



abhi.ko
Members
-
Joined
-
Last visited
Everything posted by abhi.ko
-
RESOLVED. Root cause was a self-heal cron entry I'd added to /boot/config/plugins/dynamix/nextcloud.cron four days earlier — its OR-fallback (docker exec ... || mkdir -p /mnt/user/appdata/...) ran during boot when Docker wasn't up yet, polluting rootfs before shfs could mount. emhttpd then silently skipped shfs invocation as a safety measure. Removed the dangerous cron entry and shfs mounted cleanly on the next reboot. Lesson: any cron touching /mnt/user/ paths must guard against the boot-time race since crond starts before Docker. Had to dig through every change I made in the last 2-3 weeks one-by-one and try re-voting after removing each of them. Finally figured it out.
-
TL;DR: After upgrading 7.2.4 → 7.2.5 and rebooting (first reboot in ~3 weeks), emhttpd is silently skipping the shfs invocation during array start. /mnt/user is left as a rootfs stub with only the four hard-coded system stub directories (appdata, domains, isos, system). Failure persists across downgrade, Safe Mode, and stock-minimum boot. Underlying disk data is fully intact — every byte of every share is accessible via /mnt/disk1–/mnt/disk21 and /mnt/cache. This is purely a missing user-share namespace, not lost data. Below troubleshooting was done with the help of AI and from my knowledge of anything that was changed recently. Bug report is filed (link below), but I'm posting here separately because someone in the community may have hit this and have a fix. Server has been down for nearly a day, including Nextcloud sync (active dev work) and a Home Assistant VM (home automation). The forensic smoking gunIn a normal boot, emhttpd invokes shfs via an shcmd entry around shcmd 220–221, which mounts /mnt/user as fuse.shfs. Then services start. What I'm seeing instead, on every boot: shcmd (219): /usr/local/sbin/update_cron ← last pre-shfs cmd ← 13 seconds of silence, no log entries emhttpd: Starting services... ← services start anyway shcmd (221): chmod 0777 '/mnt/user/appdata' ← chmodding rootfs stubThe shcmd numbering shifts boot-to-boot based on optional steps, but the missing entry is always the shfs invocation. No error message. No failure message. No log entry of any kind during those 13 silent seconds. emhttpd proceeds to "Starting services" as if user shares were enabled, then runs chmod against the rootfs stub. Because shfs isn't running, when Docker/libvirt autostart they create fake docker.img (500GB sparse) and libvirt.img (1GB) in RAM at /mnt/user/system/... instead of pointing at the real images on cache. The real images on /mnt/cache/system/ are untouched and intact. Hardware / configUnraid 7.2.4 (originally 7.2.5, downgraded — failure mode identical) 21-disk XFS array, 2 parity, ~156TB Single 2TB Samsung 860 PRO XFS cache pool (no ZFS pools on this server) 21 legitimate shares: 4 system (appdata, domains, isos, system), 15 user-defined (Books, Movies, TV Shows, Music, etc.), 2 anomalous (8hszb7dd_rlib.cfg, lost+found.cfg) Plugins: ca.mover.tuning, dynamix.cache.dirs, unassigned.devices-plus, ca.backup, user.scripts, dockerMan, parity.check.tuning, fix.common.problems, recycle.bin, prometheus_node_exporter, tailscale, unbalanced, folderview.plus, dynamix.cron, nvidia-driver Things I've eliminated# Hypothesis Test Result 1 7.2.5 regression Tools → Downgrade OS to 7.2.4 Same failure on 7.2.4, but it started with the upgrade reboot 2 FUSE not loaded dmesg | grep fuse init (API version 7.41) — loaded fine 3 Plugin interference Boot in Safe Mode (all plugins disabled) Same failure 4 User Scripts race Disabled frequency=start script Same failure 5 Loose files at /mnt/cache root Quarantined 30 .md/.txt/.tsv files Same failure 6 shareUser="e" config corruption Compared to working backup; toggled in GUI "e" is correct/expected for "yes" in this version 7 Cache xattr support broken setfattr test on /mnt/cache xattr works fine 8 75 orphaned "Books deleted" ghost share configs Quarantined ghosts + 2 anomalous, leaving only 19 legitimate configs Same failure (ghosts were also in the working Apr 27 backup) 9 Flash config drift since last working state Diffed full /boot/config/ against Apr 27 backup zip Configs byte-identical for share.cfg, disk.cfg, pools/cache.cfg 10 Hardware fault SMART check, mount tests All disks healthy 11 Stale tmpfs / parity-check race (per [other forum thread]) Stopped Docker/libvirt, wiped /mnt/user to canonical empty nobody:users 0777, rebooted with no parity check running Same failure, identical 13-second silent gap 12 Custom /boot/config/go file (had ffmpeg symlinks under /mnt/user/appdata/) Replaced with absolute stock minimum (just /usr/local/sbin/emhttp), verified no rc.local, no plugin boot scripts anywhere Same failure What's intact (helpful for triage)Cache pool mounted, XFS healthy, all data present All 21 array disks mounted, XFS healthy, all data present Real docker.img and libvirt.img on cache untouched All Nextcloud and other appdata at /mnt/cache/appdata/ intact /boot/config/ configuration intact My askIf anyone has hit this exact symptom — emhttpd deterministically and silently skipping shfs invocation, with /mnt/user reduced to four stubs — I'd love to know: What was the eventual fix? Was there a specific file, setting, or state on the flash that triggered it? Is there a known-safe strace procedure on emhttpd during boot anyone can share? Bug report with full diagnostics: bug report - diagnostics on 7.2.5 and after rollback to 7.2.4 attached below as well. Happy to run any diagnostic the community suggests. Server is in a stable broken state — array up, all data accessible via disk shares, no risk of further damage. Thanks for reading this far. tower-diagnostics-20260501-1700.zip tower-diagnostics-Broken-725-Downgrade-20260501_0619.zip
-
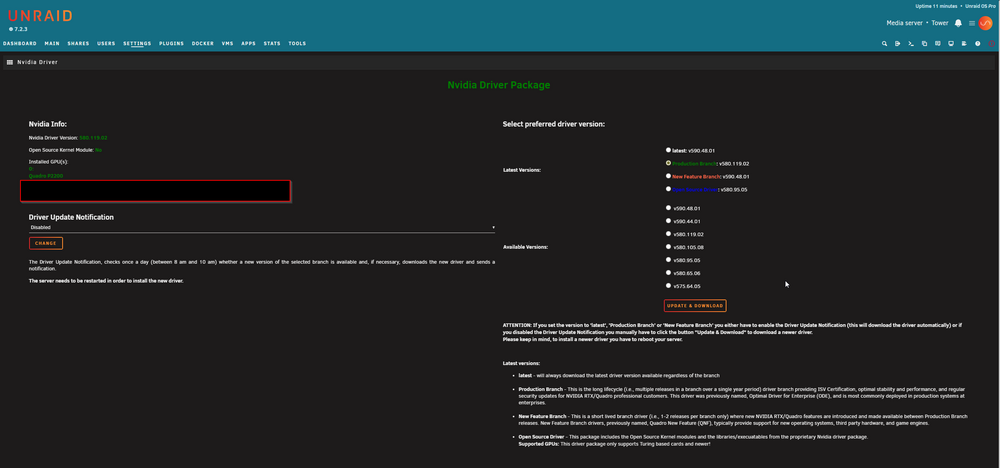
Thanks for the response. Had been travelling for the holidays - just got back to the server. I did not have those two line and I rolled back the driver and restarted and everything is good now. Screenshot below. Does this mean that I am stuck on version 580 until I change this card?
-
Hello - after a recent update to 7.2.3 (from 7.2.2) i started getting this error. Diagnostics attached. Can anyone help resolve this please? Nvidia Info: Nvidia Driver Version: 590.48.01 Open Source Kernel Module: No Installed GPU(s): NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. GPU does show up still in the system devices, but I do get a notification saying there was an error and asking me to install the driver manually. Nvidia Driver Dec 21, 09:01 AM NotificationFound new Nvidia Driver v590.48.01 but a download error occurred! Please try to download the driver manually! OMMU group 1: [10de:1c31] b3:00.0 VGA compatible controller: NVIDIA Corporation GP106GL [Quadro P2200] (rev a1) [10de:10f1] b3:00.1 Audio device: NVIDIA Corporation GP106 High Definition Audio Controller (rev a1) tower-diagnostics-20251221-1902.zip
-
Hello - after a recent update to 7.2.3 (from 7.2.2) i started getting this error. Can anyone help resolve this? Nvidia Info: Nvidia Driver Version: 590.48.01 Open Source Kernel Module: No Installed GPU(s): NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. GPU does show up still in the system devices, but I do get a notification saying there was an error and asking me to install the driver manually. Nvidia Driver Dec 21, 09:01 AM NotificationFound new Nvidia Driver v590.48.01 but a download error occurred! Please try to download the driver manually! OMMU group 1: [10de:1c31] b3:00.0 VGA compatible controller: NVIDIA Corporation GP106GL [Quadro P2200] (rev a1) [10de:10f1] b3:00.1 Audio device: NVIDIA Corporation GP106 High Definition Audio Controller (rev a1)
-
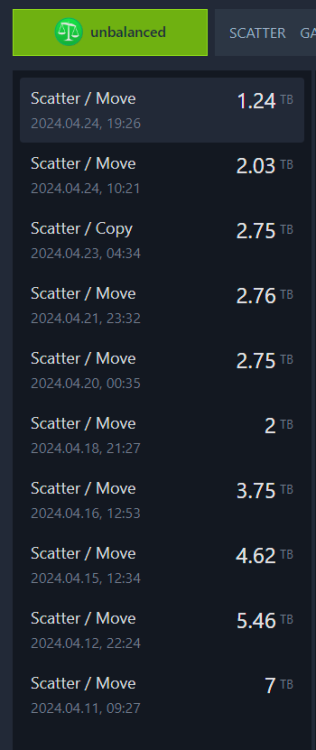
Finally all done. Left most of the docker apps running except for the ones that wrote to the disk, VM (HA) was never stopped. Used unbalanced to move. Took forever - started with the largest disk and worked my way down. Largest disk with 7TB of data to move took ~42hrs and the smallest with 1.2TB of data took 8 hrs. All disks are xfs now.
-
Thank You, just for learning purposes - what in the diagnostics file shows that SMART test passed for disk 9. I do have another disk - disk 1 with udma crc errors which I think might be related to cables or the controller.
-
It never completed I don't think. was stuck at 20% for over a day and then I refreshed the page, it shows a completed without error under Last SMART Test Result. tower-diagnostics-20240423-1903.zipNew diagnostics attached.
-
Thanks for taking a look, disabled spin down delay and just kicked an extended test off. Will report back once done.
-
Sorry here you go. tower-diagnostics-20240422-1235.
-
I woke up to a disk with read errors today. Here is what is on the disk smart error log: ATA Error Count: 1 CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 1 occurred at disk power-on lifetime: 58269 hours (2427 days + 21 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 41 00 00 00 00 00 Error: UNC at LBA = 0x00000000 = 0 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 60 00 00 f8 83 3f 40 00 16d+08:16:05.319 READ FPDMA QUEUED 60 00 00 f8 7f 3f 40 00 16d+08:16:02.537 READ FPDMA QUEUED 60 b8 00 40 7d 3f 40 00 16d+08:16:02.536 READ FPDMA QUEUED 60 d0 00 70 79 3f 40 00 16d+08:16:02.529 READ FPDMA QUEUED 60 00 00 70 75 3f 40 00 16d+08:16:02.528 READ FPDMA QUEUED Could someone please help me understand what this means? If this is critical enough to warrant a disk replacement. I recently had a lot of reads from and writes to this disk (and a few other ones) for converting FS from reiserfs to xfs. This disk was a reiserfs disk until last week, just converted it to xfs, I'm not sure if that is what caused this to have the error. All help is appreciated. I am basically trying to understand whether I'm risking the disk failing so, should be prepared with a replacement, or is there anything I should do to prevent these errors.
-
Thank you - appreciate the quick responses @Syco54645. If anyone else feels that I should not attempt this with the VM running please let me know - otherwise I plan to proceed with this plan.
-
Thank you. Edited steps to add the format disk step. My docker image & libvirt image, vm domains (vdisk location) and isos (boot iso's for VM's) are all cache primary and always on the cache disk and not on the array. As far as containers that write to the array yes I do have a few like Nextcloud (data location). I am okay with shutting docker off. Would it be okay to leave the VM running (just HA) while I do this. Also with not copying the content back to original disk - as per the docs this is a step, assume you did not do this in your original case was there any issues with shares and files etc.
-
Apologies for dusting up this old thread - but I am trying to change FS on multiple data disks from reiserfs to xfs. So, I believe the above steps should work for me, I just have to do them multiple times for each of the reiserfs disks. Is that accurate? Questions - Would I have to stop all dockers and VM's while doing this? Do I need to copy the contents of the disk back to the original disk after formatting it to xfs. If I don't, is there anything in config that i need to change? Steps to follow for multiple disks: Shutdown VM and docker From Disk 1 (reiserfs) move contents to empty disk 20 (xfs) Stop Array Change Disk 1 to xfs Restart array Format Disk 1 Repeat Steps 2-6 for next disk, until all are xfs Restart Docker and VM One of my VM's is Home Assistant - so this would mean that all the smart home related stuff will go down during this process, is there another way?
-
I am happy to - is there a beta plg file or something that I need to download? BTW - I removed the exclusions to /mnt/user/ and it ran without errors.
-
Can you share the script that i need to add to user scripts for this please?
-
Thanks for pointing that out.
-
Thank you for a taking a look. I am sure it is user error. The reason why I excluded that was in an effort to get rid of the Multi-mapping detected warning. It did not help, but any pointers on what I can do differently to avoid the warning and have the backup run without errors? Are these containers still backed up even though they failed verification since I am getting a Backup created without issues message right before the verification starts?
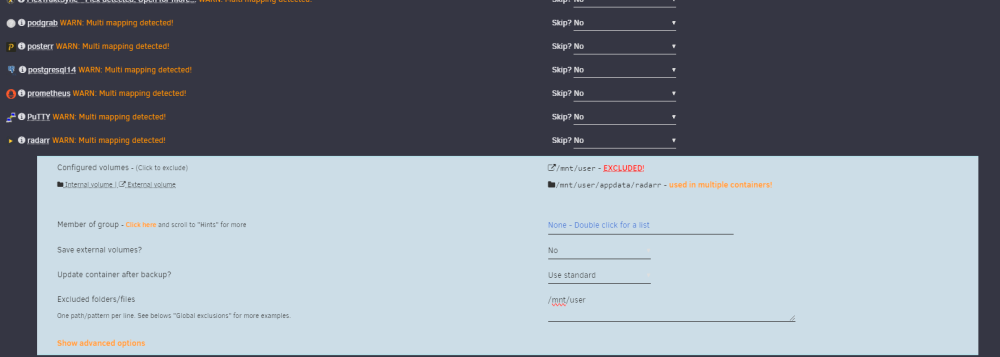
-
I'm getting a lot of tar verification failed errors in the log after my first run (switched from old plugin just last week). Some of the containers don't have the errors, but most of them do. Not sure what if anything I can do to resolve these? I am also confused about what the previous errors referred to in the due to previous errors statement is. Log snippet below: [04.03.2024 02:38:10][ℹ️][radarr] Stopping radarr... done! (took 4 seconds) [04.03.2024 02:38:14][ℹ️][radarr] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:38:14][ℹ️][radarr] Calculated volumes to back up: /mnt/user/appdata/radarr [04.03.2024 02:38:14][ℹ️][radarr] Backing up radarr... [04.03.2024 02:38:14][ℹ️][radarr] Backup created without issues [04.03.2024 02:38:14][ℹ️][radarr] Verifying backup... [04.03.2024 02:38:14][❌][radarr] tar verification failed! Tar said: tar: /mnt/user/appdata/radarr: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:38:29][ℹ️][radarr] Starting radarr... (try #1) done! [04.03.2024 02:38:31][ℹ️][Plex-Media-Server] Stopping Plex-Media-Server... done! (took 7 seconds) [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] '/mnt/user/appdata/Plex-Media-Server/Transcode' is within mapped volume '/mnt/user/appdata/Plex-Media-Server'! Ignoring! [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Calculated volumes to back up: /mnt/user/appdata/Plex-Media-Server [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Backing up Plex-Media-Server... [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Backup created without issues [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Verifying backup... [04.03.2024 02:38:38][❌][Plex-Media-Server] tar verification failed! Tar said: tar: /mnt/user/appdata/Plex-Media-Server: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:47:16][ℹ️][Plex-Media-Server] Starting Plex-Media-Server... (try #1) done! [04.03.2024 02:47:19][ℹ️][nzbget] Stopping nzbget... done! (took 5 seconds) [04.03.2024 02:47:24][ℹ️][nzbget] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:47:24][ℹ️][nzbget] Calculated volumes to back up: /mnt/user/appdata/nzbget [04.03.2024 02:47:24][ℹ️][nzbget] Backing up nzbget... [04.03.2024 02:47:24][ℹ️][nzbget] Backup created without issues [04.03.2024 02:47:24][ℹ️][nzbget] Verifying backup... [04.03.2024 02:47:24][❌][nzbget] tar verification failed! Tar said: tar: /mnt/user/appdata/nzbget: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:47:28][ℹ️][nzbget] Starting nzbget... (try #1) done! [04.03.2024 02:47:30][ℹ️][sabnzbd] Stopping sabnzbd... done! (took 4 seconds) [04.03.2024 02:47:34][ℹ️][sabnzbd] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:47:34][ℹ️][sabnzbd] Calculated volumes to back up: /mnt/user/appdata/sabnzbd/config [04.03.2024 02:47:34][ℹ️][sabnzbd] Backing up sabnzbd... [04.03.2024 02:47:34][ℹ️][sabnzbd] Backup created without issues [04.03.2024 02:47:34][ℹ️][sabnzbd] Verifying backup... [04.03.2024 02:47:34][❌][sabnzbd] tar verification failed! Tar said: tar: /mnt/user/appdata/sabnzbd/config: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:47:38][ℹ️][sabnzbd] Starting sabnzbd... (try #1) done! ... ... ... [04.03.2024 04:04:11][ℹ️][Main] Backing up the flash drive. [04.03.2024 04:05:23][ℹ️][Main] Flash backup created! [04.03.2024 04:05:23][ℹ️][Main] Copying the flash backup to '/mnt/user/Other Media/unRAID/Flash Backup/' as well... [04.03.2024 04:05:28][ℹ️][Main] VM meta backup enabled! Backing up... [04.03.2024 04:05:28][ℹ️][Main] Done! [04.03.2024 04:05:28][⚠️][Main] An error occurred during backup! RETENTION WILL NOT BE CHECKED! Please review the log. If you need further assistance, ask in the support forum. [04.03.2024 04:05:28][ℹ️][Main] DONE! Thanks for using this plugin and have a safe day ;) [04.03.2024 04:05:28][ℹ️][Main] ❤️ Here is the debug log id for a more recent manually triggered backup with same errors but different timestamps - f73d93f6-bece-4fe4-97b6-8477b9440833
-
I'm getting a lot of tar verification failed errors in the log after my first run (switched from old plugin just last week). Some of the containers don't have the errors, but most of them do. Not sure what if anything I can do to resolve these? I am also confused about what the previous errors referred to in the due to previous errors statement is. Log snippet below: [04.03.2024 02:38:10][ℹ️][radarr] Stopping radarr... done! (took 4 seconds) [04.03.2024 02:38:14][ℹ️][radarr] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:38:14][ℹ️][radarr] Calculated volumes to back up: /mnt/user/appdata/radarr [04.03.2024 02:38:14][ℹ️][radarr] Backing up radarr... [04.03.2024 02:38:14][ℹ️][radarr] Backup created without issues [04.03.2024 02:38:14][ℹ️][radarr] Verifying backup... [04.03.2024 02:38:14][❌][radarr] tar verification failed! Tar said: tar: /mnt/user/appdata/radarr: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:38:29][ℹ️][radarr] Starting radarr... (try #1) done! [04.03.2024 02:38:31][ℹ️][Plex-Media-Server] Stopping Plex-Media-Server... done! (took 7 seconds) [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] '/mnt/user/appdata/Plex-Media-Server/Transcode' is within mapped volume '/mnt/user/appdata/Plex-Media-Server'! Ignoring! [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Calculated volumes to back up: /mnt/user/appdata/Plex-Media-Server [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Backing up Plex-Media-Server... [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Backup created without issues [04.03.2024 02:38:38][ℹ️][Plex-Media-Server] Verifying backup... [04.03.2024 02:38:38][❌][Plex-Media-Server] tar verification failed! Tar said: tar: /mnt/user/appdata/Plex-Media-Server: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:47:16][ℹ️][Plex-Media-Server] Starting Plex-Media-Server... (try #1) done! [04.03.2024 02:47:19][ℹ️][nzbget] Stopping nzbget... done! (took 5 seconds) [04.03.2024 02:47:24][ℹ️][nzbget] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:47:24][ℹ️][nzbget] Calculated volumes to back up: /mnt/user/appdata/nzbget [04.03.2024 02:47:24][ℹ️][nzbget] Backing up nzbget... [04.03.2024 02:47:24][ℹ️][nzbget] Backup created without issues [04.03.2024 02:47:24][ℹ️][nzbget] Verifying backup... [04.03.2024 02:47:24][❌][nzbget] tar verification failed! Tar said: tar: /mnt/user/appdata/nzbget: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:47:28][ℹ️][nzbget] Starting nzbget... (try #1) done! [04.03.2024 02:47:30][ℹ️][sabnzbd] Stopping sabnzbd... done! (took 4 seconds) [04.03.2024 02:47:34][ℹ️][sabnzbd] Should NOT backup external volumes, sanitizing them... [04.03.2024 02:47:34][ℹ️][sabnzbd] Calculated volumes to back up: /mnt/user/appdata/sabnzbd/config [04.03.2024 02:47:34][ℹ️][sabnzbd] Backing up sabnzbd... [04.03.2024 02:47:34][ℹ️][sabnzbd] Backup created without issues [04.03.2024 02:47:34][ℹ️][sabnzbd] Verifying backup... [04.03.2024 02:47:34][❌][sabnzbd] tar verification failed! Tar said: tar: /mnt/user/appdata/sabnzbd/config: Not found in archive; tar: Exiting with failure status due to previous errors [04.03.2024 02:47:38][ℹ️][sabnzbd] Starting sabnzbd... (try #1) done! ... ... ... [04.03.2024 04:04:11][ℹ️][Main] Backing up the flash drive. [04.03.2024 04:05:23][ℹ️][Main] Flash backup created! [04.03.2024 04:05:23][ℹ️][Main] Copying the flash backup to '/mnt/user/Other Media/unRAID/Flash Backup/' as well... [04.03.2024 04:05:28][ℹ️][Main] VM meta backup enabled! Backing up... [04.03.2024 04:05:28][ℹ️][Main] Done! [04.03.2024 04:05:28][⚠️][Main] An error occurred during backup! RETENTION WILL NOT BE CHECKED! Please review the log. If you need further assistance, ask in the support forum. [04.03.2024 04:05:28][ℹ️][Main] DONE! Thanks for using this plugin and have a safe day ;) [04.03.2024 04:05:28][ℹ️][Main] ❤️
-
Yes tried both with no luck, stuck in boot loop for non-UEFI mode (folder name in the manual install left as EFI-) as well.
-
Updated my BIOS to the latest available version for my MB and tried upgrading to 6.12.3 and still has the same issue. Stuck in a boot loop, getting to bzroot loading - gets an OK pretty quickly and then reboots. Tried with a stock UNRAID trial version of 6.12.3 on a different USB (manual install method used) and had the same result. So issue still exists. So I am unable to update to versions higher than 6.11.5, which is disappointing and frustrating as more time passes and newer versions come out but this issue still remains unsolved. @limetech is there any work being done to identify what is causing the issue for all these systems and to fix it? Happy to provide diagnostics or anything else that you guys might need.
-
UnRaid experts - any updates on this hardware compatibility issue (based on my troubleshooting). It doesn't seem isolated to one machine and seems to impact a good number of users. Any and all help appreciated. I'm still on 11.5 and I see that 12.2 is out now.
-
Are there any know hardware computability issues with the Linux kernel in 6.12?
-
USB creator did not work for me always. It was hit or miss. Just got stuck midway most of the time but completed a few times. So I have been using the manual install method and followed the same instructions. The flash drive is Bootable (I think) since it gets to the screen with the boot options, but when it tries to load bzroot it fails, is my limited understanding. Happy to try something else.



