




GerryGER
Members
-
Joined
-
Last visited
Everything posted by GerryGER
-
No splitters, the PSU is also rather new (max. 2 years or so). Because of your previous comment I regained my hope ;) and tried once more. I connected the HDD to a different Port on the JMB and reseated the SATA Power, lets see... Edit: Yeah, that didn't work out. I will switch to a different SATA Power port, just in case... Edit 2: I'm having a virtual stroke right now, I went back and checked my screenshot with all my drives and... well, realized that BOTH MY TOSHIBAS END ON THE SERIAL F94G... when searching the HDD, I only checked those last 4 digits and was working on the wrong drive the whole time! Get the Cat5 o’ nine tails and give me a good whipping and do it again for me still not having labeled them! And do it a third time, for me forgetting that I put the drives in Top Down order from Parity to last Disk inside the case... So I changed the correct SATA cable now and also switched the SATA Power port, just in case. First 150GB are looking fine. Now at 600GB read and its still looking clean. What would the recommended best practice approach be? Rebuilding or trusting the drive? I'm pretty (like 99,x%) sure I haven't written anything to the disk since the error. Moved from it? Not 100% sure, but since the disk is basically full, I doubt it or is the stat on that not correctly displayed, since it was emulated?
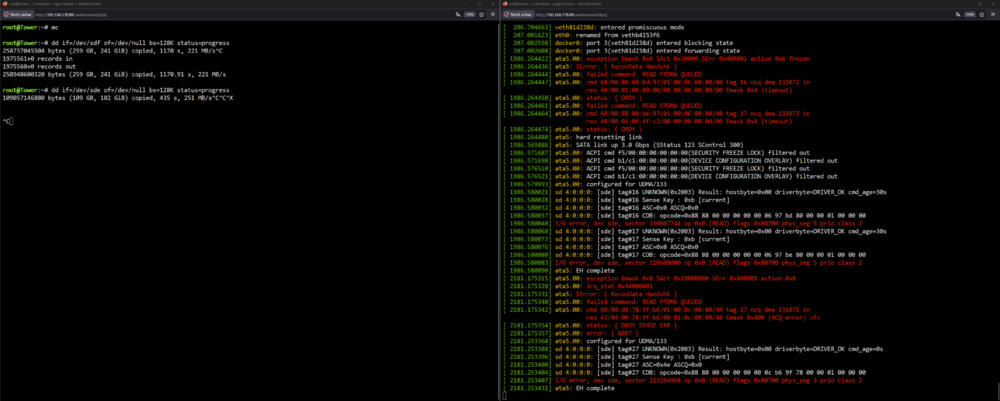
-
Yeah and that's the problem... I already changed cables twice and used different SATA Ports. The result is still this: I mean I could wait until the HBA arrives and try with that, but I would prefer to try the HBA with a working unRAID... anyway, I ordered brand new SATA cables, just to be sure. I can check those tomorrow.
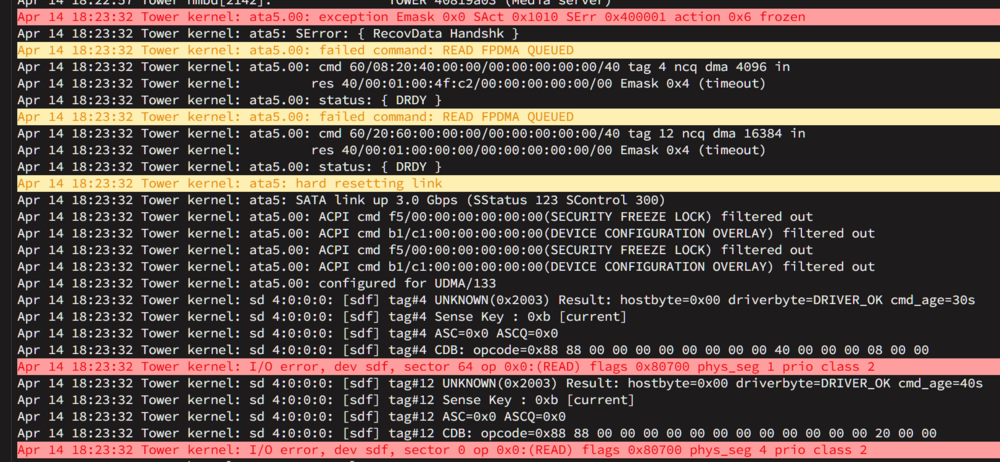
-
tower-diagnostics-20260414-1826.zip Edit: Wtf is it with the unRAID Forum deleting whole messages, when attaching the diagnostics... anyway, I'm not typing all of it again. TL;DR FYI: OG error happened on Mainboard SATA Port -> new cable and attached to JMB585 -> error occurred again -> switched out to a new cable again and attached back to Mainboard Port since I'm still waiting on my LSI 9207-8i.
-
Hi, maybe someone can already help me with this info, I can upload a proper log / diagnostic tomorrow. Apr 12 22:34:40 Tower kernel: ata5.00: status: { DRDY } Apr 12 22:34:40 Tower kernel: ata5.00: failed command: READ FPDMA QUEUED Apr 12 22:34:40 Tower kernel: ata5.00: cmd 60/40:c0:e0:04:5d/00:00:00:04:00/40 tag 24 ncq dma 32768 in Apr 12 22:34:40 Tower kernel: res 40/00:01:01:4f:c2/00:00:00:00:00/00 Emask 0x4 (timeout) ... Apr 12 22:37:56 Tower kernel: ata5.00: sense data available but port frozen Apr 12 22:37:56 Tower kernel: ata5.00: exception Emask 0x10 SAct 0x80fc0007 SErr 0x400101 action 0x6 frozen Apr 12 22:37:56 Tower kernel: ata5.00: irq_stat 0x08000000, interface fatal error Apr 12 22:37:56 Tower kernel: ata5: SError: { RecovData UnrecovData Handshk } Apr 12 22:37:56 Tower kernel: ata5.00: failed command: WRITE FPDMA QUEUED Apr 12 22:37:56 Tower kernel: ata5.00: cmd 61/08:00:28:26:0a/00:00:00:03:00/40 tag 0 ncq dma 4096 out Apr 12 22:37:56 Tower kernel: res 43/84:01:00:00:00/00:00:00:00:00/00 Emask 0x10 (ATA bus error) Apr 12 22:37:56 Tower kernel: ata5.00: status: { DRDY SENSE ERR } Apr 12 22:37:56 Tower kernel: ata5.00: error: { ICRC ABRT } Apr 12 22:37:56 Tower kernel: ata5.00: failed command: WRITE FPDMA QUEUED Apr 12 22:37:56 Tower kernel: ata5.00: cmd 61/08:08:30:26:0a/00:00:00:03:00/40 tag 1 ncq dma 4096 out Apr 12 22:37:56 Tower kernel: res 43/84:01:00:00:00/00:00:00:00:00/00 Emask 0x10 (ATA bus error) Apr 12 22:37:56 Tower kernel: ata5.00: status: { DRDY SENSE ERR } Apr 12 22:37:56 Tower kernel: ata5.00: error: { ICRC ABRT } Apr 12 22:37:56 Tower kernel: ata5.00: failed command: READ FPDMA QUEUED SMART data showed: Reallocated Sectors = 0 Pending Sectors = 0 Uncorrectable = 0 I guessed I hit the SATA cable when I replaced a SSD, so I switched out the cable and also switched the SATA Port, just in case. Did a test read with dd if=/dev/sde of=/dev/null bs=100M status=progress and checked the log: I guess it wasn't just hit to the cable...? I'm still on warranty and checked RMA with Toshiba, but before RMAing and uploading 14TB of data to a friends unRAID, I would like to know if my HDD is dying or my SATA ports are just F-ed, since it's an old Z68 Sandy Bride board. Thanks.
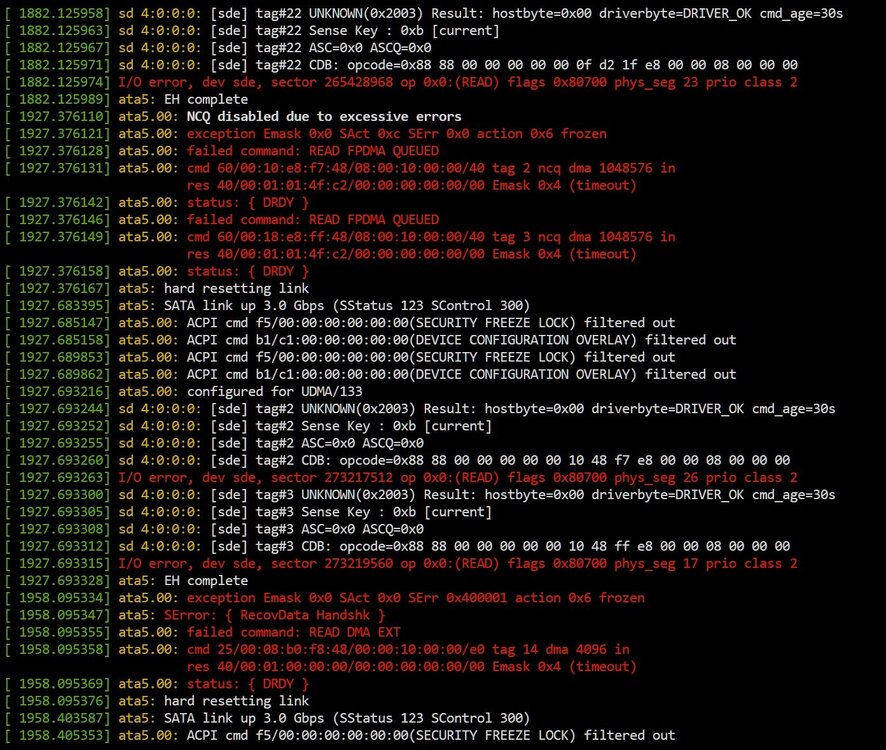

-
So, can I consider everything ok again? What's the safest way to restoring Docker? Deleting it via the WebGUI and restoring the containers? (They should be recoverable via the Docker selection or not?)
-
Must have been an old .cfg as they are definitely NOT shared. Not in unRAID and not visible on the network. Never saw that option, thanks, just did that. I now put it at 15GB min. and cleared up 50GB on the Cache. A few 100GB on the Array itself. As soon as Docker runs again, I can clean up more stuff.
-
Yeah, will do. ;) Attached. tower-diagnostics-20260203-2227.zip
-
Yeah, with current HDD prices, that is only going to change marginally. Maybe I will gut my 4TB external and use that for the time being. Disabled both, I'm not using VMs anyway. Scrub:
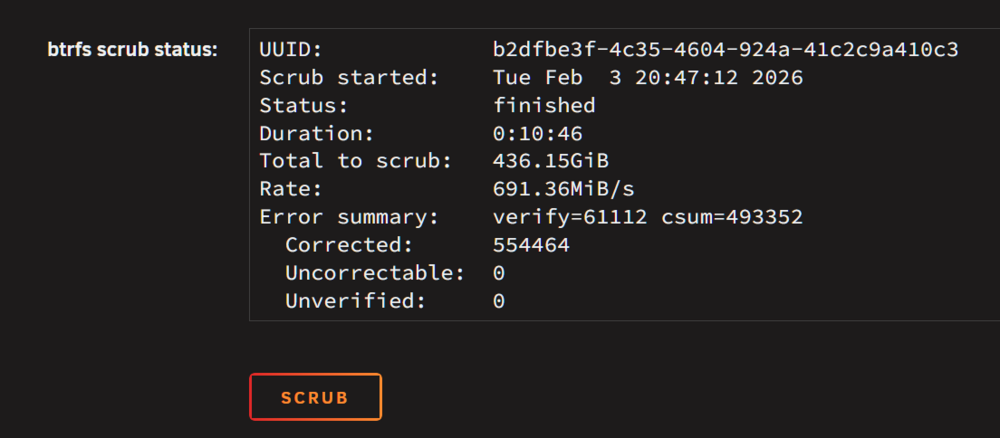
-
Edit: uh... why the hell is all my text gone?! Have to retype this when I'm back. I will keep the diag attached. Reattached the cables and didn't see the errors anymore. tower-diagnostics-20260203-1757.zip
-
Well, I thought I did that... checked all cables and no disk is shown as error / no CRC errors pop up.
-
Hi, I'm greeted on the Docker Tab as the title states: "Docker Service failed to start". I saw that I accidentally filled the whole cache pool and thought.... "Well, I guess that's the problem", cleared up some space and... nope, still failed to start. Then I checked the Log and saw that there were some errors with sdb (which makes me sweat a little, since it's one of my 14TB drives) and BTRFS errors on sdc, which would make more sense in the context of Docker, since sdc should be my cache (pool) and apps/docker are on there. sdc and sdf are some "old" 250GB SSDs which I use for the pool. First I thought it was caused by sdf, since the SATA cable came loose a bit(? -> unRAID reporting the SSD as disconnected) when I opened my case to install an Intel Gigabit CT Desktop NIC, but I guess that was just coincidence? The array wasn't on while I was doing this. How should I go about this? I don't dare to try anything in repairing BTRFS, without someone's more experience opinion... tower-diagnostics-20260202-2156.zip
-
Meh, I actually wanted to say "Latest unRaid update fixed this", but the problem just occurred again, after working for the last few days... Diagnostics is right after it happened again, first the files were written to unRaid with like 50-60MB/s and after a few GB written dropped to 1,3MB/s. tower-diagnostics-20240404-1559.zip
-
So far, no. Only after sleep it seems. But at the other hand... I never kept the server running... I will keep the server running for today and tomorrow and check what happens. Edit: Ironically, that just happened. I rebooted the server, deactivated S3 sleep, copied files, worked for a few GB and then stuck at 1.1MB/S again. Diagnostic attached. tower-diagnostics-20240328-1317.zip
-
So far I couldn't reproduce the mid transfer drop, but attached a log where it got stuck on 1-3MB/s again. Before going to sleep, I copied some files and it worked fine... Yes. tower-diagnostics-20240325-2301.zip
-
I wonder what could cause this? I have been using the S3 plugin for the last 10 years and never experienced something like this. Just now, again it started out perfectly fine, even topping out at 110MB/s, but then gets stuck at 1,xxMB/s...
-
Hi, for a few days now, my unRAID had been bugging me: Sometimes when I write to a share, my write speed gets stuck on 1,1MB/s. At other times the write speed starts out good (40-110MB/s), but then drops. Reading can get slow too, but more like 10-15MB/s. And sometimes it just works! I tried different PCs and they all suffer the same problem. Writing to a Windows share from PC to PC works fine. Mounting an external SMB share to unRAID and copying files from it to the array, suffers from the same problem. It doesn't matter what HDD is getting accessed inside unRAID and the SSD Cache has the same problem. Rebooting unRAID or the PCs/SMB share sometimes helps. No change if I turn all Dockers off. My network hardware hasn't been touched (PCs <-> GBit Switch <-> a good 10m Cat. 7 cable <-> Router <-> unRAID connected to Router), the only thing that changed with unRAID was a new drive (Toshiba MG09 18TB, pre-cleared and then used as Parity) - a quick parity checked showed 140MB/s+ speed. Router reboot doesn't help. Connection from my PC to the router gives full 1GBit/s to the internet, so these cables are fine. I also switched out the cable from unRAID to the router - that worked for a day, next day (after S3 Sleep) the write speed started out ok and later dropped to 1.1MB/s again... I have a feeling that the NIC gets stuck on 10MBit/s after S3 Sleep, but ethtool gives me advertised link mode as 1000baseT, partner too, NIC is supposedly in "1000MBit/s" Mode. I have absolutely no idea what the heck is going on... tower-diagnostics-20240324-1219.zip
-
So that means I could just keep it there and start the Parity Rebuild?
-
Only for a few of those (very personal stuff), but most is just Entertainment like movies etc., who don't get an extra backup. So: Move stuff out of lost+found and then do a parity rebuild? What happens with the lost+found folder during/after the rebuild?
-
Yeah that's there and filled with 3000 folders and files without a file ending. Should I move these files and folders and try to puzzle everything back together or...? No to mention that Parity is still not rebuild, since I started the rebuild and stopped it.
-
Updated last post, how should I proceed? Contend on the disk is currently only emulated.
-
"Phase 1 - find and verify superblock... bad primary superblock - bad sector size !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... would write modified primary superblock Primary superblock would have been modified. Cannot proceed further in no_modify mode. Exiting now." Ah I'm dumb, had -n on... after removing -n and going with only -v: Phase 1 - find and verify superblock... bad primary superblock - bad sector size !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... writing modified primary superblock - block cache size set to 1420144 entries Phase 2 - using internal log - zero log... zero_log: head block 493884 tail block 493884 - scan filesystem freespace and inode maps... Metadata CRC error detected at 0x43d440, xfs_agf block 0x1/0x200 agf has bad CRC for ag 0 Metadata CRC error detected at 0x468740, xfs_agi block 0x2/0x200 agi has bad CRC for ag 0 bad magic # 0x0 for agf 0 bad version # 0 for agf 0 bad length 0 for agf 0, should be 268435455 bad uuid 00000000-0000-0000-0000-000000000000 for agf 0 bad magic # 0x0 for agi 0 bad version # 0 for agi 0 bad length # 0 for agi 0, should be 268435455 bad uuid 00000000-0000-0000-0000-000000000000 for agi 0 reset bad agf for ag 0 reset bad agi for ag 0 bad levels 0 for btbno root, agno 0 bad agbno 0 for btbno root, agno 0 bad levels 0 for btbcnt root, agno 0 bad agbno 0 for btbcnt root, agno 0 bad levels 0 for refcountbt root, agno 0 bad agbno 0 for refcntbt root, agno 0 bad levels 0 for inobt root, agno 0 bad agbno 0 for inobt root, agno 0 bad levels 0 for finobt root, agno 0 bad agbno 0 for finobt root, agno 0 agi unlinked bucket 0 is 0 in ag 0 (inode=0) agi unlinked bucket 1 is 0 in ag 0 (inode=0) agi unlinked bucket 2 is 0 in ag 0 (inode=0) agi unlinked bucket 3 is 0 in ag 0 (inode=0) agi unlinked bucket 4 is 0 in ag 0 (inode=0) agi unlinked bucket 5 is 0 in ag 0 (inode=0) agi unlinked bucket 6 is 0 in ag 0 (inode=0) agi unlinked bucket 7 is 0 in ag 0 (inode=0) agi unlinked bucket 8 is 0 in ag 0 (inode=0) agi unlinked bucket 9 is 0 in ag 0 (inode=0) agi unlinked bucket 10 is 0 in ag 0 (inode=0) agi unlinked bucket 11 is 0 in ag 0 (inode=0) agi unlinked bucket 12 is 0 in ag 0 (inode=0) agi unlinked bucket 13 is 0 in ag 0 (inode=0) agi unlinked bucket 14 is 0 in ag 0 (inode=0) agi unlinked bucket 15 is 0 in ag 0 (inode=0) agi unlinked bucket 16 is 0 in ag 0 (inode=0) agi unlinked bucket 17 is 0 in ag 0 (inode=0) agi unlinked bucket 18 is 0 in ag 0 (inode=0) agi unlinked bucket 19 is 0 in ag 0 (inode=0) agi unlinked bucket 20 is 0 in ag 0 (inode=0) agi unlinked bucket 21 is 0 in ag 0 (inode=0) agi unlinked bucket 22 is 0 in ag 0 (inode=0) agi unlinked bucket 23 is 0 in ag 0 (inode=0) agi unlinked bucket 24 is 0 in ag 0 (inode=0) agi unlinked bucket 25 is 0 in ag 0 (inode=0) agi unlinked bucket 26 is 0 in ag 0 (inode=0) agi unlinked bucket 27 is 0 in ag 0 (inode=0) agi unlinked bucket 28 is 0 in ag 0 (inode=0) agi unlinked bucket 29 is 0 in ag 0 (inode=0) agi unlinked bucket 30 is 0 in ag 0 (inode=0) agi unlinked bucket 31 is 0 in ag 0 (inode=0) agi unlinked bucket 32 is 0 in ag 0 (inode=0) agi unlinked bucket 33 is 0 in ag 0 (inode=0) agi unlinked bucket 34 is 0 in ag 0 (inode=0) agi unlinked bucket 35 is 0 in ag 0 (inode=0) agi unlinked bucket 36 is 0 in ag 0 (inode=0) agi unlinked bucket 37 is 0 in ag 0 (inode=0) agi unlinked bucket 38 is 0 in ag 0 (inode=0) agi unlinked bucket 39 is 0 in ag 0 (inode=0) agi unlinked bucket 40 is 0 in ag 0 (inode=0) agi unlinked bucket 41 is 0 in ag 0 (inode=0) agi unlinked bucket 42 is 0 in ag 0 (inode=0) agi unlinked bucket 43 is 0 in ag 0 (inode=0) agi unlinked bucket 44 is 0 in ag 0 (inode=0) agi unlinked bucket 45 is 0 in ag 0 (inode=0) agi unlinked bucket 46 is 0 in ag 0 (inode=0) agi unlinked bucket 47 is 0 in ag 0 (inode=0) agi unlinked bucket 48 is 0 in ag 0 (inode=0) agi unlinked bucket 49 is 0 in ag 0 (inode=0) agi unlinked bucket 50 is 0 in ag 0 (inode=0) agi unlinked bucket 51 is 0 in ag 0 (inode=0) agi unlinked bucket 52 is 0 in ag 0 (inode=0) agi unlinked bucket 53 is 0 in ag 0 (inode=0) agi unlinked bucket 54 is 0 in ag 0 (inode=0) agi unlinked bucket 55 is 0 in ag 0 (inode=0) agi unlinked bucket 56 is 0 in ag 0 (inode=0) agi unlinked bucket 57 is 0 in ag 0 (inode=0) agi unlinked bucket 58 is 0 in ag 0 (inode=0) agi unlinked bucket 59 is 0 in ag 0 (inode=0) agi unlinked bucket 60 is 0 in ag 0 (inode=0) agi unlinked bucket 61 is 0 in ag 0 (inode=0) agi unlinked bucket 62 is 0 in ag 0 (inode=0) agi unlinked bucket 63 is 0 in ag 0 (inode=0) sb_icount 146880, counted 212288 sb_ifree 1301, counted 727 sb_fdblocks 1475402857, counted 1098436740 root inode chunk not found Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 imap claims in-use inode 131 is free, correcting imap imap claims in-use inode 132 is free, correcting imap imap claims in-use inode 133 is free, correcting imap imap claims in-use inode 134 is free, correcting imap imap claims in-use inode 135 is free, correcting imap imap claims in-use inode 136 is free, correcting imap imap claims in-use inode 139 is free, correcting imap imap claims in-use inode 140 is free, correcting imap imap claims in-use inode 141 is free, correcting imap imap claims in-use inode 142 is free, correcting imap imap claims in-use inode 143 is free, correcting imap imap claims in-use inode 144 is free, correcting imap imap claims in-use inode 145 is free, correcting imap imap claims in-use inode 146 is free, correcting imap imap claims in-use inode 147 is free, correcting imap imap claims in-use inode 148 is free, correcting imap imap claims in-use inode 149 is free, correcting imap imap claims in-use inode 150 is free, correcting imap imap claims in-use inode 151 is free, correcting imap imap claims in-use inode 152 is free, correcting imap imap claims in-use inode 153 is free, correcting imap imap claims in-use inode 154 is free, correcting imap imap claims in-use inode 155 is free, correcting imap imap claims in-use inode 156 is free, correcting imap imap claims in-use inode 157 is free, correcting imap imap claims in-use inode 158 is free, correcting imap imap claims in-use inode 159 is free, correcting imap imap claims in-use inode 160 is free, correcting imap imap claims in-use inode 161 is free, correcting imap imap claims in-use inode 162 is free, correcting imap imap claims in-use inode 163 is free, correcting imap imap claims in-use inode 164 is free, correcting imap imap claims in-use inode 165 is free, correcting imap imap claims in-use inode 166 is free, correcting imap imap claims in-use inode 167 is free, correcting imap imap claims in-use inode 168 is free, correcting imap imap claims in-use inode 169 is free, correcting imap imap claims in-use inode 170 is free, correcting imap imap claims in-use inode 171 is free, correcting imap imap claims in-use inode 172 is free, correcting imap imap claims in-use inode 173 is free, correcting imap imap claims in-use inode 174 is free, correcting imap imap claims in-use inode 175 is free, correcting imap imap claims in-use inode 176 is free, correcting imap imap claims in-use inode 177 is free, correcting imap imap claims in-use inode 178 is free, correcting imap imap claims in-use inode 179 is free, correcting imap imap claims in-use inode 180 is free, correcting imap imap claims in-use inode 181 is free, correcting imap imap claims in-use inode 182 is free, correcting imap imap claims in-use inode 183 is free, correcting imap imap claims in-use inode 184 is free, correcting imap imap claims in-use inode 185 is free, correcting imap imap claims in-use inode 186 is free, correcting imap imap claims in-use inode 187 is free, correcting imap imap claims in-use inode 188 is free, correcting imap imap claims in-use inode 189 is free, correcting imap imap claims in-use inode 190 is free, correcting imap imap claims in-use inode 191 is free, correcting imap - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 entry "Anime" in shortform directory 128 references non-existent inode 1097794569 junking entry "Anime" in directory inode 128 entry "Serien" in shortform directory 128 references non-existent inode 1654179027 junking entry "Serien" in directory inode 128 - agno = 3 entry "[SNIP PRIVATE ;)]" at block 0 offset 3320 in directory inode 131 references non-existent inode 470699848 clearing inode number in entry at offset 3320... entry "[SNIP PRIVATE ;)]" at block 1 offset 4008 in directory inode 131 references non-existent inode 470699851 clearing inode number in entry at offset 4008... entry "[SNIP PRIVATE ;)]" at block 2 offset 3520 in directory inode 131 references non-existent inode 1654179040 clearing inode number in entry at offset 3520... [a bit more of this] bad hash table for directory inode 4394447249 (no data entry): rebuilding rebuilding directory inode 4394447249 bad hash table for directory inode 4394448335 (no data entry): rebuilding rebuilding directory inode 4394448335 entry ".." in directory inode 4402441515 points to non-existent inode 947597284, marking entry to be junked bad hash table for directory inode 4402441515 (no data entry): rebuilding rebuilding directory inode 4402441515 entry ".." in directory inode 4402453480 points to non-existent inode 947620170, marking entry to be junked bad hash table for directory inode 4402453480 (no data entry): rebuilding rebuilding directory inode 4402453480 bad hash table for directory inode 4402459807 (no data entry): rebuilding rebuilding directory inode 4402459807 entry ".." in directory inode 4402462710 points to non-existent inode 947627638, marking entry to be junked bad hash table for directory inode 4402462710 (no data entry): rebuilding rebuilding directory inode 4402462710 entry ".." in directory inode 4402473729 points to non-existent inode 947633416, marking entry to be junked bad hash table for directory inode 4402473729 (no data entry): rebuilding rebuilding directory inode 4402473729 entry ".." in directory inode 4461736554 points to non-existent inode 1654179027, marking entry to be junked bad hash table for directory inode 4461736554 (no data entry): rebuilding rebuilding directory inode 4461736554 entry ".." in directory inode 4464777177 points to non-existent inode 2132507164, marking entry to be junked bad hash table for directory inode 4464777177 (no data entry): rebuilding rebuilding directory inode 4464777177 [more of this] bad hash table for directory inode 25774422906 (no data entry): rebuilding rebuilding directory inode 25774422906 - traversal finished ... - moving disconnected inodes to lost+found ... disconnected inode 159, moving to lost+found disconnected inode 160, moving to lost+found disconnected inode 161, moving to lost+found disconnected dir inode 2533438893, moving to lost+found disconnected dir inode 2533438895, moving to lost+found disconnected dir inode 2636384149, moving to lost+found disconnected dir inode 2638402822, moving to lost+found disconnected dir inode 2638402854, moving to lost+found disconnected dir inode 2638606000, moving to lost+found disconnected inode 2638606162, moving to lost+found disconnected inode 2638606163, moving to lost+found disconnected inode 2638606164, moving to lost+found disconnected inode 2638606165, moving to lost+found disconnected inode 2638606166, moving to lost+found disconnected inode 2638606167, moving to lost+found [...] Phase 7 - verify and correct link counts... resetting inode 128 nlinks from 15 to 13 resetting inode 131 nlinks from 145 to 141 resetting inode 137 nlinks from 2 to 1323 resetting inode 4368292562 nlinks from 42 to 38 resetting inode 8594108591 nlinks from 31 to 29 resetting inode 8729374599 nlinks from 7 to 6 resetting inode 8873887464 nlinks from 21 to 20 resetting inode 6725417451 nlinks from 28 to 26 resetting inode 11132024064 nlinks from 13 to 12 resetting inode 6727076067 nlinks from 16 to 15 resetting inode 8896771389 nlinks from 44 to 40 resetting inode 4394423285 nlinks from 18 to 17 resetting inode 8574919624 nlinks from 17 to 13 resetting inode 25784296244 nlinks from 5 to 4 Note - stripe unit (0) and width (0) were copied from a backup superblock. Please reset with mount -o sunit=,swidth= if necessary XFS_REPAIR Summary Wed Jun 7 12:07:23 2023 Phase Start End Duration Phase 1: 06/07 12:06:24 06/07 12:06:24 Phase 2: 06/07 12:06:24 06/07 12:06:25 1 second Phase 3: 06/07 12:06:25 06/07 12:06:47 22 seconds Phase 4: 06/07 12:06:47 06/07 12:06:47 Phase 5: 06/07 12:06:47 06/07 12:06:48 1 second Phase 6: 06/07 12:06:48 06/07 12:07:07 19 seconds Phase 7: 06/07 12:07:07 06/07 12:07:07 Total run time: 43 seconds done
-
It was xfs_repair -v /dev/sdc
-
Hi, yesterday my Disk 2 went "Unmountable: Wrong or no file system", so I tried "xfs_repair", but that went on for 6+ hours and I stopped it, since there was no indication on how long it would continue to take (endless spam of "...." and it initially started with an error about the superblock being damaged/not found). A friend of mine recommended me to just do a parity rebuild and be done with it. So I stopped the array, took Disk2 out, started the array, stopped it, re-added Disk 2 and started the Parity rebuild, 20 seconds later, the "Unmountable" option popped up again. How should I proceed? I didn't dare to format it, since there is the warning about "update Parity to reflect this", which sounded like the data can't be recovered by parity rebuild anymore...

-
Using the Add-on "Cookie Quick Manager" and deleting the Cookies for my unRAIDs IP actually worked. Dunno why FFs onboard cookie deleting didn't work.
-
Yeah, I later figured out that this had to be a problem with Firefox, since I could still access the WebGUI with Brave from my Smartphone. On my PC Chrome also works. Deleting the Cookies for "192.168.178.89" (my unRAID IP) doesn't help though.





