

evakq8r
-
Posts
52 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by evakq8r
-
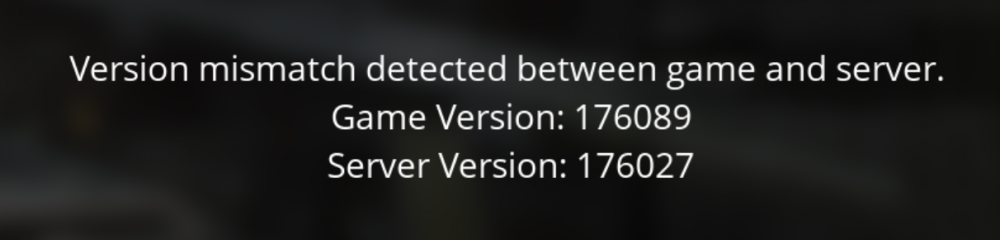
/facepalm... no idea why I didn't pick that up myself; forgot that the dedicated server defaults to EA(also just rechecked the patch notes and somehow missed (EXPERIMENTAL) against the latest version...). I've added -beta experimental to the game parameters and validated the files. It appeared to download an update, but the game still complains of a mismatch (server doesn't match the client). Tried -beta -experimental, same deal. I suspect I might need to rebuild the docker container completely as it still thinks EA is Experimental.
-
Has anyone encountered any issues with the Satisfactory container not pulling the latest game version? (even though the logs suggest the latest has been pulled). Is there a way to interact with steamcmd from within the Satisfactory docker to try and force an update? I also installed the same container on a completely different server and no difference. Satisfactory is throwing a 'game version mismatch' error: From the different server (new install): Update state (0x5) verifying install, progress: 2.67 (120586243 / 4522427563) Update state (0x5) verifying install, progress: 6.94 (314071968 / 4522427563) Update state (0x5) verifying install, progress: 10.79 (487774880 / 4522427563) Update state (0x5) verifying install, progress: 15.19 (686813465 / 4522427563) Update state (0x5) verifying install, progress: 19.87 (898567076 / 4522427563) Update state (0x5) verifying install, progress: 25.74 (1163915780 / 4522427563) Update state (0x5) verifying install, progress: 29.96 (1354779631 / 4522427563) Update state (0x5) verifying install, progress: 34.42 (1556748166 / 4522427563) Update state (0x5) verifying install, progress: 39.39 (1781451636 / 4522427563) Update state (0x5) verifying install, progress: 44.03 (1991436565 / 4522427563) Update state (0x5) verifying install, progress: 47.12 (2131001286 / 4522427563) Warning: failed to init SDL thread priority manager: SDL not found Update state (0x5) verifying install, progress: 51.67 (2336568147 / 4522427563) Update state (0x5) verifying install, progress: 55.57 (2513281039 / 4522427563) Update state (0x5) verifying install, progress: 60.30 (2726960366 / 4522427563) Update state (0x5) verifying install, progress: 65.98 (2984071282 / 4522427563) Update state (0x5) verifying install, progress: 71.34 (3226146982 / 4522427563) Update state (0x5) verifying install, progress: 76.97 (3480813547 / 4522427563) Update state (0x5) verifying install, progress: 82.25 (3719792347 / 4522427563) Update state (0x5) verifying install, progress: 88.28 (3992280189 / 4522427563) Update state (0x5) verifying install, progress: 93.53 (4229697601 / 4522427563) Update state (0x5) verifying install, progress: 98.72 (4464500652 / 4522427563) Success! App '1690800' fully installed. ---Prepare Server--- ---Server ready--- ---Start Server--- From the game: EDIT: Hmm, might be a Steam issue; loaded a new version of the dedicated server from Steam directly and it's also not up to date... but would be good if someone else can confirm so I can at least verify it's not just me.
-
Ahh, Game Parameters and Extra Parameters aren't the same thing (that's where I was getting confused): vs: As the error suggests, 'ultihome' is because '-m is another abbreviation for --memory in unRAID, and it's in the wrong format. Just tried again under Game Parameters only, and (after a few restarts) it seems to have registered. Thanks @DazedAndConfused.


-
@DazedAndConfused Are you adding the -multihome part to the Extra Parameters template under Advanced View? Or somewhere else? If I add as you've pasted above, I get: invalid argument "ultihome=0.0.0.0" for "-m, --memory" flag: invalid size: 'ultihome=0.0.0.0' If I add a double-dash ( -- ) : unknown flag: --multihome Adding to Game Parameters starts the container, but throws the error listed on the QA website:

-
The wiki is your friend @ra1k_0. There are suggestions for improving multiplayer under 'temporary lag solution', but I've implemented them anyway to prevent that kind of issue happening. Not sure if @ich777 wanted to consider doing the same for this template? Others that have spun up the dedicated server as a Docker container appear to have.
-
Right, my bad. I'm used to manually spinning up docker files in non-Unraid environments and added the Variable path to substitute for -v. As for raising it under Satisfactory Steam Community/their own QA website, they have announced plans to spin up Satisfactory Server as a docker hub container, but no ETA on when that will actually come to fruition. Not a big issue, I just like things to represent actual time zones of where I am. Thanks @ich777.
-
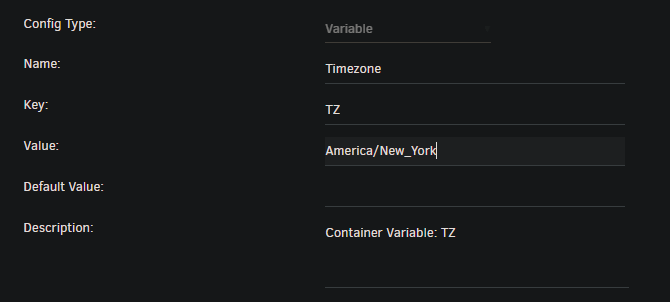
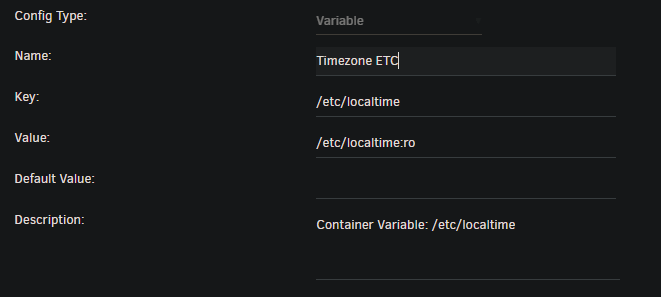
I might have missed it somewhere in the documentation, but is it possible to get the times in the logs to match your local timezone rather than UTC? I've tried adding the TZ variable: -e TZ="America/New_York" \ (example) to the container as well as: -v /etc/localtime:/etc/localtime:ro \ But the logs seem to revert back to UTC (I'm +9.5): [2021.10.30-05.42.44:871][602]LogGame: Write Backup to Disk and Cleanup time: 0.003 seconds [2021.10.30-05.42.44:874][602]LogGame: Total Save Time took 0.428 seconds [2021.10.30-05.47.44:648][574]LogGame: World Serialization (save): 0.166 seconds [2021.10.30-05.47.44:913][574]LogGame: Compression: 0.262 seconds [2021.10.30-05.47.44:913][574]LogGame: Write To Disk: 0.002 seconds [2021.10.30-05.47.44:913][574]LogGame: Write Backup to Disk and Cleanup time: 0.003 seconds EDIT: Actual Unraid Template screenshots would probably help:
-
True, but people have been asking for dedicated servers for quite a while now, so I figured a lot of people would be trying to set this up
-
Thank you for the Satisfactory template @ich777! I was literally in the midst of spinning up a dedicated server on a VM and stumbled across this. I do however seem to have some weird anomaly with trying to connect (it is likely a me problem as I can't find any reports of the same issues happening with someone else). This happens with both Windows Server (via Steam app) and Linux (via steamcmd). When I try and connect to the game server, my logs are spammed with the following (the IP is from my Steam client on my gaming PC): None of the server info loads in Game on my client (game thinks the server is offline). I understand this is all still experimental, but has anyone else had this same issue as yet? EDIT: Fixed my own issue; turns out I made an unnecessary port change (tried connecting to 7777 instead of 15777). Swapped to 15777 and now it loads.
-
I've had 3 DNS servers on 2 different bits of hardware fail on me in the last 24 hours (power blackouts really aren't fun), so yes I have; it's now set to a known public DNS provider and everything "just works".
-
Both plugins remain once booted. Here you go. syslog
-
I did notice an update earlier (for both nvidia and DVB). Installed both and rebooted.... The boot time is significantly faster now! I'll keep an eye on this for a few days but suffice to say it no longer takes my server 90 mins to boot!
-
Ah yes of course! Forgot about that handy feature. Thanks again!
-
I see, that would make sense. Australia No problems, I'll take that under advisement. Trying to limit myself to services like unbound or other recursive servers, but I will set that as a last resort. Great, thanks! Thanks for your help thus far @ich777
-
That said, here's the current syslog file attached (without rebooting). syslog
-
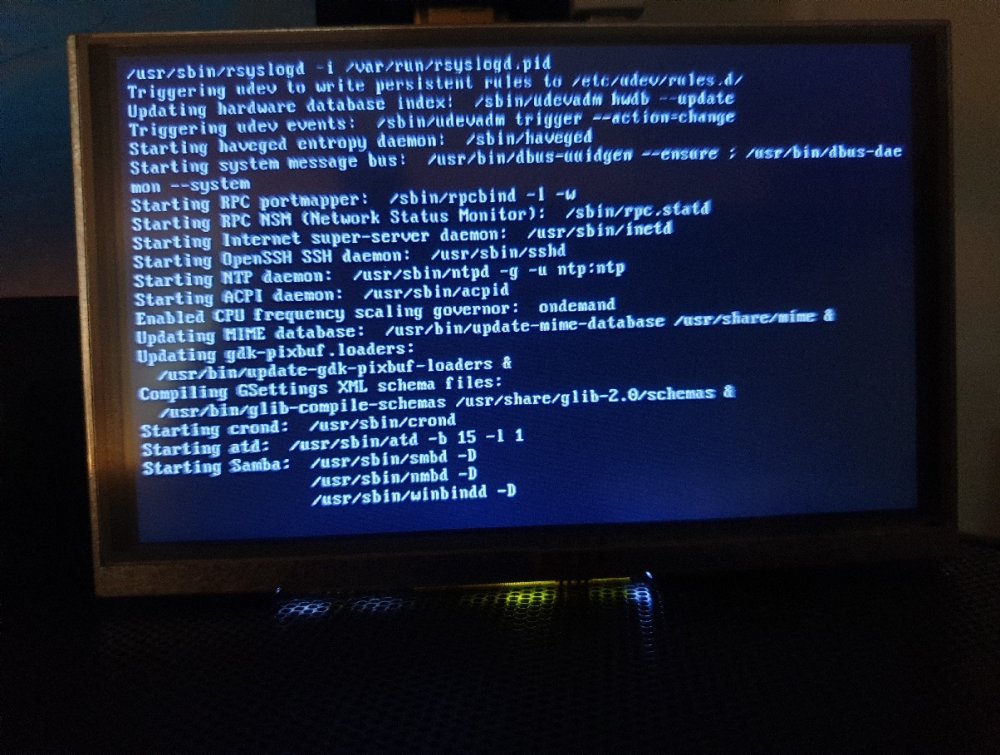
There were Plugin errors listed for the Nvidia and DVB drivers, which have since been removed. Server does have an active internet connection, yes. I do run PiHole on the server as well as the Unifi Controller. Not sure whether not having the controller accessible would prevent internet access? (haven't had the issue before). I would, but after I made the last edit earlier (the server did finally boot with a working GUI), I'm now reluctant to reboot it again and have to wait over an hour and a half for it to become responsive. Well when I took the USB boot drive and plugged it into an alternative computer, I deleted all plugins listed in the folder and tested, which worked fine. I then added JUST the NVIDIA plugin and tested, and the boot hanging began. Putting 2 + 2 together made me think that was the case, but maybe it was coincidence, I'm not sure. That's correct; I plugged a 5" RPI screen I had spare into the 1st port of the P2000 so I could get an idea on what was happening when the server didn't respond after the power blackout.
-
No worries, thanks @JohnnyP!
-
Hi there, My Unraid server seems to no longer be booting with the NVIDIA plugin installed. Need to explain a little. We had a power blackout today (the server is on a UPS, but due to the length of the blackout the UPS shut the server down, which was fine). Since power was restored, Unraid has been hanging after starting Samba services during the bootup sequence (normal boot time takes ~5 minutes, I left the server at this state for over an hour and no GUI). I took the USB to another computer, set the syslinux.cfg to boot into Safe Mode, and I am now able to get to the GUI, which made me think one of the plugins went bad. I had an old USB backup from 12 days ago that I flashed using the Unraid Creator and tried to boot that, which didn't work. Thinking that was odd, I removed all addons from the config folder on the boot USB, and attempted to boot in normal mode. Successful. I then went to reinstall the NVIDIA plugin (460.67 driver), disabled and re-enabled Docker as suggested, and tested Plex transcoding. Successful. I then went to reboot Unraid, and it once again stuck at the Samba login screen. I did however notice the server was pingable and can be SSH'd from another device (not directly, oddly enough), so the server is 'alive' but with no GUI. I rolled the change back with the NVIDIA plugin not installed, and the server fired up no problem (albeit with no plugins). I've gone back to the last backup I was able to grab before the UPS' power went out, and pulled a diagnostics via SSH. TL;DR: What would potentially cause the NVIDIA plugin to prevent GUI bootup? Pic attached is as far as the boot sequence will go. Server specs are in my sig. EDIT: Well, after waiting an hour and a half... the bloody thing boots with a GUI. I have no idea why it took so long to boot, but it's up and that's all that matters. I will do some more investigation over the coming days, but if anyone has any insight as to the lengthy lead times on boot up, I'm all ears. tower-diagnostics-20210322-2110.zip
-
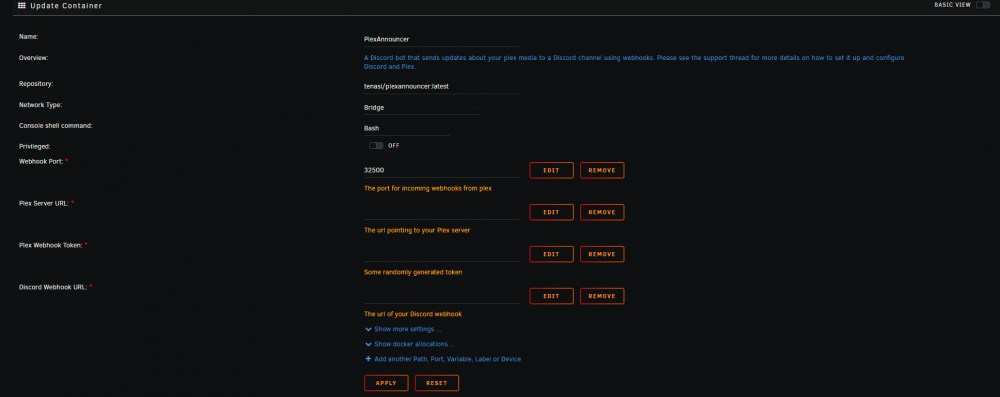
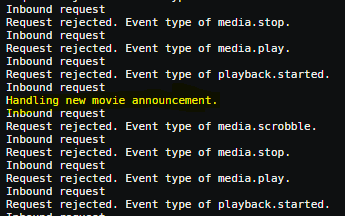
Hi there, May seem like a dumb question, but is the Config Path meant to populate as a mandatory field when first downloading the app? Or can that be added as an optional path? I've tried setting this up today and I have four variables, but no Config Path listing: Trying to work out why the announcer doesn't seem to be announcing anything. I've followed the instructions and setup the relevant Webhooks in Plex and Discord, but nothing is announced when a new movie is added. The only thing in log file is that it's running, and I've tried adding ~8 movies since it was set up: Any ideas? EDIT: For whatever reason, leaving the container going for the last few hours and allowing other movies to populate the library has finally allowed the announcements through into Discord. Logs now show:

-
Thanks very much!
-
Thanks for the reply @binhex, sorry for the delay - hectic week. I've made the changes to the qbittorrent container as suggested (changed to tun0) and restarted the container. So far so good! No more P2P logs from my router. I'll keep an eye on it over the weekend and see whether any more spring through, but so far this looks to be a viable workaround. Thanks!
-
Out of curiousity, are the IP Leak issues with qBittorrentvpn still a thing? Since the update was made about the ip leakage and an update to this container was released, my USG4P has been throwing DHT announce messages out once every 4 minutes. ie. Threat Management Alert 1: Potential Corporate Privacy Violation. Signature ET P2P BitTorrent DHT announce_peers request. From: 192.168.1.100:20541, to: 172.98.71.202:20541, protocol: UDP 172.98.71.202 points to the PIA endpoint for Montreal. I've also tested this with the binhex-rtorrentvpn container and do not get these logs, which to me means it's specific to this container. I'm unable to swap to rtorrentvpn however for other reasons (not relevant to this issue). Prior to the update, this wasn't happening at all. If this is expected behaviour, I'll learn to live with it but every 4 minutes for over a week is a lot of log file.
-
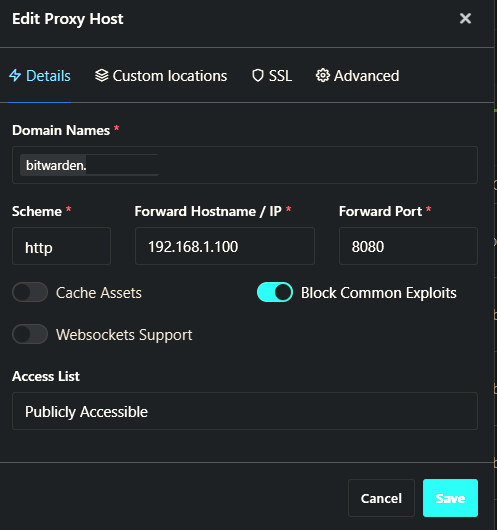
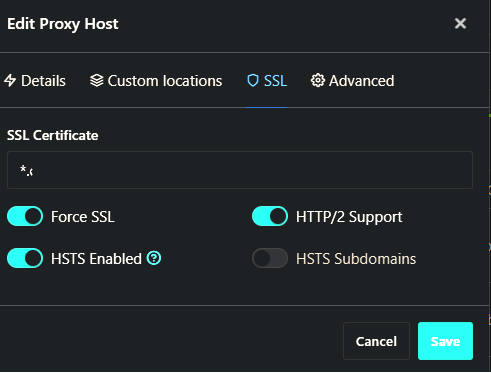
Hi there, Hoping this is the right place to report issues.. if not, please redirect as needed. Also, sorry for the long post. TL;DR: Bitwarden on NPM results in 'unexpected error' on login. Bitwarden on SWAG results in no issues. SETUP: Host OS: Unraid 6.9.1 Containers with issues: Bitwarden (via docker-compose) and NginxProxyManager I've spent this weekend trying to migrate from SWAG to NPM (mainly for testing, but having a UI to do most of the NGINX work is nice too). All my containers work, except Bitwarden... this one keeps failing intermittently. I've also implemented Authelia with NPM following https://github.com/ibracorp/authelia and that works too. I've been unable to use Bitwarden_rs with my Unraid server (see https://github.com/dani-garcia/bitwarden_rs/issues/1071), but have had SWAG work with my Bitwarden install (via docker-compose) without issue for several months. After setting up my Bitwarden instance under NPM, I am able to authenticate using Authelia, which redirects to the public Bitwarden address I have setup, but after attempting to login, it fails for 'unexpected error has occurred'. I've tried digging through the bitwarden-mssql, bitwarden-admin and bitwarden-nginx logs for errors, but none appear. If I turn off NPM and swap back to SWAG, I can log in without error. Configs: SWAG:- server { listen 443 ssl; listen [::]:443 ssl; server_name bitwarden.*; include /config/nginx/ssl.conf; client_max_body_size 128M; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; # enable for Authelia # include /config/nginx/authelia-server.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /ldaplogin; # enable for Authelia # include /config/nginx/authelia-location.conf; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app bitwarden-nginx; set $upstream_port 8080; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } location /admin { return 404; } location /notifications/hub { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app bitwarden-nginx/; set $upstream_port 8080; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade"; } location /notifications/hub/negotiate { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app bitwarden-nginx; set $upstream_port 8080; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } } NPM:- location /authelia { internal; set $upstream_authelia http://192.168.1.100:9091/api/verify; proxy_pass_request_body off; proxy_pass $upstream_authelia; proxy_set_header Content-Length ""; # Timeout if the real server is dead proxy_next_upstream error timeout invalid_header http_500 http_502 http_503; client_body_buffer_size 128k; proxy_set_header Host $host; proxy_set_header X-Original-URL $scheme://$http_host$request_uri; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $remote_addr; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-Host $http_host; proxy_set_header X-Forwarded-Uri $request_uri; proxy_set_header X-Forwarded-Ssl on; proxy_redirect http:// $scheme://; proxy_http_version 1.1; proxy_set_header Connection ""; proxy_cache_bypass $cookie_session; proxy_no_cache $cookie_session; proxy_buffers 4 32k; send_timeout 5m; proxy_read_timeout 240; proxy_send_timeout 240; proxy_connect_timeout 240; } location / { set $upstream_app bitwarden-nginx; set $upstream_port 8080; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; location /notifications/hub { set $upstream_app bitwarden-nginx/; set $upstream_port 8080; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade"; } location /notifications/hub/negotiate { set $upstream_app bitwarden-nginx; set $upstream_port 8080; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } auth_request /authelia; auth_request_set $target_url https://$http_host$request_uri; auth_request_set $user $upstream_http_remote_user; auth_request_set $groups $upstream_http_remote_groups; proxy_set_header Remote-User $user; proxy_set_header Remote-Groups $groups; error_page 401 =302 https://<auth.domain.com>/?rd=$target_url; client_body_buffer_size 128k; proxy_next_upstream error timeout invalid_header http_500 http_502 http_503; send_timeout 5m; proxy_read_timeout 360; proxy_send_timeout 360; proxy_connect_timeout 360; proxy_set_header Host $host; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection upgrade; proxy_set_header Accept-Encoding gzip; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-Host $http_host; proxy_set_header X-Forwarded-Uri $request_uri; proxy_set_header X-Forwarded-Ssl on; proxy_redirect http:// $scheme://; proxy_http_version 1.1; proxy_set_header Connection ""; proxy_cache_bypass $cookie_session; proxy_no_cache $cookie_session; proxy_buffers 64 256k; set_real_ip_from 192.168.1.0/24; real_ip_header X-Forwarded-For; real_ip_recursive on; } I've tried cycling SSL, HSTS and HTTP2 on and off with no difference to the outcome. I can also access the local IP of Bitwarden and login without error while NPM is configured, which makes me think this is specifically an NPM problem. Happy to be corrected. Any help would be appreciated. Thanks for reading. EDIT: The 'auth.domain.com' is normally filled in, but has been substituted for posting purposes (is normally auth.<mydomain>.<mydomain>) EDIT2: After many hours of pulling my hair out, finally resolved the issue. Turns out the configs between SWAG and NPM are defined slightly differently. In SWAG, the bitwarden-nginx port is pointed to 8080, however in NPM it needed to be pointed to my custom port that was defined during the docker-compose... Now it works without issue!
-
[Support] [Depreciated] FlippinTurt PiHole DoT-DoH
evakq8r replied to FlippinTurt's topic in Docker Containers
None of the containers are timing out, it's just loading the plugins page on the Unraid GUI. Each time the plugins were attempted, an error like the below would appear: ERR failed to connect to an HTTPS backend "https://1.1.1.1/dns-query" error="failed to perform an HTTPS request: Post \"https://1.1.1.1/dns-query\": net/http: request canceled (Client.Timeout exceeded while awaiting headers)" I have 2 DNS servers set (both operated by PiHole, Unraid as primary, RPI as secondary). As mentioned, when I turned off the Unraid PiHole-DoT-DoH container, the issue disappeared once the RPI started doing the DNS resolution. The errors are still present in the logs after I restarted the container the other day. My guess is it's not as noticeable as it's using the RPIs DNS for backup resolution. I'll just put up with it for now, but this is only a recent development. The only major change I've done was upgrade Unraid from 6.8.3 to 6.9.1 in the last week. EDIT: I have also completely removed all config folders and setup with this container and started from scratch after the 6.9.1 upgrade. That didn't make any difference. -
[Support] [Depreciated] FlippinTurt PiHole DoT-DoH
evakq8r replied to FlippinTurt's topic in Docker Containers
Hi there, For reasons unknown I've started to encounter an issue with this application after it has been working for several weeks. The docker container was running but no addresses were resolving. I checked the logs, and found: [x] DNS resolution is not available Rebooted the container several times, no difference. Started Googling, found that some people were only able to get their container to fully start by adding '--dns 127.0.0.1, --dns 1.1.1.1' to their Extra Parameters config. This resolved the DNS resolution error for about an hour, and now I'm starting to get these errors in the logs when trying to navigate to different web addresses: 2021-03-08T23:21:39Z ERR failed to connect to an HTTPS backend "https://1.1.1.1/dns-query" error="failed to perform an HTTPS request: Post \"https://1.1.1.1/dns-query\": net/http: request canceled (Client.Timeout exceeded while awaiting headers)" 2021-03-08T23:21:39Z ERR failed to connect to an HTTPS backend "https://1.1.1.1/dns-query" error="failed to perform an HTTPS request: Post \"https://1.1.1.1/dns-query\": net/http: request canceled (Client.Timeout exceeded while awaiting headers)" 2021-03-08T23:34:23Z ERR failed to connect to an HTTPS backend "https://1.1.1.1/dns-query" error="failed to perform an HTTPS request: Post \"https://1.1.1.1/dns-query\": net/http: request canceled (Client.Timeout exceeded while awaiting headers)" 2021-03-08T23:34:23Z ERR failed to connect to an HTTPS backend "https://1.1.1.1/dns-query" error="failed to perform an HTTPS request: Post \"https://1.1.1.1/dns-query\": net/http: request canceled (Client.Timeout exceeded while awaiting headers)" Most notably is when I try and load the Plugins webpage within the Unraid GUI. It'll constantly spin for about 10 minutes (yet the syslog in Unraid doesn't show that it's timed out (yet)). In a normal circumstance, it'll load in about 10 seconds. I have another Pihole setup on my RPI as a fallback (not using this Docker as it doesn't support armv7) so I can get around it, but I don't quite get why this one has just packed up now. It is intermittent so I understand it probably won't be easy to replicate (if at all). Any ideas? EDIT: The logs have become a lot more frequent in the last couple of days, which have led to DNS resolution issues. I've tried completely installing from scratch but no joy. My router's DNS settings have not been tweaked in many months, but they all look correct. I have turned off this docker container in favour of my RPIs PiHole install, and that's been working without issue.












