in maintenance mode and tried to just run 'xfs_repair -n', but it showed an error stating basically I needed to rebuild the log with the -L switch. I then re-ran with 'xfs_repair -L' , which completed in a couple minutes. Then after starting the array, I now have all the missing data!
Thanks for the replies.
-
I stopped the rebuild and checked what was emulated, and it didn't emulate anything. Going to chalk this up to something incorrect I did last night. It doesn't make sense, but I don't see a way to get back the data.
-
I have replaced a drive in my array yesterday and parity was rebuilding the contents. Before the rebuild, the files were emulated and accessible. But today, about 10 hours into the rebuild, it appears all files were deleted from the array. I don't really understand what is happening.. All the modified times for the folders with missing data is around 2:15pm 12/30. So, it appears something in the rebuild process deleted the files? Not sure what to do. It is still rebuilding and at 80% complete.
-
41 minutes ago, Squid said:
Because 8091 is what port the container actually uses internally, and the template is set up to go to internal port 8091 when hitting the GUI. In Bridge you can map the port to be anything else.
EDIT: I changed the Home Assistant container to run on the same bridge (br0). Apparently when set to host mode it cannot access the br0 containers. Now it connects with websockets.
-
Just now, Squid said:
That is correct. Once you apply a custom IP address (br0) to a container, port mappings no longer take effect and are effectively meaningless since the container is running on it's own IP and nothing else would conflict, so the docker engine automatically converts those path mappings to instead be environment variables.
Can I ask then why does the 8091 show mapped in the GUI? Also, why in my other Domoticz container does it show all three that is also on br0? I understand your explanation, but that port is not working to access from other containers. Only when I set the container to bridge mode does the websockets port 3000 become connectable.
-
I am trying to setup my new z-wave devices with zwave-js-ui container. That is working, but I am unable to use websockets due to the port not mapping.
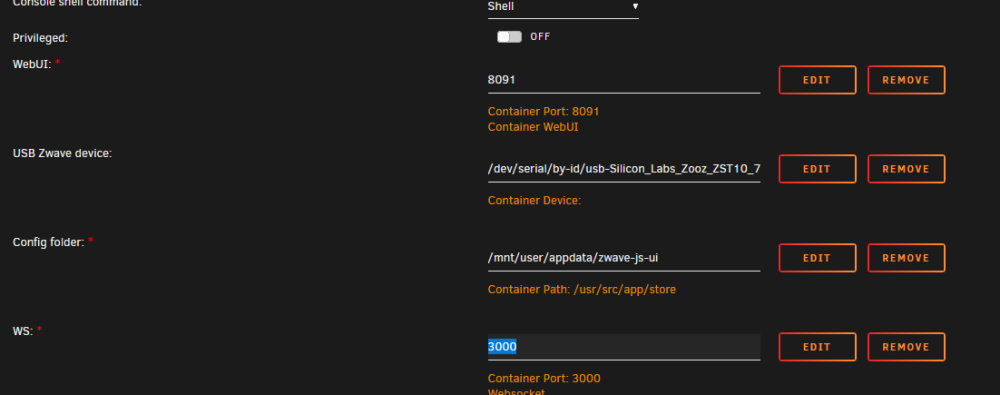
Below is an example of my Domoticz container, in which I have 3 mapped ports that all are showing. And in the zwave entry, only the 8091 shows. I can get it to map 3000if I change this to bridge mode, but I can't do that as I need this to access the MQTT container that is also on br0.

Also when I edit and save the container, you can see the 3000 port is in the docker run command:
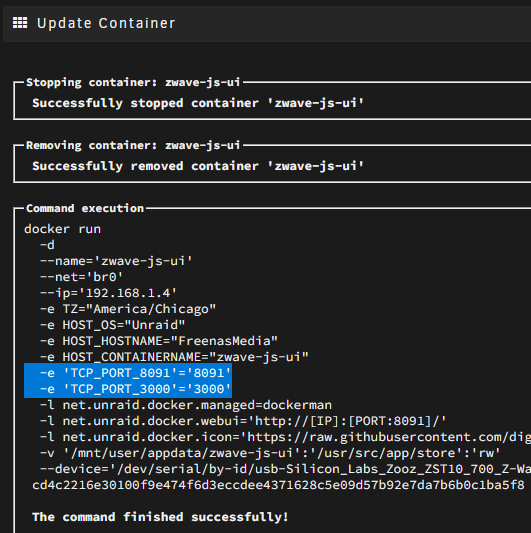
-
8 minutes ago, JorgeB said:
It already comes with stock Unraid v6.11.x
Ah, rad. I should have checked. Thanks!
-
Thanks a ton for this plugin! One request - can you add iperf3 in there? I use that for quick network tests.
-
Parity is rebuilding and all files appear to be available. Here is what I did:
* Stopped the array.* Manually ran the below on the un-mountable disk
xfs_repair -L /dev/sdb1*I had to run this with -L as without it it would not run.
*Generate New Config with the same assignments.
After these steps it started the parity rebuild, and all the shares are still available. So far, all the files seem to be there, but if there is any corruption I will just have to deal with it at this point.
-
That is the problem, disk1 wasn't disabled until I started the array. The system automatically started rebuilding at the same time.
-
Yes, the diagnostic files were taken before the parity sync completed. When I downloaded the diagnostic they were both showing red.
I guess I will try doing a new config, but I am just worried I will lose data from both drives. Maybe I will just try to figure out a way to get the files off of them in Windows first.
-
I have a big issue this morning I am hoping someone can help me with. As you can see below there are two disks that are unmountable in Unraid. This morning disk 4 was in an error state, so I swapped out the cable for this disk and proceeded to remove and re-add the drive so that it rebuilds from parity. However, upon starting the array, Disk 1 was showing as missing. I rebooted my server, and it then shows as disabled. The system went on to sync parity, and Disk 4 now shows green, yet unmountable.
I could accept HW failure and move on, but both of these disks when mounted in my USB enclosure on my Windows machine will show all files using Linux Reader.
I have swapped postitions / cables / from LBA to on-board SATA, nothing has worked. Also want to note that when I start the array in maint mode and try to check the file system for this disk, it will just output this:
Phase 1 - find and verify superblock... superblock read failed, offset 0, size 524288, ag 0, rval -1 fatal error -- Input/output errorIs there anyway I can just force Unraid to mount these disks? I don't understand how the file system is fully readable on another machine but not in Unraid.
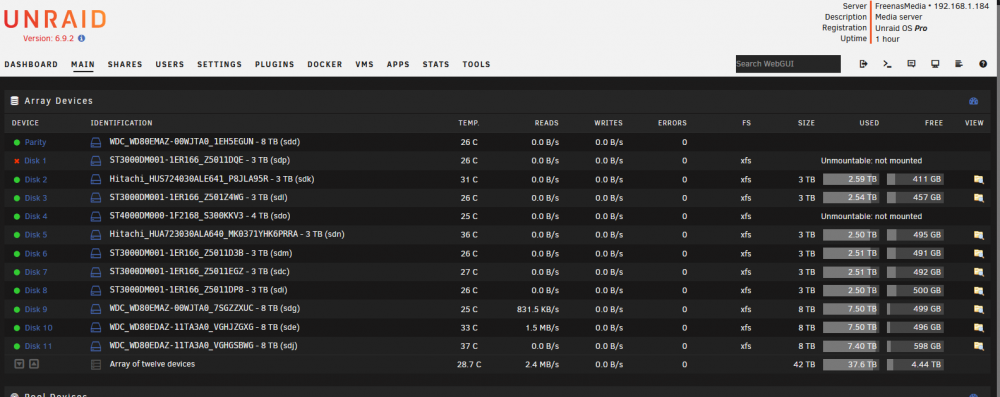
-
I've been getting a lot of slow responses and timeouts lately for searches. The docker log is showing many errors that look like the below. Anyone else having issues recently?
Traceback (most recent call last): File "/usr/local/lib/python3.8/site-packages/cachelib/file.py", line 230, in set fsize = Path(filename).stat().st_size File "/usr/local/lib/python3.8/pathlib.py", line 1198, in stat return self._accessor.stat(self) FileNotFoundError: [Errno 2] No such file or directory: '/config/session/2029240f6d1128be89ddc32729463129' ERROR:app:Exception on /element [GET] Traceback (most recent call last): File "/usr/local/lib/python3.8/site-packages/flask/app.py", line 2446, in wsgi_app response = self.full_dispatch_request() File "/usr/local/lib/python3.8/site-packages/flask/app.py", line 1951, in full_dispatch_request rv = self.handle_user_exception(e) File "/usr/local/lib/python3.8/site-packages/flask/app.py", line 1820, in handle_user_exception reraise(exc_type, exc_value, tb) File "/usr/local/lib/python3.8/site-packages/flask/_compat.py", line 39, in reraise raise value File "/usr/local/lib/python3.8/site-packages/flask/app.py", line 1949, in full_dispatch_request rv = self.dispatch_request() File "/usr/local/lib/python3.8/site-packages/flask/app.py", line 1935, in dispatch_request return self.view_functions[rule.endpoint](**req.view_args) File "/whoogle/app/routes.py", line 88, in decorated os.remove(invalid_session) FileNotFoundError: [Errno 2] No such file or directory: '/config/session/f3e9e8a510a2a4e8480278de12876f59' WARNING:root:Exception raised while handling cache file '/config/session/2029240f6d1128be89ddc32729463129'
-
2 minutes ago, seanwalter said:
I am having the same issue
Just as I posted that, I checked updates and there was one available. New update has resolved the issue.
-
10 hours ago, daldridge said:
The latest update has broken Whoogle for me. In the logs the first error I see is - ERROR: Could not open requirements file: [Errno 2] No such file or directory: 'requirements.txt'
Same for me.
-
Edited my post above. Was able to get it running again by changing the repository to use the alpha image:
dyonr/qbittorrentvpn:alpha
-
 2
2
-
-
EDIT:
Fixed this for now by changing the repo to: dyonr/qbittorrentvpn:alpha
Just updated today, and the GUI isn't coming up.
Docker log shows below. Note that PID is not displayed.
2021-11-01 13:58:10.792792 [INFO] A group with PGID 100 already exists in /etc/group, nothing to do. 2021-11-01 13:58:10.812855 [INFO] An user with PUID 99 already exists in /etc/passwd, nothing to do. 2021-11-01 13:58:10.831970 [INFO] UMASK defined as '002' 2021-11-01 13:58:10.853118 [INFO] Starting qBittorrent daemon... Logging to /config/qBittorrent/data/logs/qbittorrent.log. 2021-11-01 13:58:11.880629 [INFO] Started qBittorrent daemon successfully... 2021-11-01 13:58:11.902356 [INFO] qBittorrent PID: 2021-11-01 13:58:12.179287 [INFO] Network is upThe qbittorrent.log shows this on the end, which might be the issue:
/usr/local/bin/qbittorrent-nox: error while loading shared libraries: libQt5Sql.so.5: cannot open shared object file: No such file or directory /usr/local/bin/qbittorrent-nox: error while loading shared libraries: libQt5Sql.so.5: cannot open shared object file: No such file or directory-
3
-
-
Also updated to 2020.2 today, and found that my custom-cont-init.d scripts wasn't working. Looks like it moved to Ubuntu, so if you have any 'apt add' running, you will need to change to 'apt install'. Wondered why my lifxlan scripts stopped working, and found that the dependencies were failing.
-
6.8.3. But, I ended up switching out some drives in another system, and now rebuilding with a 4TB drive. Had to sacrifice some data that was on the drive though.
-
Edit: I ended up switching out some drives in another system, and now rebuilding with a 4TB drive. Had to sacrifice some data that was on the drive though.
Have an urgent issue with my Unraid server. This morning, had a drive failure on a 3TB drive. I stopped the array and replaced it with a 4 TB drive accidentally (this drive had important data NOT on the array). I then stopped that re-build, and tried to replace it with the correct 3TB replacement. But, now it is saying that it is too small. How can I force Unraid to accept the 3TB drive, which is the only data amount that it would need to restore?
-
EDIT: I increased the Propagation parameter to 60 seconds in the container, and that has fixed the issue.
I just updated this docker and now it is failing to get my cloudflare DNS verification. Anyone know why/how? I see it is inserting the TXT acme-challenge records in the cloudflare dashboard. This has taken down my production sites, so if anyone knows of an issue please let me know.Unsafe permissions on credentials configuration file: /config/dns-conf/cloudflare.ini Waiting 10 seconds for DNS changes to propagate Waiting for verification... Waiting for verification... Challenge failed for domain my.domain Challenge failed for domain my.domain dns-01 challenge for my.domain dns-01 challenge for my.domain Cleaning up challenges Some challenges have failed. IMPORTANT NOTES: - The following errors were reported by the server: Domain: my.domain Type: dns Detail: DNS problem: NXDOMAIN looking up TXT for _acme-challenge.my.domain - check that a DNS record exists for this domain Domain: my.domain Type: dns Detail: DNS problem: NXDOMAIN looking up TXT for _acme-challenge.my.domain - check that a DNS record exists for this domain ERROR: Cert does not exist! Please see the validation error above. Make sure you entered correct credentials into the /config/dns-conf/cloudflare.ini file.
-
Wondering if you can add unrar-free package to the container? I use that in qbit for when torrents are finished. Was able to run apt update && apt -y install unrar-free, but would be persistent if it were in the template. Wireguard working great, Thanks!
-
Quote
please can you do the following:-
https://github.com/binhex/documentation/blob/master/docker/faq/help.md
also could you attach the file /config/privoxy/config
Here are both files when I run the latest image. I also reverted to binhex/arch-qbittorrentvpn:4.2.1-1-05 and it is working normally.





[Support] binhex - Sonarr
in Docker Containers
Posted
Also getting the same error when adding a show or when the application refreshes info. Did you ever find a fix for this?
DEBG 'sonarr' stdout output: [Error] X509CertificateValidationService: Certificate validation for https://skyhook.sonarr.tv/v1/tvdb/shows/en/403294 failed. RemoteCertificateChainErrors [v3.0.4.1126] System.Net.WebException: Error: TrustFailure (Authentication failed, see inner exception.): 'https://skyhook.sonarr.tv/v1/tvdb/shows/en/403294' ---> System.Net.WebException: Error: TrustFailure (Authentication failed, see inner exception.) ---> System.Security.Authentication.AuthenticationException: Authentication failed, see inner exception. ---> Mono.Btls.MonoBtlsException: Ssl error:1000007d:SSL routines:OPENSSL_internal:CERTIFICATE_VERIFY_FAILED at /build/mono/src/mono/external/boringssl/ssl/handshake_client.c:1132 ...