Matthew_K
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Matthew_K
-
New RAID Card, New cables and the Drive mounts and then after a few minutes drops from the server with this error. Aug 8 18:49:33 HomeMedia kernel: mdcmd (60): check resume Aug 8 18:49:54 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred Aug 8 18:50:24 HomeMedia kernel: sd 3:0:2:0: Power-on or device reset occurred Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Metadata corruption detected at xfs_buf_ioend+0x4c/0x95 [xfs], xfs_inode block 0x80 xfs_inode_buf_verify Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Unmount and run xfs_repair Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): First 128 bytes of corrupted metadata buffer: Aug 8 18:50:24 HomeMedia kernel: 000000004dc2f79f: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 0000000066d17bd8: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 00000000420fd23e: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 000000007f612d6c: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 00000000ba2cb676: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 000000006ff199fa: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 00000000c2ac7ef7: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: 0000000063a41862: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): metadata I/O error in "xfs_trans_read_buf_map" at daddr 0x80 len 32 error 117 Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): xfs_imap_to_bp: xfs_trans_read_buf() returned error -117. Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): xfs_do_force_shutdown(0x8) called from line 3399 of file fs/xfs/xfs_inode.c. Return address = 00000000ecc14961 Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Corruption of in-memory data detected. Shutting down filesystem Aug 8 18:50:24 HomeMedia kernel: XFS (sdd1): Please umount the filesystem and rectify the problem(s)
-
Ok I think I see my issue Q) A Pre-Read operation failed and I see Pending Sectors on the SMART report. A) Pending Sectors will lead to read errors, and the Pre-Read operation will fail. To force the hard drive firmware to remap those sectors, you have to run a Preclear session with the Skip Pre-Read option checked.
-
I am just trying to understand, because on the first pass, it does this. Unraid device sdb SMART message [197]: 30-07-2020 10:16 Notice [HOMEMEDIA] - current pending sector returned to normal value WDC_WD60EFRX-68MYMN0_WD-WX11D4447554 (sdb) But then if I do a second pass suddenly the same sector pops up a bad again. I thought that typically, automatic remapping of sectors only happens when a sector is written to. In the normal operation of a hard drive, the detection and remapping of bad sectors should take place in a manner transparent to the rest of the system and in advance before data is lost. Sense the remapped sector in smart has not increase and but later down the line the same sector keeps being flagged whats going on?
-
I was running a 3 cycle six step preclear on one of my 6TB drives, I know that the drive has a pending bad sector. On the first pass, everything reported fine and it even cleared out the pending sector count. Then on the 6th step of the second pass the entire script just aborted. Can someone double check for me the reason. I am thinking that maybe I have a bad cable or my sata controller is going on top of the bad sector. I might need to pull the drive and use something like Victoria to check to see if the drive is dead, dead. mosty dead or mostly alive. Thx Jul 24 21:14:14 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Preclear Disk Version: 1.0.16 Jul 24 21:14:14 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T. info type: default Jul 24 21:14:14 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T. attrs type: default Jul 24 21:14:15 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Disk size: 6001175126016 Jul 24 21:14:15 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Disk blocks: 1465130646 Jul 24 21:14:15 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Blocks (512 bytes): 11721045168 Jul 24 21:14:15 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Block size: 4096 Jul 24 21:14:15 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Start sector: 406 Jul 24 21:14:16 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: dd if=/dev/sdb of=/dev/null bs=2097152 skip=0 count=6001175126016 conv=notrunc,noerror iflag=nocache,count_bytes,skip_bytes Jul 24 21:17:00 HomeMedia root: Fix Common Problems Version 2020.05.05 Jul 24 21:17:01 HomeMedia root: Fix Common Problems: Warning: Plugin Update Check not enabled Jul 24 21:17:01 HomeMedia root: Fix Common Problems: Warning: Docker Update Check not enabled Jul 24 21:17:10 HomeMedia root: Fix Common Problems: Other Warning: Unassigned Devices Plus not installed Jul 24 21:17:10 HomeMedia root: Fix Common Problems: Other Warning: Background notifications not enabled Jul 24 22:00:02 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 24 22:16:55 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 10% read @ 157 MB/s Jul 24 23:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 24 23:21:09 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 20% read @ 153 MB/s Jul 24 23:33:08 HomeMedia dhcpcd[1774]: br0: hardware address 40:16:7e:59:7c:10 claims 192.168.1.88 Jul 25 00:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 00:27:40 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 30% read @ 149 MB/s Jul 25 01:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 01:36:31 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 40% read @ 141 MB/s Jul 25 02:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 02:36:26 HomeMedia kernel: ata2.00: exception Emask 0x0 SAct 0x48124007 SErr 0x0 action 0x0 Jul 25 02:36:26 HomeMedia kernel: ata2.00: irq_stat 0x40000008 Jul 25 02:36:26 HomeMedia kernel: ata2.00: failed command: READ FPDMA QUEUED Jul 25 02:36:26 HomeMedia kernel: ata2.00: cmd 60/b8:f0:48:7f:60/04:00:51:01:00/40 tag 30 ncq dma 618496 in Jul 25 02:36:26 HomeMedia kernel: res 41/40:00:c8:80:60/00:00:51:01:00/00 Emask 0x409 (media error) <F> Jul 25 02:36:26 HomeMedia kernel: ata2.00: status: { DRDY ERR } Jul 25 02:36:26 HomeMedia kernel: ata2.00: error: { UNC } Jul 25 02:36:26 HomeMedia kernel: ata2.00: configured for UDMA/133 Jul 25 02:36:26 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#30 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Jul 25 02:36:26 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#30 Sense Key : 0x3 [current] Jul 25 02:36:26 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#30 ASC=0x11 ASCQ=0x4 Jul 25 02:36:26 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#30 CDB: opcode=0x88 88 00 00 00 00 01 51 60 7f 48 00 00 04 b8 00 00 Jul 25 02:36:26 HomeMedia kernel: print_req_error: I/O error, dev sdb, sector 5660245832 Jul 25 02:36:26 HomeMedia kernel: ata2: EH complete Jul 25 02:36:32 HomeMedia kernel: ata2.00: exception Emask 0x0 SAct 0x21a018 SErr 0x0 action 0x0 Jul 25 02:36:32 HomeMedia kernel: ata2.00: irq_stat 0x40000008 Jul 25 02:36:32 HomeMedia kernel: ata2.00: failed command: READ FPDMA QUEUED Jul 25 02:36:32 HomeMedia kernel: ata2.00: cmd 60/08:18:c8:80:60/00:00:51:01:00/40 tag 3 ncq dma 4096 in Jul 25 02:36:32 HomeMedia kernel: res 41/40:00:c8:80:60/00:00:51:01:00/00 Emask 0x409 (media error) <F> Jul 25 02:36:32 HomeMedia kernel: ata2.00: status: { DRDY ERR } Jul 25 02:36:32 HomeMedia kernel: ata2.00: error: { UNC } Jul 25 02:36:32 HomeMedia kernel: ata2.00: configured for UDMA/133 Jul 25 02:36:32 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#3 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Jul 25 02:36:32 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#3 Sense Key : 0x3 [current] Jul 25 02:36:32 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#3 ASC=0x11 ASCQ=0x4 Jul 25 02:36:32 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#3 CDB: opcode=0x88 88 00 00 00 00 01 51 60 80 c8 00 00 00 08 00 00 Jul 25 02:36:32 HomeMedia kernel: print_req_error: I/O error, dev sdb, sector 5660246216 Jul 25 02:36:32 HomeMedia kernel: Buffer I/O error on dev sdb, logical block 707530777, async page read Jul 25 02:36:32 HomeMedia kernel: ata2: EH complete Jul 25 02:36:38 HomeMedia kernel: ata2.00: exception Emask 0x0 SAct 0x8010000 SErr 0x0 action 0x0 Jul 25 02:36:38 HomeMedia kernel: ata2.00: irq_stat 0x40000008 Jul 25 02:36:38 HomeMedia kernel: ata2.00: failed command: READ FPDMA QUEUED Jul 25 02:36:38 HomeMedia kernel: ata2.00: cmd 60/08:d8:c8:80:60/00:00:51:01:00/40 tag 27 ncq dma 4096 in Jul 25 02:36:38 HomeMedia kernel: res 41/40:00:c8:80:60/00:00:51:01:00/00 Emask 0x409 (media error) <F> Jul 25 02:36:38 HomeMedia kernel: ata2.00: status: { DRDY ERR } Jul 25 02:36:38 HomeMedia kernel: ata2.00: error: { UNC } Jul 25 02:36:38 HomeMedia kernel: ata2.00: configured for UDMA/133 Jul 25 02:36:38 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#27 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Jul 25 02:36:38 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#27 Sense Key : 0x3 [current] Jul 25 02:36:38 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#27 ASC=0x11 ASCQ=0x4 Jul 25 02:36:38 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#27 CDB: opcode=0x88 88 00 00 00 00 01 51 60 80 c8 00 00 00 08 00 00 Jul 25 02:36:38 HomeMedia kernel: print_req_error: I/O error, dev sdb, sector 5660246216 Jul 25 02:36:38 HomeMedia kernel: Buffer I/O error on dev sdb, logical block 707530777, async page read Jul 25 02:36:38 HomeMedia kernel: ata2: EH complete Jul 25 02:49:23 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 50% read @ 134 MB/s Jul 25 03:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 03:37:11 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 25 03:40:01 HomeMedia crond[1856]: exit status 3 from user root /usr/local/sbin/mover &> /dev/null Jul 25 04:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 04:06:43 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 60% read @ 125 MB/s Jul 25 05:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 05:29:55 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 70% read @ 116 MB/s Jul 25 06:00:02 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 07:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 07:01:11 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 80% read @ 103 MB/s Jul 25 08:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 08:44:14 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 90% read @ 89 MB/s Jul 25 09:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 10:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704349696 bytes) trimmed on /dev/loop2 Jul 25 10:20:52 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 25 10:22:11 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog Jul 25 10:23:30 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 25 10:23:33 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 25 10:24:36 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog Jul 25 10:44:37 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 100% read @ 75 MB/s Jul 25 10:44:38 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: dd - read 6001175228416 of 6001175126016. Jul 25 10:44:38 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: elapsed time - 13:30:20 Jul 25 10:44:38 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: dd exit code - 0 Jul 25 10:44:38 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: openssl enc -aes-256-ctr -pass pass:'******' -nosalt < /dev/zero > /tmp/.preclear/sdb/fifo Jul 25 10:44:38 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: emptying the MBR. Jul 25 10:44:38 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd if=/tmp/.preclear/sdb/fifo of=/dev/sdb bs=2097152 seek=2097152 count=6001173028864 conv=notrunc iflag=count_bytes,nocache,fullblock oflag=seek_bytes iflag=fullblock Jul 25 10:44:38 HomeMedia rc.diskinfo[6930]: SIGHUP received, forcing refresh of disks info. Jul 25 10:44:38 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd pid [26597] Jul 25 11:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704906752 bytes) trimmed on /dev/loop2 Jul 25 11:11:53 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 25 11:44:14 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 10% erased @ 164 MB/s Jul 25 12:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704906752 bytes) trimmed on /dev/loop2 Jul 25 12:45:54 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 20% erased @ 156 MB/s Jul 25 13:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704906752 bytes) trimmed on /dev/loop2 Jul 25 13:49:11 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 30% erased @ 155 MB/s Jul 25 14:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704906752 bytes) trimmed on /dev/loop2 Jul 25 14:55:16 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 40% erased @ 148 MB/s Jul 25 15:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704906752 bytes) trimmed on /dev/loop2 Jul 25 15:54:36 HomeMedia sshd[6189]: Accepted none for root from 192.168.1.143 port 53750 ssh2 Jul 25 15:54:38 HomeMedia sshd[6777]: Accepted none for root from 192.168.1.143 port 53751 ssh2 Jul 25 16:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17704906752 bytes) trimmed on /dev/loop2 Jul 25 16:04:45 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 50% erased @ 139 MB/s Jul 25 16:27:30 HomeMedia dhcpcd[1774]: br0: hardware address 40:16:7e:59:7c:10 claims 192.168.1.88 Jul 25 16:44:08 HomeMedia kernel: docker0: port 1(vethaad2204) entered blocking state Jul 25 16:44:08 HomeMedia kernel: docker0: port 1(vethaad2204) entered disabled state Jul 25 16:44:08 HomeMedia kernel: device vethaad2204 entered promiscuous mode Jul 25 16:44:08 HomeMedia kernel: IPv6: ADDRCONF(NETDEV_UP): vethaad2204: link is not ready Jul 25 16:44:08 HomeMedia kernel: docker0: port 1(vethaad2204) entered blocking state Jul 25 16:44:08 HomeMedia kernel: docker0: port 1(vethaad2204) entered forwarding state Jul 25 16:44:08 HomeMedia kernel: docker0: port 1(vethaad2204) entered disabled state Jul 25 16:44:09 HomeMedia kernel: eth0: renamed from vethd2410e8 Jul 25 16:44:09 HomeMedia kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethaad2204: link becomes ready Jul 25 16:44:09 HomeMedia kernel: docker0: port 1(vethaad2204) entered blocking state Jul 25 16:44:09 HomeMedia kernel: docker0: port 1(vethaad2204) entered forwarding state Jul 25 16:44:09 HomeMedia kernel: IPv6: ADDRCONF(NETDEV_CHANGE): docker0: link becomes ready Jul 25 16:44:10 HomeMedia avahi-daemon[6996]: Joining mDNS multicast group on interface docker0.IPv6 with address fe80::42:5fff:fed4:2da5. Jul 25 16:44:10 HomeMedia avahi-daemon[6996]: New relevant interface docker0.IPv6 for mDNS. Jul 25 16:44:10 HomeMedia avahi-daemon[6996]: Registering new address record for fe80::42:5fff:fed4:2da5 on docker0.*. Jul 25 16:44:10 HomeMedia avahi-daemon[6996]: Joining mDNS multicast group on interface vethaad2204.IPv6 with address fe80::fcb0:a6ff:fe9b:c929. Jul 25 16:44:10 HomeMedia avahi-daemon[6996]: New relevant interface vethaad2204.IPv6 for mDNS. Jul 25 16:44:10 HomeMedia avahi-daemon[6996]: Registering new address record for fe80::fcb0:a6ff:fe9b:c929 on vethaad2204.*. Jul 25 16:44:14 HomeMedia kernel: tun: Universal TUN/TAP device driver, 1.6 Jul 25 17:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17715097600 bytes) trimmed on /dev/loop2 Jul 25 17:18:56 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 60% erased @ 131 MB/s Jul 25 17:45:27 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 25 17:49:28 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 25 18:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17715912704 bytes) trimmed on /dev/loop2 Jul 25 18:38:35 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 70% erased @ 124 MB/s Jul 25 19:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17716690944 bytes) trimmed on /dev/loop2 Jul 25 20:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17717477376 bytes) trimmed on /dev/loop2 Jul 25 20:05:53 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 80% erased @ 109 MB/s Jul 25 21:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17718259712 bytes) trimmed on /dev/loop2 Jul 25 21:43:45 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 90% erased @ 97 MB/s Jul 25 22:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17719042048 bytes) trimmed on /dev/loop2 Jul 25 23:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17719824384 bytes) trimmed on /dev/loop2 Jul 25 23:39:07 HomeMedia rc.diskinfo[6930]: SIGHUP received, forcing refresh of disks info. Jul 25 23:39:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd - wrote 6001175126016 of 6001175126016. Jul 25 23:39:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: elapsed time - 12:54:29 Jul 25 23:39:09 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd exit code - 0 Jul 25 23:39:09 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: emptying the MBR. Jul 25 23:39:09 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd if=/dev/zero of=/dev/sdb bs=2097152 seek=2097152 count=6001173028864 conv=notrunc iflag=count_bytes,nocache,fullblock oflag=seek_bytes Jul 25 23:39:09 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd pid [25529] Jul 26 00:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17721196544 bytes) trimmed on /dev/loop2 Jul 26 00:38:43 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 10% zeroed @ 167 MB/s Jul 26 00:45:40 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 26 00:48:01 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 26 01:00:02 HomeMedia root: /var/lib/docker: 16.5 GiB (17738829824 bytes) trimmed on /dev/loop2 Jul 26 01:04:54 HomeMedia kernel: vethd2410e8: renamed from eth0 Jul 26 01:04:54 HomeMedia kernel: docker0: port 1(vethaad2204) entered disabled state Jul 26 01:04:54 HomeMedia avahi-daemon[6996]: Interface vethaad2204.IPv6 no longer relevant for mDNS. Jul 26 01:04:54 HomeMedia avahi-daemon[6996]: Leaving mDNS multicast group on interface vethaad2204.IPv6 with address fe80::fcb0:a6ff:fe9b:c929. Jul 26 01:04:54 HomeMedia kernel: docker0: port 1(vethaad2204) entered disabled state Jul 26 01:04:54 HomeMedia kernel: device vethaad2204 left promiscuous mode Jul 26 01:04:54 HomeMedia kernel: docker0: port 1(vethaad2204) entered disabled state Jul 26 01:04:54 HomeMedia avahi-daemon[6996]: Withdrawing address record for fe80::fcb0:a6ff:fe9b:c929 on vethaad2204. Jul 26 01:04:58 HomeMedia kernel: docker0: port 1(veth6be567d) entered blocking state Jul 26 01:04:58 HomeMedia kernel: docker0: port 1(veth6be567d) entered disabled state Jul 26 01:04:58 HomeMedia kernel: device veth6be567d entered promiscuous mode Jul 26 01:04:58 HomeMedia kernel: IPv6: ADDRCONF(NETDEV_UP): veth6be567d: link is not ready Jul 26 01:04:58 HomeMedia kernel: docker0: port 1(veth6be567d) entered blocking state Jul 26 01:04:58 HomeMedia kernel: docker0: port 1(veth6be567d) entered forwarding state Jul 26 01:04:58 HomeMedia kernel: docker0: port 1(veth6be567d) entered disabled state Jul 26 01:04:59 HomeMedia kernel: eth0: renamed from vetha6de50d Jul 26 01:04:59 HomeMedia kernel: IPv6: ADDRCONF(NETDEV_CHANGE): veth6be567d: link becomes ready Jul 26 01:04:59 HomeMedia kernel: docker0: port 1(veth6be567d) entered blocking state Jul 26 01:04:59 HomeMedia kernel: docker0: port 1(veth6be567d) entered forwarding state Jul 26 01:05:01 HomeMedia avahi-daemon[6996]: Joining mDNS multicast group on interface veth6be567d.IPv6 with address fe80::c0d4:5dff:fe98:eb91. Jul 26 01:05:01 HomeMedia avahi-daemon[6996]: New relevant interface veth6be567d.IPv6 for mDNS. Jul 26 01:05:01 HomeMedia avahi-daemon[6996]: Registering new address record for fe80::c0d4:5dff:fe98:eb91 on veth6be567d.*. Jul 26 01:40:44 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 20% zeroed @ 162 MB/s Jul 26 02:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17744506880 bytes) trimmed on /dev/loop2 Jul 26 02:44:33 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 30% zeroed @ 155 MB/s Jul 26 03:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17745416192 bytes) trimmed on /dev/loop2 Jul 26 03:40:01 HomeMedia crond[1856]: exit status 3 from user root /usr/local/sbin/mover &> /dev/null Jul 26 03:40:06 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 26 03:40:15 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 26 03:50:46 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 40% zeroed @ 148 MB/s Jul 26 04:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17746325504 bytes) trimmed on /dev/loop2 Jul 26 05:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17747079168 bytes) trimmed on /dev/loop2 Jul 26 05:00:29 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 50% zeroed @ 141 MB/s Jul 26 06:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17747861504 bytes) trimmed on /dev/loop2 Jul 26 06:14:40 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 60% zeroed @ 131 MB/s Jul 26 07:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17748611072 bytes) trimmed on /dev/loop2 Jul 26 07:34:06 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 70% zeroed @ 121 MB/s Jul 26 08:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17749327872 bytes) trimmed on /dev/loop2 Jul 26 09:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17750073344 bytes) trimmed on /dev/loop2 Jul 26 09:01:18 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 80% zeroed @ 108 MB/s Jul 26 09:34:10 HomeMedia sshd[22329]: Accepted none for root from 192.168.1.143 port 58327 ssh2 Jul 26 09:37:33 HomeMedia sshd[23264]: Accepted none for root from 192.168.1.143 port 58386 ssh2 Jul 26 10:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17751019520 bytes) trimmed on /dev/loop2 Jul 26 10:39:12 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 90% zeroed @ 96 MB/s Jul 26 11:00:02 HomeMedia root: /var/lib/docker: 16.5 GiB (17751801856 bytes) trimmed on /dev/loop2 Jul 26 12:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17752649728 bytes) trimmed on /dev/loop2 Jul 26 12:34:18 HomeMedia rc.diskinfo[6930]: SIGHUP received, forcing refresh of disks info. Jul 26 12:34:18 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd - wrote 6001175126016 of 6001175126016. Jul 26 12:34:18 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: elapsed time - 12:55:08 Jul 26 12:34:19 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd exit code - 0 Jul 26 12:34:19 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Writing signature: 0 0 2 0 0 255 255 255 1 0 0 0 255 255 255 255 Jul 26 12:34:20 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: verifying the beggining of the disk. Jul 26 12:34:20 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: cmp /tmp/.preclear/sdb/fifo /dev/zero Jul 26 12:34:20 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd if=/dev/sdb of=/tmp/.preclear/sdb/fifo count=2096640 skip=512 conv=notrunc iflag=nocache,count_bytes,skip_bytes Jul 26 12:34:21 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: verifying the rest of the disk. Jul 26 12:34:21 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: cmp /tmp/.preclear/sdb/fifo /dev/zero Jul 26 12:34:21 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd if=/dev/sdb of=/tmp/.preclear/sdb/fifo bs=2097152 skip=2097152 count=6001173028864 conv=notrunc iflag=nocache,count_bytes,skip_bytes Jul 26 13:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17753464832 bytes) trimmed on /dev/loop2 Jul 26 13:36:59 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 10% verified @ 158 MB/s Jul 26 14:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17754345472 bytes) trimmed on /dev/loop2 Jul 26 14:41:16 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 20% verified @ 153 MB/s Jul 26 15:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17755324416 bytes) trimmed on /dev/loop2 Jul 26 15:47:34 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 30% verified @ 148 MB/s Jul 26 16:00:01 HomeMedia root: /var/lib/docker: 16.5 GiB (17756303360 bytes) trimmed on /dev/loop2 Jul 26 16:56:29 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 40% verified @ 141 MB/s Jul 26 17:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17760067584 bytes) trimmed on /dev/loop2 Jul 26 18:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17761505280 bytes) trimmed on /dev/loop2 Jul 26 18:09:10 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 50% verified @ 133 MB/s Jul 26 19:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17762320384 bytes) trimmed on /dev/loop2 Jul 26 19:26:30 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 60% verified @ 125 MB/s Jul 26 20:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17763102720 bytes) trimmed on /dev/loop2 Jul 26 20:49:50 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 70% verified @ 116 MB/s Jul 26 21:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17763852288 bytes) trimmed on /dev/loop2 Jul 26 22:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17764700160 bytes) trimmed on /dev/loop2 Jul 26 22:20:57 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 80% verified @ 103 MB/s Jul 26 23:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17765478400 bytes) trimmed on /dev/loop2 Jul 27 00:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17766260736 bytes) trimmed on /dev/loop2 Jul 27 00:04:02 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 90% verified @ 89 MB/s Jul 27 01:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17767206912 bytes) trimmed on /dev/loop2 Jul 27 02:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17769238528 bytes) trimmed on /dev/loop2 Jul 27 02:04:07 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd - read 6001175126016 of 6001175126016. Jul 27 02:04:07 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: elapsed time - 13:29:45 Jul 27 02:04:07 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd exit code - 0 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 5 Reallocated_Sector_Ct 0 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 9 Power_On_Hours 33475 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 194 Temperature_Celsius 33 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 196 Reallocated_Event_Count 0 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 197 Current_Pending_Sector 0 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 198 Offline_Uncorrectable 0 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 199 UDMA_CRC_Error_Count 0 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Cycle: elapsed time: 52:49:52 Jul 27 02:04:08 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: dd if=/dev/sdb of=/dev/null bs=2097152 skip=0 count=6001175126016 conv=notrunc,noerror iflag=nocache,count_bytes,skip_bytes Jul 27 03:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17770086400 bytes) trimmed on /dev/loop2 Jul 27 03:06:46 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 10% read @ 158 MB/s Jul 27 03:40:01 HomeMedia crond[1856]: exit status 3 from user root /usr/local/sbin/mover &> /dev/null Jul 27 04:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17770930176 bytes) trimmed on /dev/loop2 Jul 27 04:10:56 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 20% read @ 153 MB/s Jul 27 05:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17771646976 bytes) trimmed on /dev/loop2 Jul 27 05:17:23 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 30% read @ 149 MB/s Jul 27 06:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17772429312 bytes) trimmed on /dev/loop2 Jul 27 06:26:09 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 40% read @ 141 MB/s Jul 27 07:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17773215744 bytes) trimmed on /dev/loop2 Jul 27 07:38:50 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 50% read @ 134 MB/s Jul 27 08:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17773998080 bytes) trimmed on /dev/loop2 Jul 27 08:56:14 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 60% read @ 126 MB/s Jul 27 09:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17774780416 bytes) trimmed on /dev/loop2 Jul 27 10:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17775562752 bytes) trimmed on /dev/loop2 Jul 27 10:19:28 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 70% read @ 115 MB/s Jul 27 11:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17780236288 bytes) trimmed on /dev/loop2 Jul 27 11:50:50 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 80% read @ 103 MB/s Jul 27 12:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17780883456 bytes) trimmed on /dev/loop2 Jul 27 12:11:24 HomeMedia sshd[8748]: Accepted none for root from 192.168.1.143 port 63773 ssh2 Jul 27 12:11:26 HomeMedia sshd[8814]: Accepted none for root from 192.168.1.143 port 63774 ssh2 Jul 27 13:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17781600256 bytes) trimmed on /dev/loop2 Jul 27 13:33:58 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 90% read @ 90 MB/s Jul 27 14:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17782419456 bytes) trimmed on /dev/loop2 Jul 27 15:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17783201792 bytes) trimmed on /dev/loop2 Jul 27 15:14:21 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 27 15:34:15 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: progress - 100% read @ 75 MB/s Jul 27 15:34:16 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: dd - read 6001177223168 of 6001175126016. Jul 27 15:34:16 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: elapsed time - 13:30:06 Jul 27 15:34:16 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pre-Read: dd exit code - 0 Jul 27 15:34:17 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: openssl enc -aes-256-ctr -pass pass:'******' -nosalt < /dev/zero > /tmp/.preclear/sdb/fifo Jul 27 15:34:17 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: emptying the MBR. Jul 27 15:34:17 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd if=/tmp/.preclear/sdb/fifo of=/dev/sdb bs=2097152 seek=2097152 count=6001173028864 conv=notrunc iflag=count_bytes,nocache,fullblock oflag=seek_bytes iflag=fullblock Jul 27 15:34:17 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd pid [19284] Jul 27 15:34:17 HomeMedia rc.diskinfo[6930]: SIGHUP received, forcing refresh of disks info. Jul 27 16:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17783984128 bytes) trimmed on /dev/loop2 Jul 27 16:33:48 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 10% erased @ 166 MB/s Jul 27 17:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17786535936 bytes) trimmed on /dev/loop2 Jul 27 17:35:27 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 20% erased @ 156 MB/s Jul 27 18:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17787322368 bytes) trimmed on /dev/loop2 Jul 27 18:39:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 30% erased @ 156 MB/s Jul 27 19:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17788104704 bytes) trimmed on /dev/loop2 Jul 27 19:45:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 40% erased @ 147 MB/s Jul 27 20:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17788788736 bytes) trimmed on /dev/loop2 Jul 27 20:54:42 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 50% erased @ 140 MB/s Jul 27 21:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17789960192 bytes) trimmed on /dev/loop2 Jul 27 22:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17790742528 bytes) trimmed on /dev/loop2 Jul 27 22:08:53 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 60% erased @ 131 MB/s Jul 27 23:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17792118784 bytes) trimmed on /dev/loop2 Jul 27 23:28:21 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 70% erased @ 122 MB/s Jul 28 00:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17797292032 bytes) trimmed on /dev/loop2 Jul 28 00:55:31 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 80% erased @ 108 MB/s Jul 28 01:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17798078464 bytes) trimmed on /dev/loop2 Jul 28 02:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17800036352 bytes) trimmed on /dev/loop2 Jul 28 02:33:43 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: progress - 90% erased @ 97 MB/s Jul 28 03:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17800622080 bytes) trimmed on /dev/loop2 Jul 28 03:40:01 HomeMedia crond[1856]: exit status 3 from user root /usr/local/sbin/mover &> /dev/null Jul 28 04:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17801142272 bytes) trimmed on /dev/loop2 Jul 28 04:28:13 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Pause (hdparm run time: 24s) Jul 28 04:28:13 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Paused Jul 28 04:28:25 HomeMedia preclear_disk_WD-WX11D4447554[24260]: killing hdparm with pid 20606 - probably stalled... Jul 28 04:28:37 HomeMedia preclear_disk_WD-WX11D4447554[24260]: killing hdparm with pid 20606 - probably stalled... Jul 28 04:28:49 HomeMedia preclear_disk_WD-WX11D4447554[24260]: killing hdparm with pid 20606 - probably stalled... Jul 28 04:28:56 HomeMedia rc.diskinfo[6930]: SIGHUP received, forcing refresh of disks info. Jul 28 04:29:02 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Resumed Jul 28 04:29:02 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd - wrote 6001175126016 of 6001175126016. Jul 28 04:29:02 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: elapsed time - 12:53:56 Jul 28 04:29:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Erasing: dd exit code - 0 Jul 28 04:29:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: emptying the MBR. Jul 28 04:29:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd if=/dev/zero of=/dev/sdb bs=2097152 seek=2097152 count=6001173028864 conv=notrunc iflag=count_bytes,nocache,fullblock oflag=seek_bytes Jul 28 04:29:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd pid [975] Jul 28 04:29:03 HomeMedia rc.diskinfo[6930]: SIGHUP received, forcing refresh of disks info. Jul 28 05:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17801728000 bytes) trimmed on /dev/loop2 Jul 28 05:28:37 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 10% zeroed @ 165 MB/s Jul 28 06:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17802412032 bytes) trimmed on /dev/loop2 Jul 28 06:30:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 20% zeroed @ 152 MB/s Jul 28 07:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17803190272 bytes) trimmed on /dev/loop2 Jul 28 07:33:41 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 30% zeroed @ 155 MB/s Jul 28 08:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17803907072 bytes) trimmed on /dev/loop2 Jul 28 08:39:36 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 40% zeroed @ 148 MB/s Jul 28 09:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17804693504 bytes) trimmed on /dev/loop2 Jul 28 09:48:58 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 50% zeroed @ 141 MB/s Jul 28 10:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17805410304 bytes) trimmed on /dev/loop2 Jul 28 10:31:38 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 28 11:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17806061568 bytes) trimmed on /dev/loop2 Jul 28 11:03:07 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 60% zeroed @ 132 MB/s Jul 28 12:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17806708736 bytes) trimmed on /dev/loop2 Jul 28 12:22:11 HomeMedia kernel: vetha6de50d: renamed from eth0 Jul 28 12:22:11 HomeMedia kernel: docker0: port 1(veth6be567d) entered disabled state Jul 28 12:22:11 HomeMedia avahi-daemon[6996]: Interface veth6be567d.IPv6 no longer relevant for mDNS. Jul 28 12:22:11 HomeMedia avahi-daemon[6996]: Leaving mDNS multicast group on interface veth6be567d.IPv6 with address fe80::c0d4:5dff:fe98:eb91. Jul 28 12:22:11 HomeMedia kernel: docker0: port 1(veth6be567d) entered disabled state Jul 28 12:22:11 HomeMedia kernel: device veth6be567d left promiscuous mode Jul 28 12:22:11 HomeMedia kernel: docker0: port 1(veth6be567d) entered disabled state Jul 28 12:22:11 HomeMedia avahi-daemon[6996]: Withdrawing address record for fe80::c0d4:5dff:fe98:eb91 on veth6be567d. Jul 28 12:22:15 HomeMedia kernel: docker0: port 1(vethe465e3e) entered blocking state Jul 28 12:22:15 HomeMedia kernel: docker0: port 1(vethe465e3e) entered disabled state Jul 28 12:22:15 HomeMedia kernel: device vethe465e3e entered promiscuous mode Jul 28 12:22:15 HomeMedia kernel: IPv6: ADDRCONF(NETDEV_UP): vethe465e3e: link is not ready Jul 28 12:22:15 HomeMedia kernel: docker0: port 1(vethe465e3e) entered blocking state Jul 28 12:22:15 HomeMedia kernel: docker0: port 1(vethe465e3e) entered forwarding state Jul 28 12:22:15 HomeMedia kernel: docker0: port 1(vethe465e3e) entered disabled state Jul 28 12:22:16 HomeMedia kernel: eth0: renamed from vetha5ae19a Jul 28 12:22:16 HomeMedia kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethe465e3e: link becomes ready Jul 28 12:22:16 HomeMedia kernel: docker0: port 1(vethe465e3e) entered blocking state Jul 28 12:22:16 HomeMedia kernel: docker0: port 1(vethe465e3e) entered forwarding state Jul 28 12:22:17 HomeMedia avahi-daemon[6996]: Joining mDNS multicast group on interface vethe465e3e.IPv6 with address fe80::d0c1:1aff:fe44:17d9. Jul 28 12:22:17 HomeMedia avahi-daemon[6996]: New relevant interface vethe465e3e.IPv6 for mDNS. Jul 28 12:22:17 HomeMedia avahi-daemon[6996]: Registering new address record for fe80::d0c1:1aff:fe44:17d9 on vethe465e3e.*. Jul 28 12:22:21 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 70% zeroed @ 126 MB/s Jul 28 13:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17817698304 bytes) trimmed on /dev/loop2 Jul 28 13:49:26 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 80% zeroed @ 107 MB/s Jul 28 14:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17818218496 bytes) trimmed on /dev/loop2 Jul 28 15:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17818800128 bytes) trimmed on /dev/loop2 Jul 28 15:27:35 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: progress - 90% zeroed @ 96 MB/s Jul 28 16:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17819451392 bytes) trimmed on /dev/loop2 Jul 28 17:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17821839360 bytes) trimmed on /dev/loop2 Jul 28 17:22:38 HomeMedia rc.diskinfo[6930]: SIGHUP received, forcing refresh of disks info. Jul 28 17:22:39 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd - wrote 6001175126016 of 6001175126016. Jul 28 17:22:39 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: elapsed time - 12:53:35 Jul 28 17:22:40 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Zeroing: dd exit code - 0 Jul 28 17:22:41 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Writing signature: 0 0 2 0 0 255 255 255 1 0 0 0 255 255 255 255 Jul 28 17:22:41 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: verifying the beggining of the disk. Jul 28 17:22:41 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: cmp /tmp/.preclear/sdb/fifo /dev/zero Jul 28 17:22:41 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd if=/dev/sdb of=/tmp/.preclear/sdb/fifo count=2096640 skip=512 conv=notrunc iflag=nocache,count_bytes,skip_bytes Jul 28 17:22:43 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: verifying the rest of the disk. Jul 28 17:22:43 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: cmp /tmp/.preclear/sdb/fifo /dev/zero Jul 28 17:22:43 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd if=/dev/sdb of=/tmp/.preclear/sdb/fifo bs=2097152 skip=2097152 count=6001173028864 conv=notrunc iflag=nocache,count_bytes,skip_bytes Jul 28 18:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17822490624 bytes) trimmed on /dev/loop2 Jul 28 18:25:31 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 10% verified @ 157 MB/s Jul 28 19:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17823145984 bytes) trimmed on /dev/loop2 Jul 28 19:30:15 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 20% verified @ 152 MB/s Jul 28 20:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17823793152 bytes) trimmed on /dev/loop2 Jul 28 20:36:40 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 30% verified @ 148 MB/s Jul 28 21:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17824444416 bytes) trimmed on /dev/loop2 Jul 28 21:11:34 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_24260 Jul 28 21:46:07 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 40% verified @ 141 MB/s Jul 28 22:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17825030144 bytes) trimmed on /dev/loop2 Jul 28 22:59:10 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 50% verified @ 132 MB/s Jul 28 23:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17825681408 bytes) trimmed on /dev/loop2 Jul 29 00:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17826856960 bytes) trimmed on /dev/loop2 Jul 29 00:17:09 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 60% verified @ 123 MB/s Jul 29 00:49:40 HomeMedia kernel: vetha5ae19a: renamed from eth0 Jul 29 00:49:40 HomeMedia kernel: docker0: port 1(vethe465e3e) entered disabled state Jul 29 00:49:40 HomeMedia avahi-daemon[6996]: Interface vethe465e3e.IPv6 no longer relevant for mDNS. Jul 29 00:49:40 HomeMedia avahi-daemon[6996]: Leaving mDNS multicast group on interface vethe465e3e.IPv6 with address fe80::d0c1:1aff:fe44:17d9. Jul 29 00:49:40 HomeMedia kernel: docker0: port 1(vethe465e3e) entered disabled state Jul 29 00:49:40 HomeMedia kernel: device vethe465e3e left promiscuous mode Jul 29 00:49:40 HomeMedia kernel: docker0: port 1(vethe465e3e) entered disabled state Jul 29 00:49:40 HomeMedia avahi-daemon[6996]: Withdrawing address record for fe80::d0c1:1aff:fe44:17d9 on vethe465e3e. Jul 29 00:59:19 HomeMedia dhcpcd[1774]: br0: hardware address 40:16:7e:59:7c:10 claims 192.168.1.88 Jul 29 01:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 01:40:57 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: progress - 70% verified @ 115 MB/s Jul 29 02:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 03:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 03:10:49 HomeMedia kernel: ata2.00: exception Emask 0x0 SAct 0xf0200120 SErr 0x0 action 0x0 Jul 29 03:10:49 HomeMedia kernel: ata2.00: irq_stat 0x40000008 Jul 29 03:10:49 HomeMedia kernel: ata2.00: failed command: READ FPDMA QUEUED Jul 29 03:10:49 HomeMedia kernel: ata2.00: cmd 60/c0:e0:40:af:7f/04:00:2d:02:00/40 tag 28 ncq dma 622592 in Jul 29 03:10:49 HomeMedia kernel: res 41/40:00:e8:b3:7f/00:00:2d:02:00/00 Emask 0x409 (media error) <F> Jul 29 03:10:49 HomeMedia kernel: ata2.00: status: { DRDY ERR } Jul 29 03:10:49 HomeMedia kernel: ata2.00: error: { UNC } Jul 29 03:10:49 HomeMedia kernel: ata2.00: configured for UDMA/133 Jul 29 03:10:49 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#28 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Jul 29 03:10:49 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#28 Sense Key : 0x3 [current] Jul 29 03:10:49 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#28 ASC=0x11 ASCQ=0x4 Jul 29 03:10:49 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#28 CDB: opcode=0x88 88 00 00 00 00 02 2d 7f af 40 00 00 04 c0 00 00 Jul 29 03:10:49 HomeMedia kernel: print_req_error: I/O error, dev sdb, sector 9353277248 Jul 29 03:10:49 HomeMedia kernel: ata2: EH complete Jul 29 03:10:56 HomeMedia kernel: ata2.00: exception Emask 0x0 SAct 0x400003e0 SErr 0x0 action 0x0 Jul 29 03:10:56 HomeMedia kernel: ata2.00: irq_stat 0x40000008 Jul 29 03:10:56 HomeMedia kernel: ata2.00: failed command: READ FPDMA QUEUED Jul 29 03:10:56 HomeMedia kernel: ata2.00: cmd 60/08:30:e8:b3:7f/00:00:2d:02:00/40 tag 6 ncq dma 4096 in Jul 29 03:10:56 HomeMedia kernel: res 41/40:00:e8:b3:7f/00:00:2d:02:00/00 Emask 0x409 (media error) <F> Jul 29 03:10:56 HomeMedia kernel: ata2.00: status: { DRDY ERR } Jul 29 03:10:56 HomeMedia kernel: ata2.00: error: { UNC } Jul 29 03:10:56 HomeMedia kernel: ata2.00: configured for UDMA/133 Jul 29 03:10:56 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#6 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Jul 29 03:10:56 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#6 Sense Key : 0x3 [current] Jul 29 03:10:56 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#6 ASC=0x11 ASCQ=0x4 Jul 29 03:10:56 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#6 CDB: opcode=0x88 88 00 00 00 00 02 2d 7f b3 e8 00 00 00 08 00 00 Jul 29 03:10:56 HomeMedia kernel: print_req_error: I/O error, dev sdb, sector 9353278440 Jul 29 03:10:56 HomeMedia kernel: Buffer I/O error on dev sdb, logical block 1169159805, async page read Jul 29 03:10:56 HomeMedia kernel: ata2: EH complete Jul 29 03:11:02 HomeMedia kernel: ata2.00: exception Emask 0x0 SAct 0x42000 SErr 0x0 action 0x0 Jul 29 03:11:02 HomeMedia kernel: ata2.00: irq_stat 0x40000008 Jul 29 03:11:02 HomeMedia kernel: ata2.00: failed command: READ FPDMA QUEUED Jul 29 03:11:02 HomeMedia kernel: ata2.00: cmd 60/08:90:e8:b3:7f/00:00:2d:02:00/40 tag 18 ncq dma 4096 in Jul 29 03:11:02 HomeMedia kernel: res 41/40:00:e8:b3:7f/00:00:2d:02:00/00 Emask 0x409 (media error) <F> Jul 29 03:11:02 HomeMedia kernel: ata2.00: status: { DRDY ERR } Jul 29 03:11:02 HomeMedia kernel: ata2.00: error: { UNC } Jul 29 03:11:02 HomeMedia kernel: ata2.00: configured for UDMA/133 Jul 29 03:11:02 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#18 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Jul 29 03:11:02 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#18 Sense Key : 0x3 [current] Jul 29 03:11:02 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#18 ASC=0x11 ASCQ=0x4 Jul 29 03:11:02 HomeMedia kernel: sd 2:0:0:0: [sdb] tag#18 CDB: opcode=0x88 88 00 00 00 00 02 2d 7f b3 e8 00 00 00 08 00 00 Jul 29 03:11:02 HomeMedia kernel: print_req_error: I/O error, dev sdb, sector 9353278440 Jul 29 03:11:02 HomeMedia kernel: Buffer I/O error on dev sdb, logical block 1169159805, async page read Jul 29 03:11:02 HomeMedia kernel: ata2: EH complete Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd - read 4788878561280 of 6001175126016. Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: elapsed time - 9:48:21 Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd command failed, exit code [1]. Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 4782968274944 bytes (4.8 TB, 4.4 TiB) copied, 35221.9 s, 136 MB/s Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2281330+0 records in Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2281329+0 records out Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 4784293675008 bytes (4.8 TB, 4.4 TiB) copied, 35234.8 s, 136 MB/s Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2281962+0 records in Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2281961+0 records out Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 4785619075072 bytes (4.8 TB, 4.4 TiB) copied, 35247.7 s, 136 MB/s Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2282592+0 records in Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2282591+0 records out Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 4786940280832 bytes (4.8 TB, 4.4 TiB) copied, 35260.5 s, 136 MB/s Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2283224+0 records in Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2283223+0 records out Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 4788265680896 bytes (4.8 TB, 4.4 TiB) copied, 35273.5 s, 136 MB/s Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2283514+0 records in Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2283513+0 records out Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 4788873854976 bytes (4.8 TB, 4.4 TiB) copied, 35285.8 s, 136 MB/s Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: dd: error reading '/dev/sdb': Input/output error Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2283514+1 records in Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 2283514+1 records out Jul 29 03:11:03 HomeMedia preclear_disk_WD-WX11D4447554[24260]: Post-Read: dd output: 4788876464128 bytes (4.8 TB, 4.4 TiB) copied, 35298.4 s, 136 MB/s Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 5 Reallocated_Sector_Ct 0 Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 9 Power_On_Hours 33524 Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 194 Temperature_Celsius 33 Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 196 Reallocated_Event_Count 0 Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 197 Current_Pending_Sector 1 Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 198 Offline_Uncorrectable 0 Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: S.M.A.R.T.: 199 UDMA_CRC_Error_Count 0 Jul 29 03:11:04 HomeMedia preclear_disk_WD-WX11D4447554[24260]: error encountered, exiting... Jul 29 03:40:01 HomeMedia crond[1856]: exit status 3 from user root /usr/local/sbin/mover &> /dev/null Jul 29 04:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 05:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 06:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 07:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 08:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 09:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 09:32:03 HomeMedia dhcpcd[1774]: br0: hardware address 40:16:7e:59:7c:10 claims 192.168.1.88 Jul 29 10:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 10:22:50 HomeMedia dhcpcd[1774]: br0: hardware address 40:16:7e:59:7c:10 claims 192.168.1.88 Jul 29 11:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 11:10:07 HomeMedia statistics.sender: sending report: Jul 29 11:10:08 HomeMedia statistics.sender: report sent. Jul 29 11:11:42 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --erase-clear --cycles 1 --no-prompt /dev/sdb Jul 29 11:11:42 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Preclear Disk Version: 1.0.16 Jul 29 11:11:42 HomeMedia preclear_disk_WD-WX11D4447554[18694]: S.M.A.R.T. info type: default Jul 29 11:11:42 HomeMedia preclear_disk_WD-WX11D4447554[18694]: S.M.A.R.T. attrs type: default Jul 29 11:11:43 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Disk size: 6001175126016 Jul 29 11:11:43 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Disk blocks: 1465130646 Jul 29 11:11:43 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Blocks (512 bytes): 11721045168 Jul 29 11:11:43 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Block size: 4096 Jul 29 11:11:43 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Start sector: 0 Jul 29 11:11:44 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Pre-Read: dd if=/dev/sdb of=/dev/null bs=2097152 skip=0 count=6001175126016 conv=notrunc,noerror iflag=nocache,count_bytes,skip_bytes Jul 29 11:12:03 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_18694 Jul 29 11:12:14 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_18694 Jul 29 11:12:20 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 29 12:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 12:14:28 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Pre-Read: progress - 10% read @ 157 MB/s Jul 29 13:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 13:18:51 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Pre-Read: progress - 20% read @ 153 MB/s Jul 29 13:41:01 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_18694 Jul 29 13:41:05 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 29 14:00:01 HomeMedia root: /var/lib/docker: 16.6 GiB (17844695040 bytes) trimmed on /dev/loop2 Jul 29 14:01:13 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 29 14:25:11 HomeMedia preclear_disk_WD-WX11D4447554[18694]: Pre-Read: progress - 30% read @ 149 MB/s Jul 29 14:30:02 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 29 14:30:24 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log Jul 29 14:32:25 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_18694 Jul 29 14:32:38 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 29 14:33:43 HomeMedia dhcpcd[1774]: br0: hardware address 40:16:7e:59:7c:10 claims 192.168.1.88 Jul 29 14:35:58 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog Jul 29 14:36:45 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/disk_log sdb Jul 29 14:37:27 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/preclear.disk/script/tail_log preclear_disk_WD-WX11D4447554_18694 Jul 29 14:37:35 HomeMedia emhttpd: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog
-
I moved the drive to a different system and all the issues save for the one sector issue resolved (which the drive successfully remapped). I tried swapping out the cable first and it didn't do anything, which makes me wonder if its the sata port on the board. I will try some more swapping soon as I have the ability to. In the middle of playing musical drives moving all my data to the server. Thank for the reply.
-
So I am in the process of setting up a new unraid box, and moving data off an old ESXi VM with Win2016 NTFS Mounts I am trying to repurpose some of the hardware from the ESXi host. I ended up getting 2 WDC_WD100EFAX which my plan was to make them parity drives, that was right before the all my WDC_WD60EFRX started to throw sector errors. Because this new setup will have more than 6 drives I wanted to know if from power users what you would recommend for a Storage Controller card to add to the system. The LSI Broadcom SAS 9300-8i and LSI Logic SAS 9207-8i come up a lot and other then being a later version not 100% sure what the difference is. On top of that I am looking at getting a replacement for the Samsung SSD 850 EVO 1TB I was planning to use as its gone to crap. TL;DR Recommendation for 1x Storage Controller Card and cables 1x replacement for Samsung SSD 850 EVO 1TB Existing Hardware ASUSTeK COMPUTER INC. Z97-PRO(Wi-Fi ac) Version Rev 1.xx Intel® Core™ i7-4790K CPU @ 4.00GHz 32 GiB DDR3 (max. installable capacity 32 GiB) Fractal Design Define R6 Case, so I have lots of room WDC_WD100EFAX 10TB New WDC_WD100EFAX 10TB New WDC_WD60EFRX 6TB OK but 4 yrs old WDC_WD60EFRX 6TB OK but 4 yrs old WDC_WD60EFRX 6TB Questionable 5 yrs old with (Current pending sector 1) WDC_WD60EFRX 6TB Questionable 5 yrs old with (Current pending sector 1) WDC_WD60EFRX 6TB Very Very Bad Now Samsung SSD 850 EVO 1TB Very Very Bad Now Thank you.
-
Ok got my setup back up a running. I tried moving the data off the drive using the mover, but it did do anything. so I resorted to rsync to move the one docker config file i cared about. and now I a running preclear to see if it will toss any more errors. I also swapped sata cables, but that didnt seem to do anything after the reboot. Jul 23 20:50:02 Tower kernel: ata1: SATA max UDMA/133 abar m2048@0xdfe39000 port 0xdfe39100 irq 39 Jul 23 20:50:02 Tower kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jul 23 20:50:02 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 20:50:02 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 20:50:02 Tower kernel: ata1.00: ATA-9: Samsung SSD 850 EVO 1TB, S21CNWAFC03914M, EMT02B6Q, max UDMA/133 Jul 23 20:50:02 Tower kernel: ata1.00: 1953525168 sectors, multi 1: LBA48 NCQ (depth 32), AA Jul 23 20:50:02 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 20:50:02 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 20:50:02 Tower kernel: ata1.00: configured for UDMA/133 Jul 23 20:50:02 Tower kernel: sd 1:0:0:0: [sdb] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB) Jul 23 20:50:02 Tower kernel: sd 1:0:0:0: [sdb] Write Protect is off Jul 23 20:50:02 Tower kernel: sd 1:0:0:0: [sdb] Mode Sense: 00 3a 00 00 Jul 23 20:50:02 Tower kernel: sd 1:0:0:0: [sdb] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Jul 23 20:50:02 Tower kernel: sdb: sdb1 Jul 23 20:50:02 Tower kernel: sd 1:0:0:0: [sdb] Attached SCSI disk Jul 23 20:50:04 Tower kernel: ata1.00: exception Emask 0x50 SAct 0x1000 SErr 0x4090800 action 0xe frozen Jul 23 20:50:04 Tower kernel: ata1.00: irq_stat 0x00400040, connection status changed Jul 23 20:50:04 Tower kernel: ata1: SError: { HostInt PHYRdyChg 10B8B DevExch } Jul 23 20:50:04 Tower kernel: ata1.00: failed command: READ FPDMA QUEUED Jul 23 20:50:04 Tower kernel: ata1.00: cmd 60/08:60:00:6d:70/00:00:74:00:00/40 tag 12 ncq dma 4096 in Jul 23 20:50:04 Tower kernel: ata1.00: status: { DRDY } Jul 23 20:50:04 Tower kernel: ata1: hard resetting link Jul 23 20:50:08 Tower kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jul 23 20:50:08 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 20:50:08 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 20:50:08 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 20:50:08 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 20:50:08 Tower kernel: ata1.00: configured for UDMA/133 Jul 23 20:50:08 Tower kernel: sd 1:0:0:0: [sdb] tag#12 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Jul 23 20:50:08 Tower kernel: sd 1:0:0:0: [sdb] tag#12 Sense Key : 0x5 [current] Jul 23 20:50:08 Tower kernel: sd 1:0:0:0: [sdb] tag#12 ASC=0x21 ASCQ=0x4 Jul 23 20:50:08 Tower kernel: sd 1:0:0:0: [sdb] tag#12 CDB: opcode=0x28 28 00 74 70 6d 00 00 00 08 00 Jul 23 20:50:08 Tower kernel: print_req_error: I/O error, dev sdb, sector 1953524992 Jul 23 20:50:08 Tower kernel: ata1: EH complete Jul 23 20:50:17 Tower kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jul 23 20:50:17 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 20:50:17 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 20:50:17 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 20:50:17 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 20:50:17 Tower kernel: ata1.00: configured for UDMA/133 Jul 23 20:50:26 Tower emhttpd: Samsung_SSD_850_EVO_1TB_S21CNWAFC03914M (sdb) 512 1953525168 Jul 23 20:50:26 Tower emhttpd: import 30 cache device: (sdb) Samsung_SSD_850_EVO_1TB_S21CNWAFC03914M Jul 23 20:53:58 Tower emhttpd: Samsung_SSD_850_EVO_1TB_S21CNWAFC03914M (sdb) 512 1953525168 Jul 23 20:56:05 Tower emhttpd: Samsung_SSD_850_EVO_1TB_S21CNWAFC03914M (sdb) 512 1953525168 Jul 23 20:56:05 Tower emhttpd: import 30 cache device: (sdb) Samsung_SSD_850_EVO_1TB_S21CNWAFC03914M And down and down it goes till it bottoms out. Jul 23 21:27:17 Tower kernel: ata1: link is slow to respond, please be patient (ready=0) Jul 23 21:27:20 Tower kernel: ata1: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Jul 23 21:27:20 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 21:27:20 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 21:27:20 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 21:27:20 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 21:27:20 Tower kernel: ata1.00: configured for UDMA/33 Jul 23 21:27:28 Tower emhttpd: Samsung_SSD_850_EVO_1TB_S21CNWAFC03914M (sdb) 512 1953525168 Jul 23 21:28:25 Tower preclear_disk_S21CNWAFC03914M[2937]: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --cycles 1 --no-prompt /dev/sdb Jul 23 21:28:25 Tower preclear_disk_S21CNWAFC03914M[2937]: Disk /dev/sdb is a SSD, disabling head stress test. Jul 23 21:28:27 Tower preclear_disk_S21CNWAFC03914M[2937]: Pre-Read: dd if=/dev/sdb of=/dev/null bs=2097152 skip=0 count=1000204886016 conv=notrunc,noerror iflag=nocache,count_bytes,skip_bytes Jul 23 21:38:58 Tower preclear.disk: Pausing preclear of disk 'sdb' Jul 23 21:38:58 Tower preclear.disk: Resuming preclear of disk 'sdb' Jul 23 21:39:15 Tower preclear.disk: Pausing preclear of disk 'sdb' Jul 23 21:39:22 Tower preclear.disk: Resuming preclear of disk 'sdb' Jul 23 21:39:25 Tower kernel: ata1: link is slow to respond, please be patient (ready=0) Jul 23 21:39:28 Tower kernel: ata1: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Jul 23 21:39:28 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 21:39:28 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 21:39:28 Tower kernel: ata1.00: supports DRM functions and may not be fully accessible Jul 23 21:39:28 Tower kernel: ata1.00: disabling queued TRIM support Jul 23 21:39:28 Tower kernel: ata1.00: configured for UDMA/33
-
Attached, Something else I noticed is that it keeps defaulting to SATA 1.0 (1.5gbps) and yes I am aware that I have a bunch of failing WD 6.0 Red drives, that Why I am in the process of moving stuff off them. tower-diagnostics-20200723-1743.zip
-
When I built my setup I set the cache to be BTRFS, stopping and staring the array, the drive mounted but then lost the FS after a few hours, Checking the system I discovered that the drive became unassailable and I end up formatting it as XFS. Looking at the Smart data I see that I had 1 Reallocated sector count which was mapped out. This seemed to work and I setup a bit torrent client and tested out downloading ~500GB of torrent files to the Cache drive via a docker container. Everything seemed to be working fine, but then when i tried to install another container, docker became unavailable. I looked into the recommendations and stopped the docker service and deleting the /mnt/cache/system/docker/docker.img and then starting and re-downloading the image. However non of the containers would start. Looking into the logs I keep seeing. Jul 23 15:58:41 Tower kernel: BTRFS warning (device loop2): csum failed root 294 ino 43871 off 16384 csum 0x473ac0bb expected csum 0xfbab9ca3 mirror 1 The only thing I can think of is that the docker.img is running the BTRFS internalized and something about the drive it doesn't like. To be safe I am removing the drive and will preform a full check on it. If BTRFS has issues with Uncorrectable error count and Reallocated sector count occurring is it really ready for prime time. at least with XFS unraid seems to handle bad sectors occurring more gracefully in that the data is still accessible. In the mean time is there anything else I should be doing?
-
BTRFS Workers when no BTRFS Filesystem? Normal?
Matthew_K replied to Wavey's topic in General Support
Sorry to hijack this thread, but I wan ran into an interesting issue. So I am in the process of settign up a new system I setup my cache drive, made sure that everything was working. Mounted and formatted the drive with btrfs. Then I swapped the Hardware as soon as it became available, now when I look at the system, It tells me that the Cache is healthy and active but the mount say No filesystem. If i go to /mnt/cache it also tells me that location does not exist. Looking at the error logs Jul 22 10:16:01 Tower kernel: ata2.00: exception Emask 0x10 SAct 0x7000 SErr 0x4090000 action 0xe frozen ... Jul 22 10:27:22 Tower kernel: BTRFS error (device sdc1): parent transid verify failed on 26034176 wanted 56 found 19 Jul 22 10:27:22 Tower kernel: BTRFS warning (device sdc1): failed to read fs tree: -5 ... Jul 22 10:27:22 Tower emhttpd: /mnt/cache mount error: No file system So am I looking at a Bad Drive, Cable, something else? I was mapping an NTFS drive to copy data to the Disk 1 partition and started and stopped the array in rapid succession. also the drive does have one Uncorrectable error count
-
Does anyone remember Parchive? back in the usenet days, Par was used to recover corrupted or missing data from Usenet block. The nice thing about Par was that it would use the file(s) themselves to create a parity and would only require the number of blocks to replace the missing data. Hypothetically speaking if you had a 20GB file had a 4k corruption within that file you would only need a 4k par file to repair the original file (assuming the bad data was on in same block). I was cool tech back then, and I and surprised that it never when anywhere. I was just curious what people think. I could see a background task that would reserve 1%-10% of each drive to create a Par set per file at 4K per block. sure the initial calc would be long, but considering that the majority of data never changes, and that this could be done on a per file basis I could see this as a way to adding partial a functionality of a Q disk with needing a second drive, Just my 2 cents.
-
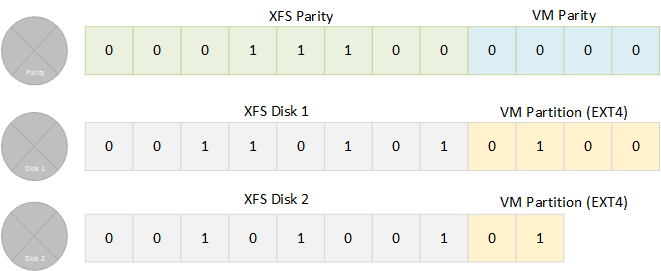
I am new to UNRaid, and I looking for some answers about how best to configure a system. Right now I am running EXSI 6.7 and have 1TB of /OS/VMSpace and then 4x6TB Drives all mapped as raw disks to a Window Server 2016 VM. Obviously this is not the best setup but it is what I kinda grew into overtime. Based upon what I have read UNRaid acts as a JBOB with each disk being a standard XFS or BTRFS partition and then a parity drive that acts as redundancy for the disk. Because the way that UNRaid calculates the parity data this allows for full redundancy across mismatched drives as long as the parity drive is same size or large. Enter KVM… As much as each file system tries to be everything to everyone it always comes down to using the right file system for the correct application. A good case would be with VM, BTRFS kinds sucks because of the overhead, but BTRFS is more feature rich then say XFS or EXT4. It seems that UNRiad is all or nothing for the array? Is it in the plans to allow for mixed file systems for the best possible performance for any give operation? I thought other a quick diagrams with the knowledge I have on how this might work. Is this what was meant in the last poll for t 2020 for multi array support? Partitioned Disk Dedicated Disk Finally as someone who had to deal with KVM snapshots in the past, when this feature is added, please, please make sure that each snapshot delta is stored as separate file. This fixes so many issues and on top of that because the base OS in VM tends to be the largest part of a VM, it should make, creating a parity of the base VM easier because you only really need to do it once. however, this is form a person that tends to work off of deltas and merge the delta back into the head every once in a while and create a new working delta. I don’t think a lot of people know just how powerful this trick really is. Thank you for humoring me.