




opiekeith
Members
-
Joined
-
Last visited
Everything posted by opiekeith
-
Switched to airvpn for the port forwarding. It seems to work and I tested it with a leak tester, but this one line in my logs has me suspect that I am missing something. 2024-11-04 12:44:13,104 DEBG 'start-script' stdout output: [info] VPN provider 'airvpn' not supported for automatic port forwarding, skipping incoming port assignment I got a port in my account on the airvpn site, I added it in the qbittorrent gui under connections and I also created a new port in unraid with this port, but I still get this during startup. Am I reading too much into this or am I missing something ? I do see a number of tracker timeouts or operation not permitted or host not found (authoritative), but not sure if that's just common. I mainly use pubic torrents as I don't have access to any private sites. TIA, Opie
-
Everything is copied over and Uraid is back up. TY for the help. Learned a lot about Unraid these last few weeks
-
So it just knows that there is a Pictures directory in /mnt/disk3/ drive. Ok, ty.
-
if I go to /mnt/usr/pictures it has all of my picture files that are spread across my 6 disk. I am just courious how unraid knows to look in disk3 for my prictures directory that I copied over. Thats all, I am just paranoid that after copiing over the files to the disk, unraid won't see them in the combined folder.
-
I have started copying files over. QQ, does unraid know about the files because of the folder structure? I guess unraid should just know the files on this disk once copied over? --Keith
-
Finally finished, and it says "Sorry, could not find valid secondary superblock Exiting now. " What options do I have? I do have the old drive that this one was replaced. I can copy things over if it comes down to it.
-
Running now, will update when finished.
-
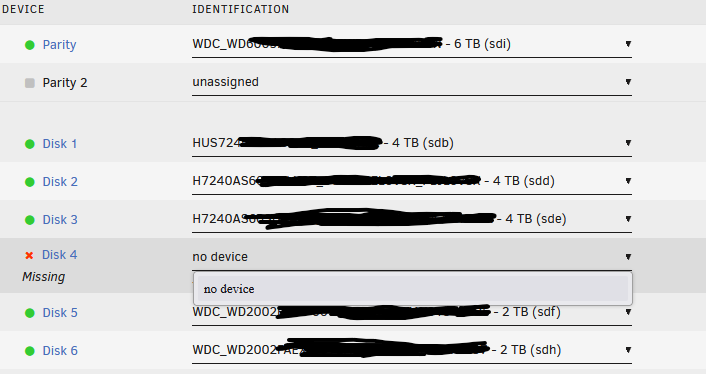
I am on drive 2 to be replaced. I lost data on the first one so trying not to loose data on this one. I replaced a drive that was showing errors during a smart test. I installed the new drive, and it was showing type 2 formatting. So I reformatted with the following command "sg_format --format --fmtpinfo=0 /dev/sde". After this, I started the parity rebuild. During the parity rebuild I noticed that it said that it was unmountable? unsupported or no file sytem, but was hoping the rebuild would fix this. The Parity rebuild is now done and I still get the same message. During my first drive I removed the rebuilt drive and reformatted but ended up loosing data since it did not rebuild again after the format, so I don't want to do that again. What do I need to do to get this drive normal without loosing any data, now that the parity has rebuilt. I don't want to do anything before asking first. I don't see disk3 listed.. drwxrwxrwx 10 nobody users 188 Jan 8 07:25 disk1/ drwxrwxrwx 12 nobody users 232 Jan 8 07:25 disk2/ drwxrwxrwx 8 nobody users 121 Jan 8 07:25 disk4/ drwxrwxrwx 2 nobody users 6 Jan 8 07:25 disk5/ drwxrwxrwx 2 nobody users 6 Jan 8 07:25 disk6/ --Keith hades-diagnostics-20240108-2303.zip


-
That fixed it. The format completed after about 15 hours. It looks like the preclear is now running.
-
I got that, its just his wording it threw me off thats all. I am 15% in with the format. Hopefully that will fix my issue.
-
No go, I even tried switching the cables and still nothing. On another thread that I am asking about this, some one mentioned to "LSI HBA and retry the format on the /dev/sg[0-9] SCSI generic device" but not sure what the LSI HBA means. and lsblk, show s sdc as: sdc 8:32 0 0B 0 disk and it does show under SCSI Devices: SCSI Devices [5:0:1:0]disk SEAGATE ST6000NM0095 NE00 /dev/sdc - I wonder if the format screwed up and now I just need to reformat. I got the format regoing, this time in console instead of unraid terminal.
-
ugh, started the format noticed it was going to take awhile, and when I came back to check on it, screen was gone and disk is now missing and is not showing up anymore. Restarted, and it does not even show up during the boot when the HBA starts scanning connected drives. Attached is the latest diag. The drive was /dev/sdc, and this was the command I ran to format it. sg_format --format --fmtpinfo=0 /dev/sdc --Keith hades-diagnostics-20240101-1718.zip
-
Ok. Let me do that then.
-
I did not think it did, but I went under the assumption based on my readings that newer version of unraid don't necessarily need to have drives precleared. It does some checks during the rebuild process. Thats why I just went ahead and did the rebuild. See attached for the latest diagnostics. It seems I am going to have to buy another drive to replace another failing drive so I will get a chance to run preclear on that one when I get it in and replaced. Then one day I will be able to replace my MB/CPU and add a new cache drive, one day. hades-diagnostics-20231231-0954.zip
-
/sigh. I guess I will order me another hard drive. Ty for the info.
-
I have been having drive issues over the past few weeks and have already replaced one drive. I ran the short smart test on all of my drives after the fact and another drive failed a quick test. Is the attached info indicititive of another drive that looks to need to be replaced? SMART Self-test log Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ] Description number (hours) # 1 Background short Failed in segment --> 3 9485 - [- - -] # 2 Background short Failed in segment --> 3 9485 - [- - -] H7240AS60SUN4.0T_001432EGKUNX_PCGGKUNX_35000cca05c1a8078-20231230-1043.txt
-
I ended up just adding it to the cluster. It rebuilt without errors. I know it was not ideal and I would have preferred to have done a pre clear but my unraid was down for longer than I wanted. If I run into more errors I will remove it from the cluster and run a pre clear with formatting with type 1 to see if that fixes the issue. I will let this soak for a few days before I start a motherboard/cpu upgrade on my unraid box.
-
New Molex to SATA cable installed and doing the same as before. Same errors on the initial read. This is my second drive and don't want to submit another return if the drive is not the issue. To recap, I have replaced the data cable, and the power cable for the drive, and I still get the same error.
-
Switched out the data cable and running preclear again. Still getting the same error after about 4 and a half min. It does this 5 times, then fails. Dec 28 11:45:28 preclear_disk_ZAD201L30000C75286YQ_11826: Preclear Disk Version: 1.0.29 Dec 28 11:45:29 preclear_disk_ZAD201L30000C75286YQ_11826: Disk size: 6001175126016 Dec 28 11:45:29 preclear_disk_ZAD201L30000C75286YQ_11826: Disk blocks: 1465130646 Dec 28 11:45:29 preclear_disk_ZAD201L30000C75286YQ_11826: Blocks (512 bytes): 11721045168 Dec 28 11:45:29 preclear_disk_ZAD201L30000C75286YQ_11826: Block size: 4096 Dec 28 11:45:30 preclear_disk_ZAD201L30000C75286YQ_11826: Start sector: 0 Dec 28 11:45:32 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-read: pre-read verification started 1 of 5 retries... Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 248.999 s, 8.4 kB/s Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: dd: error reading '/dev/sdc': Input/output error Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 249.684 s, 8.4 kB/s Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: dd: error reading '/dev/sdc': Input/output error Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:57 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 249.7 s, 8.4 kB/s Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: dd: error reading '/dev/sdc': Input/output error Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 249.718 s, 8.4 kB/s Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: dd: error reading '/dev/sdc': Input/output error Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 249.736 s, 8.4 kB/s Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: dd: error reading '/dev/sdc': Input/output error Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 249.753 s, 8.4 kB/s Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: dd: error reading '/dev/sdc': Input/output error Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 249.771 s, 8.4 kB/s Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: dd: error reading '/dev/sdc': Input/output error Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records in Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 1+0 records out Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-Read: dd output: 2097152 bytes (2.1 MB, 2.0 MiB) copied, 249.788 s, 8.4 kB/s Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: dd process hung at 2097152, killing ... Dec 28 11:49:58 preclear_disk_ZAD201L30000C75286YQ_11826: Pre-read: pre-read verification started 2 of 5 retries... I should have my 4pin molex to sata power cable to put in tomorrow to rule out my taping the 3.3v pin on the new drives. That's the only thing different about my new drive vs my older/other ones. They don't need the 3.3v disabled.
-
I got a pass, no errors. This is a pretty old box. DDR3-1333 memory. I was using the memory test in the unraid menu. If there is another that I need to run, jlmk. About done with the second pass with no errors. I let it run for 4 passes without any failures.
-
Running preclear on a disk, and got the following warnings/errors attached. This is the second drive that I have gotten. I am about to order a new SFF-8087 to SFF-8482 cable. I did just order a molex to SATA power cable so I don't have to cover the 3.3v pins up, to rule that out. Here is a diagnostics also. hades-diagnostics-20231227-0032.zip preclear_disk_segate-hdd.txt
-
I submitted for a return and replacement drive. Hoping to get a new one this time around.
-
I ended up stopping the test after 14 hours and it was on 2% the whole time. Here is the SMART report from that. I have also uploaded the latest diagnostics. smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.1.64-Unraid] (local build) Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Vendor: HGST Product: HUS726060AL5215 Revision: D7J0 Compliance: SPC-4 User Capacity: 6,001,175,126,016 bytes [6.00 TB] Logical block size: 512 bytes Physical block size: 4096 bytes LU is fully provisioned Rotation Rate: 7200 rpm Form Factor: 3.5 inches Logical Unit id: 0x5000cca2426feb40 Serial number: NAHZK2ZS Device type: disk Transport protocol: SAS (SPL-4) Local Time is: Fri Dec 22 06:37:26 2023 PST SMART support is: Available - device has SMART capability. SMART support is: Enabled Temperature Warning: Enabled Read Cache is: Enabled Writeback Cache is: Enabled === START OF READ SMART DATA SECTION === SMART Health Status: OK Current Drive Temperature: 33 C Drive Trip Temperature: 85 C Manufactured in week 52 of year 2015 Specified cycle count over device lifetime: 50000 Accumulated start-stop cycles: 27 Specified load-unload count over device lifetime: 600000 Accumulated load-unload cycles: 1677 Elements in grown defect list: 261 Vendor (Seagate Cache) information Blocks sent to initiator = 80134226334187520 Error counter log: Errors Corrected by Total Correction Gigabytes Total ECC rereads/ errors algorithm processed uncorrected fast | delayed rewrites corrected invocations [10^9 bytes] errors read: 0 753 0 753 98043026 3167084.029 15 write: 0 4297 0 4297 19402902 875973.236 73 verify: 0 0 0 0 204724 5.341 0 Non-medium error count: 0 SMART Self-test log Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ] Description number (hours) # 1 Background long Failed in segment --> 7 43715 13150208 [0x3 0x5d 0x1] Long (extended) Self-test duration: 51471 seconds [14.3 hours] Background scan results log Status: waiting until BMS interval timer expires Accumulated power on time, hours:minutes 43737:16 [2624236 minutes] Number of background scans performed: 229, scan progress: 0.00% Number of background medium scans performed: 229 # when lba(hex) [sk,asc,ascq] reassign_status 1 43668:51 0000000007aca6e8 [3,11,0] Recovered via rewrite in-place 2 43668:48 0000000003c663c8 [3,11,0] Recovered via rewrite in-place 3 43668:47 0000000002cac718 [3,11,0] Recovered via rewrite in-place 4 43668:47 0000000002c78930 [3,11,0] Recovered via rewrite in-place 5 43668:46 0000000001cc1208 [3,11,0] Recovered via rewrite in-place 6 43668:46 0000000001c10ed0 [3,11,0] Recovered via rewrite in-place 7 43668:41 0000000000c78de0 [3,11,0] Recovered via rewrite in-place 8 43668:41 0000000000c60b58 [3,11,0] Recovered via rewrite in-place 9 43668:41 0000000000c23930 [3,11,0] Recovered via rewrite in-place 10 43668:41 0000000000c11068 [3,11,0] Recovered via rewrite in-place 11 43668:41 0000000000c11060 [3,11,0] Recovered via rewrite in-place General statistics and performance log page: General access statistics and performance: Number of read commands: 14648407550 Number of write commands: 4776372095 number of logical blocks received: 1710885225927 number of logical blocks transmitted: 6185710994363 read command processing intervals: 0 write command processing intervals: 0 weighted number of read commands plus write commands: 0 weighted read command processing plus write command processing: 0 Idle time: Idle time intervals: 1235886083 in seconds: 61794304.150 in hours: 17165.084 Protocol Specific port log page for SAS SSP relative target port id = 1 generation code = 3 number of phys = 1 phy identifier = 0 attached device type: SAS or SATA device attached reason: power on reason: unknown negotiated logical link rate: phy enabled; 6 Gbps attached initiator port: ssp=1 stp=1 smp=1 attached target port: ssp=0 stp=0 smp=0 SAS address = 0x5000cca2426feb41 attached SAS address = 0x500605b006585f70 attached phy identifier = 0 Invalid DWORD count = 4 Running disparity error count = 0 Loss of DWORD synchronization count = 1 Phy reset problem count = 0 relative target port id = 2 generation code = 3 number of phys = 1 phy identifier = 1 attached device type: no device attached attached reason: unknown reason: power on negotiated logical link rate: phy enabled; unknown attached initiator port: ssp=0 stp=0 smp=0 attached target port: ssp=0 stp=0 smp=0 SAS address = 0x5000cca2426feb42 attached SAS address = 0x0 attached phy identifier = 0 Invalid DWORD count = 0 Running disparity error count = 0 Loss of DWORD synchronization count = 0 Phy reset problem count = 0 hades-diagnostics-20231222-0844.zip
-
These are def not new drives. This one has the following: "Accumulated power on time, hours minutes 43712" I just buy used SAS drives to connect to my IT Flashed HBA. I have no problem waiting, its been on 2% for awhile now. I don't want to click around much in the GUI, but the Smart health status shows passed. After the test, I will double check to make sure the cable is good. I did have to disable the 3rd pin on this drive, where I added some tape to the pin. i will check to see if the percentage has increased any tomorrow.
-
So how long should I expect for it to take for the extended SMART test to take to finish on the 6TB drive? Also after the parity check, the read errors never incremented after the first set. and, should I close out this post and start a new one in the HD section, since it seems that my issue now is HD related?



