




unburt
Members
-
Joined
-
Last visited
-
Hi, how do I update from a very old version of the CA plugin? I have just updated one of my servers from a 2022 release up to Unraid 7.0.1 and my "Apps" tab does not load properly and just shows a spinner forever. The current installation instructions indicate you can get the plugin from the Apps tab which is a problem for me as it will not load. Can I use the URL of a plg file to update? Where can I find that URL? My CA plugin version is 2022.04.03. The plugins page says that version 2024.12.14 is available. But when I click Update the output seems to indicate it is just staying on 2022.04.03. And also when I refresh the Plugins page it still says I'm on 2022.04.03. And I guess this is still kind of problematic because the actual latest version of CA seems to be 2026.05.15gh. Here is the output I get when I try to update the plugin by pressing the Update button. plugin: updating: community.applications.plg Executing hook script: pre_plugin_checks Cleaning Up Old Versions Fixing pinned apps Setting up cron for background notifications +============================================================================== | Upgrading community.applications-2022.04.03-x86_64-1 package using /boot/config/plugins/community.applications/community.applications-2022.04.03-x86_64-1.txz +============================================================================== Pre-installing package community.applications-2022.04.03-x86_64-1... Removing package: community.applications-2022.04.03-x86_64-1-upgraded-2026-05-28,10:04:47 Verifying package community.applications-2022.04.03-x86_64-1.txz. Installing package community.applications-2022.04.03-x86_64-1.txz: PACKAGE DESCRIPTION: Package community.applications-2022.04.03-x86_64-1.txz installed. Package community.applications-2022.04.03-x86_64-1 upgraded with new package /boot/config/plugins/community.applications/community.applications-2022.04.03-x86_64-1.txz. Creating Directories Adjusting icon for unRaid version ---------------------------------------------------- community.applications has been installed. Copyright 2015-2022, Andrew Zawadzki Version: 2022.04.03 ---------------------------------------------------- plugin: community.applications.plg updated Executing hook script: post_plugin_checks
-
Thanks for creating this plugin! Since nerdpack tools are no longer compatible on newer Unraid versions, this seems like a good way to get tmux to run long duration terminal commands. I am using it for doing an initial rsync of data from an old system to a new system which will be many hours. I have a question though: I am curious why I cannot scroll back though. Pressing the arrow keys, using the Page Up or Page Down keys or using the mouse wheel results in control characters being printed instead of scrolling up to see past output. The output looks something like this: ^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[5~^[[5~^[[A^[[A^[[B^[[B^[[5~^[[5~^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[A^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[B^[[BIs this normal? edit: Actually, maybe it has to do with my rsync options. rsync -avu --numeric-ids --progress -e "ssh -T -o Compression=no -x" "[email protected]:/mnt/user/files/" "/mnt/user/Backup/files/"
-
My rebuild completed and seems like the array is back to normal. Thank you for the help! tower-diagnostics-20260121-1432.zip
-
Thanks! I started a rebuild. Hopefully I'm back to normal in about a day (16TB drives).
-
Thanks for looking at it with me. So, to rebuild the disk I will: Write down the model and serial number of the disk. Unassign the disk Start the array Stop the aray Then reassign the disk (using the model/serial number to be sure I'm assigning the correct disk) And then the rebuild will start when I start the array. Does that sound right?
-
Sorry, I did not realize the information would be lacking the way I did it. I have started the array and taken another diagnostics file. I also have the output from earlier when I did the xfs repair (after I zeroed the log). tower-diagnostics-20260120-1225.zip xfs_repair disk 4 fix after zero log.txt
-
Zeroing the log and fixing the errors seemed to have completed successfully. However, Disk 4 is still disabled with the 'x' icon. I've attached new diagnostics to this post. I have rebooted the server and started it in Maintenance Mode and did another filesystem check on that disk. It says there are no errors. Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 4 - agno = 11 - agno = 14 - agno = 3 - agno = 6 - agno = 5 - agno = 8 - agno = 9 - agno = 1 - agno = 10 - agno = 13 - agno = 12 - agno = 2 - agno = 7 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. tower-diagnostics-20260120-0911.zip
-
I am now trying to proceed using the gui. But am not sure if I'm going about this correctly? It suggests I should mount the filesystem, how do I do that? I have started the array in maintenance mode. I click on the disabled Disk's name ("Disk 4") and am brought to its settings page at http://192.168.1.152/Main/Device?name=disk4 In the "Check Filesystem Status" section, I clicked the button to check the file system. It outputs a lot of identified errors in the box labeled "xfs_repair status". The button changes to something like "fix" (I forgot the exact wording) and I click it. It outputs the following in the "xfs_repair status" box: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If the filesystem is a snapshot of a mounted filesystem, you may need to give mount the nouuid option. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. The button has now changed to say "ZERO LOG" with the note "Dirty log detected." written beside it. And the following warning beneath: "Note: While there is some risk, if it is not possible to first mount the filesystem to clear the log, zeroing it is the only option to try and repair the filesystem, and in most cases it results in little or no data loss." I'm stuck on how do I mount the filesystem? I have tried stopping the array (exiting Maintenance Mode) and starting the array normally. It started up, Disk 4 contents were emulated. Disk 4 does not seem to get mounted due to the existing errors. Then I stopped the array again and started it in Maintenance Mode once more to check the xfs_repair status and see if perhaps any new output appeared. Nothing changed. The same text as before remained. What should I do? I've attached a screenshot in case it helps illustrate what I'm seeing. The upper portion shows my array devices and the "x" icon beside Disk 4. And the lower portion shows the status page of Disk 4 and my progress so far with xfs_repair.
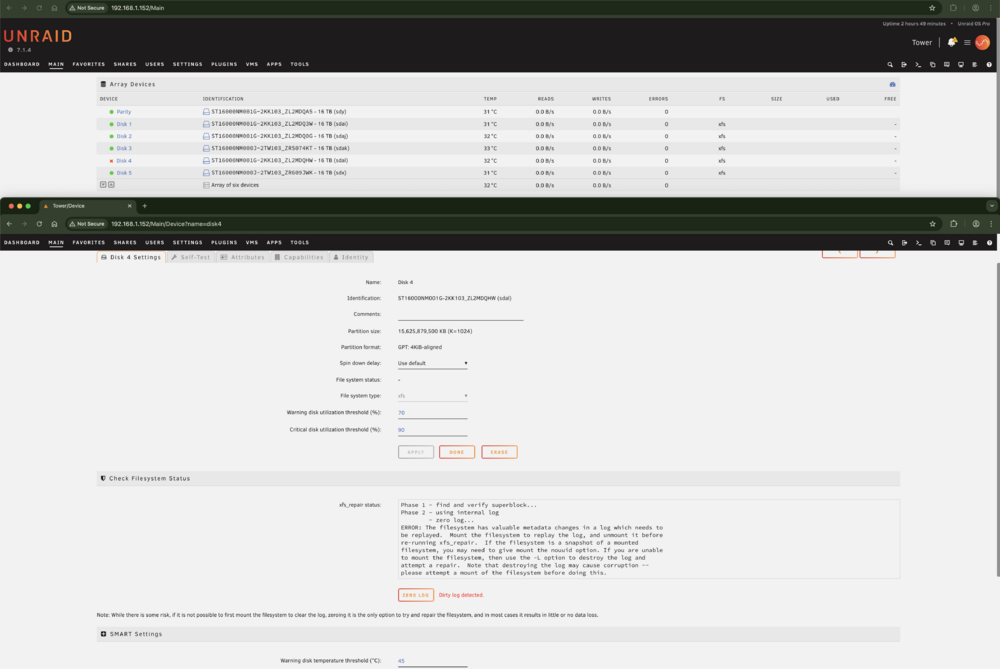
-
oh I see. That makes sense. I guess I will do the filesystem repair then. Thank you for the advice
-
Doesn't rebuilding the disk rewrite every sector of the disk, filesystem and all? So, while it's not a direct fix for the filesystem corruption, it would resolve the issue if I understand correctly. I realize that asking how long xfs_repair will take is a very open ended question. But I'm concerned that it may take days and days trying to correct the errors. I know that a rebuild takes approximately 1 day for my 16TB drives so I'm comfortable with that amount of time waiting. Is there any way to guess how long xfs_repair will take relative to a rebuild? I've attached a new diagnostics file that I've just generated after several boot/restarts of the server just poking around trying to gauge the health of the system before I bring the array online. tower-diagnostics-20260119-1309.zip
-
I asked Unraid to shutdown and it actually managed to shut down. It managed to unmount the disk I guess. However, when I brought the array back online, disk 4 appears to have major filesystem corruption. It is unmountable and when I did a filesystem check in maintenance mode (xfs_repair -n) it shows a lot of problems. I guess I will have to rebuild the disk onto a new one.
-
I found my docker applications not responding, I believe it is because my cache filled up. There were lots of messages in the log about I/O error and "BTRFS error (device loop2)" which I googled and found to be related to docker.img (I have a docker folder if that is relevant). So, that seems to make sense because I did fill up my cache pool. I tried to stop the array and it is stuck while trying to unmount disks. There is a lot lot these messages in the log that seem to be endless. I was still able to get system diagnostics while it was doing this. So I have attached that. I am wondering what I can do? Is it possible to interrupt it besides pulling the power? Jan 18 04:21:44 Tower emhttpd: Unmounting disks... Jan 18 04:21:44 Tower emhttpd: shcmd (10713): umount /mnt/disk3 Jan 18 04:21:44 Tower root: umount: /mnt/disk3: target is busy. Jan 18 04:21:44 Tower emhttpd: shcmd (10713): exit status: 32 Jan 18 04:21:44 Tower emhttpd: shcmd (10714): umount /mnt/cache Jan 18 04:21:44 Tower root: umount: /mnt/cache: target is busy. Jan 18 04:21:44 Tower emhttpd: shcmd (10714): exit status: 32 Jan 18 04:21:44 Tower emhttpd: Retry unmounting disk share(s)... Jan 18 04:21:47 Tower kernel: I/O error, dev loop2, sector 75904 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:21:47 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 809, flush 0, corrupt 0, gen 0 Jan 18 04:21:47 Tower kernel: I/O error, dev loop2, sector 180736 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:21:47 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 810, flush 0, corrupt 0, gen 0 Jan 18 04:21:49 Tower emhttpd: Unmounting disks... Jan 18 04:21:49 Tower emhttpd: shcmd (10715): umount /mnt/disk3 Jan 18 04:21:49 Tower root: umount: /mnt/disk3: target is busy. Jan 18 04:21:49 Tower emhttpd: shcmd (10715): exit status: 32 Jan 18 04:21:49 Tower emhttpd: shcmd (10716): umount /mnt/cache Jan 18 04:21:49 Tower root: umount: /mnt/cache: target is busy. Jan 18 04:21:49 Tower emhttpd: shcmd (10716): exit status: 32 Jan 18 04:21:49 Tower emhttpd: Retry unmounting disk share(s)... Jan 18 04:21:52 Tower kernel: I/O error, dev loop2, sector 75904 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:21:52 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 811, flush 0, corrupt 0, gen 0 Jan 18 04:21:52 Tower kernel: I/O error, dev loop2, sector 180736 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:21:52 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 812, flush 0, corrupt 0, gen 0 Jan 18 04:21:54 Tower emhttpd: Unmounting disks... Jan 18 04:21:54 Tower emhttpd: shcmd (10717): umount /mnt/disk3 Jan 18 04:21:54 Tower root: umount: /mnt/disk3: target is busy. Jan 18 04:21:54 Tower emhttpd: shcmd (10717): exit status: 32 Jan 18 04:21:54 Tower emhttpd: shcmd (10718): umount /mnt/cache Jan 18 04:21:54 Tower root: umount: /mnt/cache: target is busy. Jan 18 04:21:54 Tower emhttpd: shcmd (10718): exit status: 32 Jan 18 04:21:54 Tower emhttpd: Retry unmounting disk share(s)... Jan 18 04:21:57 Tower kernel: I/O error, dev loop2, sector 75904 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:21:57 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 813, flush 0, corrupt 0, gen 0 Jan 18 04:21:57 Tower kernel: I/O error, dev loop2, sector 180736 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:21:57 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 814, flush 0, corrupt 0, gen 0 Jan 18 04:21:59 Tower emhttpd: Unmounting disks... Jan 18 04:21:59 Tower emhttpd: shcmd (10719): umount /mnt/disk3 Jan 18 04:21:59 Tower root: umount: /mnt/disk3: target is busy. Jan 18 04:21:59 Tower emhttpd: shcmd (10719): exit status: 32 Jan 18 04:21:59 Tower emhttpd: shcmd (10720): umount /mnt/cache Jan 18 04:21:59 Tower root: umount: /mnt/cache: target is busy. Jan 18 04:21:59 Tower emhttpd: shcmd (10720): exit status: 32 Jan 18 04:21:59 Tower emhttpd: Retry unmounting disk share(s)... Jan 18 04:22:01 Tower kernel: buffer_io_error: 3 callbacks suppressed Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md2p1, logical block 0, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md5p1, logical block 0, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md1p1, logical block 0, async page read Jan 18 04:22:01 Tower kernel: I/O error, dev loop2, sector 0 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev loop2, logical block 0, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md4p1, logical block 0, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md3p1, logical block 0, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md3p1, logical block 1, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md3p1, logical block 2, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md3p1, logical block 3, async page read Jan 18 04:22:01 Tower kernel: Buffer I/O error on dev md3p1, logical block 4, async page read Jan 18 04:22:03 Tower kernel: I/O error, dev loop2, sector 75904 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:22:03 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 815, flush 0, corrupt 0, gen 0 Jan 18 04:22:03 Tower kernel: I/O error, dev loop2, sector 180736 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Jan 18 04:22:03 Tower kernel: BTRFS error (device loop2): bdev /dev/loop2 errs: wr 0, rd 816, flush 0, corrupt 0, gen 0 Jan 18 04:22:04 Tower emhttpd: Unmounting disks... tower-diagnostics-20260118-0420.zip
-
Thanks for such a detailed reply. That gave me a lot to think about and was helpful for making me consider more clearly what I am hoping for: We're planning on syncing our photo libraries to each other's servers as an offsite backup. Some kind of protection to prevent snooping is optional. We're somewhat concerned we'd forget the encryption password if there are significant barriers to accessing the data. Backups should be automatic. Immediate transfers are probably unnecessary. Weekly or nightly is probably suitable. Based on this, I think the sftp/filezilla suggestion might not suit me as that sounds like a manually initiated backup? The solution from the unraid blog does seem like a good fit and I guess I was sort of aware of the concept. I will need to put some time into understanding the rsync flags. And what level of access a "server to server" wireguard tunnel provides.
-
Hi, I know this is a topic that is not that unique but I was having trouble figuring out what the best solution for myself would be. I would like to set up an Unraid to Unraid backup between myself and my friend's server. His server is at his home and mine is at my home. I am decently technical and can do the set up on both sides if someone can point me towards a suggested way to go about this. I saw one suggestion about setting up a VPN tunnel between the two and using rsync? Would that give full access to each other's networks? That's not exactly ideal but if it's the only way I guess we would be okay with it. Thanks for your help.
-
On further reflection, it is possible the [conflicted] files were created sometime in the past and were not created by my current `mv` command. But, when I returned I saw the DSC_7862 [conflicted].NEF file in the source and the DSC_7862.NEF file in the destination and I did not see a [conflicted] version of the file in the destination, I tried the `mv * ../../disk1/files/` command a second time and it returned immediately and gave me the same output about being unable to remove directories due to them not being empty. So it seems like the mv command had no files to move and was aware of the [conflicted] files? I have since used Midnight Commander to complete the move and it had no issues about putting the DSC_7862 [conflicted].NEF file next to the DSC_7862.NEF file in the destination. So, perhaps there is a subtle difference?

