Mathervius
-
Posts
43 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Mathervius
-
I have been trying to eliminate call trace issues on my server and have read through lots of info on the forum. Original post After a bunch of issues I was able to get things working better. Now I have br0 up and running on one NIC and br2 running on a second NIC. br0 is the UNRAID network and I have a static IP set for it in pfSense, which is working well. Following a forum thread I set br2 up with it's IP set to none. I then set my docker network to use br2 and gave it a DHCP pool and that's working perfectly. My VMs are also on br2. I would like to have a static IP set for br2 within pfSense so that I can add it to an Alias but nothing on br2 network shows up in the DHCP lease section of pfSense. All of the br2 IPs assigned are accessible over the LAN without issue but do not show up in my DHCP leases. Should I assign an IP address to br2 to do what I am wanting or something else? Any ideas? Thanks for reading!
-
I see this in the log a couple times Tower kernel: bond0: the permanent HWaddr of eth0 - MAC:ADDRESS - is still in use by bond0 - set the HWaddr of eth0 to a different address to avoid conflicts
-
After reading through a bunch of forum posts I tried putting the docker network onto its own NIC. Anytime I change the network settings I am no longer able to reach the machine over LAN. I then deleted the network.cfg and rebooted into GUI mode. I made the suggested adjustments to put docker on its own NIC and once again I lost all network connectivity. I have now adjusted eth0 to: Bonding = no, Enable bridge = yes, Bridging members of br0 = eth0. If I try and set eth0 to a static IP I lose network connectivity again. I have it set with a static IP from pfSense already but previously I had it set as static in UNRAID as well and it worked no problem. eth1, eth2, and eth3 all show as not configured now. If I make any adjustments to them I lose network connectivity and have to delete the network.cfg file and reboot in order to get connected again. The dashboard still shows that I'm using bond0, which is what it always showed before. It seems like it would match the network settings page though? Sorry for the long post but I am genuinely stuck here.
-
OK, I read through that post but my dockers don't have an IP address assigned to them. Mine are Host, Bridge, Proxynet (letsencrypt), and a VPN container. Could one of those networks cause the macvlan issue? Maybe it's because I have docker set to be able to communicate with the host network (Host access to custom networks)?
-
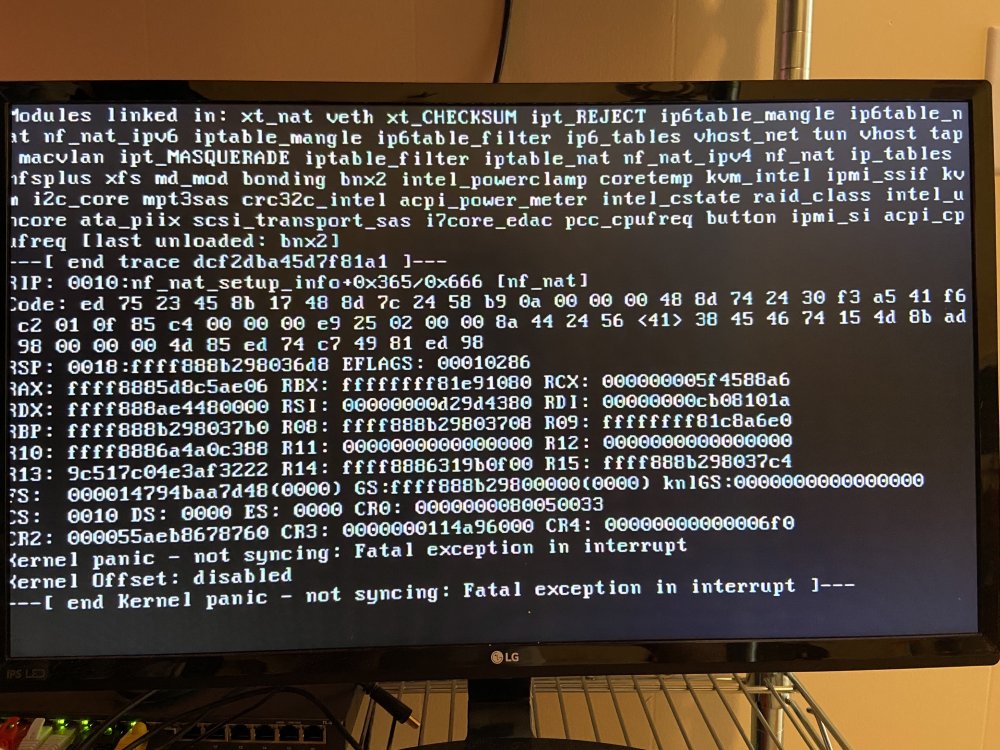
Well, the crashes are back.... I was finally able to setup Graylog since my other syslog server (unraid) wasn't capturing the issue. I've attached the logs. The other issue is that it seems Graylog didn't export everything in the exact order that it came in. Sorry about that... This came in after rebooting the server and had it running for about an hour: May 26 19:17:08 Tower kernel: RIP: 0010:__nf_conntrack_confirm+0xa0/0x69e May 26 19:17:08 Tower kernel: Code: 04 e8 56 fb ff ff 44 89 f2 44 89 ff 89 c6 41 89 c4 e8 7f f9 ff ff 48 8b 4c 24 08 84 c0 75 af 48 8b 85 80 00 00 00 a8 08 74 26 <0f> 0b 44 89 e6 44 89 ff 45 31 f6 e8 95 f1 ff ff be 00 02 00 00 48 May 26 19:17:08 Tower kernel: RSP: 0018:ffff8885a99c3d58 EFLAGS: 00010202 May 26 19:17:08 Tower kernel: RAX: 0000000000000188 RBX: ffff888574348500 RCX: ffff888ad98fce18 May 26 19:17:08 Tower kernel: RDX: 0000000000000001 RSI: 0000000000000001 RDI: ffffffff81e091c4 May 26 19:17:08 Tower kernel: RBP: ffff888ad98fcdc0 R08: 00000000e48f2dcb R09: ffffffff81c8aa80 May 26 19:17:08 Tower kernel: R10: 0000000000000158 R11: ffffffff81e91080 R12: 000000000000baf1 May 26 19:17:08 Tower kernel: R13: ffffffff81e91080 R14: 0000000000000000 R15: 000000000000eaf0 May 26 19:17:08 Tower kernel: FS: 0000000000000000(0000) GS:ffff8885a99c0000(0000) knlGS:0000000000000000 May 26 19:17:08 Tower kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 May 26 19:17:08 Tower kernel: CR2: 0000146fb1114000 CR3: 0000000001e0a000 CR4: 00000000000006e0 May 26 19:17:08 Tower kernel: Call Trace: May 26 19:17:08 Tower kernel: <IRQ> May 26 19:17:08 Tower kernel: ipv4_confirm+0xaf/0xb9 May 26 19:17:08 Tower kernel: nf_hook_slow+0x3a/0x90 May 26 19:17:08 Tower kernel: ip_local_deliver+0xad/0xdc May 26 19:17:08 Tower kernel: ? ip_sublist_rcv_finish+0x54/0x54 May 26 19:17:08 Tower kernel: ip_sabotage_in+0x38/0x3e May 26 19:17:08 Tower kernel: nf_hook_slow+0x3a/0x90 May 26 19:17:08 Tower kernel: ip_rcv+0x8e/0xbe May 26 19:17:08 Tower kernel: ? ip_rcv_finish_core.isra.0+0x2e1/0x2e1 May 26 19:17:08 Tower kernel: __netif_receive_skb_one_core+0x53/0x6f May 26 19:17:08 Tower kernel: process_backlog+0x77/0x10e May 26 19:17:08 Tower kernel: net_rx_action+0x107/0x26c May 26 19:17:08 Tower kernel: __do_softirq+0xc9/0x1d7 May 26 19:17:08 Tower kernel: do_softirq_own_stack+0x2a/0x40 May 26 19:17:08 Tower kernel: </IRQ> May 26 19:17:08 Tower kernel: do_softirq+0x4d/0x5a May 26 19:17:08 Tower kernel: netif_rx_ni+0x1c/0x22 May 26 19:17:08 Tower kernel: macvlan_broadcast+0x111/0x156 [macvlan] May 26 19:17:08 Tower kernel: ? __switch_to_asm+0x41/0x70 May 26 19:17:08 Tower kernel: macvlan_process_broadcast+0xea/0x128 [macvlan] May 26 19:17:08 Tower kernel: process_one_work+0x16e/0x24f May 26 19:17:08 Tower kernel: worker_thread+0x1e2/0x2b8 May 26 19:17:08 Tower kernel: ? rescuer_thread+0x2a7/0x2a7 May 26 19:17:08 Tower kernel: kthread+0x10c/0x114 May 26 19:17:08 Tower kernel: ? kthread_park+0x89/0x89 May 26 19:17:08 Tower kernel: ret_from_fork+0x35/0x40 May 26 19:17:08 Tower kernel: ---[ end trace b58796bea918bc16 ]--- It didn't crash the server this time though. Sorry I just don't have experience with this kind of issue... graylog-search-result-relative-0.txt
-
I'm assuming you looked at this guide? https://kodi.wiki/view/Adding_video_sources#Adding_Remote_sources Should be the same using an UNRAID SMB share I think.
-
Have you tried testing with iperf to see the speed between your two devices on your LAN? What OS are you transferring from? MacOS SMB over wifi has been slow for me since I was on High Sierrra. The other thing you might run into is the speed of the disks you are reading from/writing to. I've had much better luck running docker containers on the UNRAID box itself rather than using a separate box.
-
The same thing happened to me on High Sierra as well....
-
This happens to me all the time unfortunately. Usually relaunching Finder fixes the issue and then you remount the volume(s) again.
-
I am using rsync from my Ubuntu box to put the backups on UNRAID and getting between 80 - 120 Mbps transfer speeds. Something is weird with MacOS + UNRAID + SMB I guess.
-
Nextcloud, letsencrypt, welcome to our server message
Mathervius replied to ljt's topic in General Support
Maybe try using your IP instead of the hostname set $upstream_app nextcloud; On my server I always have to use the IP. I'm sure this could be fixed somewhere but I use a static IP and it's no issue for me. -
Yes, I set it up exactly like my bare metal Ubuntu 19.10 setup, which is currently working perfectly for the last several days.
-
Unfortunately, this did not work. I already had an Ubuntu 19.10 desktop VM running so I added the packages needed for TimeMachine and it does not work. None of the Macs on my network can see the TimeMachine share on the network. It looks like the VM isn't able to advertise on the local network even with avahi running. If someone knows a workaround I'm willing to test this again.
-
I have this exact issue. It's frustrating and was not an issue on 6.7.2 for me. I can get a backup to begin but after about 14 hours it will just fail. I turned a very low powered Ubuntu box into a TimeMachine server yesterday and all of my machines have been backing up to it without issue. It's also much faster than with UNRAID 6.8.3. I kept reading that backing up over the network is glitchy but it was never an issue for me. I'm not sure what changed but it really sucks to not be able to backup straight to my UNRAID box anymore.
-
I just wanted to post a quick update about this issue. Since turning off the tdarr_aio docker there have been no crashes for 8 days, which is more like my normal experience with UNRAID. I really liked that container but for now I'm going back to my own solution.
-
Thank you for getting back to me! The only recent changes are adding syncthing and tdarr_aio. They have both been running without any issues until this all started about two weeks ago. I believe you are correct about the ffdetect error being emby. That was my impression as well. My MTU is default of 1500. I'm going to setup the syslog server now. Thank you for that idea! I have tdarr_aio off for now as it isn't essential and Im going to wait a few days and see if it happens again. It seems to be about every 48hrs give or take a little.
-
Just bumping this in the hopes that someone has some input or experience with issues like this...
-
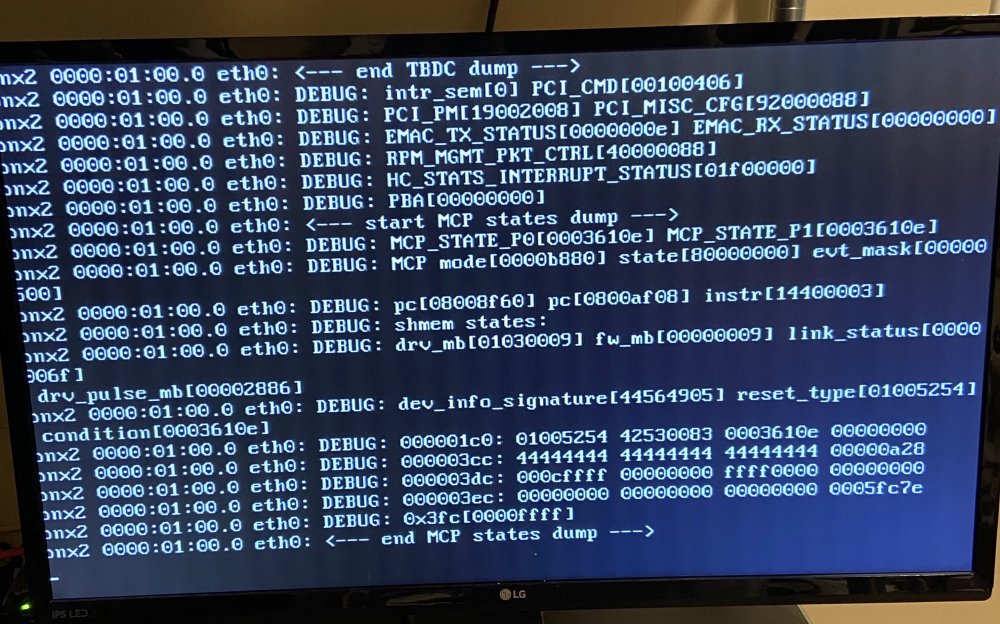
Hi Guys, Server stats: Dell T610 Dual Xeon E5530 CPUs 44GB RAM UNRAID 6.8.3 Plugins: CA Auto Update Applications CA Backup / Restore CA Config Editor Custom Tab Local Master SSD TRIM System Statistics Fix common problems Nerd Tools NUT Server Layout Speed Test Theme engine Tips and Tweaks Unassigned Drives (both) User scripts I've been running UNRAID for about a year now and have no issues and it has been solid, until now! About every two days now my server will crash. I've searched the web and the only things I can really find have to do with a kernel issue that affects the NIC. I honestly have no idea because when this happens I can't access anything on the server. The monitor plugged into the server just keeps repeating the same error message over and over and the only thing I can do is hold down the power button and force a reboot. I've only been able to find similar issues that are pretty dated involving other OS. It seems like those issues have something to do with the kernel. I'm attaching a picture of the error. Apologies because I can't access any other diagnostics when this happens. Syslog and image of the error attached... tower-syslog-20200413-0241.zip