




cpetro45
Members
-
Joined
-
Last visited
Everything posted by cpetro45
-
Thanks Jorge!
-
Warming this back up as I have some clarification questions: This happened again. I had PSU failure and a few unclean shutdowns (PSU would cause a reboot when disks spun up or doing anything). One stability was achieved, I ran a non-correcting parity check, it had 1 error. I ran it again (non-correcting) and it found no errors. This is all in maintenance mode BTW. Here is the log: Jun 14 14:24:41 Tower kernel: mdcmd (36): check nocorrect Jun 14 14:24:41 Tower kernel: md: recovery thread: check P Q ... Jun 14 14:41:00 Tower kernel: md: recovery thread: PQ incorrect, sector=217794056 Jun 15 06:37:38 Tower kernel: md: sync done. time=58377sec Jun 15 06:37:38 Tower kernel: md: recovery thread: exit status: 0 Jun 15 09:07:11 Tower kernel: mdcmd (37): check nocorrect Jun 15 09:07:11 Tower kernel: md: recovery thread: check P Q ... Jun 16 01:20:27 Tower kernel: md: sync done. time=58396sec Jun 16 01:20:27 Tower kernel: md: recovery thread: exit status: 0 You can see I ran these 1 after the other pretty much without a reboot. My question is more of a general computing question. In this post and others, I see mention of a "flipped bit" and the potential for that to show up here. With non-ECC memory which I believe is still far more common, wouldn't this be more of a problem? What does memory have to do with this process in the first place, what does it load into memory that it needs to compare? In addition, without ECC memory, is my array always at risk for data corruption? For example, if I'm copying 30GiB of information over my TCP/IP Network to the Unraid array, we've got memory (non-ECC in this case) of the host computer, memory (non-ECC) of the unraid array, and the TCP/IP protocol as well. If there is a "bit flip" anywhere along the process does that corrupt whatever I'm copying? Wouldn't this be more of an issue? Do I really need to rum memtest? I didn't run it before, but I guess I'm willing to run it now since I've had the array in maintenance mode and unavailable for some time at this point. I appreciate the insight, I am just trying to determine the best way forward as I have some data that is 25 years old and I don't want bit rot. Should I run a 3rd parity check (I haven't rebooted, it's still in maintenance mode) or should I just ignore this? Thanks
-
Update: Replacing the Power Supply with a new one stopped the rebooting. Thank goodness it was an easy fix. Super bizarre failure. The old power supply that introduced the instability/reboot was a thermaltake 550W SP-550 which looks like I ordered around 2015 for something. The age lines up with expected EOL. It wasn't a particularly good one at the time of purchase. I've replaced it with a seasonic focus gx-750 (totally overkill but was cheaper than the 550W with a better warranty). I've learned over the years to buy the best PSU you can afford! Just wanted to provide the update. Thanks!
-
Thanks JorgeB, yeah that's what I was suspecting as well more so after I downgraded. I guess I'll throw a PSU at it and see if it resolves. Will update the post after I do that in a few weeks.
-
Hi there, I've been running unraid for a long time (10 years). I've had problems here and there, but this one I think is gonna be hard to nail down. I do think it's a h/w issue due to: server being stable for years keeping up with latest releases downgraded to 6.12.9 and same exact issue as 6.12.10 syslog shows nothing about any kernel panics or anything like that. If I let the server sit for a few days with no disks mounted, it will stay up. As soon as I start a parity check, it will reboot within 5 minutes with no indication of problem in syslog. I wonder if I've got some weird power supply issue where with disks not spun up and under no load, no issues, but disks spun up, under load, reboots. Any thoughts on this one? I have 6 disks , 2 parity and 4 data. I'm thinking throw a power supply in it first? Thanks. Here is latest diags before manually downgrading versions. tower-diagnostics-20240607_0742.zip
-
Thanks to you both, OK, I'll take a look at the plugin and also run memtest. Jorge parity check was started manually pretty much directly after the non-correcting check was canceled.
-
Hey Jorge, Thanks. The last full check shown below (16hr, 20 min, 57 sec) did have correcting enabled. I was expecting something to show up in the log like "parity check started" and "parity check completed." You are saying there is basically no identification for this, and things in the log would only show up if errors were found and corrected (or not corrected as the previous run shows in the log)? Thanks, Chris
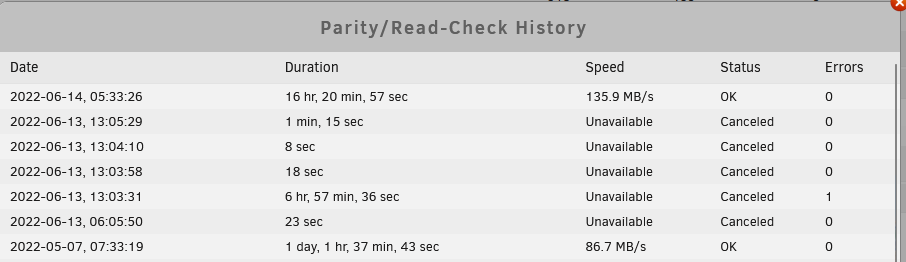
-
Alright, will give it a go, thanks. I didn't see anything related to full parity check with correction in the syslog... did I need to have debug turned on or something? Thanks
-
I have not
-
Thanks so much Jorge, let me get the whole log. All disks are XFS. I attached the whole diagnostic stack. I appreciate your reply and help. Let me know if I can provide anymore information. I also provided screenshot for times of the 1 sync error vs clean run. tower-diagnostics-20220615-1543.zip
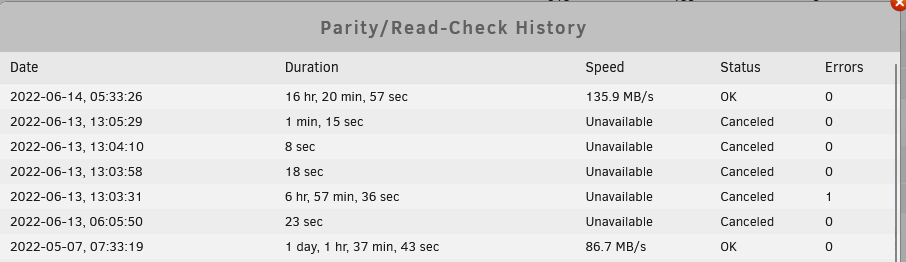
-
Hey there everyone, I'm just wondering how / why this would occur. 8 disk array, dual parity, no cache. There was an unclean shutdown due to power issues (I have UPS, but don't have the automation setup to shutdown yet). There were no writes going on and disks were spun down. The next day, I ran parity check with correct disabled and it found 1 error about 60% of through. I read these forums and decided to cancel and restart the parity check with correct enabled. The parity check ran with no errors detected. What could a reason be why this happened? Should I be concerned? Here are lines related from the log: (suspect line Jun 13 07:06:23 Tower kernel: md: recovery thread: PQ incorrect, sector=807021208) Jun 13 06:05:27 Tower kernel: mdcmd (42): check Jun 13 06:05:27 Tower kernel: md: recovery thread: check P Q ... Jun 13 06:05:50 Tower kernel: mdcmd (43): nocheck Cancel Jun 13 06:05:50 Tower kernel: md: recovery thread: exit status: -4 Jun 13 06:05:55 Tower kernel: mdcmd (44): check nocorrect Jun 13 06:05:55 Tower kernel: md: recovery thread: check P Q ... Jun 13 06:08:57 Tower nmbd[6513]: [2022/06/13 06:08:57.865107, 0] ../../source3/nmbd/nmbd_become_lmb.c:397(become_local_master_stage2) Jun 13 06:08:57 Tower nmbd[6513]: ***** Jun 13 06:08:57 Tower nmbd[6513]: Jun 13 06:08:57 Tower nmbd[6513]: Samba name server TOWER is now a local master browser for workgroup HOME on subnet 192.168.122.1 Jun 13 06:08:57 Tower nmbd[6513]: Jun 13 06:08:57 Tower nmbd[6513]: ***** Jun 13 06:08:57 Tower nmbd[6513]: [2022/06/13 06:08:57.865228, 0] ../../source3/nmbd/nmbd_become_lmb.c:397(become_local_master_stage2) Jun 13 06:08:57 Tower nmbd[6513]: ***** Jun 13 06:08:57 Tower nmbd[6513]: Jun 13 06:08:57 Tower nmbd[6513]: Samba name server TOWER is now a local master browser for workgroup HOME on subnet 172.17.0.1 Jun 13 06:08:57 Tower nmbd[6513]: Jun 13 06:08:57 Tower nmbd[6513]: ***** Jun 13 07:06:23 Tower kernel: md: recovery thread: PQ incorrect, sector=807021208 Jun 13 13:03:31 Tower kernel: mdcmd (45): nocheck Cancel Jun 13 13:03:31 Tower kernel: md: recovery thread: exit status: -4 Jun 13 13:03:40 Tower kernel: mdcmd (46): check Jun 13 13:03:40 Tower kernel: md: recovery thread: check P Q ... Jun 13 13:03:58 Tower kernel: mdcmd (47): nocheck Cancel Jun 13 13:03:58 Tower kernel: md: recovery thread: exit status: -4 Jun 13 13:04:02 Tower kernel: mdcmd (48): check nocorrect Jun 13 13:04:02 Tower kernel: md: recovery thread: check P Q ... Jun 13 13:04:10 Tower kernel: mdcmd (49): nocheck Cancel Jun 13 13:04:10 Tower kernel: md: recovery thread: exit status: -4 Jun 13 13:04:14 Tower kernel: mdcmd (50): check Jun 13 13:04:14 Tower kernel: md: recovery thread: check P Q ... Jun 13 13:05:29 Tower kernel: mdcmd (51): nocheck Cancel Jun 13 13:05:29 Tower kernel: md: recovery thread: exit status: -4 Jun 13 13:12:29 Tower kernel: mdcmd (52): check Jun 13 13:12:29 Tower kernel: md: recovery thread: check P Q ... Any thoughts much appreciated. Thanks
-
I've been running Unraid for 10 years. I have a 6 disk array that at one time was 9 or 10. All has been well. As you can imagine drive failures here and there, etc over 10 years. I updated disks and consolidated a few years ago. I have 8TB parity and 5 Data disks 2 - 4 GB each. I never updated the H/W. This thing has been running on Core 2 Duo E6600 or something with 2 GB of ram...ancient Gigabyte board and an 8800GTX , still no issues besides regular disk maintenance...til now. Log in to WebUI the other day and see a disabled disk...I'm pretty annoyed as nothing has changed and don't even write to this that much. I didn't grab the logs. The SMART report on disabled disk says UDMA CRC error count. I read all about that all over this forum. In the meantime, I think I stopped the array and shutdown to replace SATA cables. I ordered new SATA cables from Amazon. I replaced all of them (they are old). I didn't care about the sata plug / disk order cause unraid 6 no need to worry. I think I was concerned so I hooked up a monitor as well to check booting. Well, I thought it got stuck on loading bzroot since it was taking forever (more than 3 - 4 min). I got sidetracked and ended replacing the usb drive (14 years old) thinking that was bad (it wasn't). I had to use the HP Media preparation since this MOBO is real picky. Did all that BS (figuring that out again that it wouldn't boot unless specially formatted with a 15 year old tool), finally got it booting from new USB thumb drive. BTW, it was taking like 10 minutes to boot (first hint, since it never usually took that long)...remember this thing is still booting up. I didnt think it was booting and thought usb drive was bad. I used the new UNRAID 6 usb drive prep first, obviously, but it definitely needed that HP tool (thanks to this forum...again... I was able to find that info ...again and re-download it). Next, the forums say, oh, just check the file system of the disabled disk, and it's probably that. I started array in maintenance mode (after 10 minute boot or so), ran the file system check, nothing really came up on -n option. I figured, what the hell, run it without -n. Next thing you know, I get a UDMA CRC error count warning on PARITY disk, during the File system check of disabled disk. I'm like , oh man, parity better not get disabled. There were I think 21 writes in the Parity disk column and 20 errors. I started getting real nervous. Somehow the retries must have been successful (I have that syslog) I cancelled the file system check on disabled disk. I had screenshots from config before and after I moved the disks around. It wasn't the same SATA port that threw the UDMA CRC error count on data disk and parity disk. At this point, I knew something on the board was toast. Luckily, I have another system (literally only 2 years newer) but with 8GB ram and Core 2 Xtreme 3000 quad core (1200$ processor back in it's day , bought on ebay for like 250 or something like 8 years ago). Anyway, huge upgrade compared to the 2GB and Core 2 Duo LOL. We're talking DDR 2 here. So, conveniently enough, the "new" computer had a removable MOBO tray, so right now, I'm running the array off the new board, rebuilding the failed disk on top of itself. Something went real bad on in the old CPU. Added some pics....hope this was a fun blast from the past for some, and also BACK UP YOUR DATA because you never know... Ultimately, I do feel like a few bits may be off (I hope not). I definitely going to backup all the rest of my important items once array is back up completely.


-
warranty that thing, reallocated sectors
-
Just an update from my issues (see back a few posts) with this plugin and 6.3.5. On my 2nd 4TB drive, I've got the array stopped and I'm using the original (patched for latest version of unraid - see script thread) preclear_disk.sh script without issue. The server hasn't locked up at all like last time when using this plugin. Using screen is working well. I'm not saying I don't like the idea of this plugin at all, it just wasn't working for me. Thanks
-
Hey Frank, thanks. I implemented this setting and it seems like maybe it did something. However, looks like the preclear job is mostly locking up on the Pre-read phase and pegging 1 cpu at 100% with the timer stopping. I've nursed it through 2 cycles, it's working on the 3rd but I think for my 2nd HD, I may spend the time to figure out how to do it via ssh. I'm not going to spend too much time as I believe my system resources are not constrained, and the script is just bombing out for whatever reason. I do appreciate the help and input! Chris
-
Thanks, yeah it's got 2GB of ram, a little light for sure. It didn't seem like ram usage was pegged tho, about 50% versus higher cpu usage. Its prereading now, it locked up earlier (no ip, no gui) but now it seems like it's moving again...after I reset it. We shall see.... Thanks
-
Is there a minimum CPU system requirement to get this script to run successfully all the way through? I've never used it before, and I have a pretty old Dual Core Duo E6600 2.4Ghz. Anyway, I've got two new 4TB disks hooked up to a PCI Ex Ver1 X1 SATA controller. I tried both at the same time, realized that was a big mistake as it was saturating the PCI bus. Now I'm trying 1 at a time, and I had pre clear stop responding on Post-Read with CPUs pegged at 100%. The WebGUI was still responding. I uninstalled the plugin, rebooted, reinstalled it, and rebooted again and am attempting preclear once again with 1 drive and the array stopped. Hopefully it makes it all the way through this time, I'll definitely post back. This is with the latest version 2017.11.14 and Unraid 6.3.5. I'm not really using any of the new features like docker containers yet. Any thoughts? If this doesn't work, I understand I should try it manually without the plugin. Also, I could get the disks off this crappy PCIEv1 X1 controller (which I plan to do after I remove some other disks (MOBO has 8SATA ports), but I figured I'd be OK with the preclear. Thanks ! Chris




