
CS01-HS
-
Posts
475 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by CS01-HS
-
-
To add further complication behavior seems to depend on the particular USB drive/controller. This script worked (and was necessary) for me for all 6.8.X and 6.9.X versions. I don't know about 6.10 because I've switched from USB to an odroid HC2 (nice little machine.)
If I remember right unraid had issues tracking spindown state because my drive (WD Passport) would exit with an error code from hdparm -C /dev/sdX - something about "bad/missing sense" but that indicated it was actually spun down. smartctl worked properly however. To work around it I modified unRAID's sdspin to ignore that particular error and prefer smartctl to hdparm with USB drives. In /boot/config/go I put:
# Custom sdspin (to handle substandard USB drive controller) cp /usr/local/sbin/sdspin /usr/local/sbin/sdspin.unraid cp /boot/extras/utilities/sdspin /usr/local/sbin/sdspin chmod 755 /usr/local/sbin/sdspinwhere /boot/extras/utilities/sdspin was my customized version:
#!/bin/bash # spin device up or down or get spinning status # $1 device name # $2 up or down or status # ATA only # hattip to Community Dev @doron RDEVNAME=/dev/${1#'/dev/'} # So that we can be called with either "sdX" or "/dev/sdX" get_device_id () { LABEL="${RDEVNAME:5}" DEVICE_ID=`ls -l /dev/disk/by-id/ | grep -v " wwn-" | grep "${LABEL}$" | rev | cut -d ' ' -f3 | rev` echo "$DEVICE_ID" } smartctl_status () { OUTPUT=$(/usr/sbin/smartctl --nocheck standby -i $RDEVNAME 2>&1) RET=$? # Ignore Bit 1 error (Device open failed) which usually indicates standby [[ $RET == 2 && $(($RET & 2)) == 2 ]] && RET=0 } hdparm () { OUTPUT=$(/usr/sbin/hdparm $1 $RDEVNAME 2>&1) RET=$? # ignore missing sense warning which might be caused by a substandard USB interface if [[ ! "$(get_device_id)" =~ ^usb-.* ]]; then [[ $RET == 0 && ${OUTPUT,,} =~ "bad/missing sense" ]] && RET=1 fi } if [[ "$2" == "up" ]]; then hdparm "-S0" elif [[ "$2" == "down" ]]; then hdparm "-y" else # use smartctl (instead of hdparm) for USB drives if [[ "$(get_device_id)" =~ ^usb-.* ]]; then smartctl_status else hdparm "-C" fi [[ $RET == 0 && ${OUTPUT,,} =~ "standby" ]] && RET=2 fiVery hacky.
-
You can even include unraid notifications (in addition to the "echo" printouts.)
Notices ("normal") appear in green:
/usr/local/emhttp/webGui/scripts/notify -e "Unraid Server Notice" -s "Backup Critical Files" -d "Backup complete" -i "normal"and alerts in red:
/usr/local/emhttp/webGui/scripts/notify -e "Unraid Server Error" -s "Backup Critical Files" -d "Backup error" -i "alert" -
If Windows backs up on the same day every week you could add a user script to unRAID that runs later or the next day.
I just wrote one similar for another device.
You may have to tweak it slightly for unraid/your use case. Carefully test it because it calls rm and you don't want to accidentally wipe your array (or at least comment out the rm line until you're sure it works.)
#!/bin/bash # # Backup critical files # ## Options # Number of backups to keep NUM_TO_KEEP=6 # directory to be backed up BACKUP_SOURCE="/mnt/hdd/share/unraid" # directory to store backups BACKUP_DEST="/mnt/hdd/share/backup" # Begin backup dest_file="${BACKUP_DEST}/unraid-$(date '+%Y-%m-%d')" echo "Archiving critical files to: ${dest_file}.tar.gz" tar -czf ${dest_file}.tar.gz ${BACKUP_SOURCE} if [[ $? != 0 ]]; then # Alert echo "Critical Backup Archiving FAILED" exit 1 fi # make it readable by all chmod a+r ${dest_file}.tar.gz # Clear out all but X most recent (cd ${BACKUP_DEST}/ && rm `ls -t *.tar.gz | awk "NR>$NUM_TO_KEEP"`) 2>/dev/null # Alert succes echo "Critical Backup Archiving Completed" exit 0-
 1
1
-
-
3 hours ago, dlandon said:
You can't spin the disk down that way. Unraid controls the spin up/down of the disk in later versions of 6.9 and 6.10. You are confusing Unraid. Go to the UD web page and look at the help you'll see a command to spin down the disk using the UD script that uses the Unraid api. Unraid then knows the proper spin status.
Thanks, I see this command in help:
/usr/local/sbin/rc.unassigned spindown devXI wish I'd known about it earlier, still the script worked well for me in 6.8 and 6.9.
4 hours ago, jinlife said:Bad news, it still work like before even disabled the power management.
Run this script and disk will spin down, but the standy mode will only last for 20~30 minutes, then it will spin up unexpectly, then the script will spin down it again... There is no log in syslog.
jinlife:
I'd say disable the script for now, unmount the drive, run the command above where "devX is the device name in the UD page. If the device name is 'Dev 1', then use dev1 as the device to spin down."
-
On 8/11/2021 at 9:18 PM, jinlife said:
Thanks for the great script.
But my unraid has problem that the USB HDD spin up unexpected every hours, so the script runs every hours and I can see the HDD is always awake in the script log. I have already unmounted the USB HDD but don't know why it is still awaken frequently. Any suggestions?
You say the USB HDD spins up every hour, so it must be spinning down.
Is it spinning down on its own or is my script spinning it down?
You could try disabling the USB HDD's internal power management:
Find the disk's ID with:
find /dev/disk/by-id/ ! -name '*-part1'The line for your USB disk will look like:
/dev/disk/by-id/usb-XXXXXXTake that and disable power management with the command:
/usr/sbin/smartctl -s apm,off /dev/disk/by-id/usb-XXXXXXIf that fixes it add the command exactly the way you ran it to your /boot/config/go because reboot resets it.
-
46 minutes ago, danktankk said:
thanks ill give that a try
If I remember right you need the intel-gpu-telegraf docker to collect the stats in telegraf.
EDIT: Now that I think about it this plugin may not be necessary for stats collection, just the docker. Not sure, sorry it's been a while since I set it up.
EDIT 2: Ha, apparently I had my plugins confused. It's the Intel GPU TOP plugin that works with the docker to collect stats.
-
32 minutes ago, danktankk said:
Thats definitely an option, but I think I will just remove the plugin. Thanks for the reply.
I think you can disable UI Automatic Refresh in the plugin's settings to mostly solve it. Dashboard reporting's less useful than stats to track usage, e.g. through Grafana.
-
34 minutes ago, danktankk said:
Simply ignoring this message isnt that easy when you have to look through your log files and see hundreds if not thousands of these messages. Its a lot to sort through. Is there a way to keep this out of the log files at least?
If you use syslog server you can add them to a blocklist.
Here's an excerpt from my go file:
# Suppress time capsule cifs errors echo ":msg,contains,\"bogus file nlink value\" stop" >> /etc/rsyslog.d/01-blocklist.conf echo ":msg,contains,\"cifs_all_info_to_fattr\" stop" >> /etc/rsyslog.d/01-blocklist.conf /etc/rc.d/rc.rsyslogd restart-
1
-
-
On 7/18/2021 at 8:52 PM, DrJake said:
Hi CS, no, I didn't. After diagnosing the Plex library indexing thing, I monitored the unraid server occasionally, and the disks are sleeping most of the time. So I haven't bothered with the *.tmp files. If you figure it out, please do post
")
I believe I found the culprit - Fix Common Problems.
And here's the fix (I'm surprised it's not the default):

-
5 minutes ago, mgutt said:
Did you try Ubuntu?
I have not. Maybe when I get more time. Could it be a difference in kernels? Maybe 6.10 will fix it.
-
3 minutes ago, mgutt said:
I have the C246N-WU2
Very nice. I keep my fingers crossed for a W580 m-itx.
2 minutes ago, mgutt said:Did you try "pcie_aspm=force"
Yes. No difference as far as I can tell:
root@NAS:~# dmesg | grep -i aspm [ 0.000000] Command line: BOOT_IMAGE=/bzimage initrd=/bzroot mitigations=off intel_iommu=on,igfx_off pcie_aspm=force [ 0.103794] Kernel command line: BOOT_IMAGE=/bzimage initrd=/bzroot mitigations=off intel_iommu=on,igfx_off pcie_aspm=force [ 0.103948] PCIe ASPM is forcibly enabled [ 0.454763] acpi PNP0A08:00: _OSC: OS supports [ExtendedConfig ASPM ClockPM Segments MSI HPX-Type3] root@NAS:~# lspci -vv | grep ASPM LnkCap: Port #3, Speed 5GT/s, Width x1, ASPM L0s L1, Exit Latency L0s <1us, L1 <4us ClockPM- Surprise- LLActRep+ BwNot+ ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- LnkCap: Port #4, Speed 5GT/s, Width x1, ASPM not supported ClockPM- Surprise- LLActRep+ BwNot+ ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- LnkCap: Port #5, Speed 5GT/s, Width x1, ASPM not supported ClockPM- Surprise- LLActRep+ BwNot+ ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCtl1: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ LnkCap: Port #6, Speed 5GT/s, Width x1, ASPM not supported ClockPM- Surprise- LLActRep+ BwNot+ ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCtl1: PCI-PM_L1.2- PCI-PM_L1.1- ASPM_L1.2- ASPM_L1.1- pcilib: sysfs_read_vpd: read failed: Input/output error LnkCap: Port #0, Speed 5GT/s, Width x8, ASPM L0s, Exit Latency L0s <64ns ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp- LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCap: Port #0, Speed 5GT/s, Width x1, ASPM L0s L1, Exit Latency L0s <4us, L1 unlimited ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp- LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCap: Port #0, Speed 2.5GT/s, Width x1, ASPM L0s L1, Exit Latency L0s unlimited, L1 <64us ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ L1SubCap: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ L1_PM_Substates+ L1SubCtl1: PCI-PM_L1.2+ PCI-PM_L1.1+ ASPM_L1.2+ ASPM_L1.1+ LnkCap: Port #1, Speed 5GT/s, Width x1, ASPM not supported ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp- LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ root@NAS:~# -
On 7/29/2021 at 10:15 AM, mgutt said:
I tried to verify this, but my Unraid server boots with ASPM enabled?!
I believe you have (or had) a j5005?
With my j5005 I have the same problem as the German user.
ASPM is enabled in the BIOS and apparently supported:
root@NAS:~# dmesg | grep -i aspm [ 0.454584] acpi PNP0A08:00: _OSC: OS supports [ExtendedConfig ASPM ClockPM Segments MSI HPX-Type3]But disabled on all devices:
root@NAS:~# lspci -vv | grep 'ASPM.*abled' LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ pcilib: sysfs_read_vpd: read failed: Input/output error LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+-
1
-
-
57 minutes ago, charley said:
Can we please please get a newbee friendly tutorial how to restore a vm?
A few others also asked and noone really seams to care.
I figured out that i have datestamped files. Always 3:
FD-File like ....VARS-pure-efi
QCOW2 File...
xml file...
I guess i know what to do with the xml and the qcow2, but where do i put the fd file?
From the XML view of my VM it appears the FD file goes in:
/etc/libvirt/qemu/nvram/Which is one level down from the XML file in:
/etc/libvirt/qemu/ -
On 7/26/2021 at 2:40 AM, cracyfloyd said:
Since the last handbrake update i use its breake the intel QSV encoding. before it works for a couple of month. i can see the hardware profiles and i can select and start a job but the encoding doesnt work the encoding stops after i started.
in the log i can see: " Failure to initialise thread 'Quick Sync Video encoder (Intel Media SDK)'. plex working with hardware encoding and the device /dev/dri is already be there.
?????
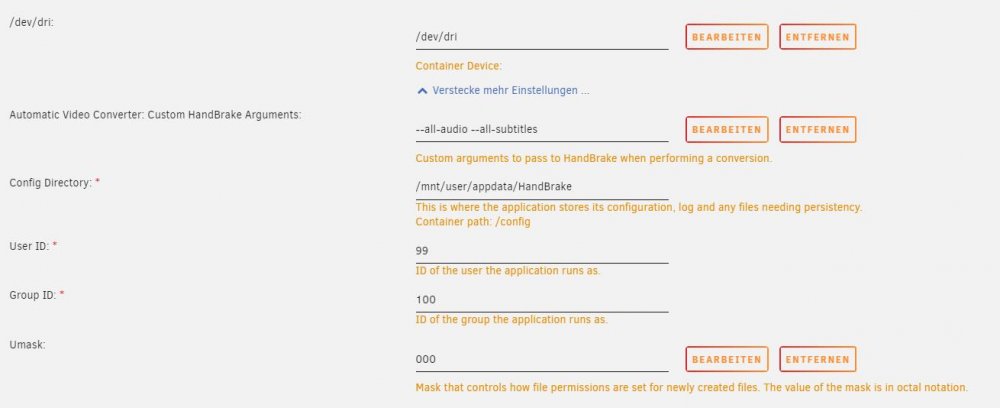
Same on my j5005 (UHD 605)
I reverted to the last tag:

then restored appdata and the template (/boot/config/plugins/dockerMan/templates-user/my-HandBrake.xml) from backup and all is well.
-
1
-
-
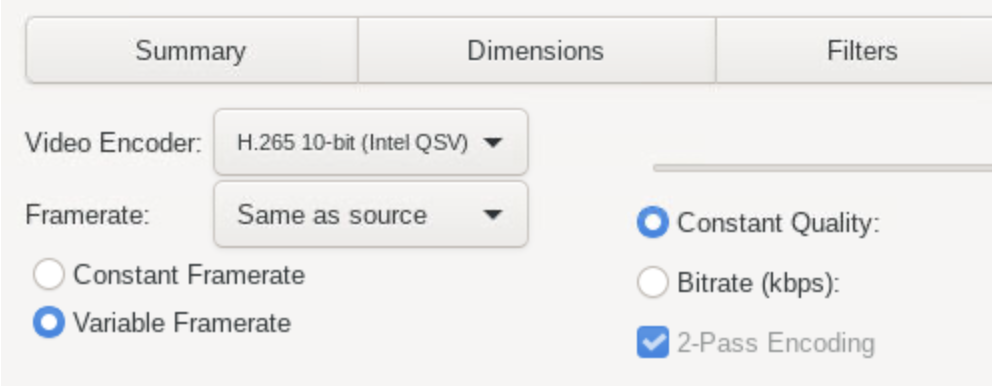
48 minutes ago, OFark said:
What encoder are you using in Handbrake?
Intel QSV:
-
5 hours ago, OFark said:
Have you passed /dev/dri to both? I use QSV in Handbrake just fine.
Yes. You can see it working in second graph (Handbrake conversion.) The GPU's utilized but at a much lower level vs Emby. Seems this problem's unique to me but will post if I make any progress.
Note: I have all video encoding filters disabled in Handbrake settings.
-
1 hour ago, OFark said:
Well it seems like it's not doing anything hardware. Hardware decoding is next to pointless these days.
Interesting. My conversions are noticeably faster with hardware encoding than pure CPU so it must be doing something.
Here are graphs of GPU utilization (dashed line) courtesy of gpu-monitor.
Emby transcoding:
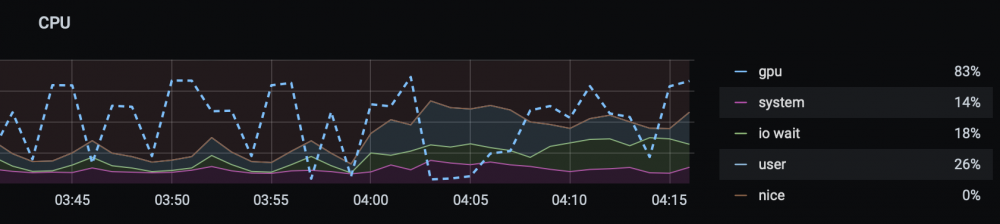
Handbrake hardware conversion:
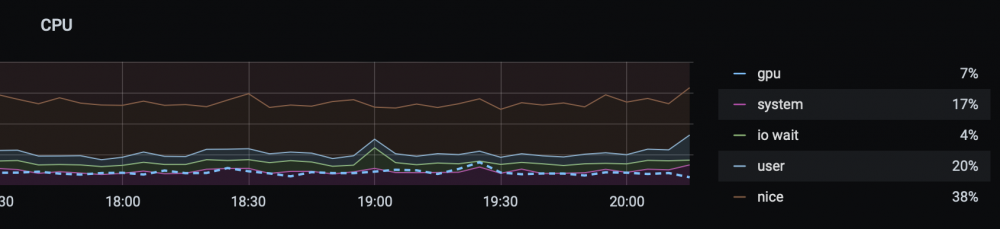
Both using the intel quicksync driver and assigned to 3 CPUs.
I wonder what accounts for the difference.
-
Slightly off-topic but does anyone know why Handbrake doesn't do hardware decoding?
When I convert h264 -> h265 using hardware encoding (thanks Djoss) I see low iGPU utilization and high CPU. Contrast with Emby/ffmpeg h265 -> h264 which has high GPU utilization and low CPU.
Seems like such an obvious oversight I wonder if there's something I'm missing.
-
On 1/10/2021 at 12:18 AM, DrJake said:
I ended up moving the ISOs folder to cache, only took up like 15Gb of space, which is quite tolerable for me.
I've been monitoring the fileactivity for a few days since last reporting here, it has been working very well, I think the disks only needs to spin up when I watch Plex, and at 3.40am for the movers.
Regarding the syncthing problem, I still don't really know how it works, but in my current setup it appears to be not scanning much.
In the fileactivity log, I see the following (I don't think it happens daily, as I haven't noticed it before), does anyone know what is creating the .tmp files? if it'll cause the drives to spin up, and how to avoid it?
Jan 10 04:30:13 CREATE => /mnt/disk1/2041296744.tmp
Jan 10 04:30:13 OPEN => /mnt/disk1/2041296744.tmp
Jan 10 04:30:13 OPEN => /mnt/disk1/2041296744.tmp
Jan 10 04:30:13 DELETE => /mnt/disk1/2041296744.tmpJan 10 04:30:13 CREATE => /mnt/disk2/1694051432.tmp
Jan 10 04:30:13 OPEN => /mnt/disk2/1694051432.tmp
Jan 10 04:30:13 OPEN => /mnt/disk2/1694051432.tmp
Jan 10 04:30:13 DELETE => /mnt/disk2/1694051432.tmpJan 10 04:30:13 CREATE => /mnt/disk3/2030880645.tmp
Jan 10 04:30:13 OPEN => /mnt/disk3/2030880645.tmp
Jan 10 04:30:13 DELETE => /mnt/disk3/2030880645.tmp
Did you ever figure out what was causing this? I'm also seeing it.
-
The UPS should report energy usage which you can view in unraid's dashboard and track with e.g. Grafana.
I have a similar configuration but no smart plug.
It wasn't "plug and play" at least with my CyberPower model.
Here's how I set it up:
-
Well that explains that.
If there's no reliable way to do it with the template (I don't really know docker or unraid's specific implementation) I guess I could cron a user script that calls it with docker exec, but it would have to be more complex to guard against multiple instances.
Thanks.
-
I run the official Emby container with the following Post Arguments to call a custom script which prunes the transcoding directory:
&& docker exec EmbyServer sh -c 'watch -n30 "/system-share/transcoding-temp-fix.sh" > /transcode/transcoding-temp-fix.log &'The problem is it doesn't run on restart.
However, if I edit the container and click Apply it runs every time.
Am I doing something obviously wrong and if not how should I go about debugging it?
I don't see anything suspicious in the container or unraid's system log.
-
2 hours ago, itimpi said:
Does the plugin only back up the vdisk files for a VM or does it back up the XML (and potentially BIOS) files that are stored in the libvirt image?
Looks like it backs up all of them. See log from a recent run (core-backup/domains is the destination directory)
2021-04-27 10:41:02 information: Debian is shut off. vm desired state is shut off. can_backup_vm set to y. 2021-04-27 10:41:02 information: actually_copy_files is 1. 2021-04-27 10:41:02 information: can_backup_vm flag is y. starting backup of Debian configuration, nvram, and vdisk(s). sending incremental file list Debian.xml sent 7,343 bytes received 35 bytes 14,756.00 bytes/sec total size is 7,237 speedup is 0.98 2021-04-27 10:41:02 information: copy of Debian.xml to /mnt/user/core-backup/domains/Debian/20210427_1040_Debian.xml complete. sending incremental file list 55c212-015b-6fc0-dada-cba0018034_VARS-pure-efi.fd sent 131,246 bytes received 35 bytes 262,562.00 bytes/sec total size is 131,072 speedup is 1.00 2021-04-27 10:41:02 information: copy of /etc/libvirt/qemu/nvram/55c212-015b-6fc0-dada-cb6ca0018034_VARS-pure-efi.fd to /mnt/user/core-backup/domains/Debian/20210427_1040_55c21fa2-015b-6fc0-dada-cba0018034_VARS-pure-efi.fd complete. '/mnt/cache/domains/Debian/vdisk1.img' -> '/mnt/user/core-backup/domains/Debian/20210427_1040_vdisk1.img' 2021-04-27 10:42:19 information: copy of /mnt/cache/domains/Debian/vdisk1.img to /mnt/user/core-backup/domains/Debian/20210427_1040_vdisk1.img complete. 2021-04-27 10:42:19 information: backup of /mnt/cache/domains/Debian/vdisk1.img vdisk to /mnt/user/core-backup/domains/Debian/20210427_1040_vdisk1.img complete. 2021-04-27 10:42:19 information: extension for /mnt/user/isos/debian-10.3.0-amd64-netinst.iso on Debian was found in vdisks_extensions_to_skip. skipping disk. 2021-04-27 10:42:19 information: the extensions of the vdisks that were backed up are img. 2021-04-27 10:42:19 information: vm_state is shut off. vm_original_state is running. starting Debian. Domain Debian started 2021-04-27 10:42:20 information: backup of Debian to /mnt/user/core-backup/domains/Debian completed. -
I had a strange problem where maybe every fifth boot my Mojave VM wouldn't have a network connection (using e1000-82545em.) The adapter (Realtek RTL8111H) was detected but no connection.
I fixed it by manually configuring the adapter in the VM. Dozens of boots so far and it hasn't happened again. Hope that's helpful.
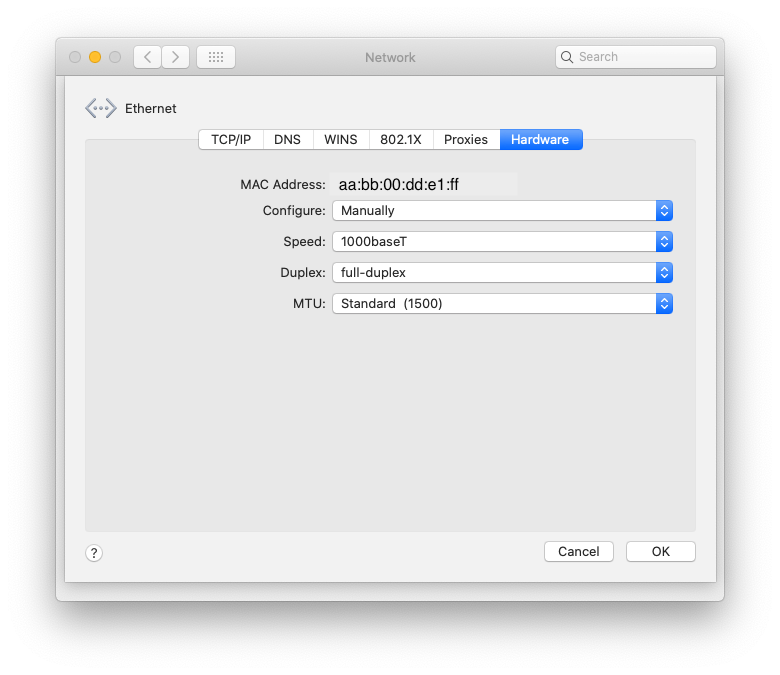









Reduce power consumption with powertop
in User Customizations
Posted · Edited by CS01-HS
Due to the error above I've run my integrated ASM1062 controller with /sys/class/scsi_host/host*/link_power_management_policy set to max_performance (the default) vs --auto-tune's med_power_with_dipm.
After updating to 6.10.0-rc1 a few days ago I tried powertop's med_power_with_dipm again and so far the error hasn't reappeared. Whatever incompatibility appears to be solved.
EDIT: I spoke too soon. Under heavy load I saw hard resets again and the (Seagate) drive's Command timeout entry increased by two.