

christopher2007
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by christopher2007
-
Hi there, I noticed that my partition `/run` is full: # df -h Filesystem Size Used Avail Use% Mounted on rootfs 16G 2.9G 13G 19% / tmpfs 32M 32M 40K 100% /run /dev/sda1 29G 1.1G 28G 4% /boot overlay 16G 2.9G 13G 19% /lib/firmware overlay 16G 2.9G 13G 19% /lib/modules devtmpfs 8.0M 0 8.0M 0% /dev tmpfs 16G 0 16G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 8.2M 120M 7% /var/log tmpfs 1.0M 0 1.0M 0% /mnt/disks tmpfs 1.0M 0 1.0M 0% /mnt/remotes tmpfs 1.0M 0 1.0M 0% /mnt/rootshare [... array disks, caches and unassigned devices] /dev/loop2 1.0G 4.8M 904M 1% /etc/libvirt tmpfs 3.2G 0 3.2G 0% /run/user/0 After inspection with `ncdu` command, I found the following file with 30.9 MiB filling almost all of `/run`: /run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/3ae06a993a7d6ea7a8899040990a24182fd279c0331b0776b17d9807a000fa98/log.json This file is bloated with almost identical lines like so: {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:16:53+01:00"} {"level":"info","msg":"Using OCI specification file path: /var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/3ae06a993a7d6ea7a8899040990a24182fd279c0331b0776b17d9807a000fa98/config.json","time":"2023-02-06T01:16:53+01:00"} {"level":"info","msg":"Auto-detected mode as 'legacy'","time":"2023-02-06T01:16:53+01:00"} {"level":"info","msg":"Using prestart hook path: /usr/bin/nvidia-container-runtime-hook","time":"2023-02-06T01:16:53+01:00"} {"level":"info","msg":"Applied required modification to OCI specification","time":"2023-02-06T01:16:53+01:00"} {"level":"info","msg":"Forwarding command to runtime","time":"2023-02-06T01:16:53+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:16:53+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:16:58+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:04+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:09+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:14+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:19+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:24+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:29+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:34+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:39+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:44+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:49+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:54+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:17:59+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:18:04+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:18:09+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:18:15+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:18:20+01:00"} {"level":"info","msg":"Using low-level runtime /usr/bin/runc","time":"2023-02-06T01:18:25+01:00"} [... Repeating the info line every five minutes !!!] In the path a docker id is provided and also the config path inside the log file contains the same docker id. This docker id on my system is `Plex-Media-Server` from the repository `plexinc/pms-docker`. Stopping and restarting Plex clears `/run` but starts the log flushing all over again. So it is no solution to restart Plex manually all several days. The log lines shown above that floats the `/run` partition are not the same shown when I click on `Logs` in the UNRAID GUI. So I have the following questions: How can I decrease the log level or the intensity of the Docker container Plex so that it will not write the same level `info` log every five minutes? I found this post that helps limit the log output to 50MB, but the `/run` is 32MB max space, so I guess the logs described here go to another place than `/run`. Maybe this is for the `Logs` when using the UNRAID GUI. Can I, besides of question 1, set the space for `/run` bigger? 32MB seems a little small and 50MB or 100MB would be nicer, I guess. I found this post that tells me how to increase `/run` on Ubuntu but the UNRAID (slackware) seems to have another construction for that folder. Or am I wrong? Thanks for your help in advance.
-
This shows the same output as System Devices in UnRAID: 00:1c.4 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port #5 (rev f0) So no new infos.
-
Lately I get the following error in the System Log from time to time (every other day): Jan 6 12:50:25 <name> kernel: pcieport 0000:00:1c.4: AER: Corrected error received: 0000:00:1c.4 Jan 6 12:50:25 <name> kernel: pcieport 0000:00:1c.4: PCIe Bus Error: severity=Corrected, type=Data Link Layer, (Transmitter ID) Jan 6 12:50:25 <name> kernel: pcieport 0000:00:1c.4: device [8086:a33c] error status/mask=00001000/00002000 Jan 6 12:50:25 <name> kernel: pcieport 0000:00:1c.4: [12] Timeout (The first three lines are red = ERROR, the last line is black = TEXT) In order to fix it I did some research and among other things I found this topic: Unfortunately none of the found topics helped me. In order to investigate my problem more, I wonder what PCI device is behind `00:1c.4`. Therefore the following: In the System Devices: IOMMU group 8:[8086:a33c] 00:1c.4 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port #5 (rev f0) In `lspci -vv` (only the entry for `00:1c.4`, not everything from the output): 00:1c.4 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port #5 (rev f0) (prog-if 00 [Normal decode]) Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 125 Bus: primary=00, secondary=04, subordinate=04, sec-latency=0 I/O behind bridge: None Memory behind bridge: a4400000-a48fffff [size=5M] Prefetchable memory behind bridge: None Secondary status: 66MHz- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort+ <SERR- <PERR- BridgeCtl: Parity- SERR- NoISA- VGA- VGA16+ MAbort- >Reset- FastB2B- PriDiscTmr- SecDiscTmr- DiscTmrStat- DiscTmrSERREn- Capabilities: [40] Express (v2) Root Port (Slot+), MSI 00 DevCap: MaxPayload 256 bytes, PhantFunc 0 ExtTag- RBE+ DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq+ RlxdOrd- ExtTag- PhantFunc- AuxPwr- NoSnoop- MaxPayload 256 bytes, MaxReadReq 128 bytes DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr+ TransPend- LnkCap: Port #5, Speed 8GT/s, Width x4, ASPM not supported ClockPM- Surprise- LLActRep+ BwNot+ ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes Disabled- CommClk+ ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt- LnkSta: Speed 8GT/s (ok), Width x4 (ok) TrErr- Train- SlotClk+ DLActive+ BWMgmt+ ABWMgmt- SltCap: AttnBtn- PwrCtrl- MRL- AttnInd- PwrInd- HotPlug- Surprise- Slot #8, PowerLimit 25.000W; Interlock- NoCompl+ SltCtl: Enable: AttnBtn- PwrFlt- MRL- PresDet- CmdCplt- HPIrq- LinkChg- Control: AttnInd Unknown, PwrInd Unknown, Power- Interlock- SltSta: Status: AttnBtn- PowerFlt- MRL- CmdCplt- PresDet+ Interlock- Changed: MRL- PresDet- LinkState+ RootCtl: ErrCorrectable- ErrNon-Fatal- ErrFatal- PMEIntEna- CRSVisible- RootCap: CRSVisible- RootSta: PME ReqID 0000, PMEStatus- PMEPending- DevCap2: Completion Timeout: Range ABC, TimeoutDis+, LTR+, OBFF Not Supported ARIFwd+ AtomicOpsCap: Routing- 32bit- 64bit- 128bitCAS- DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis-, LTR+, OBFF Disabled ARIFwd- AtomicOpsCtl: ReqEn- EgressBlck- LnkCtl2: Target Link Speed: 8GT/s, EnterCompliance- SpeedDis- Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS- Compliance De-emphasis: -6dB LnkSta2: Current De-emphasis Level: -3.5dB, EqualizationComplete+, EqualizationPhase1+ EqualizationPhase2+, EqualizationPhase3+, LinkEqualizationRequest- Capabilities: [80] MSI: Enable+ Count=1/1 Maskable- 64bit- Address: fee00278 Data: 0000 Capabilities: [90] Subsystem: ASUSTeK Computer Inc. Device 8694 Capabilities: [a0] Power Management version 3 Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold+) Status: D0 NoSoftRst- PME-Enable- DSel=0 DScale=0 PME- Capabilities: [100 v1] Advanced Error Reporting UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt+ RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UESvrt: DLP+ SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol- CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr- CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+ AERCap: First Error Pointer: 00, ECRCGenCap- ECRCGenEn- ECRCChkCap- ECRCChkEn- MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap- HeaderLog: 00000000 00000000 00000000 00000000 RootCmd: CERptEn+ NFERptEn+ FERptEn+ RootSta: CERcvd- MultCERcvd- UERcvd- MultUERcvd- FirstFatal- NonFatalMsg- FatalMsg- IntMsg 0 ErrorSrc: ERR_COR: 00e4 ERR_FATAL/NONFATAL: 0000 Capabilities: [140 v1] Access Control Services ACSCap: SrcValid+ TransBlk+ ReqRedir+ CmpltRedir+ UpstreamFwd- EgressCtrl- DirectTrans- ACSCtl: SrcValid+ TransBlk- ReqRedir+ CmpltRedir+ UpstreamFwd- EgressCtrl- DirectTrans- Capabilities: [150 v1] Precision Time Measurement PTMCap: Requester:- Responder:+ Root:+ PTMClockGranularity: 4ns PTMControl: Enabled:- RootSelected:- PTMEffectiveGranularity: Unknown Capabilities: [220 v1] Secondary PCI Express <?> Capabilities: [250 v1] Downstream Port Containment DpcCap: INT Msg #0, RPExt+ PoisonedTLP+ SwTrigger+ RP PIO Log 4, DL_ActiveErr+ DpcCtl: Trigger:0 Cmpl- INT- ErrCor- PoisonedTLP- SwTrigger- DL_ActiveErr- DpcSta: Trigger- Reason:00 INT- RPBusy- TriggerExt:00 RP PIO ErrPtr:1f Source: 0000 Kernel driver in use: pcieport So what really is behind the `00:1c.4`? I can not say. How do I know what PCI Slot this is, so that I as a human can tell what Card I plugged in there? (GPU, USB Ports, network card, ...) (Above it only says `Port 5`, but in the motherboard manual the ports are numbered differently.) Additional Information: The motherboard is a `ASUS WS c246 Pro`.
-
raw vs qcow2 (WIndows VM, UnRAID 6.9.0-beta30)
christopher2007 replied to christopher2007's topic in VM Engine (KVM)
does "better performance" means - higher read/write speed? - less CPU usage on host (UnRAID) system? - less CPU usage on VM? - less RAM on host/VM? - ... -
So I read some articles and tutorials in order to create a Windows gaming VM with UnRAID. CPU and GPU passthrough are working great and also a UnRAID share is passed to the VM. But I have a final questions that I haven't been able to find the answer to yet: What is "better" for such a gaming VM? `raw` or `qcow2` as vdisc? From what I read, raw should be faster (more performance) then qcow2. In older benchmarks this is truly visible, but in newer qcow2 versions this seems to have only an impact of up to 5% or even less. And are 5% that bad in order not to have such big raw images lying around when not even half of them are really used? So my question here: Is raw really better than qcow2 in UnRAID 6.9.0-beta30? And if so, what does "better" mean? (faster vm in general, better read/write performance and how much, ...) Thanks for any help in advance.
-
I am using unRAID since the start of the year and I am happy with it since that day (Intel build with two NVIDIA cards). Now is the time that my partner needs a new PC.She needs to run Windows and Mac iOS so I thought unRAID could be an option. So we checked the requirements and came up with this: https://geizhals.de/?cat=WL-1782256 my questions: Is it possible to run iOS as VM on such a machine? (Mac iOS on ryzen?) There are tutorials for Mac iOS and unRAID out there, but they all use Intel CPUs. Is there a reason for this? Or only a coincidence? Is it better to buy a second, very cheap (50€/$) GPU only for unRAID? Is it possible to use GPU passthrough to a VM in this setup? There is no cpu gpu possibility for the OS unRAID, so what will unRAID itself do? (And I also think that only one VM can run with such a passthrough, but that is fine ) Any rough mistakes in this build in general? Something I have overseen? Thanks in advance.
-
My setup: Netgear GSM7328Sv2 Layer-3 Switch with two SFP+ 10Gbit modules installed that convert to RJ45 with Cat6 (no a or e) On each of the Cat6 ends there is a computer: One is the UnRAID server (with a 10Gbit ASUS XG-C100C PCI card, MTU of 9000, a M2 cache drive and several seagate HDDs, the main HDD samba share does not use the cache and the mover in order to directly write to the array). The other is a Windows 10 computer (one HDD and one M2 ssd inside, with a 10Gbit ASUS XG-C100C PCI card). The old problem: Copying from the Windows Computer to the UnRAID Server failes after a few seconds and the network "freezes". (every time, no copying possible at all.) Let me explain: I sit on the Windows Computer and start a ~60GB folder copy (there are files in it from 1MB to 8GB). After a few seconds the speed drops down to 0KB/s and the UnRAID server does not respond anymore. That means I still get a pong on a ping, but I can not call the webinterface of the unraid, not open any samba share and also no SSH into the server. All from that one Windows computer. But in exact this time I can do everything from a second, other windows computer (SSH works, Samba Share read and write works, the webinterface can be called and used, ...). So I figured out that this must be a Windows problem. I read many discussions on `Super User` and `Unix & Linux` from stackexchange and tried my best ... The new/current problem: ... After all that reading I tried configuring a few windows settings: under the `Network Settings` I changed from the `128-Bit encryption` to the `40- or 56-Bit encryption` I checked the `Receive Window Auto-Tuning Level` with `netsh interface tcp show global` and set it to experimental with `netsh interface tcp set global autotuninglevel=experimental` under the network interface settings I disabled `Computer can turn off the device to save energy` MTU is set to 1500 And also configured the network interface card on windows: Energy-Efficient Ethernet -> Disabled (default was `Disabled`) Interrupt Moderation -> Disabled (default was `Enabled`) Interrupt Moderation Rate -> Off (default was `Adaptive`) Flow Control -> Disabled (default was `Rx & Tx Enabled`) all `Receive Buffers` -> 4096 (default was `512`) all `Transmit Buffers` -> 8184 (default was `2048`) all `TCP/UDP Checksum Offload` -> Disabled (default was `Rx & Tx Enabled`) Receive Side Scaling -> Enabled (default was `Enabled`) Priority & VLAN -> VLAN Enabled (default was `Priority & VLAN Enabled`) Jumbo Packet -> Disabled (default was `Disabled`) all `Recv Segment Coalescing` -> Disabled (default was `Enabled`) Downshift retries -> Disabled (default was `4`) IPv4 Checksum Offload -> Disabled (default was `Rx & Tx Enabled`) Now I can copy files from Windows to UnRAID's M2 cache with a 100/0 change for success. Copying to M2 will always work. (I created a second samba share that only uses the M2 cache drive in order to verify my thoughts.) But I can copy files from Windows to UnRAID's HDD (no mover, no cache) with only a 60/40 change for success. Copying to the HDD will fail in around 40% of the tries. So I figured that Windows tries to copy files to unraid faster than the HDD is able to write and that if the HDDs will not keep up fast enough, the copy failes. That also would explain why copying directly to the M2 cache will always success because ot the higher write speeds. I installed the UnRAID stats plugin and captured this: The Array writes without a drop. But the network drops, so I guess I am write: Windows tries to send data faster to UnRAID than the array can write. (This screenshot carries on like so: The storage continues around 150MB/s without a drop and the Network will peak up to around 200MB/s from time to time and then drop back to 0. This copying in particular succeeded.) Additional: All copying from windows were copying from a HDD inside Windows. Copying from the M2 ssd inside Windows to UnRAID makes the network peak even worth: starting at 750MB/s and then dropping down like cracy. Here a failed copy is more likly then from a HDD. I guess only around 20% of the time this will work, so really bad. (A faster timeout because of a more cracy amount for caching somethere? don' know...) My questions: Where is the data, that is sent too fast, cached? (The RAM does not goes significant higher) Is it a bad idea to go with Cat6 Rj45 cables to a SFP+ port? How can I achieve that the overall network speed for writing is lower so that it will not drop? (From Windows viewpoint: better lower but continually write speeds) Are jumbo packets needed? Turing them on crashes any copying attempt. If yes: There is a jumbo packet setting inside the network interface on Windows, but also I can set the MTU via cmd/bash. Should I set both ot only one? The interface setting can be `Disabled`, `9014 Bytes`, `4088 Bytes`, `2040 Bytes`, `16348 Bytes`. The MTU via cmd/bash can be set to anything. Should I set both to `9014` or the MTU to `9000` and the interface to `9014`? Setting the MTU to 9000 and the Interface to 9014 and I can no longer access the Webinterface and the samba shares Setting the MTU to 1500 and the Interface to 9014 and I can access the Webinterface and the samba shares The netgear switch can set a port to a maximum MTU of `9216`, not any higher. My general Problem in this quesiton 3 is: switch, interface and mtu. Three places to set a size and I have no idea where the headers are part ot the size and where not. So setting what of these three places to what setting. Setting the `autotuninglevel` to `normal` goes back to the old problem: no copying possible. Did I changed too many settings in the network card? What should I revert to default? Can I change network interface settings in UnRAID? e.g. can I change `Flow Control` in UnRAID or other settings? And if so, should I?

-
How to correctly backup an UnRAID server? (Full backup of everything) I read about different techniques (rsync, rclone, Duplicacy, ...) and decidet to use `Duplicacy` for my own shares. But what about the VMs, the docker config files and the UnRAID configuration itself? In the end I need a backup routine that generates backups for the emergency of a full server lose. So it must be possible with little or huge effort to grab a backup and recover the full server with all docker configurations, UnRAID settings made, own personal files, ... So currently Duplicasy syncs the main personal share with the user files. The plugin `Backup/Restore Appdata` generates a appdata backup onto the user share that is also after that backuped with Duplicasy. And the rest? Is it necessary to back up the full root `/`? Or how can I specify everything I need but not everything that is out there (my configs of docker images are interesting, but not the docker container itself because that can be downloaded again). How does full UnRAID backups work? What software or methods do you use in a real life scenario? (My 20TB UnRAID share is in daily use and a second 20TB server is in another building with 100Mbit connection. Not the fastest yet, but that should not concern in my question. Let's say, there is a backup server with enouph space and I want to backup my configs in order not to lose anything in an emergency.)
-
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
Ok, I have new test results. Like @bastlsuggested, I tried to max out the possible supported MTU. For that I set up a MTU of 9216 in my Netgear switch (maximum possible) and started pinging the switch with the windows machine: ping <SwitchIP> -f -l <MTU> the UnRAID server: ping -M do -s <MTU> <SwitchIP> The MTU given here is without header, so the actual MTU has 28 Bytes more. The results: OnBoard 1G network card in UnRAID: maximum possible MTU in ping command was 1472, so 1472+28=1500 ASUS 10G network card in UnRAID: maximum possible MTU in ping command was 8972, so 8972+28=9000 OnBoard 1G network card in Windows: maximum possible MTU in ping command was 1472, so 1472+28=1500 ASUS 10G network card in Windows: maximum possible MTU in ping command was 8972, so 8972+28=9000 So I set up the MTU accordingly. Also like @bastlsuggested, I tried to exclude the heat problem. Because yes, the card gets really really hot but I am not able to get temperature data out of this pci card (only motherboard, cpu and gpu seems to have sensors). So I 3D printed a holder for a 40mm fan and installed it on the UnRAID server and also on the Windows client. The cards are now much colder. But now it gets really weired: UnRaid looses the network connection on a Windows Backup. That is a behavior I already described in this thread earlier, but was not able to tell more precicly because of so many overlapping problems. Easy scenario: I want to create a Backup from either the main Windows machine or a second Windows machine over the network. The backup file starts with 0KB and will grow until the maximum backup size is reached (around 300GB on the second machine and 700GB on the main machine). On both it fails after a random period of time. And the UnRaid server is then no longer reachable in the network. I have to pull out the rj45 cat6 cable from the network card, wait a second and put it back in. Then the server can be reached again in the network. I attached a diagnostic download from after such a network lose and re-plugging the cable. The replug of the cable was at 18:25. Five to ten minutes bevore that the server was unreachable in the howl network (tested it also with my phone). This problem is independently of the network card (problem occurs in all combinations between UnRaid with ASUS, UnRais with OnBoard, Windows main with ASUS, Windows main with OnBoard, second Windows with OnBoard). Also the same happens when just copying a very very large single file to the server. I tried it with a 250GB file (single file generated only for that test) and the same weird thing happend: The server could not be reached in the network. At this point I am speechless. I have no more ideas than to blame it on UnRaid. And that is sad, I really got in love with that OS. It is so easy and clean in usage and yet so powerful. Does anyone have another idea? What am I doing wrong? (other tests I run: replacing the switch, creating a VLAN, replacing the cat6 copper cables and even turning the server up side down ... mainly for finding that one screw that rolled under the mainboard, but hey, at least it could have been a valid test.) ts-alt-diagnostics-20200720-1844.zip -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
Thanks so much @bastl. Currently, I have so many things to test on my stack that it will cost some time until I have new results and information. But one thing seems to be quite sure: It must be the 10G card. The question now is, whether it can be fixed or has to be swapped out. Jumbo frames are the next thing I will try and after that mounting additional fans only to the card for better cooling. Next post will be, hopefully, results and clarity. -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
Thanks @bastl for all your time. So currently everything points to the 10G network card. Test setup: The second Windows 10 computer (test bench) could back up with Macrium. 100% and around 400GB saved. OnBoard intel network card from Windows to OnBoard network card in UnRAID. -> pass Then a second backup with the second Windows 10 computer (test bench) with Macrium. 1% and then stuck like descriped in my first post. OnBoard intel network card from Windows to 10G ASUS network card in UnRAID. -> no pass Next I will test OnBoard intel from main Windows 10 computer to UnRAID with both intel OnBoard and 10G ASUS. Unfortunately this all is only practical testing ... no theoretical approach. But I am a littlebit confuded because others seem to use the ASUS network card without any problem. And 10G network is important for me (2G minimum, but the main machine does not have the possibility for a link Aggregation, so I have to rely on a PCI network extension card). `ethtool -i <10G network card>` on the UnRAID server: driver: atlantic version: 2.0.3.0-kern firmware-version: 3.1.58 expansion-rom-version: bus-info: 0000:01:00.0 supports-statistics: yes supports-test: no supports-eeprom-access: no supports-register-dump: yes supports-priv-flags: no `ethtool <10G network card>` on the UnRAID server: Settings for eth0: Supported ports: [ TP ] Supported link modes: 100baseT/Full 1000baseT/Full 10000baseT/Full 2500baseT/Full 5000baseT/Full Supported pause frame use: Symmetric Supports auto-negotiation: Yes Supported FEC modes: Not reported Advertised link modes: 100baseT/Full 1000baseT/Full 10000baseT/Full 2500baseT/Full 5000baseT/Full Advertised pause frame use: Symmetric Receive-only Advertised auto-negotiation: Yes Advertised FEC modes: Not reported Speed: 1000Mb/s Duplex: Full Port: Twisted Pair PHYAD: 0 Transceiver: internal Auto-negotiation: on MDI-X: Unknown Link detected: yes I changed the switch in order to hopefully find the problem in the network like suggested. So the speed is only 1G. @bastlnice one, I had overlooked the timezones ... to frustrated over the last three days because of breaking network SMB drives and no backups. Nice one -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
Is there a way to get the driver information from the installed 10G network card? Currently I am testing with another Windows 10 PC and until now Macrium runs just fine (currently 43% with finished 105GB). My changes for this test: The secondary Windows Computer has an Intel LAN OnBoard network card. The UnRAID server now uses only one OnBoard network plug and not the 10G PCI card from ASUS. The main Windows Computer normally has the exact same 10G PCI network card. UnRAID and main Windows use the `ASUS XG-C100C, RJ-45, PCIe 3.0 x4 (90IG0440-MO0R00)`. So my current guess: This card causes the trouble. Not 100% sure at this point, but the best guess in the last three days. For the main Windows Computer there are the old ASUS drivers and newer drivers from the chip `Aquantia AQC107` that is build inside the ASUS ripoff. But for UnRAID I am not sure. What version is UnRAID using? Is there a way to install a newer version? And @bastlcreepy, but I guess the geizhals link has betrayed me, hasn't it? 😜 -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
@johnnie.blackthanks a lot, that link and the explanation helped a lot. So my sde has 64239458, so 3D43762 in hex, so 0 errors ... lucky me 😅 -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
Thanks so much @bastlfor your time. I am using 4x `Seagate Exos E 7E8 8TB, 512e, SATA 6Gb/s (ST8000NM0055)` brand new. I tested the SMART information before the installation and there were no errors and also no used time (so from what I could extract, the discs were never used before). So how does it come to this kind of errors? Should I be worried? Can this be fixed? I build the new server by myself with these parts: hardware list After that I configured everything and copied all old files with `rsync -tr --info=progress2 <source> <destination>` from the old Synology NAS to the new UnRAID server directly in the fresh created SMB folder share. This command faild two times so I had to Crlt+C in order to cancel it and then remove everything with `rm -rf` in order to start from the beginning. Could the errors be the result of the rsync canceling the hard way? Now I am very worried. The system is new and there are read/write errors? 🙈 @Energenthanks for your distribution as well. Macrium warns me (in red) if I set up the file split for the backup: `Note: Incremental retention rules will not be run if backup files are split. This can be caused by setting a fixed file size or if the destination file system is FAT32` My english is not the best, but I guess only full and differential will work with file size split activated. Unfortunately there are no games I am trying to backup. It is the Windows OS with my work and the renders I am working with are sometimes large. But I will investigate my network in order to search for an error there. And I am now starting a Macrium backup with an other computer (also Windows 10) in order to have more information for the problem. -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
Unfortunately no IDS on the network. I will search for one maybe as a docker image to install on the server as well. Also not tested with other computers yet. Currently I am installing a Win10 machine in order to test Macrium backups with this in a few minutes. Avast is installed on the main system as virus scanner. But no problems when backing up to the old Synology, so I never tried turing it off. But now I did and it did not changed the result of a stuck backup. I will try it with the other windows machine and then come back with the results. Until then one side question: Better use SMB shares in Windows over IP Address or over computer name? -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
Attached the zip file. -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
@bastl thanks for your help so far. I started a new backup. Directly stuck at 0%. Disc temps all normal, under 50°C. No errors in the system log. Only output in that time: `Jul 18 13:25:04 TS-Alt emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdd` I already had a look in the diagnostic zip file, nothing found there but I attach it to this post (dump was created one minute after realizing that the backup has again stopped at 0%). My next idea maybe is the network card. I have two 1G rj45 network plugs on the motherboard and linked them with a link aggregation 802.3ad. My netgear switch can handle that just fine and so I had 2G connectifity. After I realized the backup problem I installed a 10G network card (one from ASUS, a ripoff of atlantic, twisted pair, Cat6). But the problems are even worth now: Same backup problem. But now new: sometimes breaking up the connectivity so that Windows says `host unreachable`. Waiting for a few seconds and I can use the share again. I am not sure if this problem was also on the network bond. And it is hard to test this because these `connectifity loses` are once an hour or so without any errors logged in the server. ts-alt-diagnostics-20200718-1326.zip -
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
@bastlOf course, sry for not have thought on this by myself. The screenshots are attached to this post. And yes, I have a `minimum free space` set to `100GB` for testing. Until yesterday it was on `0KB` (default). Also I restarted the system one hour ago in order to see if that helps (try to turn it off and on again?) ... sadly no change. The problem remains ... But the docker container are now showing the `WebUI` menu entry again. That was a problem the last days because this menu entry was missing but instead the context menu on right click showed `Console`. Curently only one docker container is installed and running: `binhex-krusader` with additional hooks to the undesigned devices and the root share. But turning off the docker image does not help for the problem discussed in this thread.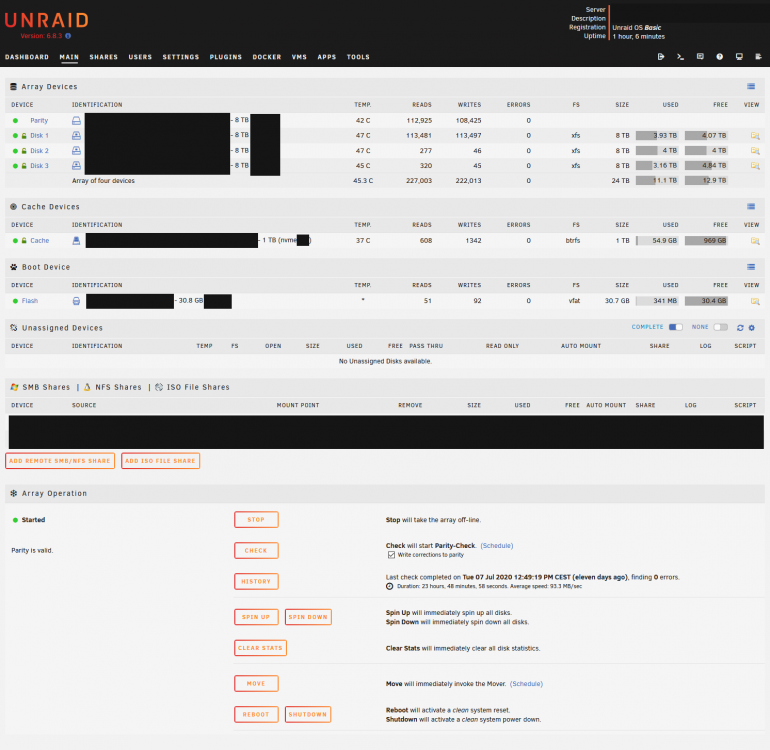
-
problem with growing files on the disk array
christopher2007 replied to christopher2007's topic in General Support
@bastlthanks for your fast reply. Yes, there is a option for splitting the Backup in smaller files. But with this setting turned on, Macrium is no longer able to create incremental backups. So sadly that is no option for me due to the daily backup importance. Currently there is one full backup every two months, a differencial backup every two weeks and incremental backups each day. And after migrating from Synology to UnRAID the first new full backup to UnRAID fails with the above explained problem. -
I have a problem similar to this old one. I am trying to backup my Windows Computer to the UnRAID Array with a Software called `Macrium`. The program works fine, no error logs or crashes. Backups are working when sent to Synology shared folders or Qnap shared folders. But on UnRAID: The backup is starting, creating a small backup file on the server (around 500MB to 1.3GB) and then does not continue. The Windows process does not freeze and the backup process can be paused, stopped and closed. It will just tell me `20 minutes remaining` and stuck at around 0%-2% in the progress bar, but nothing happens from there on. So no log fails I can share. I am using one cache drive, but not for the shared folder the backup will be put on. The share for the backup is split on multiple drives (all 8TB) with the option `Allocation method` set to `High-water`. All drives are around 45-53% full. So the High-water will kick in for the next files. One backup file could reach a size of 500GB to a maximum of 1TB. The extension `Recycle Bin` is installed on the UnRAID System along to the `Fix common plugin`. Could it be the `High water` setting? What exactly is UnRaid doing if a file grows over time. The Macrium `.tmp` image backup file starts with 0KB and then will grow up to the maximum size (500GB or max 1TB). What, if UnRAID after some percentage decides to move the physical file to an other disk? Does a "normal copy" of a large, already existing file, tells the server what space to reserve on the drive or not? What can I do with such growing files over time when the final space is not known at start? EDIT Putting the setting `Allocation method` to `Fill up` helps a littlebit. Now the process comes to 50%. But then the same problem. At some point for a growing file it could be the decision of UnRaid to put it on another physical disk when the old one does have not enough space left. So there is no Allocation method that protects me from this behavior. But how is this solved in the real world? e.g. two disks each 1GB big. disk one is 500MB full, disk two 0MB. I start with a new file, it will be put to disk one. The file grows and grows and at some point will be 501MB, not the file must be moved from disk one to disk two ... and while that is done the client crashes? That can not be the wanted behavior. Am I missing a setting? And what is the best Allocation method for such real life scenario? And what Allocation method do the most people use and why? Or is this setting not the problem? Does a file get a node on the drive and will not be pushed from UnRAID when it grows? Infos from my setup: verison 6.8.3 SMB Share over the UnRAID interface (no samba direct config) Windows 10
-
Because my girlfriend is maybe also having a VM and she has her own Workspace two rooms nearby. So if one solution has direct cables, what about the other one? And if there is no performance drawback, I then can roll out one solution for both stations in order to keep it clean. Or is the difference between network usage and direct plug so big?
-
Thanks for your time and answers @meep. So you use direct cables to the server (USB keyboard, USB mouse, multiple monitor cables, ...) or devices that combine all cables to a single network cable. The first approach could be a problem for me because of the distance between server and consumer work place. But the second solution sounds interesting. Thanks for your blog link. But now I am curious with the setup. Please correct me if I didn't understand your post correctly: The server has a GPU and the VM uses that GPU and other server resources (RAM, container space for the drive, ...). The GPU goes with a HDMI into a KVM emitter and from there on it is a Cat 5e/6 to a switch/router and into the network. Somewhere else there is a KVM receiver where a Cat Cable goes in. And out you get HDMI (monitor) and several USB ports (mouse, keyboard, ...). So far correct? It seems that this is a hardware solution for a Raspberry VM client software. It would be interesting to know how the performance in between the two solutions is. I would guess, that in a Raspberry software build you have more overhead for encoding and decoding with also the host device controllers. But in the end I am now searching for a KVE device in order to get more information of the specs and maybe just try it. Do you have a recommendation except the `4KEX100-KVM`? It seems only to handle one monitor. So what to do with my two monitor setup? Or how are these devices in general called so that I can search for my own? (Until now I did not knew they exist, so I have no name for them.) Thanks in advance.
-
hi, I am new to unRAID and currently upgrading from my old NAS (only network storage) to a unRAID solution. I want to use this new hardware build mainly for network storage, but also for some docker container, plex and two VMs (one windows and one linux). The VMs should erase the purpose of my current desktop PC for my work (currently dual boot, that's why there will be two VMs). I never build a VM solution like that and so I have some questions: Is it a good idea to replace a desktop PC with a VM completely? (of course having a laptop for problem solving situations in the house is essential) What are downsides, drawbacks (power, reliability, ...) and things to consider when doing so? What is the way to go in order to get a decent experience? I read different approaches in the web, but what is "the normal way to go"? Server with LAN cable to switch, Raspberry with LAN cable to switch and a VM client on the Raspberry (pure LAN connector to LAN connector) Server with LAN cable + HDMI Cable to LAN cable converter and the Raspberry then also with a HDMI+LAN converter (something like this) Direct connected USB Mouse, USB keyboard and two Monitors to the Server in order not to use LAN at all (thunderbolt maybe as longer range?) Maybe a completely other setup? Is there a big difference between 2.1. and 2.2. in case of speed? Does the input of keyboard and mouse lag? Or is there a limit of monitors (I need two) and display resolution (one is 4K, the other ultra wide) and the speed of transmitting the video signal? In Case of 2.1. and 2.2. is a 1GbE network enough or does this require a 10GbE? Because a Raspberry only has 1GbE. Otherwise there must be an other computer as client in order to receive and control the VM as client. The VM should later be capable of: Video editing, programming and sometimes a little gaming. The hardware is not part of the question. Here I am only interested in the setup for the VM and the transmission to the client that the user will sit and work with. Thanks in advance.
-
ok, thanks a lot. I think that I can now choose a system that fits my needs
-
I am sorry, this time I have big troubles understanding the content of your answer. Maybe it is because of my bad knowledge or due to my English skills. But although I picked an AMD consumer CPU, I should not have disadvantages over the Xeon, right? From the features I read, there should be no big difference. Here I now have my understanding problems: You refer to the Gigabyte X570, not the ASRock X570, right? Both have the same `X570` in the name, so I am a little bit confused. Let's assume you meant the Gigabyte X570: So I should not take the Gigabyte X570 AORUS ELITE because it only has 2 x16 PCI-E. I should go for 3 x16 PCI-E, but do you mean the Gigabyte X570 UD or the Gigabyte X570 AORUS PRO? So picking one with 3 x16 should not defeat the purpose to get Gigabyte, right? Or is the 3 x16 defeating the purpose of getting a Gigabyte? I will use a GPU, currently there is a Nvidia 1060Ti in the build. Will unraid not boot with this build? Why do I need a second cheap GPU? And do I have to dump vbios in order to pass through the 1060Ti to a VM? Sry for the mess, but I really have big troubles understanding your answer. All the references are confusing do to double used names.



