

Gnomuz
-
Posts
130 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Gnomuz
-
Hello, Thanks for this great plugin, installation was a no-brainer and my old P2000 can be used to transcode (Plex) and compute (F@H) without any problem with recent Nvidia drivers 455.38. But, the geek I am is now the happy owner of a brand new RTX 3060ti, which was delivered today. And, as you certainly know, this GPU needs drivers v455.45.01 released on 2020/11/17 to be supported. Although I'm sure you've already guessed the question, is there any plan to make this version of the nvidia drivers rapidly available through the plugin, so that the card doesn't remain in its box for too long 😉? And more generally, how do you envisage the availability of the latest drivers in the future, especially after the launch of a new GPU and the unavoidable drivers' debugging to follow? Thanks in advance for your help. PS : I had a look at your other Kernel Helper/Builder plugin, which may be a solution to get the latest nvidia drivers installed (?), but I would then need some further guidance. I'm not a total noob, but not a Linux kernel builder expert at all !
-
Thanks for the quick answer @Squid. According to crontab, daily jobs are scheduled at 4:40am, I suppose it's default setting. - I've checked User scripts, none of them is "Scheduled Daily", and anyway none of them is supposed to restart apcupsd either. - CA Backup runs at 3AM for 15/20 minutes. - Parity check runs on a daily basis and is scheduled on December 1st. And that's all I'm aware of in terms of sceduled tasks during the night. I'll have a regular look at it and if it happens again I'll investigate further.
-
Having a look at syslogs, I've just noticed that this plugin seems to have stopped and restarted the apcupsd daemon this morning : Nov 29 04:40:02 NAS root: Fix Common Problems Version 2020.11.28 Nov 29 04:40:27 NAS apcupsd[10250]: apcupsd exiting, signal 15 Nov 29 04:40:27 NAS kernel: usb 3-2: reset full-speed USB device number 14 using xhci_hcd Nov 29 04:40:27 NAS apcupsd[10250]: apcupsd shutdown succeeded Nov 29 04:40:30 NAS apcupsd[27100]: apcupsd 3.14.14 (31 May 2016) slackware startup succeeded Nov 29 04:40:30 NAS apcupsd[27100]: NIS server startup succeeded I only have 5 days of uptime, it's the first time this happens since the reboot, but I remember having seen this sequence at least once recently. I had no notification from Fix Common Problems. Is it expected that this plugin interacts with the UPS daemon under specific conditions, or is it a pure coincidence ? I swear I was sleeping at 4:40am, so only a background task may have restarted apcupsd. Thanks in advance for the support.
-
Thanks for the lesson @jonathanm, next time I will think of what file sytem is used before posting ... go file modified, usbreset will be copied to /usr/local/sbin and I modified the user script accordingly. Thks for the template @SimonF We'll see tomorrow, as now it's 10pm, good night all.
-
Well, I just copied usbreset to /boot/config/, but chmod +x /boot/config/usbreset sends no error, but doesn't change the file permissions (still -rw-------). Sounds like a noob question, but I'm a noob in linux !!!
-
Thanks a lot for that @SimonF ! I had seen various versions of this program, but didn't know how to simply compile them with gcc under Unraid. Btw, how do you do that, I didn't find a way to install gcc in Unraid (no Nerd Pack package, an old unmaintained plugin) ? With the UPS communicating properly with the daemon, everything seems fine : root@NAS:~# /tmp/usbreset /dev/bus/usb/003/014 Resetting USB device /dev/bus/usb/003/014 Reset successful Nov 28 20:09:02 NAS kernel: usb 3-2: reset full-speed USB device number 14 using xhci_hcd Nov 28 20:09:02 NAS kernel: hid-generic 0003:051D:0003.0018: hiddev96,hidraw0: USB HID v1.11 Device [American Power Conversion Smart-UPS_1000 FW:UPS 04.1 / ID=1018] on usb-0000:2e:00.3-2/input0 Nov 28 20:09:02 NAS apcupsd[18031]: Communications with UPS lost. Nov 28 20:09:02 NAS kernel: usb 3-2: usbfs: process 18031 (apcupsd) did not claim interface 0 before use Nov 28 20:09:03 NAS kernel: usb 3-2: reset full-speed USB device number 14 using xhci_hcd Nov 28 20:09:05 NAS kernel: usb 3-2: reset full-speed USB device number 14 using xhci_hcd Nov 28 20:09:05 NAS apcupsd[18031]: Communications with UPS restored. And after this soft reset the daemon still gets correct information. I now have to reboot without unplugging the UPS, and check if the sequence stop daemon/soft reset/start daemon restores a proper communication. I noticed that this soft reset, unlike the unplug/replug which obviously re-enumerates, keeps the same device number (see 14 above). So I'm a bit doubtful, as with the "physical" sequence, the daemon restarts without any device connected, and then "discovers" a new one. We'll see .... I will reboot later this evening or tomorrow morning (8:30 pm here) and let you posted. I've copied usbreset on the flash and prepared a script : #!/bin/bash sleep 10 DEVNUMS=`lsusb | grep -i 'American Power Conversion UPS' | tr -d : | awk '{print "/dev/bus/usb/" $2 "/" $4;}'` /boot/config/usbreset $DEVNUMS
-
My mainboard is an AsrockRack X470D4U2-2T, and there are very few USB related BIOS options. To be honest the MB has great hardware, but the BIOS & (non)updates are very poor, not documented at all, and the community around this board is very little ... Anyway, if your suggestion is to boot the server without USB connectivity to the UPS, I'm almost sure the BIOS options are not granular enough to disable a specific USB port or hub without disabling the whole USB stack, which will for sure raise an issue when it comes to booting Unraid from the USB flash drive. Unless you have more specific directions, I don't think it's the way to go. Thanks for your help
-
Agreed, but simply restarting the daemon without unplugging the UPS between stop and restart has no effect, I tried it as a first possible workaround. In the meantime I found https://raspberrypi.stackexchange.com/questions/6782/commands-to-simulate-removing-and-re-inserting-a-usb-peripheral/7396#7396 , which is also based on sysfs, the proposed commands here are : sudo sh -c 'echo 1-1.2 > /sys/bus/usb/drivers/usb/unbind' sudo sh -c 'echo 1-1.2 > /sys/bus/usb/drivers/usb/bind' Unluckily, I tried both (your commands and mine), and they don't work, the information remains fanciful. And my physical magic formula (stop daemon/unplug/start daemon/replug) still works. Watching the logs while messing with all that, I noticed that the physical unplug/replug sequence increases the device number (device number is currently 7 !), while the bus of course remains the same (bus 3/port 1 for me). None of the sysfs commands (unbind/bind or authorized 0/1) I tried had this effect, which certainly explains why they don't work. My guess is the device changing its number forces somehow apcupsd to reinitiate its communication sequence with the "new" UPS from zero, which brings things back to normal. And that doesn't happen when the device "reappears" with the sysfs commands under the same device number. Here is a typical log example of the device number increasing : Nov 28 15:11:57 NAS apcupsd[32176]: apcupsd shutdown succeeded <------- 1 - stop daemon Nov 28 15:12:04 NAS kernel: usb 3-1: USB disconnect, device number 6 <------- 2 - unplug USB Nov 28 15:12:11 NAS apcupsd[32742]: apcupsd 3.14.14 (31 May 2016) slackware startup succeeded <------- 3 - start daemon Nov 28 15:12:11 NAS apcupsd[32742]: NIS server startup succeeded Nov 28 15:12:21 NAS kernel: usb 3-1: new full-speed USB device number 7 using xhci_hcd <------- 4 - replug USB Nov 28 15:12:21 NAS kernel: hid-generic 0003:051D:0003.0010: hiddev96,hidraw0: USB HID v1.11 Device [American Power Conversion Smart-UPS_1000 FW:UPS 04.1 / ID=1018] on usb-0000:2e:00.3-1/input0 I think we are getting closer to a viable workaround, we "just" need someone who would be highly technical on the usb part of the kernel, which is far from being my case ! Thanks all for your help, we'll find in the end !
-
I tried to boot with "USBTYPE usb" (partial but correct information) and then switch to "USBTYPE modbus" through the UPS settings tab, as suggested by @Vr2Io. No luck, definitely I need a reinit at USB device level to have the dameon working properly. Then another idea came to my mind for a workaround. Allright, the "normal" boot sequence ends up in a faulty communication between the UPS and the apcupsd daemon, for whatever reason, probably a sync issue between the daemon startup (very early in boot sequence) and the USB device initialization. But I found, after many attempts, a proper post boot workaround to come back to normal : - stop the daemon - unplug USB cable - start daemon - plug USB cable I'm pretty sure it's possible to emulate the unplug and plug actions in a script. If I found a way to do this, that would be pretty simple to have a user script triggered @reboot which would sleep for a minute or so, and would then chain the 4 actions above, perhaps with some kind of temporization in between. So my question to linux/Unraid experts is simple, is there any way I could emulate the USB cable unplug and plug actions in a script ? I'm aware the answer may be more complicated than the question, but it's key for me not to have to physically access the server or UPS to complete the boot sequence properly, especially in the case of a power outage when I'm away from home. Thanks in advance for your brilliant ideas 😉
-
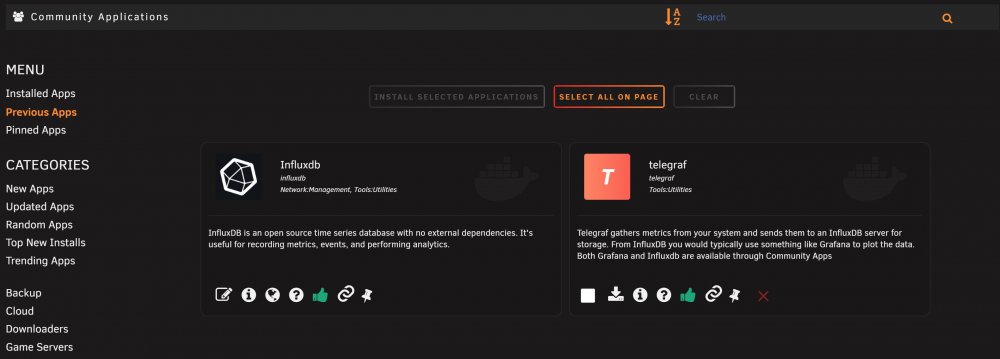
I have just noticed a strange issue : two of my installed containers (namely Influxdb and telegraf) are not showing in the "Installed Apps" section of CA, but instead showing in the "Previous Apps" section. grafana was installed at the same and is showing as expected. Screenshots : Previous apps section in CA : Docker containers tab, showing both containers are installed, up and running properly Any idea where this strange behavior comes from and how to fix it ? Thanks in advance

-
Hum, it's 11pm here, I'm not really willing to reboot now, but I'll try tomorrow morning. If ever it worked, there could be a temporary workaround : - somehow boot with an apcupsd.conf file where UPSTYPE would be forced to "usb" - trigger a user script on boot which would sleep for instance 2 minutes, stop the apcupsd daemon, set UPSTYPE to "modbus" in apcupsd.conf, and restart the daemon. The "only" issue is how to make sure a specific .conf file with "usb" would be present at boot time. The only customization I know of is the "go" file, but it's launched well after the daemon has started. And I even don't know how the UPS settings persist a reboot. So I can't see how I could force the server to modify the UPSTYPE directive during a clean shutdown. Anyhow, in case of a dirty shutdown due to a hang, the server would restart with the "modbus" setting in place. But I'm sure others may have ideas on possible implementations. Btw @Vr2Io, I've seen posts from you in another thread about apcupsd issues. As you may have seen in my logs, in my case it can't be a USB conflict with a fancy RGB whatever, as the UPS is the only USB device, apart from the Unraid USB key ofc. A NAS is a server, not a night-club or a Christmas tree😉
-
Thanks for the answer. As required, I rebooted without disconnecting the UPS from the server. Of course, no power outage occurred, and the battery charge level was 100% from the start. You will find the following attachments (01 to 09) : A) Before the reboot 01 & 02 : screenshots of the UPS settings tab, with correct information 03 : diagnostics file 03 - Diagnostics before reboot.zip B) After the graceful reboot 04 & 05 : screenshots of the UPS settings tab, with fanciful information. The status of the UPS is "Online LOWBATT", the battery charge level is 6.2%, UPS load % is 0, battery voltage is 0.4V, line frequency is 6.6 Hz (instead of 50Hz here in Europe), output current is 480.25A (!!!), and nominal output voltage is 120V (instead of 230V). To summarize, the communication between the daemon and the UPS is somehow heavily buggy ! 06 : diagnostic file after reboot 06 - Diagnostics after reboot.zip I then applied the reinitialization process described in the OP to return to normal : - 19:06:13 : stop apcupsd daemon in the UPS settings tab - 19:06:22 : disconnect the USB cable between the UPS and the server - 19:06:54 : restart the daemon - 19:07:24 : reconnect the UPS to the server C) After reinitialization 07 & 08 : screenshots of the UPS settings tab, which clearly show all information are now correct 09 : diagnostic file after reinit, with the new syslog messages (nothing unexpected, as far as I can see) 09 - Diagnostics after reinit.zip I hope that will be enough to chase the root cause of this malfunctioning. Do not hesitate to ask for more, I'll be more than happy to help and finally sort it out.
-
[SOLVED] [6.9.0-beta25] through [6.9.0-RC1] Syslog Server Broken, Error in Logs.
Gnomuz commented on nblom's report in Prereleases
I've been reporting bugs and bugs have also been reported to me for more than 30 years in large IT teams, so be sure I understand your doomed to failure attempt to sort between urgent, important, minor and -above all- problems with the chair-to-keyboard interface ... But in that case, you may have noticed from the reports that redirection to a remote syslog server is also faulty, as rsyslogd crashes immediately each time it is launched, whatever the settings are. As for the webgui log window, the terminal window running "tail -f", or the IPMI remote KVM for me, you and I have for sure learned the hard way over the years that they are rarely open in front of you, especially in the case of an unexpected crash in the middle of the night or during the weekend ! If ever I were to experiment a crash with beta35 right now, I would report it, but would also be totally unable to provide you with any relevant pre-crash log, which for sure would not ease the diag or fix on your side. I think that's why we have taken the liberty of insisting on this issue, as it is key for the debugging and validation process of our OS in beta phases, and may thus help you deliver a stable and exciting 6.9.0 final release soon(er)™ to this great community 😉 -
[SOLVED] [6.9.0-beta25] through [6.9.0-RC1] Syslog Server Broken, Error in Logs.
Gnomuz commented on nblom's report in Prereleases
Let's say that on July 19th 2020 (date of the OP), it may have been considered as "Minor", but on November 23rd 2020, more than 4 months later, without any reaction or acknowledgement in the meantime, I'm sure you understand the "Urgent" tag was a kind of desperate "message in a bottle" ... Moreover, as @Dataonestated above, and I completely agree with him, I hardly would qualify as "Minor" a bug which prevents from preserving syslogs in case of a crash, and thus prevents any serious diagnostic on the root cause, especially on beta versions we are happy to test and debug with you. Anyway, glad to see it has been taken into account and we'll be able to retest in the next beta release ! -
Thanks again @Frank1940, I created a new report in, hopefully, the right section of the forum (as I have installed the UPS when I was already in 6.9.0 beta 30) : I hope my third attempt will be the successful one ! @MXS, please reply on the new report above (Bug Reports > Prereleases), so that developers are aware I'm not alone in the dark 😉
-
Hi all, I'd like to report an issue I have with my brand new APC UPS SMC1000IC (tower model) on my Unraid server. All that follows was first seen in beta30, and beta35 didn't change anything. I first updated the UPS to the latest firmware (v 04.1) and enabled ModBus communication protocol via the LCD display (it is disabled by default, even though the operation manual states the contrary, so beware ...) After setting up apcupsd accordingly (UPS cable USB, UPS type ModBus), I plugged the UPS in the server (USB-A to USB-A), and all information were properly populated, especially the nominal power and load percent. So far, it was plug and play, what a good surprise after the various posts I had read in the forum ! But, there's a but, as you may have guessed... After a reboot, all info were wrong, except for "runtime left" and status (Online/On battery): a fully charged battery was reported as 6% charged, no nominal power nor load percent, and many other tags were absent or totally out of range, including an output voltage of 400+ volts ! After many attempts stopping and starting the daemon, with the UPS plugged or unplugged, I finally reached a stable behaviour : - when the server boots with the UPS plugged in (USB), the daemon gets fanciful information, and the workaround is to unplug the UPS, stop/start the daemon, plug the UPS back, and everything is back to normal - when the server boots with the UPS unplugged, and I plug it after the boot process is over, communication with the UPS is established, and all information are correct at first sight. I have also tried to use NUT instead of the built-in apcupsd, but the problem is NUT doesn't seem to know of the ModBus protocol, it only manages communication with UPS in "basic" USB mode. And this UPS reports very little information in basic USB mode (just battery charge level and runtime left, no load percent, no nominal power, no voltages, ...). I get the same limited set of information with both apcupsd in USB mode and NUT. I agree these info (batt level and runtime left) are sufficient to manage a smooth shutdown in case of power outage, so I could run apcupsd with UPS type set to "USB" instead of "ModBus" (or NUT, which would be the same), as I have no issue at boot with this setup. But I also want to feed various UPS data to my Grafana dashboard (custom UUD 1.4 currently) through telegraf, so I don't see any other solution than apcupsd running with UPS type set to "ModBus" to capture what I want in the dashboard. So, I've been stuck on this problem for a while now, and my setup is still not operational in case of an unexpected power outage. As the reboot will be automatic when the power comes back, the daemon will get false information (no possible USB unplug/replug if I'm away or sleeping...). It will see the UPS Online with the correct Runtime left, but with a ridiculously low battery charge level (1 to 6% "captured" vs 90+% in reality during my tests). And the batt level remains stuck over time. As I have set the "Battery level to initiate shutdown" to 60%, when a second power outage will occur, even for a few seconds, the shut down will be immediately initiated, due to the false battery charge level. I haven't tested what happens next when the power comes back, but I think it may enter a loop of shutdowns/reboots each time a power outage occurs. That is obviously not a proper setup for a 24/7 server... I suspect the apcupsd dameon establishes the communication "a bit" too early on my setup, at a stage where the USB "stack" on the server is not totally ready (sorry for the improper words, I'm not an Unraid/Linux expert...) and thus the communication with the UPS is not initialized properly. To try and sort it out, I think that delaying the launch of the apcupsd daemon might be a solution, but I didn't find any setting or thread on this forum to do so. Another possible solution may be to fully reset the USB device through a script, but again I didn't find anything similar in the forum. Thanks in advance for your thoughts and guidance on this issue.
-
Thanks for jumping in @Frank1940. As I saw reviving this thread gave no result, I created a new post a month ago : So far, it had little to no success, even after two bumps 😉. The only suggestion from @jonathanm was about using NUT instead of the built-in apcupsd, which I had already tried before posting and is not an alternative for me, as explained. Btw, would you have any clue on how to delay the apcupsd start in the whole boot process, because I highly suspect it starts too early and somehow the USB device is not properly initialized when the daemon initiates the communication. It thought it was a hardware-specific issue on my side, but at least we are two on the same boat... My motherboard is AsrockRack X470D4U-2T fyi. @MXS, please reply on my quoted post, it may attract attention of some helpful community members, or even the developers ! My UPS is also brand new (manufacture date 2020-05-28), and I received it on 2020-09-14. Your UPS is a different model and wattage (SMT1500 vs SMC1000IC) Let's cross our fingers for a better diagnostic or fix, because booting with the UPS USB interface unplugged is a workaround for planned reboots, but doesn't make any sense in the case of a power outage, which is precisely the use case of a UPS ...
-
[SOLVED] [6.9.0-beta25] through [6.9.0-RC1] Syslog Server Broken, Error in Logs.
Gnomuz commented on nblom's report in Prereleases
Great, let's hope it will draw attention ! Really, we can't insist enough that a way to have persistent logs is a must in case of a crash, that's, among others, why rsyslog has been created so long ago -
[SOLVED] [6.9.0-beta25] through [6.9.0-RC1] Syslog Server Broken, Error in Logs.
Gnomuz commented on nblom's report in Prereleases
@nblom As the original poster, I suppose you are able to change the post title. May I suggest something like "[6.9.0-beta25]->[6.9.0-beta35] Major syslog server issue" so that the post is not considered as only related to beta 25 and thus ignored by the developers. Thanks -
[SOLVED] [6.9.0-beta25] through [6.9.0-RC1] Syslog Server Broken, Error in Logs.
Gnomuz commented on nblom's report in Prereleases
Just to confirm the misconfiguration of rsyslogd is still present in 6.9.0-beta35. Whatever the settings are (mirror to flash, activation of the local syslog server, forward to a remote syslog server), rsyslogd crashes when parsing rsyslog.conf with the same error again and again : "rsyslogd: Could not find template 1 'remote' - action disabled" I do agree with @nblom and @Dataone that this is now an urgent matter. I do enjoy testing beta releases, but it doesn't make much sense if I'm not given the possibility to provide the developers with a syslog in case of an unexpected crash ... So @limetech, a simple acknowledgment of this issue and a confirmation that you don't imagine a candidate release with such a blackhole in the management capabilities would be more than welcome. I know your "lack of immediate reply does not mean (our) report is being ignored.", as stated in your pinned post, but more than four months after the OP, with three beta releases (29, 30, and 35) in the meantime, I'm sure you will understand we wonder whether this post has ever been read and/or taken into account. Thanks in advance. -
Just a little feedback on upgrading from Unraid Nvidia beta30 to beta35 with Nvidia drivers plugin. The process was smooth and I see no stability or performance issue after 48h, following these steps : - Disable auto-start on "nvidia aware" containers (Plex and F@H for me) - Stop all containers - Disable Docker engine - Stop all VMs (none of them had a GPU passthrough) - Disable VM Manager - Remove Unraid-Nvidia plugin - Upgrade to 6.9.0-beta35 with Tools>Update OS - Reboot - Install Nvidia Drivers plugin from CA (be patient and wait for the "Done" button) - Check the driver installation (Settings>Nvidia Drivers, should be 455.38, run nvidia-smi under CLI). Verify the GpuID is unchanged, which was the case for me, otherwise the "NVIDIA_VISIBLE_DEVICES" variable should be changed accordingly for the relevant containers - Reboot - Enable VM Manager, restart VMs and check them - Enable Docker engine, start Plex and F@H - Re-enable autostart for Plex and F@H All this is perhaps a bit over-cautious, but at least I can confirm I got the expected result, i.e. an upgraded server with all functionalities up and running under 6.9.0-beta35 !
- 291 comments
-
- 13
-

-

-
Thanks for the quick answer. I was just trying to understand if there was any major underlying difference between both implementations. I do agree that trying to "share" a GPU between VMs and containers is risky and will in many cases lead to an unclean shutdown if you are not highly cautious. I've experienced it myself, I'm not to be convinced ! And of course, if the GPU is bound to VFIO for a VM passthrough, when you want to use it back in container(s), you have to unbind it and reboot, nothing new. So, now all my doubts are raised, and I think I am ready to upgrade to the brand new setup proposed by 6.9.0-beta35.
-
Are you 100% sure @jonathanm ? So far, with the so-called unofficial kernel, you weren't obliged to mess up with settings and reboot to share -cautiously- a GPU between VMs and containers. You could passthrough a GPU to a VM and start it, provided the GPU wasn't currently in use by a container, otherwise the system hung and you had to go through an unclean shutdown, I agree. But if no container was actively using the GPU, no issue. And once the VM was started, the containers knowing of the GPU ('--runtime-nvidia') would fallback to CPU transcoding for Plex, CPU-only computing for F@h, ... but would not crash, and the system neither of course. At least it was my understanding of the now deceased support stream of Nvidia-Unraid. Correct me if I am wrong. And If the new official solution has new major limitations, then please let the whole community know clearly.
-
Thanks, so on we go !!!
-
Hi all, I have built an Unraid server and so far, so good ! I just got a Quadro P2000 GPU to add to the current config, to support hardware transcoding in Plex. I went through numerous threads, including this one of course, and I think I now have a pretty good idea of how to proceed thanks to all of you. The Unraid Nvidia Plugin is installed. Now that I'm ready to open the box, I just have a simple question. Should I : - install Nvidia Unraid build without the P2000 plugged-in, shutdown, install the P2000 physically, and then restart - or shutdown, install the P2000, restart, install Nvidia Unraid build, and then reboot - or the order doesn't matter ? Thanks in advance for your help !



