
CS01-HS
-
Posts
475 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by CS01-HS
-
-
On 6/6/2023 at 10:07 AM, dlandon said:
NFS cannot deal with a symlink. You can use the actual storage location. For example if you have Syslogs as a cache only share, use the /mnt/cache/Syslog reference rather than /mnt/user/Syslog. This avoids shfs when using /mnt/user/Syslog.
Similar problem with 9p (which I use for a VM) in that it's not transparent.
Still I'd appreciate some way to override it - I have a share that was exclusive in rc6 and now because of one subdirectory mounted over NFS (that worked fine) no longer is.
Sure I can hardcode paths but the biggest problem - that I access the share from my Mac over SMB where every access risks triggering an shfs bug that takes down the array – is difficult to work around.
Worst case I'll disable NFS and mount it some other way.
-
6.12 offers a partial solution with cache-only shares bypassing shfs (if you can restructure your workflow to use them.)
-
On 5/7/2023 at 10:07 PM, Squid said:
Nobody thinks of it like that, and it's never actually logged anything in my system setting the syslog server to the IP or 127.0.0.1. For remote systems it works no problems
If I remember right 127* doesn't work, you have to use the LAN IP.
I've run mine like that for years.
I also have these tweaks in config/go:
# Put syslogs in system/logs (web ui only allows share root) cp /etc/rsyslog.conf /etc/rsyslog.conf.orig sed -i -e 's/\/mnt\/user\/system\//\/mnt\/user\/system\/logs\//g' /etc/rsyslog.conf # name logs by hostname instead of IP sed -i -e 's/FROMHOST-IP/FROMHOST/g' /etc/rsyslog.conf # Apply changes /etc/rc.d/rc.rsyslogd restartWith the corresponding change to logrotate (along with other tweaks) in a user script set to run At Startup of Array – for some reason they didn't work in config/go.
#!/bin/bash # update logrotate with non-default syslog location cp /etc/logrotate.d/rsyslog.local /etc/logrotate.d/rsyslog.local.orig sed -i -e 's/\/mnt\/user\/system\//\/mnt\/user\/system\/logs\//g' /etc/logrotate.d/rsyslog.local # add compression sed -i -e 's/missingok/missingok\n compress\n delaycompress/g' /etc/logrotate.d/rsyslog.local # make sure log size doesn't exceed 10MB (setting to 10MB unintuitively allow up to 11MB) sed -i -e 's/size 10M/size 9M/g' /etc/logrotate.d/rsyslog.local # not sure this is necessary /etc/rc.d/rc.rsyslogd restart exit 0 -
7 minutes ago, Squid said:
Did you remake the flash drive? That happens if the template isn't within /config/plugins/dockerMan/templates-user on the flash drive (eg: you inadvertently deleted it), is corrupt etc
I didn't remake anything as far as I know.
This morning I spotted and deleted a leftover NerdPack directory in plugins - I can't imagine I mistakenly cleared templates-user but the timing seems too close for coincidence.
-
I compared the backup to the boot drive and the only difference is the missing user templates. Copied them over and all's back to normal.
Strange.
-
root@NAS:/boot/config/plugins/dockerMan/templates-user# ls -l total 0 root@NAS:Huh, well that explains it.
As it happens I ran the new Appdata backup overnight and they're present in the flash backup... will investigate.
-
Happened again, my first time with rc3. Failed creation of a new folder on a share from my Mac (possibly duplicate name) produced this in the log (I use syslog sever.)
Apr 19 08:25:28 NAS emhttpd: read SMART /dev/sdd Apr 19 08:25:57 NAS emhttpd: read SMART /dev/sde Apr 19 08:34:54 NAS shfs: shfs: ../lib/fuse.c:1450: unlink_node: Assertion `node->nlookup > 1' failed. Apr 19 08:34:54 NAS rsyslogd: file '/mnt/user/system/logs/syslog-nas.log'[9] write error - see https://www.rsyslog.com/solving-rsyslog-write-errors/ for help OS error: Transport endpoint is not connected [v8.2102.0 try https://www.rsyslog.com/e/2027 ] Apr 19 08:34:54 NAS rsyslogd: file '/mnt/user/system/logs/syslog-nas.log': open error: Transport endpoint is not connected [v8.2102.0 try https://www.rsyslog.com/e/2433 ] Apr 19 08:34:54 NAS emhttpd: error: get_filesystem_status, 7380: Transport endpoint is not connected (107): scandir Transport endpoint is not connectedShares inaccessible. Had to stop everything and reboot.
I have to treat every file operation over SMB as though it might take down the array. That's a serious inconvenience.
-
 1
1
-
-
I gave up on unraid time machine (I now use a time capsule) so my comment's not based on experience with the recent versions but it seems to me the later samba versions made MacOS less compatible generally – search doesn't work out of the box, folders don't always refresh when their content changes (which sometimes causes fuse errors that take down the array.)
I'd be tempted to blame MacOS but I have an old Raspberry Pi running samba 4.9.5 that works just fine.
-
I've triggered it a few times with SMB file operations from my Mac client where the folder/file structure was stale.
Since then I force a refresh by e.g. navigating down a directory then back up before every SMB move or copy. Tedious but so far it hasn't failed.
-
Any update here?
More than 2 years and no official fix.
I appreciate all the updates since but it's frustrating to see a pretty basic function not working and not addressed.
-
 1
1
-
-
On 1/5/2023 at 3:15 PM, Micleeso said:
I am on macOS 13.1 (22C65) and can not search Windows 10 shares
Am I missing something? What's the relevance to unRAID?
-
Happened to me recently with 6.11.2.
In my case it's always triggered by SMB file operations - macOS's poor implementation acting on a stale version of the directory tree, causing invalid operations and the fuse exception. I have to remember to navigate down or up then back to force a refresh.
-
On 10/4/2022 at 9:44 PM, dlandon said:
Copy the /etc/samba/smb-fruit.conf to /flash/config/smb-fruit.conf. Then make changes to the /flash/config/smb-fruit.conf file. After making changes, you need to restart samba:
/etc/rc.d/rc.samba restartYou need to make changes to the copied smb-fruit.conf because it contains the "vfs objects = catia fruit streams_xattr". You'll see uncommented lines. Those are the defaults. The commented lines are lines you can uncomment to try out different settings.
Just a note because it threw me off - restarting samba didn't apply my /(flash|boot)/config/smb-fruit.conf changes. Stopping the array and restarting did though.
-
18 hours ago, _whatever said:
You might try doing 'find /mnt/user/data \( -name '.DS_Store' \) -delete' on Unraid to remove any existing files and run 'defaults write com.apple.desktopservices DSDontWriteNetworkStores -bool TRUE' on your Mac to stop it from creating .DS_Store files.
I use the Mover Tuning plugin to keep all my .DS_Store files on the (SSD) Cache.
I don't know whether that's as fast as disabling them entirely.

None of these tweaks have made SMB as fast and reliable as AFP unfortunately.
On 8/24/2022 at 11:15 AM, kri kri said:I continue to have extremely slow navigating and data transfers.
How slow is extremely slow?
For reference I get about 25MB/s for large transfers over 802.11n.
I'd really like to know whether these performance issues apply to SMB in general with mac clients or whether they're specific to unraid. Does anyone have another high-performance NAS to test against and compare?
-
So far so good.
A couple of minor problems I haven't dug into:
– I see this in the log, not sure what's causing it.
kernel: Attempt to set a LOCK_MAND lock via flock(2). This support has been removed and the request ignored.– Nerd Pack hangs on retrieving plugin information
-
1
-
1
-
-
Could be a freak occurrence but unraid suddenly stopped tracking reads/writes to my cache pool. It was being read from but according to the webgui and telegraf there was no activity. A reboot fixed it. Very strange.
-
If you can guarantee your Time Machine data will always only exist on a pool (or a single disk) you might get some speed improvement by bypassing shfs. Please verify these instructions because it's been a while since I tested.
NOTE: Because we'll be specifying the share options manually changes to the share with the webgui will be ignored. Make sure the share's settings are already optimized for time machine before proceeding.
1. Record your time machine share's settings from this file:
cat /etc/samba/smb-shares.conf2. Stop the array
3. Go to Settings -> SMB -> SMB Extras and verify this line exists near the bottom. If it doesn't, create it
include = /boot/config/smb-custom.conf
3. Add your time machine share's settings recorded in Step 1 to /boot/config/smb-custom.conf replacing user in the path line with your pool's name, e.g. for pool named "fast"path = /mnt/user/Time-Machinebecomes:
path = /mnt/fast/Time-Machine4. Save and start the array
-
2 hours ago, itimpi said:
Not quite sure what you are asking for here? I pass USB devices through to VMs (for instance an Unraid USB flash drive to run a development UnRaid environment).
Has that always worked? I remember about a year ago I had to jump through hoops to pass an iphone to a Mac VM (board only has one USB controller and one PCIe slot occupied by my HBA) because it wouldn't. My setup works but just barely. Anyone passing an iDevice without passing the whole controller?
-
Bumping this because I see it's not fixed in the (otherwise excellent and stable!) 6.10.0-rc1
-
2
-
-
16 minutes ago, Zer0Nin3r said:
Do we have to input share specific folders? Would stopping at '/mnt/user/' allow the spotlight flag to be recursive?
The path directive supplies the path for a particular share. Not sure why I have to duplicate it in Extra since it's specified by unraid but it wouldn't work without it.
These are share-specific directives so AFAIK it would only apply to the share whose path is /mnt/user (and creating that share might cause conflicts.)
-
 1
1
-
-
Looks good.
-
1
-
-
10 hours ago, BenW said:
Yeah - I checked and it all seems OK.
I'm also massively out of my depth but REALLY appreciate the help you've given thus far, it's appreciated.
It seems there's a bit of a collective *shrug* when it comes to MacOS around the unraid community, so any help is definitely useful.
I *think* it might be this line:
Spotlight backend = tracker
As I've been following the below article since I couldn't get it working, and it's pointing to a spotlight backend using elasticsearch:
and
This article: https://wiki.samba.org/index.php/Spotlight_with_Gnome_Tracker_Backend
Seems to suggest that you need to compile and install Gnome Tracker backend (hence specifying the backend for spotlight as 'tracker'
Was that something you installed separately or does Unraid have it included? As that would match up to my error: mds_init_ctx: Unknown backend 1
Anyway - I'm *hoping* elasticsearch works after it's finished indexing, otherwise I'll revert back to this thread again.
That's a way to get spotlight indexing working, I haven't tried it and haven't installed extra libraries.
Have you tried stopping/starting the array?
If you post your full smb extras maybe someone will spot a problem.
-
41 minutes ago, BenW said:
Nice - thanks for this!
I tried copying in the entries, but it's still not working (even though Terminal says Indexing is on and doesn't report an error) - Perhaps I'll wait 24 hours and see if spotlight indexes.
I am getting some errors in the log though, any idea where to start with this?
-- Paste--
Apr 13 11:19:00 CHASM smbd[5906]: [2021/04/13 11:19:00.522119, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:19:00 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:19:00 CHASM smbd[5906]: [2021/04/13 11:19:00.522159, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:19:00 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Productions
Apr 13 11:19:02 CHASM smbd[5906]: [2021/04/13 11:19:02.670841, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:19:02 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:19:02 CHASM smbd[5906]: [2021/04/13 11:19:02.670877, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:19:02 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Photos
Apr 13 11:19:58 CHASM smbd[5906]: [2021/04/13 11:19:58.988604, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:19:58 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:19:58 CHASM smbd[5906]: [2021/04/13 11:19:58.988639, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:19:58 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Productions
Apr 13 11:20:08 CHASM smbd[5906]: [2021/04/13 11:20:08.789527, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:20:08 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:20:08 CHASM smbd[5906]: [2021/04/13 11:20:08.789583, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:20:08 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Productions
Apr 13 11:20:32 CHASM smbd[5906]: [2021/04/13 11:20:32.311396, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:20:32 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:20:32 CHASM smbd[5906]: [2021/04/13 11:20:32.311436, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:20:32 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Productions
Apr 13 11:20:45 CHASM smbd[5906]: [2021/04/13 11:20:45.346181, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:20:45 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:20:45 CHASM smbd[5906]: [2021/04/13 11:20:45.346217, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:20:45 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Productions
Apr 13 11:22:48 CHASM smbd[5906]: [2021/04/13 11:22:48.626097, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:22:48 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:22:48 CHASM smbd[5906]: [2021/04/13 11:22:48.626131, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:22:48 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Productions
Apr 13 11:23:25 CHASM smbd[5906]: [2021/04/13 11:23:25.156402, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:23:25 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:23:25 CHASM smbd[5906]: [2021/04/13 11:23:25.156437, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:23:25 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Photos
Apr 13 11:24:06 CHASM smbd[5906]: [2021/04/13 11:24:06.250267, 0] ../../source3/rpc_server/mdssvc/mdssvc.c:1565(mds_init_ctx)
Apr 13 11:24:06 CHASM smbd[5906]: mds_init_ctx: Unknown backend 1
Apr 13 11:24:06 CHASM smbd[5906]: [2021/04/13 11:24:06.250301, 0] ../../source3/rpc_server/mdssvc/srv_mdssvc_nt.c:187(_mdssvc_open)
Apr 13 11:24:06 CHASM smbd[5906]: _mdssvc_open: Couldn't create policy handle for Photos
Are you sure there's not a typo in your config?
I'm afraid I'm out of my depth here.
I can say as far as I'm aware spotlight's not involved in SMB search - it should work immediately.
-
Put it in Settings -> SMB -> SMB Extras
You have to stop the array to edit it.
Here's what mine looks like with two shares: Private and Public, but I've customized it enough I forget what's changed from the default. I believe the highlighted lines are the only ones necessary to fix search.
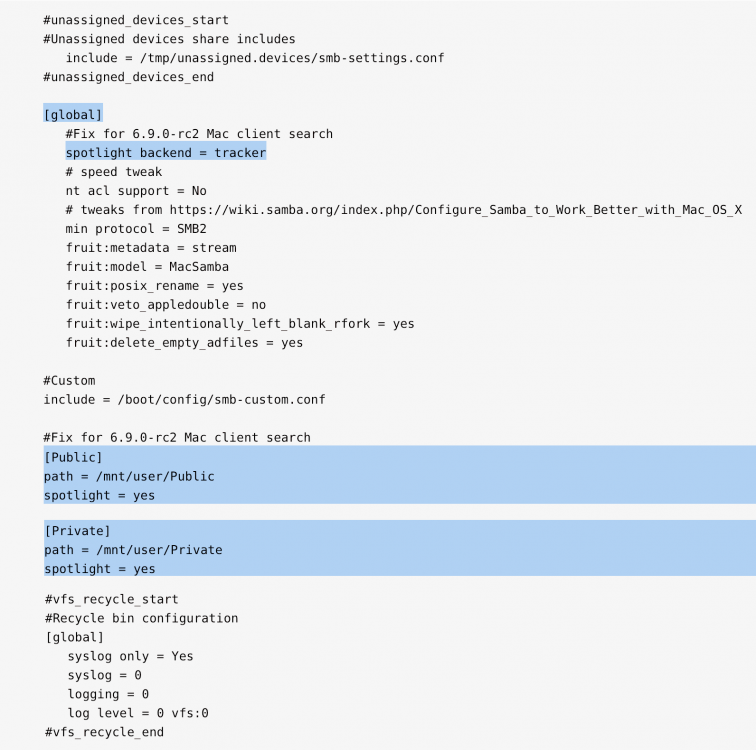






[6.8.3] shfs error results in lost /mnt/user
in Stable Releases
Posted
In my case the half a dozen times it happened were all triggered by SMB operations. Never happened in any other case and since the new implementation where cache-only shares bypass shfs (and the majority of my SMB use is cache-only shares) it hasn't happened since.