

daan_SVK
-
Posts
141 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by daan_SVK
-
-
35 minutes ago, trurl said:
manual install indeed resolved.
I wish there was a way to tell the USB creator failed to write the full image to the USB stick. All it says is "Writing done!" which really indicates it was done successfully.
-
2 minutes ago, trurl said:
Your config folder on flash is missing a lot of important stuff.
What exactly do you mean by "imaged"?
Did you not use any of the normal install methods?
I used the USB creator from the website, multiple USB keys as well.
Should I just extract it manually? Doesn't the creator check the USB integrity once it writes the image?
-
-
hi there,
I'm just looking for some ideas on how to troubleshoot this further.
I am trying to test a new build, it's a Lenovo P620 workstation. I imaged a new USB key and booted it up, I get no webgui, connection refused.
- I can ping the server by hostname and IP
- router shows the server by hostname as a connected device
- I get no local gui because the server has a P2000 and it needs a driver first
- I can not ssh into the server as the root password hasn't been set in the webgui first
- I tried different USB sticks and different USB ports, it's always the same
the server runs headless, is there anything else I can try?
-
6 hours ago, JorgeB said:
This is usually a bad SATA cable.
I will replace the cable, it's just weird the server started having all these odd issues all of a sudden.
-
16 minutes ago, trurl said:
post new diagnostics
Sure, please see attached tower-diagnostics-20230207-1932.zip
-
so the disk rebuild failed with read errors again on the same drive so I replaced it and the replacement drive is rebuilding now, however I now see this in the log:
Feb 7 17:51:28 Tower kernel: ata9.00: exception Emask 0x10 SAct 0x0 SErr 0x280100 action 0x6 frozen Feb 7 17:51:28 Tower kernel: ata9.00: irq_stat 0x08000000, interface fatal error Feb 7 17:51:28 Tower kernel: ata9: SError: { UnrecovData 10B8B BadCRC } Feb 7 17:51:28 Tower kernel: ata9.00: failed command: READ DMA EXT Feb 7 17:51:28 Tower kernel: ata9.00: cmd 25/00:40:68:1e:da/00:05:4b:00:00/e0 tag 4 dma 688128 in Feb 7 17:51:28 Tower kernel: res 50/00:00:67:1e:da/00:00:4b:00:00/e0 Emask 0x10 (ATA bus error) Feb 7 17:51:28 Tower kernel: ata9.00: status: { DRDY } Feb 7 17:51:28 Tower kernel: ata9: hard resetting link Feb 7 17:51:28 Tower kernel: ata9: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Feb 7 17:51:28 Tower kernel: ata9.00: configured for UDMA/133 Feb 7 17:51:28 Tower kernel: ata9: EH completeand also my parity drive UDMA CRC error count just went from 0 to 1.
I was originally thinking to replace the Sata cable to the disabled drive but now with the CRC error on the parity drive I'm wondering if I should just abandon the motherboard controller and move all the drives onto an LSI card.
-
13 hours ago, JorgeB said:
Type reboot on the console, if it doesn't work after a few minutes you'll need to force it, ideally you'd fix the crashing problem first, see this if you haven't yet.
I replaced the RAM and disabled C-states, I can't believe they were enabled.
The drive is rebuilding now onto itself, I will report back.
thanks again.
-
On 1/28/2023 at 12:56 AM, JorgeB said:
Does errors are still about the docker image, reboot and post new diags after array start.
I did as you suggested, rebooted and the btrfs errors cleared. I was hoping that was the end of it but the server locked up with a Kernel Panic two days later. Rebooted with a successful parity check, the server ran OK for another two or three days. Last night it locked up again with Kernel Panic. After it was rebooted, a disk was disabled during the parity check which never happened before.
I have a spare disk that I can replace the faulty one, if it is indeed faulty. However, I can not stop the array as the server is reporting that the parity check is running. It does not appear so as all the disks are spun down. Pressing the Cancel or Resume Parity check button does not re-enable the Stop array button so I'm not sure how to proceed.
the latest diagnostics is below, what's my best course of action here?
thanks in advance!
-
54 minutes ago, trurl said:
attach diagnostics to your NEXT post in this thread
sure, please see attached.
the pool was rebalanced and scrubbed after the docker image was recreated.
-
On 1/26/2023 at 8:09 AM, JorgeB said:
For now I don't see any issues with the pool filesystem, besides the already mentioned data corruption errors, only the docker image went read-only.
I deleted and re-created the docker container, reinstalled all my dockers, but immediately saw more btrfs errors in the log:
Jan 27 15:22:40 Tower kernel: BTRFS error (device loop2: state EA): parent transid verify failed on 335167488 wanted 2298130 found 2298088 Jan 27 15:22:40 Tower kernel: BTRFS error (device loop2: state EA): parent transid verify failed on 335167488 wanted 2298130 found 2298088 Jan 27 15:22:40 Tower kernel: BTRFS error (device loop2: state EA): parent transid verify failed on 335167488 wanted 2298130 found 2298088 Jan 27 15:22:40 Tower kernel: BTRFS error (device loop2: state EA): parent transid verify failed on 335167488 wanted 2298130 found 2298088ran scrub on the cache pool, no errors reported. Are the errors from within the docker container img? How do I resolve this for good?
I'm rebalancing the pool now as I saw a thread where the full FS allocation caused the same error on cache.
-
1 hour ago, JorgeB said:
just to be clear, are you saying recreating the docker image is a better approach than reformatting the cache pool?
I'd like to address the possible cause of the corrupted image as well.
-
Thanks for the reply,
Yes, I am aware, but this corruption has been on the cache pool for some time without a changed count.
I will run another memtest but I still need to deal with the read only docker image.
-
hi guys,
I keep loosing the ability to write to my docker image file. After seeing the below in my logs, I'm suspecting the cache or the image file is corrupted and was hoping to get some guidance on what should I do next.
Jan 25 17:29:04 Tower kernel: ---[ end trace 0000000000000000 ]--- Jan 25 17:29:04 Tower kernel: BTRFS: error (device loop2: state A) in __btrfs_free_extent:3079: errno=-2 No such entry Jan 25 17:29:04 Tower kernel: BTRFS info (device loop2: state EA): forced readonly Jan 25 17:29:04 Tower kernel: BTRFS: error (device loop2: state EA) in btrfs_run_delayed_refs:2157: errno=-2 No such entry Jan 25 17:29:14 Tower flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup updateRecreate the docker.img or nuke the whole cache pool and reformat it?
thanks in advance for reading,
-
On 3/22/2022 at 4:07 AM, jeypiti said:
The easiest way would be to simply adapt the existing paperless-ng template because you won't have to mess with any configuration:
- Find your paperless container in the UI.
- Open the configuration.
-
Under "Repository", replace
jonaswinkler/paperless-ng:latest
with
ghcr.io/paperless-ngx/paperless-ngx:latest - Click "Apply".
That's it!
Optional:
- Rename the container itself: In the container configuration, change the "Name" field to "paperless-ngx". It seems if you change this name you will also have to potentially re-configure the auto-start option.
- Rename your appdata folder (while the container is stopped). After renaming the folder, make sure to mirror the name change in the container configuration field "Data" (and any other fields that reference the appdata folder).
-
Update the "Overview" field to remove references to paperless-ng and add paperless-ngx info. To do this, switch to the advanced view within the container configuration and paste the following into "Overview":
Paperless-ngx is a document management system that transforms your physical documents into a searchable online archive so you can keep, well, less paper. Paperless-ngx forked from paperless-ng to continue the great work and distribute responsibility of supporting and advancing the project among a team of people.[br][br] Requirements: Paperless-ngx requires Redis as external service. You can install it from the CA store. Make sure to adjust the configuration in the template accordingly. Setup: Create a user account after this container is created i.e. from Unraids Docker UI, click the paperless-ngx icon and choose Console. Then enter "python manage.py createsuperuser" in the prompt and follow the instructions. Paperless-ngx Documentation: https://paperless-ngx.readthedocs.io/en/latest/ Additional Template Variables: https://paperless-ngx.readthedocs.io/en/latest/configuration.html Demo: https://demo.paperless-ngx.com/(This is the text that the paperless-ngx template uses, you can find it here on GitHub)
-
In advanced view, change "Docker Hub URL" to
https://github.com/paperless-ngx/paperless-ngx/pkgs/container/paperless-ngx
If you do all these optional steps, you have effectively transformed the old paperless-ng template into the new paperless-ngx template. There are two exceptions to this however: you can't update the template with links to the paperless-ngx GitHub repository or this support forum thread, both of those will still point to the respective paperless-ng resources.
The alternative is to pull the new template from CA but this will require you to copy over configuration with will lead to problems if you make a mistake. I haven't done this myself but the steps should be as follows:
- Stop the paperless-ng container.
- Pull the paperless-ngx template and copy over all the configuration from the old paperless-ng template 1-to-1 (including the old appdata folder name).
- Start the paperless-ngx container and check that everything is working as you'd expect.
- Remove the paperless-ng container.
Can I use this method to migrate from the deprecated Paperless docker as well?
-
perfect, thank you both for the quick confirmation!
-
hi there,
this is an old thread, is the info still valid?
I have a drive in my array that is still on REISERFS. Can I use the procedure described here to convert it to XSF? The drive will be empty at the time of conversion. I don't mind rebuilding the parity.
-
2 hours ago, binhex said:
yep that should work, if i were you though i would simply rename the radarr.db to something like radarr.db.old JUST incase you need it rather than deleting it.
the official Radarr forum has a few other things that can be attempted to repair corruption in existing database, I might try to do that before starting anew. The step by step guide is here:
https://wiki.servarr.com/useful-tools#recovering-a-corrupt-db-ui
-
 1
1
-
-
8 minutes ago, binhex said:
@daan_SVK @Tolete looks like the upgrade of the db partially happened when you upgraded to the latest version of radarr leaving things in a broken state when you roll back, not great!. solution is to either wipe your db, go to latest and reimport everything (ideal but time consuming) or restore your config for radarr from backup.
I restored from backup and it seems OK.
thanks once again.
what's the plan going forward with the update?
-
9 minutes ago, Tolete said:
after reverting back to
binhex/arch-radarr:3.2.2.5080-1-01
now im seen this on home page
Error parsing column 42 (MediaInfo={ "containerFormat": "MPEG-4", "videoFormat": "h264", "videoCodecID": "x264", "videoProfile": "[email protected]", "videoBitrate": 2500000, "videoBitDepth": 8, "videoMultiViewCount": 0, "videoColourPrimaries": "", "videoTransferCharacteristics": "bt709", "videoHdrFormat": "none", "height": 816, "width": 1920, "audioFormat": "aac", "audioBitrate": 224000, "runTime": "01:44:04.2860000", "audioStreamCount": 1, "audioChannels": 6, "audioChannelPositions": "5.1", "videoFps": 23.976, "audioLanguages": [], "subtitles": [], "scanType": "Progressive", "schemaRevision": 5 } - String)
same for me, library empty, just the same error you're getting
-
3 hours ago, binhex said:
do I have to re-import the library after rolling back?
My web interface came back up, but the library is empty now.
-
On 10/15/2021 at 11:03 PM, ich777 said:
Have you installed a Influx DB or something similar too?
Is it now showing as "UP" in the Prometheus dashboard?
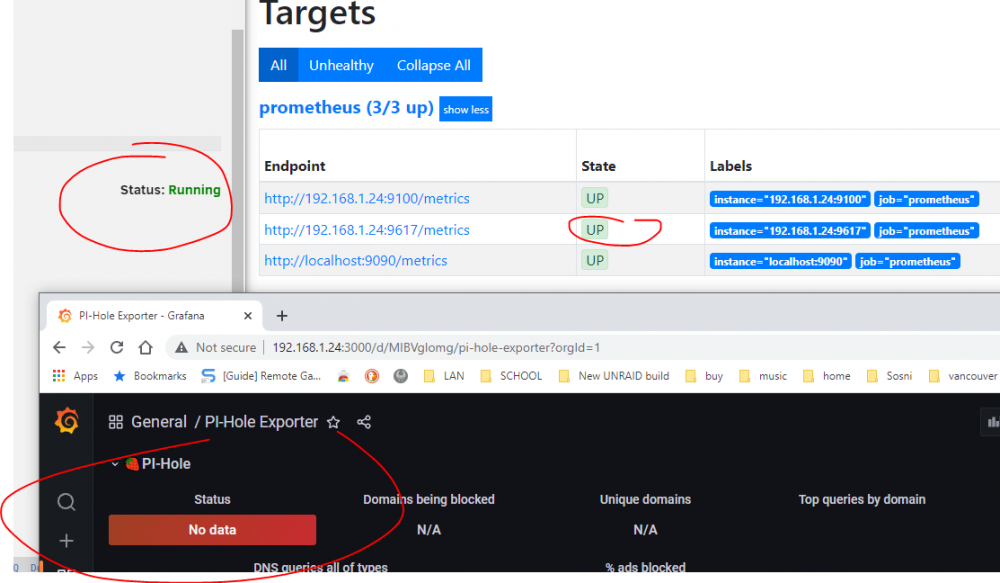
no, I'm not running any DB containers, my setup is fairly simple.
yes, it stays UP for about 10 minutes, then it stops.
I might try the Nvidia one as well just to try to isolate the issue.
-
On 10/14/2021 at 7:11 AM, ich777 said:
Please check that nothing is stopping the PiHole container or restarting it since this can cause issues.
As said, the Exporter runs as long as PiHole is running and the Exporter will stop when PiHole is stopped/restarted.
Maybe check also the Docker logs from your PiHole container and also the syslog if you see anything suspicious.
Also try to click on the URL in Prometheus for the PiHole Exporter and see what the output is.
Have you enabled Host access if you run this container on the custom br0 network?
Sent from my C64
the Pihole Container has 27hrs uptime so the 10 minute shut down interval is not caused by the Pihole docker restarting.
Host Access is enabled on the Docker configuration page, before I enabled it I couldn't get Prometheus to connect to it.
When I click the link in Prometheus for Pihole Explorer, it goes to the metrics site with all the parameters as long as the PiHole explorer is running. Grafana still doesnt pull any data though.
with my limited knowledge, I don't see anything obvious in the logs I'm afraid. The standard Grafana dashboard works OK.
-
7 hours ago, ich777 said:
What does the Exporter plugin page tell you is it "Running" or "Starting"?
Do you restart PiHole, if so, keep in mind that if you restart PiHole the Exporter won't also stop and there is nothing I can do about this.
You've posted a screenshot where it shows that the Exporter is DOWN, have you seen it yet do display UP?
Are you running PiHole on unRAID?
thanks for y our reply.
yes, when I start the Explorer plugin it starts, runs for about 10 minutes and then it stops.
Pihole runs on Unraid.
Even with the services running, I dont get any data from the Pihole in Grafana:


new install - no webgui
in General Support
Posted
I appreciate the time you took to respond but it was indeed incomplete image on the USB stick.
this was a new install in new environment so I was suspecting something wrong with the network, I never had issues with the USB creator before. I will stick with the manual USB creation, is like we used to do it in the 90's anyway.