jvlarc
Members
-
Joined
-
Last visited
Everything posted by jvlarc
-
Hi guys, Been running unRAID for the past few years now since Covid and love the system so much I've also setup another unRAID server in my office. A couple of months ago, I made the switch to the Docker directory for both servers, and both were successfully updated to version 6.12.3. A few weeks back, I encountered an issue where the Docker image on my office server got corrupted. It took quite a while to resolve as I had to let it run overnight, but eventually, I managed to delete the corrupted image. After that, I had to reinstall the Docker containers I had previously set up which was the usual process and everything was back up as per normal. Fast forward to last week, I ran into a similar problem on my home server. Some containers wouldn't start, and my initial thought was that it was the same issue as what happened in my office. However, despite my best efforts, including leaving it running overnight for about 5 days, I couldn't seem to resolve the problem. Yesterday, I was prompted by 'Fix Common Problems' to address the issue Upon investigation, it appears that Cache 1 had one CRC error count. I attempted to resolve this issue by shutting down the system, reseating the cable, but unfortunately, that did not resolve the problem. Suspecting a faulty cable, I replaced it with a new one and tested it. Strangely, Cache 1 no longer appears on my unRAID server, even after trying different SATA ports on the motherboard. However, when I connected Cache 1 SSD to my main PC using the new cable, it showed up, and I successfully reformatted it. I also verified that both SATA cables are functioning correctly on my main PC. Still, Cache 1 doesn't show up on unRAID, and I'm stuck with the cache in read-only mode. Any suggestions and steps will be greatly appreciated! I've attached my diagnostic files here - tower-diagnostics-20231015-1339.zip
-
Hi guys, I work in the media industry and at times we do have to share large asset files with remote editors/clients sometimes more than 100GB, have tried NextCloud & YouTransfer, but some have complained that the download keeps failing, so any advice and help would be appreciated! I know I can go the VPN route (But I do not wish to expose my server to others) or even p2p file sharing like torrent, but for a one-off type of usage, what would be the best method to achieve what I require and simple for everyday users? Thank you!
-
Same thing, my RTX 3070 is not getting detected as well after upgrade and throwing same error logs. Also my reverse proxy (NC & Bitwarden) now seems to take a really long time before it started to work, restarted a few times only to find out it works after I went for a shower and came back to it working. Edit : seems like reverse proxy isn't working again, gonna downgrade back to 6.10.1
-
Hi JorgeB, Just took the other cache drive out of the system and plugged into my pc, I guess the SSD died as it's not being detected anymore on my system. Can I check how to tell the errors from the btrfs corruption? Anyway I've managed to restore the appdata and everything seems to be back up running normally again. I shall run a memtest within the next few days... really hoping I do not have bad ram again as it was a few months ago and replaced it
-
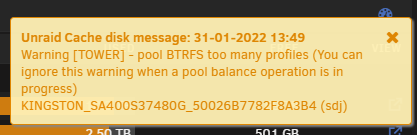
Update - the entire array hang after awhile and I just hard restart the server and seems to ask me to rebalance the pools first. ran this command Data, RAID1: total=15.00GiB, used=10.97GiB Data, single: total=311.00GiB, used=233.32GiB System, RAID1: total=32.00MiB, used=0.00B System, single: total=32.00MiB, used=80.00KiB Metadata, RAID1: total=1.00GiB, used=131.83MiB Metadata, single: total=3.00GiB, used=491.55MiB GlobalReserve, single: total=288.73MiB, used=16.00KiB WARNING: Multiple block group profiles detected, see 'man btrfs(5)'. WARNING: Data: single, raid1 WARNING: Metadata: single, raid1 WARNING: System: single, raid1
-
Hi guys, just installed a new 128gb nvme drive to be used for VM into my unraid server, however on auto startup, Something seems to have merged my 2 existing 500GB Cache drive into a 960GB pool and is currently running a BTRFS Balance. Looking at the disk log, it shows devid 2 is missing. Was asking on Discord and was advised that I should post it here as it may be a possible bug. Will be trying to restart the system shortly after the balance is completed. Attached is my diagnostic file. Have currently changed my shares to 'Yes' to slowly move them off the cache drives first before switching to 'No' and reboot. I do have CA Backup/Restore running but just to be safe tower-diagnostics-20220131-1236.zip
-
Hi guys, just installed a new 128gb nvme drive to be used for VM into my unraid server, however on auto startup, Something seems to have merged my 2 existing 500GB Cache drive into a 960GB pool and is currently running a BTRFS Balance. Looking at the disk log, it shows devid 2 is missing. Was asking on Discord and was advised that I should post it here as it may be a possible bug. Will be trying to restart the system shortly after the balance is completed. Attached is my diagnostic file. Have currently changed my shares to 'Yes' to slowly move them off the cache drives first before switching to 'No' and reboot. I do have CA Backup/Restore running but just to be safe tower-diagnostics-20220131-1236.zip

-
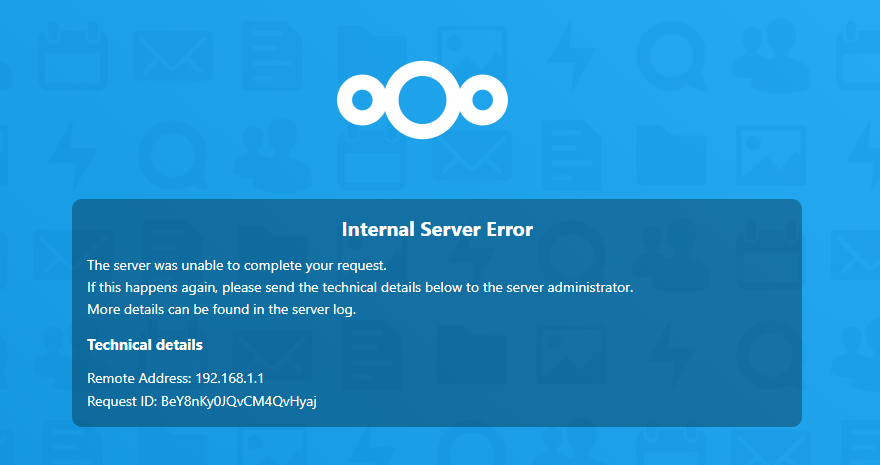
Hi guys, Been having this error after updating some nextcloud settings with the recent video SIO released (Great followup video), all was working well till I clicked 'Update all apps', then NC was using a ton of CPU resources and I restarted the container, I kept getting a 'Internal Server Error' ever since and have scoured the forums for a solution, which mostly said changing the repo to another version like this which seemed to have helped many others. I even restoring my server through Backup/Restore Appdata but all did not work for me. Is there any way I could resolve this? Or should I re-install NC and MariaDB from a freshstart? Have checked through Adminer that the db is still intact and the weird thing is, Nextcloud is still accessible through my phone and pc's file browser, but the web browser constantly shows this error. Has anyone ever experienced something like this and what can I do to solve this? Thank you!
-
Same issue for me, have you found a work around yet?
-
Hi Squid, love your apps! Does it mean I'll need to either reduce or increase my memory size for the error to solve this issue? As I swapped out a 16gb for an 8gb RAM stick when I first encountered this error
-
So I've actually downgraded to 6.9.2 and the VM seems to have improved tremendously. However I'm still getting the CPU */KVM Tainted errors, how should I get it cleared?
-
Hey everyone, my unRAID server has been running really strong the past few months but recently I'm running into some issues with the CPU /KVM tainted error recently after my cache drive was full the other day which corrupted my docker img as well. After going on discord and getting some help, I managed to solve my reverse proxy issues, however this tainted error seems very persistent and even took my access point down this morning, AP only worked when I unplugged the LAN. Only realized it as it happened to me a few months prior with bad ram and corrupted BTRFS files, doing a scrub on a few of my BTRFS drives as we speak. Have tried doing a memtest86+, but for whatever reason when in the boot menu to select the memtest86+, the system would reboot. This error seems to only show when I'm running my Windows 10 VM for my wife, which from the start has been constantly stuttering every 20-30 secs where we have an inside joke while listening to Taylor Swift that it was Taylor Twift instead. Have tried applying the MSI Interrupt fix from the start, yet still unable to get it solved. Also I'm getting the error in the last line quite abit too recently where my dynamix system stats seems to have some missing file. another small issue while watching PleX locally on a web browser, it'll show insecure connection, and this has been the case ever since I restarted the whole unRAID install the last time. But plays perfectly fine on local and external clients. Appreciate any help! Below are my logs and diagnostic file Attached is my diagnostics. tower-diagnostics-20210923-1240.zip
-
Hi this is a great docker and I've been mining with a 1070, now I have a spare RTX 2070 which usually is able to hit 43MH/s on windows however I'm only able to get 37 MH/s now, is there anyway I can OC my card settings by undervolting and changing the memory settings? Thank you!
-
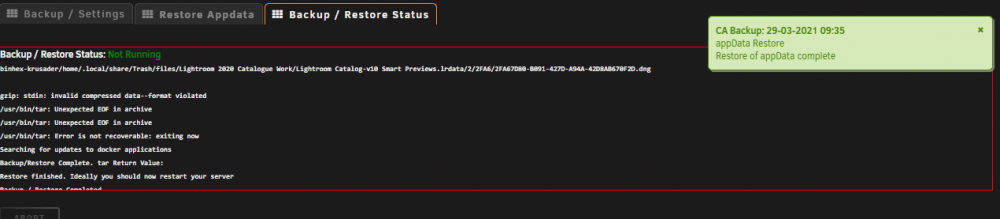
Hi, require some assistance as I am a dumbass and recently formatted both my cache drive due to when I start the array, it says they were not a mountable drive partition. I did run the backup/ restore 3 times the day before and they all were successful. However now that I've formatted and when I tried restoring the app data, it shows this and exit, tried unzipping it via window's winrar however also got roughly the same thing that the zip is corrupted and this happens on all 3 backups that I have. Is there any way I could get it properly working?