

Gnomuz
-
Posts
130 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by Gnomuz
-
-
If you have a free pcie 1x slot on your motherboard, that will do the trick. The other route would be a USB to rs232 adapter, but there are many compatibility issues as most of these so-called FTDI adapters are Chinese cheap crap. So stick with the add-on card if you can.
-
11 hours ago, tetrapod said:
Ok @Gnomuz, I would have given up a looong time ago. Which is exactly what I did. Big thanks for keeping at it because when I got the Unraid Ultimate Dashboard up and running that incorrect UPS reporting started bugging me again and this time I found this bugreport. Reading it was a roller-coaster ride between hope and despair 😐
I can report that I have exactly the same problem with APC Smart-UPS 1500 (SMC1500IC), manufactured Jul 18, 2020 and equipped with FW V. 03.5. (running Unraid 6.9.0)
I got the same nonsense numbers when trying to use ModBus as UPS type and I get Server Alert that Unraid lost communication with UPS and then directly that it's restored again.
Running your recipe with unplugging USB, restarting daemon and then reattaching USB got those sweet correct numbers I never seen before but they do not survive a reboot.

Thanks for praising my perseverance, I hate giving up, maybe a kind of OCD, but it's sometimes useful
")
The "magic recipe" for getting correct numbers was only a poor workaround for me, as t didn't survive a reboot as you mentioned. The issue we face is a apcupsd bug, reported on the apcupsd mailing list on various OSes.
But if you read my recent posts since late March 2021, you'll see I've now implemented a working solution which consists in replacing the USB connection with a good old RS232 serial connection between the UPS and the server ("Smart" cable ref AP940-0625A). If you have a DB9 serial port available on your server and you're ready to invest 30€ in the cable (amazon Europe price), I would definitely recommend to go this way and forget about it forever !
-
No spin down issue here for 6.9.2, working as expected, six SATA HDDs with LSI HBA
-
Maybe this thread should be moved by a forum admin in the "General support" section. I initially posted it as a prerelease bug report as I discovered the issue when I installed the UPS and my server was on 6.9.0 beta30, but it's obviously Unraid version agnostic. Moreover, it's very likely an apcupsd package and/or UPS firmware issue with USB connection, as others report the same under various distros in the apcupsd general mailing list.
Despite, as it is the built-in Unraid solution to communicate with UPSes, I think it would make sense to have this tested workaround visible for those who'd encounter the same problems but will very likely not find this thread buried in the prerelease bug reports section...
Thanks in advance for considering this move for the community.
-
 1
1
-
-
14 hours ago, sturgeo said:
That is excellent news, I'll get the cable ordered.
Coincidently, we had a power cut today, I'll be glad to not have to perform "the ritual" after each boot!
Many thanks for your trials and finding the solution.
You're welcome, I've been fiddling with this for so long that I'm glad to share and help others get rid of this "ritual", as you say, that I very regularly forgot when rebooting ... 😉
-
Changed Status to Solved
Changed Priority to Annoyance
-
Next and hopefully last episodes :
1) Reboot
I've rebooted the server, and no issue after reboot, the daemon restarts properly and immediately gets good values from the UPS
2) Full power outage simulation
- I set "Battery level to initiate shutdown (%)" to 85% to avoid discharging the UPS battery too much
- I've unplugged the UPS to simulate a power outage.
- Unraid server orderly shutdown was initiated @ 85%
- 3 minutes later (default UPS grace period of 180 seconds), the UPS turned off as expected
- when plugging the UPS back to mains, it started properly
- the Unraid server booted properly, without parity check
- UPS values read by apcupsd are correct
- "Battery level to initiate shutdown (%)" set back to 60% in my case for normal operation
- the UPS battery is slowly recharging (94% after 2 hours)
So, everything is working as expected now, Modbus over serial connection with the so-called "smart" serial cable (ref AP940-0625A) was definitely the way to go rather than the USB-A to USB-A supplied cable in my particular case. Don't forget to activate the Modbus protocol on the UPS from the UPS LCD panel in configuration mode (see manual). According to the manual, Modbus should be enabled by default, this was not the case for my UPS. You must have CP.1 displayed, not CP.0, under configuration mode.
The only limit of this solution is you must have a DB9 serial port on your motherboard. This is generally the case on server MBs, but a serial port is rarely present on modern workstations or desktop MBs. I've read on the apcupsd support list that this solution should work with a USB to serial adapter, but you may have to try various adpaters, avoiding cheap chinese crap. And the name of the tty device in the daemon setup should be something like ttyUSB0 or ttyACM0, depending on the chip in the adapter. I haven't digged further as I have an unused native serial port on my MB. If others want to experiment, I'll pass the torch to them now !
-
 1
1
-
-
2 hours ago, Vr2Io said:
Sound good this solve the problem.
Interesting part was it work with modbus over serial. No parameters such as buad rate, stop bit etc ......
When I use serial ( not support mobus ), due to low buad rate, to transfer one report it use more then 1 sec and sometimes will corrupt.
I confirm I didn't configure the serial port for baud rate, stop bit, parity, ...
For reference, current (default) serial port setup :
stty -F /dev/ttyS0 -a speed 9600 baud; rows 0; columns 0; line = 16; intr = <undef>; quit = <undef>; erase = <undef>; kill = <undef>; eof = <undef>; eol = <undef>; eol2 = ); swtch = M-0; start = M-s; stop = f; susp = <undef>; rprnt = <undef>; werase = <undef>; lnext = M-h; discard = <undef>; min = 0; time = 0; -parenb -parodd -cmspar cs8 -hupcl -cstopb cread clocal -crtscts -ignbrk -brkint ignpar -parmrk -inpck -istrip -inlcr -igncr -icrnl -ixon -ixoff -iuclc -ixany -imaxbel -iutf8 -opost -olcuc -ocrnl -onlcr -onocr -onlret -ofill -ofdel nl0 cr0 tab0 bs0 vt0 ff0 -isig -icanon -iexten -echo -echoe -echok -echonl -noflsh -xcase -tostop -echoprt -echoctl -echoke -flusho -extproc
So far, no data corruption here, as I monitor UPS data with telegraf/grafana, and any corrupted data would be clearly visible on graphs.
-
1
-
1
-
-
Hi all,
I just received the serial cable and have a first positive feedback.
I stopped the apcupsd daemon, unplugged the USB cable, plugged the serial cable. Then I modified the UPS settings as per the apcupsd manual :
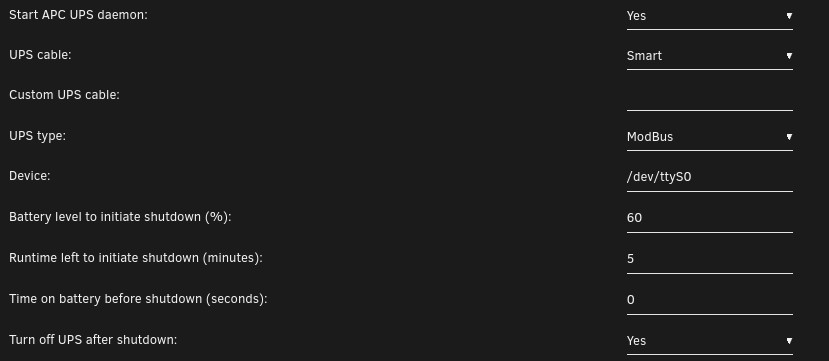
After restarting the apcupsd daemon, and a few seconds for refreshing, the daemon obviously gets consistent data from the UPS :
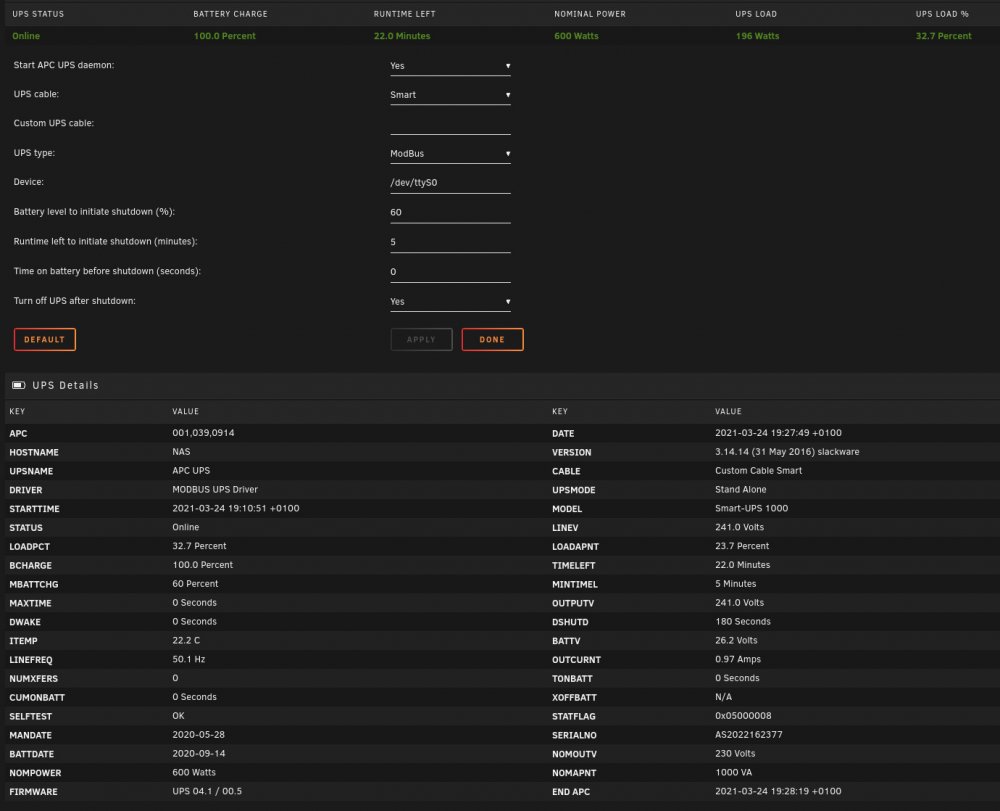
/dev/ttyS0 was obviously the unique DB9 serial port on my motherboard, and all values are correct.
I have simulated a short power outage of 2 mins (without shutdown, batteries @ 90% and 18 mins runtime left), the daemon got the expected data and had the expected behavior :
I still have to reboot the server to make sure everything starts over properly after a reboot (which was the problem with the USB cable), but I can't reboot right now, it's already a bit late here.
If everything is OK, I'll simulate a power outage long enough to trigger the shutdown, and check what happens when mains returns.
I hope I can test all that tomorrow morning and will report back.
-
Same typo here, and these footer temperatures come from the Dynamix System Temperature plugin. Support thread for this plugin is http://lime-technology.com/forum/index.php?topic=36543.0
-
23 hours ago, sturgeo said:
I'm experiencing the same issue with a SMC1000I-2UC, if that cable fixes it I'll get one ordered.
Thanks for replying, that's reassuring to see I'm not alone -at all- with this long lasting issue, as we have exactly the same UPS, except for the form factor (rack mount for you, tower for me).
I should receive the serial cable on Tuesday, and I'll share my findings, of course.
I read apcupsd manual again, and the setup should be rather straightforward according to http://apcupsd.org/manual/manual.html#modbus-driver .
As i'm not a Linux expert, and haven't played with serial ports for years if not decades, I just wonder how to find the device name. I have an existing /dev/ttyS0 entry, I suppose it is the DB9 serial port of my motherboard, but not 100% sure.
I'll keep you informed anyway.
-
1
-
-
Hello all,
I'm back on this persistent and expasperating issue, which obliges me to go back and forth from my basement to my office whenever I reboot my Unraid server ... I've just upgraded the server to 6.9.1 and of course nothing has changed. I do agree with @Dirthat Unraid as the base distro is very likely not at stake, and that apcupsd somehow messes up with this particular UPS during the initialization/reset phase. Nothing suprising either, the latest release of apcupsd in 2016 (!!!) is 3 years older than this UPS launch ...
So I went through the apcupsd mailing list as suggested by @jademonkee and obviously @Dir and I are not the only ones to meet this issue. From what I've seen, the generally agreed "solution" is to switch to the good old serial connection instead of USB, with a specific RJ45 to DB9 female cable (ref APC AP940-0625A, 2 meters long). I'm lucky enough to have a serial port on my motherboard, so i've just ordered the cable from amazon for roughly 30€ and should receive it next week.
I understand the apcupsd settings should be as follows with this setup :
- UPS Cable : Custom
- Custom UPS Cable : 940-0625A
- UPS type : APCsmart or ModBus (depending on ModBus activation or not on the UPS ?)
- Device : /dev/tty**
If anyone has already succeeded in running a similar setup, you're welcome to confirm or amend !
I'll report back once I've received the cable and tried this solution, which will remain a workaround for me, even if it happened to work in the end...
-
Hi all,
As a conclusion to this long-lasting thread, I've just updated to 6.9.1 and I succesfully managed to activate persistent syslog to an ad-hoc share by following @nblom's step-by-step. Without deleting the rsyslog.conf and .cfg files, and then rebooting, I still got errors and no persistent syslog.
-
13 hours ago, Rolucious said:
Thank you for your clarification. I have been looking around as well for overclock commands, but haven't been successful and your post confirms my doubts.
I was wondering if you've been able to find something else?
The nvidia-smi adjust clock settings only seem to apply to tesla gpus
I hope settings like these will be added in the future.
Nothing new here, under Unraid, I haven't found any way to adjust clock settings with nvidia-settings, as this utility requires at least a "minimal" Xserver, whatever it may mean (my technical skills reach their poor limits).
I have been able though to overclock an RTX3060ti with nvidia-settings CLI commands under Ubuntu on another rig, but still with a graphic environment like gnome.Perhaps a more skilled member of the community could try and identify which minimal setup / add-ons would be required for Unraid to let us use a utility like nvidia-settings, which for the moment is installed by the official nvidia drivers plugin, but is totally nonoperational.
And I do agree that would be a nice-to-have feature in a near future, which would definitely provide the community with a major step forward compared with former unofficial integrations of the nvidia drivers.
-
On 1/13/2021 at 7:39 PM, frodr said:
When not doing plex stuff, the gpu is doing a bit of folding. The gpu is trottled, is this hw specific or can it be switched off. The temp is only 37-42 C (liquid cooled), but the power is about max.
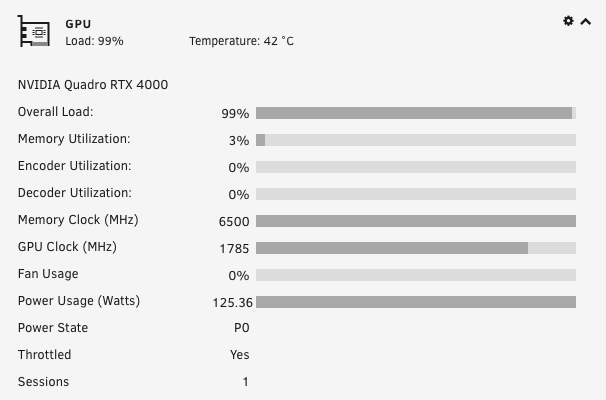
Well, it's been the normal behavior of the Nvidia drivers for a while. A "power limit" is enforced for the card by the vbios and drivers, and when the power drawn approaches this limit, the clocks are throttled.
If you want to see what the power limits are and to which extent you can adjust them, you just have a look at the output of 'nvidia-smi -q'
Mine looks like that on a P2000 (which is only powered by the PCIE slot, thus the 75W min & max) :
Power Readings Power Management : Supported Power Draw : 65.82 W Power Limit : 75.00 W Default Power Limit : 75.00 W Enforced Power Limit : 75.00 W Min Power Limit : 75.00 W Max Power Limit : 75.00 WOn this one, no adjustment is possible, as Min and Max Power Limits are the same. And it's almost constantly throttled due to the power cap when folding.
Same output for a RTX 3060 Ti on another rig:
[...] Clocks Throttle Reasons Idle : Not Active Applications Clocks Setting : Not Active SW Power Cap : Active HW Slowdown : Not Active HW Thermal Slowdown : Not Active HW Power Brake Slowdown : Not Active Sync Boost : Not Active SW Thermal Slowdown : Not Active Display Clock Setting : Not Active [...] Power Readings Power Management : Supported Power Draw : 194.23 W Power Limit : 200.00 W Default Power Limit : 200.00 W Enforced Power Limit : 200.00 W Min Power Limit : 100.00 W Max Power Limit : 220.00 W [...]For this one, you can see it is throttled because 194W are drawn out of a 200W limit. But this power limit can be adjusted between 100W and 220W through the command 'nvidia-smi -pl XXX', where XXX is the desired limit in watts.
That's the way it works, and it makes overclocking/undevolting more complicated. The way to go for efficient folding is to lower the default power limit, while overclocking the GPU (-> same perf with less power) . But it's impossible afaik on an Unraid server, as you need an X-server to launch the required 'nvidia-settings' overclocking utility ...
To summarize, nothing worrying in what you see, and not much to do. The only thing you can try under Unraid is raise the power limit to the max and see if you get better results for your folding. From my personal experience, minimal impact on performance, and a bit more power drawn 😞
-
1
-
1
-
-
It's a month now that I last posted on this thread, concluding we definitely needed help from the developers to debug this critical built-in function of Unraid, without any feedback.
Diagnostics and screenshots to document the bug had been, as required by @limetech, provided on November 24th 2020, followed-up with a deafening silence.
It's winter now in Europe, I've had a few power outages, and it was a mess to restart everything properly, especially because unplugging / replugging the USB cable is not that easy when you're away from home... It's just a crappy workaround, and I think nobody would seriously consider it as a stable production setup.
So, I hope everybody will understand my bump
If any further diagnostics, tests, attempts, ... are required, I'll be more than happy to provide them in a timely manner.
-
9 hours ago, JaseNZ said:
Thank you for the update this has seemed to resolve the issue with my container not being able to see smartctl. My temps are showing again however the Telegraf log is showing a different error now but the temps are in fact showing.
2020-12-19T22:22:49Z W! [inputs.smart] nvme not found: verify that nvme is installed and it is in your PATH (or specified in config) to gather vendor specific attributes: provided path does not exist: []This error is due to the absence of the 'nvme-cli' package in the container, and thus the 'nvme' command. You have to install the missing package through the "Post Arguments" parameter of the container (Edit/Advanced View).
Here's the content of my "Post Argument" param for reference, properly working with nvme devices, to be adapted of course to your specific configuration if required :
/bin/sh -c 'apt-get update && apt-get -y upgrade && apt-get -y install ipmitool && apt-get -y install smartmontools && apt-get -y install lm-sensors && apt-get -y install nvme-cli && telegraf'Edit the parameter according to your needs, the container will restart and you shouldn't have the error message in the log.
-
1
-
-
Well, no upgrade on Sundays, family first ...
As for write amplification, now that I can step back, I can confirm my preliminary findings about the evolution of the write load on the cache. I compared the average write load between 12/12 (BTRFS Raid1) and 12/19 (XFS) on a full 24h period, and the result is clear : 1.35 MB/s vs 454 kB/s, i.e. a factor of 3.
As I can't believe the overhead due to Raid1 metadata management may explain such a difference, it obviously confirms for me a BTRFS weakness, whatever partition alignment is ...
-
6 hours ago, Marshalleq said:
That's an impressive stat. I thought I read write amplification was solved some time ago in unraid, but perhaps it's come back (or perhaps a reformat is needed with accurate cluster sizes or something). BTW, I am also sure I read in the previous beta that the spin down issue was solved for SAS drives, which logically should also mean with a controller of some sort. It was in one of the release notes.
As for the (non) spin down issue, I understand it's brand new in RC1 due to the kernel upgrade to 5.9, when smartctl is used by e.g. telegraf to poll disks stats, and should be fixed in next RC.
So, I keep away for the moment. That would really be pity to have all disks spun up in an Unraid array without getting the benefits from a file system which by nature keeps disks spun up but gives you performance and "minor" features such as snapshots or read caching in return, wouldn't it ? 😉
For the write amplification, I had cautiously followed the steps to align both SSDs partitions to 1MB iirc, so the comparison of write loads between BTRFS Raid1 and xfs cache is on an already "optimized" btrfs setup. I just threw an eye to the overnight stats, a 3 to 4 factor is confirmed so far.
-
54 minutes ago, Marshalleq said:
There have been arguments on both side of the fence (btrfs is great, btrfs is not great). My experience has been the latter and I would recommend not using it in your cache. Switch to XFS and forget the mirror. With BTRFS mirror I did not have a reliable experience as have others.
BTRFS 'should' be able to cope with a disconnect, even if it had to be fixed manually. However, if both devices have got constant hardware disconnects then I guess that's going to be pretty challenging on any filesystem.
From my quick reading, this is a kernel issue though, not a hardware issue, so if you're not on the latest beta, if it were me, I'd probably shift to that given rc1 has the much newer kernel.
Running SSD's via an LSI card will reduce their speed as well BTW.
Another thing I'd do is raise it directly on the kernel mailing list (it's probably already there if it's still a current issue) because that would eventually find it's way into unraid.
Hopefully you're not on the latest beta / kernel as that alone might possibly solve it.
Thanks for your thoughts on my initial problem. I'm not on the latest beta RC1 because there's an issue which prevents disks from spinning down in configurations similar to mine (telegraf/smartctl). Waiting for RC2 and thus kernel 5.9+ to test again the SSDs connected to the onboard SATA controller, as it's a known issue with X470 boards.
Btw I only had disconnection issues with one of the SSDs, but btrfs never coped with it. For sure, a Raid 1 file system which turns unwritable when one the pool members fails while the other is up and running and requires a reboot to start over is not exactly what I expected ... So let's say we share the same unreliable experience with BTRFS mirroring.
For the moment I let the cache SSDs running via the LSI, have converted the cache to XFS and forgotten the mirroring as you suggested. I've immediately noticed that with the same global I/O load on the cache, the constant write load from running VMs and containers was divided by circa 3.5 switching from btrfs raid1 to xfs. At least, btrfs write amplification is a reality I can confirm...
-
Thanks for the step-by-step @nblom, persistent syslog is back ! Joint efforts are finally rewarded 😉
Maybe this procedure should be added to the release notes, as the fix seems to have no effect without it.
I will test once next release candidate is published, as I can't afford to have all the array disks spun up 24/7 with RC1.
-
According to your syslog, I would say no ! 😂
For reference, here is my syslog in 6.9.0-beta35 with exactly the same setup as @nblom (local syslog server disabled, no remote syslog server declared, Mirror syslog to flash : Yes)
Dec 15 17:31:45 NAS ool www[19853]: /usr/local/emhttp/plugins/dynamix/scripts/rsyslog_config Dec 15 17:31:47 NAS rsyslogd: invalid or yet-unknown config file command 'UDPServerAddress' - have you forgotten to load a module? [v8.2002.0 try https://www.rsyslog.com/e/3003 ] Dec 15 17:31:47 NAS rsyslogd: invalid or yet-unknown config file command 'UDPServerRun' - have you forgotten to load a module? [v8.2002.0 try https://www.rsyslog.com/e/3003 ] Dec 15 17:31:47 NAS rsyslogd: Could not find template 1 'flash' - action disabled [v8.2002.0 try https://www.rsyslog.com/e/3003 ] Dec 15 17:31:47 NAS rsyslogd: error during parsing file /etc/rsyslog.conf, on or before line 66: errors occured in file '/etc/rsyslog.conf' around line 66 [v8.2002.0 try https://www.rsyslog.com/e/2207 ] Dec 15 17:31:47 NAS rsyslogd: [origin software="rsyslogd" swVersion="8.2002.0" x-pid="20087" x-info="https://www.rsyslog.com"] startQuickly comparing, I would say there's undoubtedly a change between beta35 and rc1 : the number of errors in syslog jumped from 1 to 3 with the same setup. So it seems something has been tried, but I would leave the bug open at that stage if I were to decide.
Thanks for changing the title @nblom , and let's hope it's the last time you have to do so, otherwise you'll have to automate this somehow ...
-
Thanks, I just thought that following up on the initial issue would help the community understand the context and provide relevant answers. My mistake.
So I'm going to open a thread in General Support to ask the very same question, perhaps with a reference to this (non-bug) thread, if it doesn't infringe any forum rule.
-
Changed Status to Closed







[6.9.0 betas & 6.9.1] Apcupsd issue when booting
-
-
-
-
-
in Prereleases
Posted
I agree the USB-RS232 adapters with genuine FTDI chips are fine, and this product seems to be serious. The problem is it costs around 50€ here in France, so the add-on card would be cheaper for @tetrapod if he has a free Pcie slot.