

Matthew_K
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Matthew_K
-
-
IS there a setting where if the cache poll hits a certain size limit, Like 10 GB left that all the docker containers can be gracefully stopped until I have time to investigate my boneheaded provisioning decisions? This may be a nice safety feature to have so those containers that had databases don't become corrupted.
-
Playing musical IP, homemedia.local -> 192.168.1.123 via hosts file now.
Thank you for your response. I can confirms that if I have each container its own subdomain it works perfectly finehttp://mediawiki.homemedia.local/
http://phpbb3.homemedia.local/
http://phpmyadmin.homemedia.local/The reasons why I was running the sites as sub directory is because this it a very old site predate when widecards.somedoman became the standard. I thought it would be easier the just keep with that format but it looks like it is just a pain.
http://homemedia.local/mediawiki
http://homemedia.local/phpmyadmin
I guess i should just come into the modern age...
I am attaching my docker compose if you want to experiment. I think I should be good with just updating my crap 😁
Again thank you for your help -
Made a bit of progress for phpbb if i change the location to First location is /forum (or anything other then "/phpbb") I will get the page however it missing all the formatting and then when i try to log in it gives me a 502 error.
2023/06/03 03:06:27 [error] 2274#2274: *34126 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /bitnami/phpbb/styles/prosilver/template/forum_fn.js HTTP/1.1", upstream: "http://192.168.1.123:80/bitnami/phpbb/styles/prosilver/template/forum_fn.js", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:27 [error] 2274#2274: *34172 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /assets/javascript/jquery-3.6.0.min.js?assets_version=4 HTTP/1.1", upstream: "http://192.168.1.123:80/assets/javascript/jquery-3.6.0.min.js?assets_version=4", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:27 [error] 2275#2275: *34166 upstream prematurely closed connection while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /assets/javascript/core.js?assets_version=4 HTTP/1.1", upstream: "http://192.168.1.123:80/assets/javascript/core.js?assets_version=4", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:27 [error] 2274#2274: *34174 upstream prematurely closed connection while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /styles/prosilver/theme/stylesheet.css?assets_version=4 HTTP/1.1", upstream: "http://192.168.1.123:80/styles/prosilver/theme/stylesheet.css?assets_version=4", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:27 [error] 2274#2274: *34173 upstream prematurely closed connection while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /assets/css/font-awesome.min.css?assets_version=4 HTTP/1.1", upstream: "http://192.168.1.123:80/assets/css/font-awesome.min.css?assets_version=4", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:27 [warn] 2274#2274: *34963 using uninitialized "server" variable while logging request, client: 192.168.1.123, server: 192.168.1.123, request: "GET /styles/prosilver/theme/en/stylesheet.css?assets_version=4 HTTP/1.1", host: "192.168.1.123" 2023/06/03 03:06:28 [error] 2274#2274: *36372 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /bitnami/phpbb/styles/prosilver/template/ajax.js HTTP/1.1", upstream: "http://192.168.1.123:80/bitnami/phpbb/styles/prosilver/template/ajax.js", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:28 [error] 2277#2277: *36454 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /app.php/cron/cron.task.core.update_hashes HTTP/1.1", upstream: "http://192.168.1.123:80/app.php/cron/cron.task.core.update_hashes", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:28 [warn] 2277#2277: *36806 using uninitialized "server" variable while logging request, client: 192.168.1.123, server: 192.168.1.123, request: "GET /bitnami/phpbb/styles/prosilver/template/forum_fn.js HTTP/1.1", host: "192.168.1.123" 2023/06/03 03:06:28 [error] 2274#2274: *37784 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /bitnami/phpbb/styles/prosilver/template/ajax.js HTTP/1.1", upstream: "http://192.168.1.123:80/bitnami/phpbb/styles/prosilver/template/ajax.js", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3" 2023/06/03 03:06:28 [error] 2274#2274: *38793 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.1.142, server: 192.168.1.123, request: "GET /favicon.ico HTTP/1.1", upstream: "http://192.168.1.123:80/favicon.ico", host: "192.168.1.123", referrer: "http://192.168.1.123/phpBB3"If anyone is willing to try I can post my docker-compose.yaml and they can spin up their own instance.
-
Working on a Proof of concept, I have Nginx-Proxy-Manager-Official installed as a br0 network with public IP of 192.168.123 and it has a private network of 172.16.0.2
I am running containers of and phpbb, mediawiki and phpmyadmin on the Private network
My goal is to have each container accessible via the schema below
https:://192.168.1.123/phpbb
https:://192.168.1.123/mediawiki
https:://192.168.1.123/phpmyadmin
Nginx-Proxy-Manager-Official can resolve both the phpbb, mediawiki and phpmyadmin from in the container (curl <dnsname> I got mediawiki setup and it looks to be running
My proxy Host Domain name is 192.168.1.123
- Schema is http,
- Forward Host/IP is 192.168.1.123
- Port is 80
Under Custom location for the host domain
First location is /phpbb
- Schema=http
- Forward Hostname = phpbb
- Port 8080
Second location is /mediawiki
- Schema=http
- Forward Hostname = mediawiki
- Port 80
Third location is /phpmyadmin
- Schema=http
- Forward Hostname = phpmyadmin
- Port 80
Mediawiki seems to work but phpbb returns forbidden and phpmyadmin just error out
phpmyadmin in proxy-host-1_access
[02/Jun/2023:04:04:56 +0000] - 404 404 - GET http 192.168.1.123 "/phpmyadmin" [Client 192.168.1.142] [Length 244] [Gzip 1.18] [Sent-to 192.168.1.123] "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0" "-" [02/Jun/2023:04:04:56 +0000] - 502 502 - GET http 192.168.1.123 "/favicon.ico" [Client 192.168.1.142] [Length 154] [Gzip -] [Sent-to 192.168.1.123] "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0" http://192.168.1.123/phpmyadminphpbb in proxy-host-1_access
[02/Jun/2023:04:07:01 +0000] - 403 403 - GET http 192.168.1.123 "/phpbb/" [Client 192.168.1.142] [Length 186] [Gzip 1.14] [Sent-to 192.168.1.123] "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0" "-"Any insite onto what may be happening would be great.
-
Looks like I have made progress! 😁 This will spin up a copy of jc21/nginx-proxy-manager:latest and a simple apache webserver. The Nginx will act as the front end gateway to the rest of containers. I think this is a bug in Unraid, but the Docker Containers will only show one network but there are two on the Nginx.
version: "3" services: nginx: container_name: Nginx-Proxy-Manager-Official image: jc21/nginx-proxy-manager:latest #ports: # These ports are in format <host-port>:<container-port> # - 192.168.1.123:80:80 # Public HTTP Port # - 192.168.1.123:443:443 # Public HTTPS Port # - 192.168.1.123:81:81 # Admin Web Port volumes: - /mnt/user/appdata/Nginx-Proxy-Manager-Official/data:/data - /mnt/user/appdata/Nginx-Proxy-Manager-Official/letsencrypt:/etc/letsencrypt networks: frontend: ipv4_address: 192.168.1.123 backend: # Connect the Nginx container to the backend network aliases: - nginx apache: image: httpd:latest networks: backend: # Connect the Apache container to the backend network aliases: - apache networks: frontend: name: br0 external: true backend: driver: bridge ipam: driver: default config: - subnet: 172.20.0.0/24 # Define the subnet for the backend network
-
I have been experimenting with the Docker Compose plugin, either purposefully or accidentally, in an attempt to make a group of containers work harmoniously. Check it out:
Throughout the process of setting this up, it's important to consider a few safety measures:
1. Prior to allowing users to edit the stack, remind them to first shut down the stack.
2 .Provide an option to save a working history. Essentially, whenever a Docker Compose configuration is successfully deployed, create a checkpoint or save point.
I encountered an issue where I failed to follow rule 1, and then had to rely on rule 2 to revert the changes I made by using "compose down".
Finally, I believe it would be more user-friendly if the Docker Compose interface opened in a new window or tab. Currently, when opened, it expands downward, requiring users to scroll down the page to see what was deployed.
-
I am currently attempting to containerize my existing VM Environment by using Docker Containers for each service that is running on the VM. These services include phpBB, MediaWiki, phpMyAdmin, MariaDB, and others. I have successfully set up everything so that all the containers start correctly, and when I expose the necessary ports, the containers become accessible on the network.
Now, my objective is to create a front-end interface for these containers using Nginx, which will be configured to point to a secondary IP address, specifically 192.168.1.51 (please note that the main Unraid IP is 192.168.1.90).
Initially, I attempted to achieve this by installing Nginx-Proxy-Manager-Official as a Docker plugin. This allowed me to get the secondary IP working properly, but unfortunately, I was unable to access the other services. To overcome this challenge, I came up with the idea of deploying Nginx-Proxy-Manager-Official within the same Docker compose stack that runs all my other containers. Below, you can find the setup I have in mind:------------------- ----------------------- ----------- .---| port:80- exposed |---| host / lan can access | | container |----< ------------------- ----------------------- ----------- '_ ------------------- ----------------------- '-| 172.20.0.0/24 |---| access to 172.20.0.2 | ------------------- -----------------------I'm unsure whether this approach will achieve the desired outcome or if I am unnecessarily complicating the process.
I am posting my docker-compose.yaml file. It should work out of the box for turning up a test environment.version: "3" volumes: dbdata: networks: backend: driver: bridge ipam: config: - subnet: 172.20.0.0/24 services: nginx: container_name: Nginx-Proxy-Manager-Official image: jc21/nginx-proxy-manager:latest restart: unless-stopped ports: # These ports are in format <host-port>:<container-port> - 192.168.1.51:80:80 # Public HTTP Port - 192.168.1.51:443:443 # Public HTTPS Port - 192.168.1.51:81:81 # Admin Web Port # Add any other Stream port you want to expose # - '21:21' # FTP # Uncomment the next line if you uncomment anything in the section # environment: # Uncomment this if you want to change the location of # the SQLite DB file within the container # DB_SQLITE_FILE: "/data/database.sqlite" # Uncomment this if IPv6 is not enabled on your host # DISABLE_IPV6: 'true' volumes: - /mnt/user/appdata/Nginx-Proxy-Manager-Official/data:/data - /mnt/user/appdata/Nginx-Proxy-Manager-Official/letsencrypt:/etc/letsencrypt network_mode: br0 #networks: # - backend database: container_name: mariadb image: mariadb:latest volumes: - /mnt/user/appdata/mariadb:/var/lib/mysql environment: - MYSQL_ROOT_PASSWORD=123456 # ports: # - "3306:3306" networks: - backend mediawiki: container_name: mediawiki image: mediawiki:latest volumes: - /mnt/user/appdata/mediawiki/images:/var/www/html/images # After initial setup, download LocalSettings.php to the same directory as # this yaml and uncomment the following line and use compose to restart # the mediawiki service # - /mnt/user/appdata/mediawiki/LocalSettings.php:/var/www/html/LocalSettings.php # ports: # - "8081:80" depends_on: - database - nginx environment: MW_DB_HOST: database MW_DB_NAME: mediawiki MW_DB_USER: root MW_DB_PASSWORD: 123456 networks: - backend phpbb: container_name: phpbb image: bitnami/phpbb:latest # ports: # - "8082:8080" depends_on: - database - nginx volumes: - /mnt/user/appdata/phpbb:/bitnami/phpbb environment: - PHPBB_DATABASE_USER=root - PHPBB_DATABASE_PASSWORD=123456 - PHPBB_DATABASE_NAME=phpbb3 - PHPBB_PASSWORD=123456 - MYSQL_CLIENT_DATABASE_HOST=database - MYSQL_CLIENT_DATABASE_ROOT_PASSWORD=123456 - MYSQL_CLIENT_CREATE_DATABASE_NAME=phpbb3 networks: - backend phpmyadmin: container_name: phpmyadmin image: phpmyadmin:latest ports: - "8083:80" depends_on: - database environment: - "PMA_HOST=database" - "MYSQL_ROOT_PASSWORD=123456" networks: - backend
-
I recently added a mirror set of cache drives to my array. I ran though the process of moving my appdata to the cache. I made sure that Docker was disabled and nothing was running before changing the share and running the mover.
When mover completed I checked to make sure everything was moved successfully. However I noticed that were two directory (with files) still lefts on the disk1/appdata, binhex-plex and gitlab-ce. I did some investigation and all it appears that everything that is still left on the disk1 is all symlink with relative paths. (i.e. ../../somefile) This breaks docker images that require these files. I checked again on user/appdata and it appears that all the symlinks work from there, however when starting the Docker Image for gitlab-ce will fail to start and it looks like this is because all of the files on on the cache drive but the symlinks are on the array. With out going too much into the mover rabbit hole The only solutions that everyone seems to agree on is to copy the files manually as this issue pops up frequently.
cp -avr /mnt/disk1/appdata /mnt/cache/appdata
or
rsync -avrth --progress --dry-run //mnt/disk1/appdata/ //mnt/cache/appdata/
I guess my next question is why does mover have an issue with symlinks?
Thank you.
-
 1
1
-
 1
1
-
-
I am running into the same issue where if i try to "Compute All" most of the time it just sits and spins. just if i jump out and back into the share it becomes fully populated but its a bit hit am miss. the Shares appdata seems to be the biggest culprit of not retiring the size in a timely fashion. Two things that might be helpful if future release.
1) Have a background task that once a day collects the size and array data and stores it a file. The data in the file then can be read at the time of the page load to show the last known size. Most people don't need real time data on the shares, but would like to browse where all their data is/was at the time of the last scan
2) by having this stored in a file, if a drive is spun down, you don't need to spin it backup to see what it was. (before the drive spins down, but run the script to see the size)
in general this type of approach would just be a better experience as it gets faster feedback and if there is a need to, the enduser can always run the compute manually to update with the latest information.
-
Yeah don't do what I did, had one drive Fail, moved all the data off the drive to another drive, then replaced the First parity drive with a new (larger) drive AND then swapped the original parity drive with failed drive. If i would have removed the failed drive form the array, first, I would have been better off. Luckily I was able to recover thanks to the second parity drive, but I ended up rebuilding the first parity drive and the failed drive (now a regular data drive) I one shot.
After using Unraid for 6 months, I would like to see better (built in) logic for automating the procedure. Even something like (remove disk for array) and then have the mover reallocate the data and then remove the drive would be nice. Right now i am using unbalance to shift data around, but i feel like this logic should be built in and not relying on 3pp.
-
I have a 6TB drive that is questionable and I am looking to replace it. The Drive that I am replacing it with will be a 12TB disk, However my current Parity drive is 10TB.
What is the best strategy to swap the Parity Drive?
- Stop the Array
- Add the New Disk 12TB as Parity drive #2,
- Start the Array
- Let it rebuild
- Stop the array
- Remove the 6TB drive that is questionable
- Remove the 10TB drive from Parity drive #1,
- Add the 10TB drive back as a normal drive?
- Start the Array
- Rebuild.
Thanks
-
Is it possible to integrate a darkmode WebUI for future releases or provide instructions on how to implement from docker?
https://github.com/crash0verride11/DarkLight-qBittorent-WebUIThank you.
-
QQ or maybe a feature request or maybe I am missing something. Is there a way for Unbalance to automatically rebalance disks based upon the shares what is defined by Include/Exclude Disks? I could probably script some decent logic in bash but I am not sure I want to learn go at this time.
-
On 10/29/2020 at 11:06 PM, plantsandbinary said:
Just ran this. It doesn't work. 4 hours wasted and it didn't move a single file. God knows what it did except create a lot of read/writes. My first drive is still completely full though...
Did you uncheck the "Dry Run" before you hit move?
-
On 10/10/2020 at 11:24 PM, Jaster said:
How did you tell firefox not to do it?...
I have uBlock, uMatrix that are preventing third party scripts form executing. Disable these plugin temperately.
-
Updated the firmware and replaced the cables, same issue as soon as I try to transfer data to the drive. Keeps thoughing sector relocation counts but when I go to the sector it says its fine. IIRC when I first got this drive I had an issue where the drive failed to boot is windows and i sent it in Samsung sent it back saying there was no issues. It was at that time I replaced it with an NVME drive. So yeah I am going to call this DEAD, even if the SMART status says its OK.
-
I checked Brodcom site and it looks like they have removed an references to lsi 9207-8i other then the last manual publish in 2014. The only firmware I can find is for the Avago 9207-8i https://www.thomas-krenn.com/en/download/frame.only_content/hide_filter.1/hide_filter_serial.1/product.9983.html
mpt2sas_cm0: LSISAS2308: FWVersion(14.00.00.00), ChipRevision(0x05), BiosVersion(07.27.00.00)
-
Here is an update, I had the XFS on the cache drive fail and unmount again, but UnRaid UI still tells me that the drive is healthy.
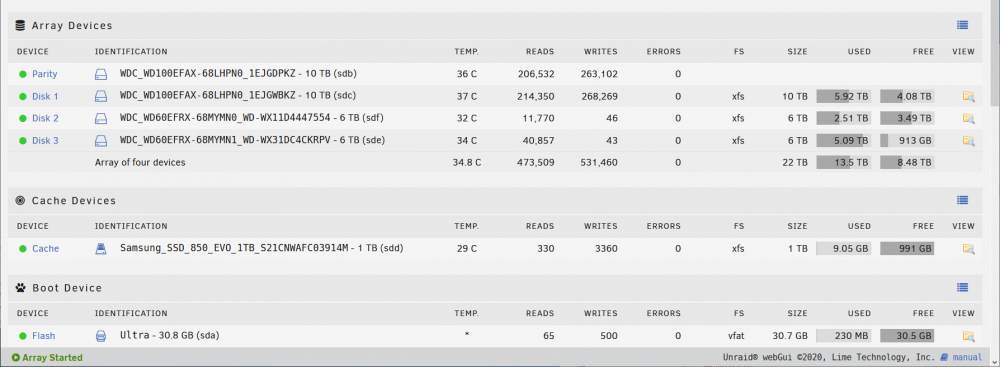
-
I got it working. The Issues was with Firefox blocking the site.
-
Disable the firewall, Setup port forwarding, enabled NAT and UPnP. Attached the Plex log, Basically its says cannot use loopback adapter 127.0.0.1 and is unable to reach plex.tv but it is able to resolve the IP
When I was running this on a windows box, I didn't have this issue. Is there some UnRaid Firewall that is causing the issue?
-
I understand that but any idea on why Plex still can not connect to the internet? It see this external IP just fine, but I am unable to claim the server
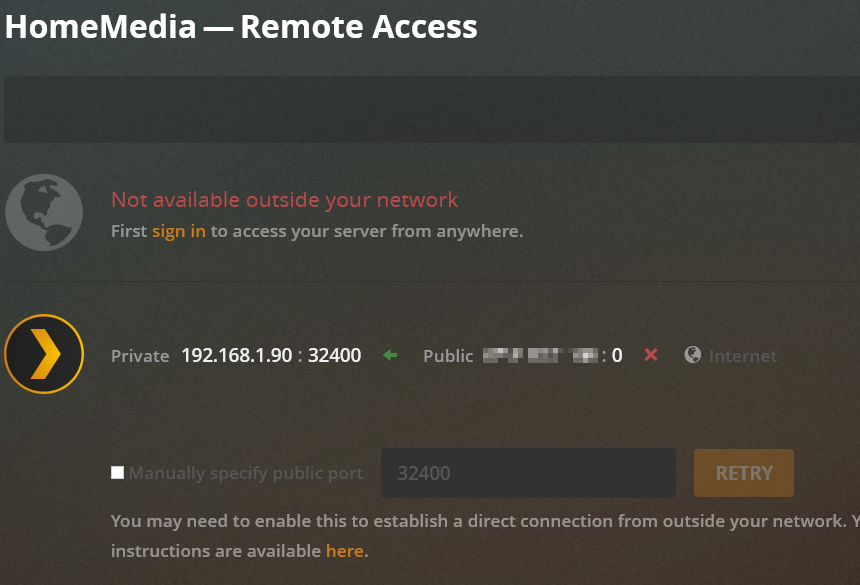
-
On 7/31/2020 at 9:10 AM, The_Athereon said:
A little help please.
My binhex-plex container isn't outputting to the network. No port mappings appear in docker.
I am having the same issue. I tired installing binhex/arch-plexpass by binhex to see if it was an issue with the other container but same issue
I tired plexinc/pms-docker by plexinc and it has the port mapping correct [IP]:[PORT] but when running it is unable to access the network as well.I disable my routers firewall (temporally) But same issue it was unable to connect to the internet.
Using binhex-qbittorrentvpn with the mapping
172.17.0.2:6881/TCP192.168.1.90:50000
172.17.0.2:6881/UDP192.168.1.90:50000
172.17.0.2:8080/TCP192.168.1.90:8080
172.17.0.2:8118/TCP192.168.1.90:8118And no problems.
-
Here is the log. to make it fail faster I scp'ed into the box and then created a folder and then tried to create a file.
Getting a consistent
Aug 8 21:50:08 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred
Aug 8 21:50:27 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred
Aug 8 21:50:38 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred
Aug 8 21:51:08 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred
Aug 8 21:51:39 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurredand when I tired to write to the drive
Aug 8 21:49:45 HomeMedia kernel: print_req_error: I/O error, dev sdd, sector 488381424
Aug 8 21:49:45 HomeMedia kernel: XFS (sdd1): writeback error on sector 488381432Now I do know that the drive had one remapped sector, but the rest of the drive is healthy, I have run extensive drive testing using Victoria hdd, and nothing else is popping up, on windows at least. The drive is 5yrs old but still has 70-80% of its write span left.
After formatting it again, i have not be able to get it to though the
Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Metadata corruption detected at xfs_buf_ioend+0x4c/0x95 [xfs], xfs_inode block 0x80 xfs_inode_buf_verify Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Unmount and run xfs_repair
Still this is highly sketchy and I should just replace the drive and be done with it.
Thanks for looking this over.
-
New RAID Card, New cables and the Drive mounts and then after a few minutes drops from the server with this error.
Aug 8 18:49:33 HomeMedia kernel: mdcmd (60): check resume Aug 8 18:49:54 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred Aug 8 18:50:24 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Metadata corruption detected at xfs_buf_ioend+0x4c/0x95 [xfs], xfs_inode block 0x80 xfs_inode_buf_verify Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Unmount and run xfs_repair Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): First 128 bytes of corrupted metadata buffer: Aug 8 18:50:24 HomeMedia kernel: 000000004dc2f79f: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 0000000066d17bd8: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 00000000420fd23e: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 000000007f612d6c: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 00000000ba2cb676: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 000000006ff199fa: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 00000000c2ac7ef7: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 0000000063a41862: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): metadata I/O error in "xfs_trans_read_buf_map" at daddr 0x80 len 32 error 117 Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): xfs_imap_to_bp: xfs_trans_read_buf() returned error -117. Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): xfs_do_force_shutdown(0x8) called from line 3399 of file fs/xfs/xfs_inode.c. Return address = 00000000ecc14961 Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Corruption of in-memory data detected. Shutting down filesystem Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Please umount the filesystem and rectify the problem(s)




[Support] binhex - qBittorrentVPN
in Docker Containers
Posted · Edited by Matthew_K
I am seeing the same issue as mdr6273, Also using NORD and I have verified that the user and the password in the credentials.conf are correct. Running on 6.11.5
I thinking the issue revolves around
2023-06-29 22:04:12 DEPRECATED OPTION: --cipher set to 'AES-256-CBC' but missing in --data-ciphers (AES-256-GCM:AES-128-GCM:CHACHA20-POLY1305). OpenVPN ignores --cipher for cipher negotiations.
...
2023-06-29 22:04:12,020 DEBG 'start-script' stdout output:
2023-06-29 22:04:12 AUTH: Received control message: AUTH_FAILED