

AndrewT
-
Posts
123 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by AndrewT
-
-
Fractal XL like this one has sound deadening for quiet, and if you still aren't happy, swap the fans with some noctua ones like these. I used to have this in my living room and was dead silent with the stock fans.
If you also replace 3 of those 5.25-inch drive bays with a 4-in-3 drive bay like this, you'll be able to store (12) 3.5" HDDs in the case. If that's still not enough disks, here is a way to get 20 disks with that case + 4 more with the 4-in-3 above. The case isn't cheap but it's by far the best I ever had.
-
I lose access to my server once a parity check begins, and when it finishes it remains completely inaccessible. Telnet, WebGUI, network file browsing, docker containers (MariaDB, AirSonic, NZBGet, etc) all fail to connect. USB connected keyboard doesn't respond (plugged it prior to startup) even 1 day after parity completed without error. I never received a parity completion email either, but other smaller and weaker unraid servers do both start and finish emails.
This has been happening for a few months, so I attached a monitor in the rack before server startup to view any screen output, but nothing I think useful is shown (pic attached). It only shows initial startup info and nothing after that. It printed log info when I did a quick power button push to safely shutdown the server. Syslog and Diagnostics are attached from that.
Line 3886 in file 'logs/syslog.1.txt' is where the parity_check was initiated. The log later lists docker containers that have new updates available. That makes me think the system should have then at least had docker containers accessible but none were. Any ideas what could be causing this issue and how to resolve??
- Parity summary: 1 day, 13 hr, 32 min, 23 sec @ 59.2 MB/s found 0 errors.
- Disk summary: 16 data (8 TB ea), 2 parity, 1 SSD cache for apps and a symlinked dir to a 2-disk RAID0 btrfs (striped) auto-mounted unassigned devices purely as a tmp downloads pool.
-
System summary: unRAID v6.6.6 Pro, AMD 8-Core @ 3.2 GHz, 32 GB RAM, 2 * LSI SAS9201-8i
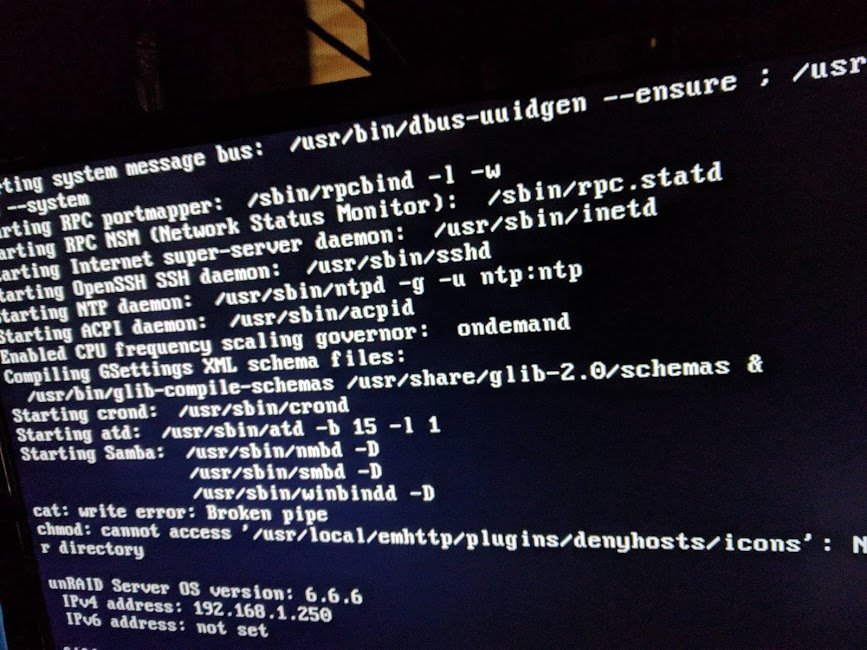
-
Thanks, @binhex! I was going through this long discussion where `mono` was described as a potential issue. Later some indicated a proxy nginx config in NZBGet may have been the issue, being unable to pass long content, with a solution here, but I didn't go on to look into that much yet. I am using the Privoxy (port 8118) connection (using binhex-delugevpn), but I don't think that's related to the reverse proxy nginx issue, so it seemed mono was the only thing to test.
I haven't used SAB since unraid5 days of Influencer, but I may need to try to move back to that if NZBGet is perhaps the issue rather than Radarr/Sonarr? I'm open to other suggestions you may have.
-
Radarr (and Sonarr) lately has been having problems connecting to NZBGet to grab completed downloads. It passes NZB files to it just fine. The settings/downloadclient "Test" connection shows "Testing NZBGet completed". Radarr also connects to Deluge and no errors are logged. I'm using all up-to-date binhex containers. Restarting containers doesn't help despite this being suggested above.
The specific message I see is "Unable to connect to NZBGet. HTTP request failed: [502:BadGateway] at [http://<My_IP>:6789/jsonrpc]" where <My_IP> is the static IP address to the server. From what I've read some suggest it's a `mono` issue in the radarr container, but maybe this is wasted effort to upgrade mono and there's a different solution.
(1) Why doesn't mono 5.16.0.220-1 get listed (Last Updated: 2018-12-18 according to https://www.archlinux.org/packages/extra/x86_64/mono/ ) ?
docker exec -it binhex-radarr bash pacman -Syy && pacman -Ss mono # lists extra/mono 5.12.0.260-1 [installed]
(2) Does this mean when mono was built it was corrupt?pacman -S mono warning: mono-5.12.0.260-1 is up to date -- reinstalling resolving dependencies... looking for conflicting packages... Packages (1) mono-5.12.0.260-1 Total Installed Size: 233.17 MiB Net Upgrade Size: 0.00 MiB :: Proceed with installation? [Y/n] Y (1/1) checking keys in keyring [###################################] 100% (1/1) checking package integrity [###################################] 100% error: mono: signature from "Levente Polyak (anthraxx) <levente@leventepolyak.net>" is unknown trust :: File /var/cache/pacman/pkg/mono-5.12.0.260-1-x86_64.pkg.tar.xz is corrupted (invalid or corrupted package (PGP signature)). Do you want to delete it? [Y/n] n error: failed to commit transaction (invalid or corrupted package (PGP signature)) Errors occurred, no packages were upgraded.
-
Wow, thanks! That installed it quickly and is very useful.
-
@binhex Could `mediainfo` be added to the install here: https://github.com/binhex/arch-radarr/blob/master/build/root/install.sh#L22 ? The radarr devs continue suggesting its use to debug issues of errors handling completed downloads with messages containing "has a runtime of 0, is it a valid video file?"
When I perform `ls -lh <movie>` it returns reasonable sizes, so I'm trying to now test if mediainfo calls within radarr is just having an issue. All mkv and mp4 tested play on VLC Player as well.
-
9 hours ago, bonienl said:
On the same page it is clearly explained what the limitations are.
Thanks!
-
https://unraid.net/pricing currently indicates the Pro license has "Unlimited attached storage devices" which I find a bit deceptive if there truly is a hard limit.
When I took my array off-line, I see I can go up to 30 slots in the array section, but I'm unsure if the cache disks count against that 30 disk maximum and whether parity disks count against the 30 too.
-
I never knew the XML files were on the flash drive! I cleaned those up, removing old ones I'll never use again. The new username and password were saved in there as expected.
The docker image file was the culprit. OP perfectly explained how to do it, and not too scary even for 16 containers. Seeing all the custom config info saved on the flash drive helped before deleting the img file. Thanks for the help!
-
 1
1
-
-
7 hours ago, binhex said:
If by docker XML GUI editor you mean NOT left clicking the icon and selecting edit and changing the cred values then you are doing it wrong.
@binhex that's what I did to change the username and password. Left click icon -> "Edit" -> change "Key 2" (VPN_USER) and "Key 3" (VPN_PASS) -> "Save". The new username and password are retained there and don't change when I start the container. Each time I try to start the docker container, it immediately changes the binhex-delugevpn/openvpn/credentials.conf file to the old username and password, so of course it returns a can't connect error. Just changing Key 2 and Key 3 doesn't work, so I'm curious where else the user and password are saved? It looks like when the container starts, the 'credentials.conf' file is overwritten with a user/pass saved from somewhere but I can't find where it's pulling that information from.
This was before starting the Docker container (at 12:43):
ls -lh /mnt/cache/appdata/binhex-delugevpn/openvpn/credentials.conf
-rwxrwxr-x 1 nobody users 20 Jul 1 02:11 /mnt/cache/appdata/binhex-delugevpn/openvpn/credentials.confThis was after starting the Docker container (at 12:43):
ls -lh /mnt/cache/appdata/binhex-delugevpn/openvpn/credentials.conf
-rwxrwxr-x 1 nobody users 20 Jul 1 12:43 /mnt/cache/appdata/binhex-delugevpn/openvpn/credentials.confAttached is the logfile. Before starting, I've also `find /mnt/cache/appdata/binhex-delugevpn -type f -maxdepth 3 -exec grep -H Old_Username {} \;` and only find it listed in the supervisord.log before starting the container, and of course after the container starts and I see the file modified, it shows up in the credentials.conf file.
Removing the credentials.conf file and starting the container also generates the credentials.conf file with the old username and password. I'm looking for something simple like `cat FILE_WITH_OLD-USER-PASS.txt > credentials.conf` but don't see anything like it here https://github.com/binhex/arch-delugevpn/search?q=credentials.conf&type=Code
-
I just got a new username and password from PIA. I changed the two fields in the Docker XML GUI editor (https://TOWER/Docker/UpdateContainer?xmlTemplate=edit:/boot/config/plugins/dockerMan/templates-user/my-binhex-delugevpn.xml), clicked "Save", and noticed it didn't change the 'binhex-delugevpn/openvpn/credentials.conf', so I changed that as well. Going back to that XML I see the new username and password are saved. When I clicked to start the Docker container, I saw in the log "SIGTERM[soft,auth-failure] received, process exiting" and when I `cat credentials.conf` I noticed the old user and password are shown(!) So, it seems somehow the old user and password are still saved somewhere, and each time I start the container (I've tried it 3Xs now) it overwrites the credentials.conf file but leaves the Docker XML alone so the new user/password remains in the Docker XML.
Is there anywhere else I should change the user and password?
-
Thanks @johnnie.black! I'm using Chrome Version 63.0.3239.132 (Official Build) (64-bit) on a vanilla Ubuntu 18.04 OS and have entries saved, so I see the space wasn't lacking in my cmd in the WebGUI. I edited my original post to avoid another person copy/pasting the wrong cmd. There might be an issue with my browser/OS still, because copy/pasting cmds with "code" formatting in this forum doesn't work despite no unusual formatting appearing when I put it into Sublime Text first. For example, the two cmds @John_M print usage errors and the text is clearly correct.
When copy/pasting this happens:
btrfs fi usage /mnt/cache btrfs filesystem: unknown token 'usage'But when typing the cmd manually it works as expected:
btrfs fi usage /mnt/cache Overall: Device size: 9.10TiB Device allocated: 2.04TiB Device unallocated: 7.05TiB Device missing: 0.00B Used: 2.04TiB Free (estimated): 7.06TiB (min: 3.53TiB) Data ratio: 1.00 Metadata ratio: 2.00 Global reserve: 512.00MiB (used: 0.00B) Data,RAID0: Size:2.03TiB, Used:2.03TiB /dev/sdn1 1.02TiB /dev/sdo1 1.02TiB Metadata,RAID1: Size:5.00GiB, Used:3.78GiB /dev/sdn1 5.00GiB /dev/sdo1 5.00GiB System,RAID1: Size:32.00MiB, Used:176.00KiB /dev/sdn1 32.00MiB /dev/sdo1 32.00MiB Unallocated: /dev/sdn1 3.53TiB /dev/sdo1 3.53TiBI prefer terminal over the WebGUi so I'm thankful you gave the full command to execute. This cmd worked as expected (within screen) to convert the Cache pool from RAID1 to RAID0, so I'll mark this [Solved]:
btrfs balance start -dconvert=raid0 -mconvert=raid1 /mnt/cache -
Wow, that might've worked! Immediately after entering that into terminal, the WebGUI had a orange menu pop up indicating
unRAID Cache disk message: 05-05-2018 11:16Warning [TOWER] - Cache pool BTRFS too many profiles
WDC_WD5001FZWX-00ZHUA0_WD-WXA1D6542HUS (sdn)This warning almost seems indicative of RAID conversion activity
")
After 5 min, nothing yet has printed to stdout or stderr, but I can see the command still running with `htop` and both disks in the Main WebGUI show active read/write speeds (170 ~MB/s max). I'll update as solved after it completes which could take awhile for 2x5TB disks, but that's odd it didn't work in the WebGUI.
-
My issue sounds the same as a recent post here, but the solutions didn't work. The command recommended in the FAQ
-dconvert=raid0 -mconvert=raid1
looks to issue the command properly in the syslog but does nothing. No errors are printed in the syslog or in the WebGUI. I restarted the server, re-issued the command, and still no conversion.
my btrfs balance status:
Data, single: total=1.95TiB, used=1 .94TiB System, single: total=32.00MiB, used=240.00KiB Metadata,g single: total=5.00GiB, used=3.69GiB GlobalReserve, single: total=512.00MiB, used=0.00B
No balance found on '/mnt/cache'
There were no errors after a btrfs scrub:
scrub status for 5bc529a5-e3b4-4eec-9c77-265b61962b61 scrub started at Thu May 3 23:56:56 2018 and finished after 09:18:32 total bytes scrubbed: 1.94TiB with 0 errors
My 2-disk (5 TB WD Black Caviar each) RAID1 pool is <25% full after deleting 2.5TB of incomplete downloads. The other suggestion in that post was to update the OS, which I have v6.5.1.
A command suggested to get allocated space of the cache pool here:
btrfs fi usage /mnt/cacheprints
Overall: Device size: 9.10TiB Device allocated: 1.95TiB Device unallocated: 7.15TiB Device missing: 0.00B Used: 1.95TiB Free (estimated): 7.15TiB (min: 7.15TiB) Data ratio: 1.00 Metadata ratio: 1.00 Global reserve: 512.00MiB (used: 0.00B) Data,single: Size:1.95TiB, Used:1.94TiB /dev/sdn1 998.00GiB /dev/sdo1 994.00GiB Metadata,single: Size:5.00GiB, Used:3.69GiB /dev/sdn1 1.00GiB /dev/sdo1 4.00GiB System,single: Size:32.00MiB, Used:240.00KiB /dev/sdo1 32.00MiB Unallocated: /dev/sdn1 3.57TiB /dev/sdo1 3.57TiBwhich makes me think my newly-created RAID1 cache pool is acting as a cache pool. I only want a pool for performance, so I'm hoping to get it setup for RAID0. I've also never seen the warning "Cache pool BTRFS too many profiles" that's been said as normal to see.
-
I've had issues deleting items in Deluge, whether it's a few or many (80-100s). When I select all, right click "Remove Torrent" and select "Remove With Data", I've never got a rapid response. The menu stays up, and clicking a second or third time still doesn't remove the menu. Often a few seconds later, I get a weird "The connection to the webserver has been lost!" and get kicked out of the webserver. When I go back in a few seconds later the files are usually removed. I don't think this an issue unique to binhex's version, but what are others doing to cleanup occasionally? Maybe skip the webserver connection to delete files?
I don't expect Deluge to be changed to resolve this anytime soon, and modifications inside the docker container seem to put unnecessary request/burden on Binhex, so does anyone have a simple script to list all those that are status "Queued" and Progress=100% ? An 8 year old example I found here depends on deluge python modules which means it would be a long one-liner to go in and out of the container:
docker exec -ti binhex-delugevpn bash && python2.7 /mounted-array/.bin/script.py && exitI'm a bit nervous to try the script, but inside the python2.7 interpreter, all 5 lines of module imports work successfully.
-
@dmacias thanks for the addition.
Now with jq, it's easy to cleanup the movies list when it get too large from "Lists" adding too many. The HOST and API_KEY vars have to be assigned.
#!/bin/sh HOST=http://serverIPaddress:7878 #Radarr port default is 7878 API_KEY=32charString #Radarr > Settings > General ids=$(curl --silent $HOST/api/movie -X GET -H "X-Api-Key: $API_KEY" \ | jq '.[] | select(.monitored == true) | .id') for id in $ids; do echo "Deleting movie id $id" curl --silent $HOST/api/movie/$id -X DELETE -H "X-Api-Key: $API_KEY" done
Also, to batch cleanup all downloaded from Raddar, .monitored == true can be replaced with .downloaded == true with the same script using the `jq` binary.
-
Could `jq` be considered to add as an install option in the Nerd Tools pack? https://stedolan.github.io/jq/
It's a simple JSON parsing binary and an example use case for it is to mass remove movies from Radarr. I tried using some of the lists in Radarr and it added far too many movies, so I'd like to wipe them clean but would take a lot of effort to just wipe the Radarr Docker and reconfig everything. The shell script that uses `jq` is here: https://gist.github.com/pstadler/bc0afefe35f608e9552e764b31f45f19
-
Thanks! It's especially useful to know the parity numbered disks do matter.
The config/super.dat is a binary file... no wonder grep -e 'WDC_' -e 'HGST_' -e 'ST4000' didn't work anywhere in the flash that I looked
edit: After each server was shutdown, moving the super.dat files between the server flash drives worked well. After booting up (autostart array turned off on both), it allowed me to change the cache disks before starting the array.
-
I have two unraid servers but one holds half the disks/slots, so I need to physically swap the array disks. I'd like to keep my cache and usb drives where they are. I can't backup my array data until this is done, so I just wanted to make sure I fully understand the process.
Johnnie Black had a recent post that helps but just want clarity from this, because I can't see what options I have after clearing the disk config until I do so:
1) For each server, save the info listed in the webGUI's Main of "Device" and "Identification" mappings.
2) Use the webGUI's Tools -> "New Config" for each server, which wipes the flash drive's memory of which disks are parity, cache, and array. Where is the file stored by default?
3) Power down both servers
4) physically swap the array disks only
5) power back up and boot into unraid
6) now in the "Main" section there will be drop-down menus for each disk to add, so add according to the saved list (keeping the current cache and flash drives as-is)
7) an option before starting the array on the Main will have a check box to say "Parity is already valid" so check that
8.) run full parity check with write errors to parity disks for both servers
9) if few to no errors, then start using arrays
Steps 6 and 7 I'm most worried about, because I remember seeing that check box option for parity already valid in unraid5 but don't remember seeing it in unraid6.
Does the disk # matter for parity disks (I have dual) or for array disks?
-
Since your secondary (backup) server is at a different location, that makes me wonder if it's usually powered off? If so, you might find it easiest to just create a cron job to execute a simple shell script that involves wakeonlan and rsync.
For now, I open a `screen -S share_name` and rsync one share, open another screen and do a second share. I've asked for guidance on the best rsync options to use but didn't seem to get much of an answer, perhaps because it might be more tailored to each person's needs. For example, how you handle symbolic links.
This is what I use once in screen on the primary (newer server) to backup `rsync --verbose --human-readable --recursive --update --copy-links --copy-dirlinks --times --perms --xattrs --owner --group --devices --specials --prune-empty-dirs --stats --log-file=/mnt/cache/rsync-logfile-ArrayTV.txt /mnt/user/TV/* root@<Backup_Server_IP>:/mnt/user/TV`
-
If you don't want a command line program, check out https://mediacompanion.codeplex.com/ I use it for TV Shows and Movies. It unify your collection with renaming, fetch art/metadata, even trailers.
-
After restarting the server I can now telnet in.
-
I have two unraid boxes with the same OS 6 version. On one, I am able to `telnet <IP-address>` then enter root as user and a password I have saved from the WebGUI address <IP>/Users/UserEdit?name=root but the other server I'm unable to do the same. On both, I am able to access the WebGUI just fine with my password.
I also tried re-entering my password in the WebGui for the server I can't telnet into, clicked "Change", then "Done" but still am unable to telnet into the system.
What could be wrong?
-
Gosh, sorry, yes `dd if=/dev/sdo of=/dev/sdk bs=4k conv=noerror,sync status=progress` is working as expected to copy the disk. If it finishes without error, do I then pull out the sdo drive off the "Disk 4" slot on the array and re-start the array with sdk in place?


Combine 2 physical servers
in Lounge
Posted
Yes you can combine 2 physical servers with storage disks in each. You need SAS cables (not USB3) for faster data speeds.
This is the approach I took to combine two 4U servers. Only 1 has a traditional mobo, CPU, RAM, etc but both have independent power supplies for the disks connected in each:
https://www.servethehome.com/sas-expanders-build-jbod-das-enclosure-save-iteration-2/