

Kreavan
-
Posts
24 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Kreavan
-
-
On 1/12/2023 at 5:52 PM, CrazyBoyS said:
Hello,
So after the newest release of the plex docker i have been having issues. Some shows wont play, Audio plays but no video, also now it wont scan my new files. I have added a bunch of new stuff and its not scanning like it has always. I have had no issues updating the plex docker from Linuxserver.io and really like it but this is a first.
Not sure what is happening. I have had a few family members let me kow about the play back issues which was fine until i did the update yesterday.
Any help on this? Also i have tried to revert back to the one from Dec but the logs keeps saying : ########################################################
# Upgrade attempt failed, this could be because either #
# plex update site is down, local network issues, or #
# you were trying to get a version that simply doesn't #
# exist, check over the VERSION variable thoroughly & #
# correct it or try again later. #
########################################################I've heard that reverting to the previous 1.30.0 version fixes the issue. Just not sure how to do that.
-
I've had this docker running flawless for 5 months. I haven't changed anything, but now it is giving the following error:
Raising maximum file descriptor to 65535 failed. This may cause problems with many clients. (errno=1)
Raising nice-ceiling to 35 failed. (errno=1)
Not sure what this is, or how to fix it. -
34 minutes ago, Kreavan said:
I went in and disabled "Passthrough" in order to re-enable the option to "Mount." When I tried, it immediately fails. Checked the log and this is what is showing.

Since I didn't really have anything on that drive needing to be recovered, I wiped the partion, re-formatted, and it's back up and running again. Still unsure what happened, but all good now.
Thanks for the help folks!
-
13 hours ago, dlandon said:
The disk is not mounted. Because the mount points are in ram and incorrect mappings can cause ram to fill, there is a protection on the mount point /mnt/disks and it is limited to 1MB. You are not really seeing the UD disk you think you are,
You need to find out why the disks aren't mounted and get them mounted.
I went in and disabled "Passthrough" in order to re-enable the option to "Mount." When I tried, it immediately fails. Checked the log and this is what is showing.
-
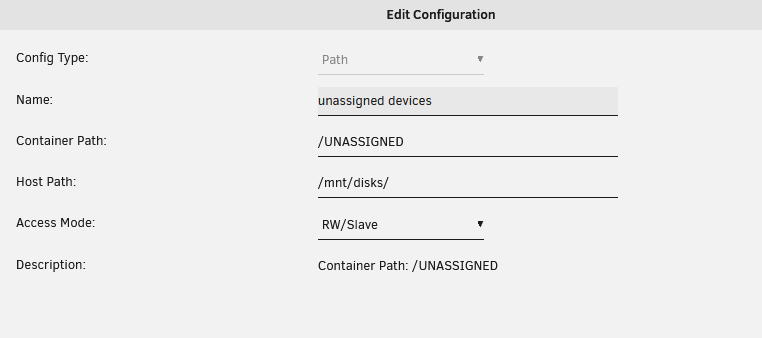
2 minutes ago, Squid said:
Is /UNASSIGNED mapped to /mnt/disks with Read/Write:SLAVE in Krusader's template?
Yes
-
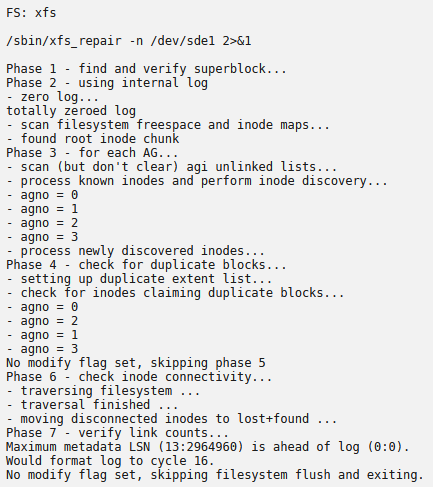
Not sure what happened, but all of a sudden my share is only showing 1mb in size. Yet, the drive in unassigned devices is showing 4tb. Uninstalling/reinstalling the plugin did nothing. Tried restoring Appdata from a previous backup (No change either). I've been using the drive as a location for downloads and transcodes.
Ran a SMART test and everything passed.
This is what is showing currently:
File System Check results:
when I navigate to the share in VNC, it is showing 1mb in size and I can go into the folder(s). However, I can no longer create anything in there. It is acting like the share is corrupt, but not sure how I can recreate it.
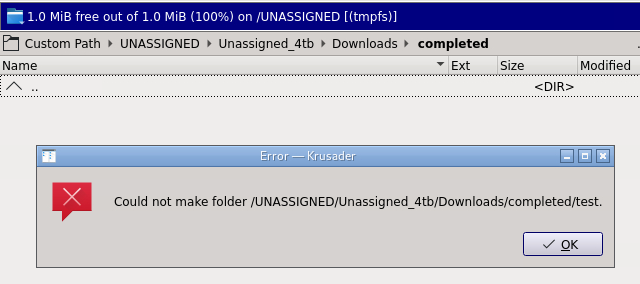
-
Ok, so I'm on day 3 of zero crashes. Looks like my issue has been fixed. Summary below of the changes that appear to have led me to this stable result.
- Moved Unraid USB to 2.0 slot.
- Flashed BIOS to latest version (1.30)
- Disabled all power management features
- No overclocking at all (Everything default or Auto)
- Changed BIOS setting "Power Supply Idle Control" to "Typical Current Idle"
- Uninstalled GPU Statistics plugin
- Added "rcu_nocbs=0-31" to the kernel
- Disabled Bonding and Bridging in Network Settings
- Changed BIOS setting "Global C State" to "Disabled"
-
 2
2
-
-
Results of my Windows 10 test. It loaded up fine. I launched Ryzen Master and all the temps are normal. Also ran CPU-Z, Prime95, and Cinebench. Stress test the machine and nothing crashed.
One thing to note, I did find out that "Global C-state" in the BIOS was still set to "Auto" when I thought I had disabled it. It is now turned off for sure. So, I'll find out tomorrow if another hard lock occurs overnight. Keeping my fingers crossed.
-
1 hour ago, meep said:
No help, but I'm in a similar boat with a similar system (Asrock Taichi X399, TR 2950X)
The system was pretty solid for months, but I made a few changes over the past couple of weeks and it's been very unstable since. Like you, it will run fine for a few hours, but then will lock up overnight, and will take a few attempts to boot reliably.
I ran a memtest today, and it froze at 2 hrs, so that's likely a clue. I've removed the extra 32GB I added and will run again overnight to see if that's the culprit.
Not a solution for you, i know, but just wanted to say I empathise!
I appreciate that I'm not the only one. I think what my next step will be is to run Windows 10 off a USB and run Ryzen Master. Maybe that'll give me some more info.
-
My server hard crashed again last night. This seems to be the trend of it hard crashing overnight when I'm asleep. It runs fine all day. I'm running out of ideas of what could be causing this.
-
Experienced another hard lock last night while I was asleep. This morning, I did find the Global C State option in the BIOS and have changed it from "Auto" to "Disabled". Hoping this fixes the instability. Keep you posted.
-
-
The server hard locked sometime last night. The syslog doesn't show any new entries from the last time I checked it. So, I'm a bit lost now. Guess it is something in the BIOS maybe. Any thoughts on what I could check/change there to stabilize my build? I'll try to photos of my current BIOS settings and post them after my shift.
-
I'm still experiencing random issues with the network connectivity as mentioned in my last post. Based on what I'm seeing in the Syslog, I'm thinking it might have something to do with the Binhex-DelugeVPN docker as I'm finding references of my VPN IP in some of the log lines before it happens.
So, I've shut down that docker and will see if that stabilizes things.-
1
-
-
I did this very same thing yesterday. I fixed it by booting into GUI mode. Once there, brought up the web interface. Go to Network Settings and on the "Bridging members of br0", add the unchecked. Reboot and it should work.
-
So, the server did not lock up overnight like it has previously. However, earlier today I did lose connectivity to the web GUI and seemed network activity ceased completely on the server. I checked the Syslog and seems docker0 had some issues.
Apr 16 10:28:05 Atlantis kernel: docker0: port 1(veth67de24f) entered disabled state
Apr 16 10:28:05 Atlantis kernel: vethd439256: renamed from eth0
Apr 16 10:28:06 Atlantis avahi-daemon[6289]: Interface veth67de24f.IPv6 no longer relevant for mDNS.
Apr 16 10:28:06 Atlantis avahi-daemon[6289]: Leaving mDNS multicast group on interface veth67de24f.IPv6 with address fe80::ec65:dbff:fe4a:32e2.
Apr 16 10:28:06 Atlantis kernel: docker0: port 1(veth67de24f) entered disabled state
Apr 16 10:28:06 Atlantis kernel: device veth67de24f left promiscuous mode
Apr 16 10:28:06 Atlantis kernel: docker0: port 1(veth67de24f) entered disabled state
Apr 16 10:28:06 Atlantis avahi-daemon[6289]: Withdrawing address record for fe80::ec65:dbff:fe4a:32e2 on veth67de24f.
Apr 16 10:28:06 Atlantis kernel: docker0: port 1(veth6f25b29) entered blocking state
Apr 16 10:28:06 Atlantis kernel: docker0: port 1(veth6f25b29) entered disabled state
Apr 16 10:28:06 Atlantis kernel: device veth6f25b29 entered promiscuous mode
Apr 16 10:28:06 Atlantis kernel: IPv6: ADDRCONF(NETDEV_UP): veth6f25b29: link is not ready
Apr 16 10:28:06 Atlantis kernel: docker0: port 1(veth6f25b29) entered blocking state
Apr 16 10:28:06 Atlantis kernel: docker0: port 1(veth6f25b29) entered forwarding state
Apr 16 10:28:06 Atlantis kernel: eth0: renamed from veth9d8220e
Apr 16 10:28:06 Atlantis kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth6f25b29: link becomes ready
Apr 16 10:28:08 Atlantis avahi-daemon[6289]: Joining mDNS multicast group on interface veth6f25b29.IPv6 with address fe80::80e3:9ff:fe4f:1367.
Apr 16 10:28:08 Atlantis avahi-daemon[6289]: New relevant interface veth6f25b29.IPv6 for mDNS.
Apr 16 10:28:08 Atlantis avahi-daemon[6289]: Registering new address record for fe80::80e3:9ff:fe4f:1367 on veth6f25b29.*.
How do I find out which one of my dockers is docker0? -
22 hours ago, Dissones4U said:
As always if anyone sees something wrong or misinterpreted please feel free to correct me, this is my best guess...
There are lots of these (↑), related to Nvidia. If I'm not mistaken it means you've installed a modified version of unRaid and would need to seek support for that plugin here. Within that topic someone says they have the same error and then system gets unresponsive.
There are lots of these too and according to this thread it can cause cause a locked console. This thread on the unRaid forum says it may be fixed by moving the offending controller. Between this PCIe error and the PCI Bus with Nvidia I think this is where I'd start (your log is completely spammed with these). One final thread about the PCIe error mentions Nvidia too.
I've uninstalled the GPU Statistics plugin as I saw that could be the cause of the constant errors of the following:
Apr 15 12:59:13 Atlantis kernel: resource sanity check: requesting [mem 0x000c0000-0x000fffff], which spans more than PCI Bus 0000:00 [mem 0x000c0000-0x000dffff window] Apr 15 12:59:13 Atlantis kernel: caller _nv000908rm+0x1bf/0x1f0 [nvidia] mapping multiple BARs Apr 15 13:01:11 Atlantis emhttpd: cmd: /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin remove gpustat.plg
I also added to the kernel "rcu_nocbs=0-31" as I saw in a video from SpaceInvaderOne that helped stability with his Ryzen build.
Lastly, I noticed in most of the instances of my hard locks, the server appeared to be doing a NIC check of some sort. It happened again last night and in the process of that, the Netgear switch my server is plugged into froze too. I read that some switches do not support bonding and could cause problems. So, I've disabled bonding as well.
So far, 1hr in, the resourse sanity check error has not popped back up on the syslog. No lock ups yet, but usually they tend to happen overnight anyway. Will post the results tomorrow.Thanks!
-
So, the hard lock happened again last night at 2:54:28. Attached the latest syslog.
-
On 4/13/2020 at 4:15 AM, johnnie.black said:
Also see this, overclock RAM is known to cause stability issues (even data corruption).
I'm running 4 sticks dual channel at 2133mhz not OC.
-
57 minutes ago, Dissones4U said:
Make sure you're USB flash is on a USB2 port, USB3 is known to cause random crashing. I'll look at the diagnostics when I get the chance...
I did have the USB flash on a 3.1 slot. I've moved it to a USB 2.0 slot now.
I also went into the BIOS and changed the "Power Supply Idle Control" setting from "Auto" to "Typical Current Idle" as I saw other forum posts mentioning that could be a problem.
Back up and running for now. Hopefully that fixes it. -
Here are more details as requested. My Unraid build is new (still on trial version for 8 more days). This hard lock issue has been happening pretty much since day one intermittently. There have even been a few instances where my netgear gigabit switch would die along with it, which was strange. Forgot to add in my hardware build, I have an Nvidia p2000 gpu. No consistency in the crashes. Sometimes it will go 5 days without an issues, and sometimes only 12-15hrs.
I have the following dockers installed, and the issue has happened even with all of them stopped.
- Plex
- Binhex Delugevpn
- Binhex Sonarr
- Binhex Radarr
- Binhex Krusader
- Jackett
Plugins installed:
CA Auto Update Applications
Community Applications
CA Backup/Restore Appdata
CA Cleanup Appdata
Dynamix Active Streams
Dynamix Cache Directories
Dynamix Date Time
Dynamix SSD Trim
Dynamix System Information
Dynamix System Statistics
Dynamix System Temperature
Fix Common Problems
GPU Statistics
Nerd Tools
Preclear Disks
Unassigned Devices
Unassigned Devices Plus
Unraid Nvidia
I do not have any VMs installed or running.
Steps I've done so far:
- Flashed BIOS to latest version being 1.30
- Disabled all power management features
- No overclocking at all
- Ran Memtest86 and it all came back fine
- Reseated CPU and all cards
- Replaced motherboard
- Tried both Ethernet ports
- Tried letting Unraid run idle with no dockers active
Full syslog starting from 4_9_2020.txt diagnostics-20200412-1246.zip
-
I've been trying to fix intermittent hard locks on my threadripper build, but have not been successful. It has happened twice in the last two nights. There are some similarities I found in the syslog during the times right before it happens. I'm not too familiar with the entries though, and was hoping someone here might be able to look at them and know what it is related to.
The two syslog files are just the snippets of activity right before the hard locks occur.
Build details:
ASRock x399 Phantom Gaming 6 (BIOS v1.30)
AMD Threadripper 2950x
32GB Corsair Vengeance LPX DDR4 3200
9207-8i HBA SAS PCIe 3.0 adapter
Samsung 860 QVO 1tb (x2 in RAID 1 as cache drive)
Western Digital Red 8tb (x5) - Main Array
Western Digital Red 4tb (x2) - One as an Unassigned drive
Thanks! -
I've got the following drives to work with and wanted to see if this would be an ideal setup.
x4 - Western Digital Red 8tb hard drives
x2 - Western Digital Red 4tb hard drives
x2 - Samsung EVO 860 1tb SSDs
My thought is to use the four 8tb and one 4tb drives as a storage array with one 8tb as a parity. This would be primarily used for media and file storage. The use the two 1tb SSD drives as a mirror array using one as a parity. This would be used for Dockers, VMs, and Plex metadata. Then use the last 4tb drive as a temporary download cache and transcoding drive.
Would this type of setup be ideal?
Thanks!






Error from Update
in General Support
Posted
I got the same error. Not sure what to do.