

fysmd
-
Posts
108 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by fysmd
-
fysmd multiple issues (from: Unassigned Devices thread)
fysmd replied to fysmd's topic in General Support
LOL! I thought exactly what you say and that's same as in help. In reality though it seems to fill the cache and then complain / fail Wondering if I need to combine wiht with a different min free value or something. .. or maybe the machin was in a funk at the time and just needed restarting. Yes, I'm a very long time user, the "server" is my (now) very stable box but I'm testing out another one to host some containers and virtual machines. On an eval license and using old disks which wile working, were removed from my live arrar due to the smart warnings. -
fysmd multiple issues (from: Unassigned Devices thread)
fysmd replied to fysmd's topic in General Support
So a reboot fixed Time discrepancies (the web ui and cli: date both reported correct local time but not syslog) and the cache disk is no longer full (prefer cache on share doesnt seem to do what I expected!). and so far the CIFS mount is stable (and so my cache disk no longer full) Syslog full of: Apr 30 15:11:30 VH1 kernel: CIFS VFS: Close unmatched open Apr 30 15:13:00 VH1 kernel: CIFS VFS: Close unmatched open Apr 30 15:17:01 VH1 kernel: CIFS VFS: Close unmatched open Apr 30 15:17:01 VH1 kernel: CIFS VFS: Close unmatched open Apr 30 15:19:01 VH1 kernel: CIFS VFS: Close unmatched open Apr 30 15:20:02 VH1 kernel: CIFS VFS: Close unmatched open Apr 30 15:20:33 VH1 kernel: CIFS VFS: Close unmatched open Are they relevant? -
Sorry in advance if answered in this (LONG) thread but I've searched and can't find same issue: Two unraid servers running 6.8.2 [server] and 6.8.3 [client] both on physical boxes. diag attached for client machine. I run UD on both but I want to mount my media shares using CIFS with UD on the client server. Many work well and are stable but my movies share is not. sometimes it mounts and works for a period but once it fails it shows mounted on the GUI and in CLI but navigating into share un GUI takes a long time but shows it empty. In cli: root@VH1:~# ls /mnt/disks/SERVER_movies /bin/ls: cannot access '/mnt/disks/SERVER_movies': Stale file handle syslog reports sucessful mount despite it not bing and syslog full of: root@VH1:~# ls /mnt/disks/SERVER_movies /bin/ls: cannot access '/mnt/disks/SERVER_movies': Stale file handle I notice that the time shown in syslog must be in a different timezone, machine reports time correctly but logs are -7h ( I know my cache disk full at the mo BTW! and a couple of HHDs are reporting smart errors, I'm in eval at the mo while I try to get this puppie working how I want ) vh1-diagnostics-20200430-1059.zip
-
Unraid v 6.7.0 diag attached and drive ogs below. This drive is not very old, only 6.3 weeks of runtime. Nothing logged (telegraf) into Grafana from that drive seems to indicate it going wrong. Could this be a simple HDD failure and nothing to worry about? May 18 12:15:22 Server kernel: sd 7:0:4:0: [sdi] 7814037168 512-byte logical blocks: (4.00 TB/3.64 TiB) May 18 12:15:22 Server kernel: sd 7:0:4:0: [sdi] 4096-byte physical blocks May 18 12:15:22 Server kernel: sd 7:0:4:0: [sdi] Write Protect is off May 18 12:15:22 Server kernel: sd 7:0:4:0: [sdi] Mode Sense: 9b 00 10 08 May 18 12:15:22 Server kernel: sd 7:0:4:0: [sdi] Write cache: enabled, read cache: enabled, supports DPO and FUA May 18 12:15:22 Server kernel: sdi: sdi1 May 18 12:15:22 Server kernel: sd 7:0:4:0: [sdi] Attached SCSI disk May 18 12:15:47 Server emhttpd: ST4000DM004-2CV104_ZFN1RHKA (sdi) 512 7814037168 May 18 12:15:47 Server kernel: mdcmd (2): import 1 sdi 64 3907018532 0 ST4000DM004-2CV104_ZFN1RHKA May 18 12:15:47 Server kernel: md: import disk1: (sdi) ST4000DM004-2CV104_ZFN1RHKA size: 3907018532 May 18 12:15:50 Server emhttpd: shcmd (27): /usr/local/sbin/set_ncq sdi 1 May 18 12:15:50 Server root: set_ncq: setting sdi queue_depth to 1 May 18 12:15:50 Server emhttpd: shcmd (28): echo 128 > /sys/block/sdi/queue/nr_requests May 21 03:14:25 Server kernel: sd 7:0:4:0: [sdi] Synchronizing SCSI cache May 21 03:14:25 Server kernel: sd 7:0:4:0: [sdi] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=0x00 May 21 03:14:25 Server kernel: sd 7:0:4:0: [sdi] tag#0 CDB: opcode=0x88 88 00 00 00 00 00 6a 24 de 70 00 00 01 40 00 00 May 21 03:14:25 Server kernel: print_req_error: I/O error, dev sdi, sector 1780801136 May 21 03:14:25 Server kernel: sd 7:0:4:0: [sdi] tag#1 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=0x00 May 21 03:14:25 Server kernel: sd 7:0:4:0: [sdi] tag#1 CDB: opcode=0x88 88 00 00 00 00 00 6a 24 df b0 00 00 00 10 00 00 May 21 03:14:25 Server kernel: print_req_error: I/O error, dev sdi, sector 1780801456 May 21 03:14:25 Server kernel: sd 7:0:4:0: [sdi] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=0x00 server-diagnostics-20190527-0933.zip
-
Hi all, Well, a week later, a full rebuild and much frustration later I think I can confirm that the SATA power cable with capacitor was my issue. No issues reported since! Thanks for the help and advise all!
-
So, after more investigation I found the only component common to the misbehaving drives was one of these puppies: https://www.scan.co.uk/products/silverstone-cp06-1-to-4-sata-power-adaptor-cable-with-capacitor Removed and now over three hours into rebuild with no faults so far (everything's crossed).
-
During rebuild two otherwise happy drives now report a >>LOT<< of read errors. I'm replacing the PSU which supplies all so far affcted drives, is there anything lurking in the logs I dont see? server-diagnostics-20190224-0822.zip
.thumb.png.0c515b788ef2096f652c13ec68dddb57.png)
-
the drives are split over two 550W PSUs but will tot up how many / which on each.
-
machine reboot rather than stop and restart array? - damn, in the middle of preclears
-
Just had another drive go, disk2 now, diag attached server-diagnostics-20190223-1439.zip
-
Sorry, that's not what I meant - I now have four drives which i removed from the array, likely cable related. is there any reason to suspect them faulty? One back at full strength I may run preclear a few times on them to test them but is there anything else?
-
thanks, I noticed disk18 and have a replacement now - preclearing. While starting a pre-clear, disk2 just went offline!! It does seem that all these drives were on the same cable. Bi of rearrangement and that cable's out of play now. REALLY glad I added two parity now! Other than drive18 with errors, would I be right thinking that they're likely OK?
-
So I've just had my third drive in a fortnight go bad. Last week I took the precaution of adding a 2nd parity but had another go unmountable since then. Now the drives failing have been old but I'm wondering if there is something going on here which I'm not noticing. Posted diag from today and one from a v poory state last week. Any advise / comments much appreciated.. [off to buy another couple of drives!] server-diagnostics-20190223-0956.zip server-diagnostics-20190216-1045.zip
-
avag0 9305-24i not detecting all drives
fysmd replied to fysmd's topic in Storage Devices and Controllers
O-M-G!! I feel like a muppet. Off to get proper cables now. Thanks again! -
avag0 9305-24i not detecting all drives
fysmd replied to fysmd's topic in Storage Devices and Controllers
I want to say a big thank you, especially to johnnie.black for all the help with my recent issues (not only in this thread!) I worked out the source of my troubles I think and it was mainly -- >>ME<< I'm embarrassed to say that I had a compound issue: 1. Two of the five cables I bought seem incompatible, drives connected after one of these cables were not detected! 2. I'm a dick - I had knocked power off for a large number of by drives (2nd PSU!) - THINGS WORK BETTER WHEN PLUGGED IN! Now I'm over my brain fart I can start to fix properly, the cables I bought (same supplier) are: https://www.scan.co.uk/products/1m-broadcom-sff-8643-to-x4-sata-cable-mini-sas-hd-to-sata-data-port (works) and https://www.scan.co.uk/products/60cm-silverstone-12gb-minisas-hd-sff-8643-to-sata-7pinplussideband-cable (don't work) What should I be looking for vs avoid in these cables, I'm not seeing the difference -
avag0 9305-24i not detecting all drives
fysmd replied to fysmd's topic in Storage Devices and Controllers
I dont know what forward vs reverse breakout means.... Tried the HBA in two identical machines, same result and have now replaced the card, same result Same cables and drives though I've upgraded the firmware on the HBA, same results, no BIOS update available for MB. Could this be MB or Drive compatibility? -
avag0 9305-24i not detecting all drives
fysmd replied to fysmd's topic in Storage Devices and Controllers
Oh I hope not, servers been down for days already Would be just my luck though! Anybody know if there's any config I need to do to enable all ports for sata drives or anything similar? -
Hi all, I'm new to this card and just installed it. It seems to only detect drives connected to the first port. All four connected drives are detected but moving the same cable to other ports on the card leaves them undetected. If I run the setup tool at boot time (ctrl-c) I see the same thing, just four drives. Any tips?
-
A drive failed, says emulated but content not in user share(s)
fysmd replied to fysmd's topic in General Support
OK, well my new toy will be with me tomorrow so I'll take it from there. Can I just check the approach when I get the new controller, after reconnecting everything should I expect the one disabled drive to still be disabled? is there a way to force it back into life or is it safer (better) to just all it to allow the array to rebuild on the same disk again? -
A drive failed, says emulated but content not in user share(s)
fysmd replied to fysmd's topic in General Support
This sounds odd to me. I do not have any stand-alone port multipliers, could they be a part of the card I'm using?? Also, I have been running this config for many years now and I have only ever had similar issues when I was mixing REISERFS and XFS, I migrated all data without issue and it's been stable since then (until now!). I have upgraded unraid - is it possible (advisable?) to downgrade back to a version which did not exhibit these errors? I have also taken the plunge and gone for one of these puppies: https://www.scan.co.uk/products/24-port-broadcom-sas-9305-24i-host-bus-adaptor-internal-12gb-s-sas-pcie-30 it's on the recommended HW list so I ought to be golden with this fella - will I?? I have another question regarding rebuilding now. I have disabled all software which might be trying to write changes to my unraid array but with one drive (allegedly) missing and and another in a very off state, how should I proceed to get back healthy? Obviously if both drive refuse to get recognised i cant rebuild the data from parity :( -
A drive failed, says emulated but content not in user share(s)
fysmd replied to fysmd's topic in General Support
O-K.. I had an almost identical issue again a couple fo days ago and followed the process described above (Maintenance mode, disk checks etc, rebuild array after remounting drive and array returned to health after a parity rebuild. Today, I have the same symptoms again but with a different drive again - diag attached prior to doing anything:. I notice that two drives from my array appear in my unassigned drives section on the main screen. One of them is the drive reporting failed and the other claims to still be healthy in the array, screenshot below: Array still started but not happy at all, lots of data missing Am I doing something really wrong somewhere, been running Unraid for a very long time without issues at all, seems to be all wrong right now! Please help! server-diagnostics-20181205-2219.zip.thumb.png.73fef282948edb1cc16a90438fd4503a.png)
-
A drive failed, says emulated but content not in user share(s)
fysmd replied to fysmd's topic in General Support
Half way through rebuilding and the contents do seem to be emulated again😄 (I was worried there!). Thank you SOOOOO much for the help, I think without this assistance I would have removed the drive from the array, rebuilt parity, mouted the drive externally and copied any working content back to the array. I had a power incident at home a couple of weeks ago, while the machine stayed up, one drive stopped working completely and I suspect another had a similar issue to this one (it mounted externally and worked, then passed a preclear without issue!) Time I think to invest in fresh batteries for the UPS which isn't on at the moment!! -
A drive failed, says emulated but content not in user share(s)
fysmd replied to fysmd's topic in General Support
It just says not installed when started, unassigned when not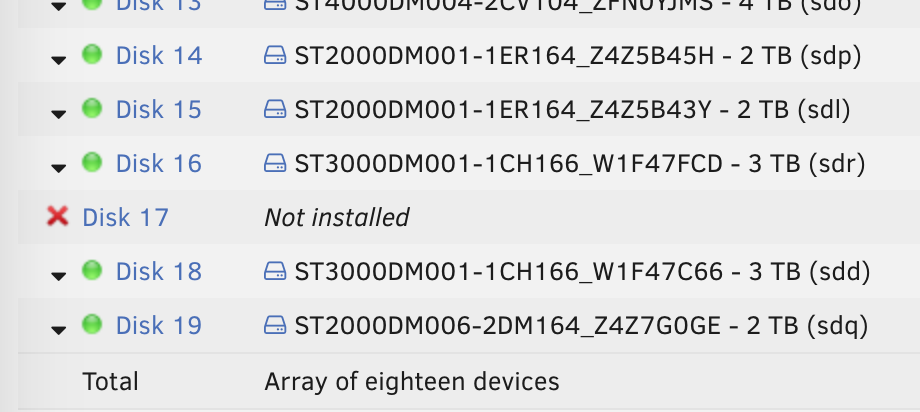
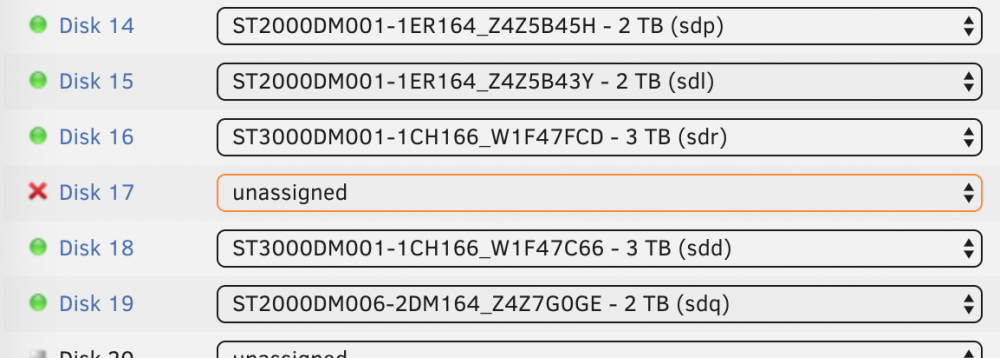
-
A drive failed, says emulated but content not in user share(s)
fysmd replied to fysmd's topic in General Support
Errr . I just clicked on disk17 in the GUI, I dont see any reference to which device it's working on.. -
A drive failed, says emulated but content not in user share(s)
fysmd replied to fysmd's topic in General Support
OK, did not mount when I restarted the array so ran with -L: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (1:138984) is ahead of log (1:2). Format log to cycle 4. done when I try to start the array again, disk17 says unassigned... I mean with the array stopped, there is no disk assignment in disk17 slot. The drive does appear in the drop down but I guess if I reassign it here it'll erase / overwrite it? Do I need to force it back into the array or something?

.png.ec063ee8a75f40b2874df50a302d1d54.png)
.png.e5af8b21ee95d4d210e0daf12bd85980.png)

